Concept Bottleneck Models (CBM)
本篇文章发表于ICML 2020。
文章链接:https://arxiv.org/abs/2007.04612
代码链接:https://github.com/yewsiang/ConceptBottleneck

这篇文章的作者之一Been Kim也是TCAV的第一作者。
一、概述
本文旨在寻找一种可以使用high-level concepts实现人与模型之间交互的方法。试想一个问题:如果一个X-ray图片中并没有骨刺,那么模型还会不会把它预测为严重的关节炎?目前大部分的SOTA方法都是采用端到端的网络,即直接从原始输入(例如像素)到输出(例如关节炎严重程度)。
一个很直觉的想法是,在最终预测之前,先去预测人类可以理解的concepts,然后使用这些concepts再去预测得到最终输出;所谓的concept bottleneck由此得名,即,位于网络中间的、用来预测概念的一层;并且,一旦我们有了瓶颈层,在测试时就可以观察该层的输出并对其预测的概念进行干预;具体来说,就是编辑、修改、纠正模型瓶颈层预测的概念值,并由此对最终的预测进行修正,大大提高了准确率。
这个想法是比较自然的。设想一个医生在诊断的时候,我们把一个端到端的网络输出甩在他的脸上,告诉他这个患者有病,那医生肯定会问:模型为什么做出这样的判断?依据是什么?但很遗憾,对于现有的大部分模型而言,这个问题将无法回答,因为我们也不知道模型为什么会给出这样的决策,这也正是可解释性的重要所在。而一旦我们有了对中间层的限制,即,在最终决策之前加入concept bottleneck对一些概念进行预测,并将这些概念作为最终决策的判断依据,我们就知道是因为“片子中有骨刺等概念”,因此综合分析得出“患者有病”的结论,增加模型的可信度、提高决策的透明度。
这个问题可以表述为:提供一系列数据点 ![]() ,其中
,其中  与
与  分别是
分别是  对应的概念标签与最终标签(比如类别),在该数据集上训练一个CBM,CBM首先会预测 ,进而通过 预测 。在test的时候,观察由input 产生的概念预测
对应的概念标签与最终标签(比如类别),在该数据集上训练一个CBM,CBM首先会预测 ,进而通过 预测 。在test的时候,观察由input 产生的概念预测  ,再由 得到最终预测
,再由 得到最终预测  。
。
该模型理论上可以应用于任何已有的网络结构,只需要调整网络中间某一层神经元的数量为定义的概念的数量,并对该层输出用损失函数加以约束,以鼓励该层神经元与所定义的概念相匹配。这种神经元与concepts的匹配将作为intervention阶段的必要条件,因为如果网络无法对concept作出完美预测,那么后续的intervention也就没有了意义,因为我们甚至不知道我们在修改、编辑的是什么概念。
到这里我们其实还可以发现该模型比较明显的一个问题——标注问题。因为对于CBM来说,训练集不仅需要类别标签,还需要概念标签。当然,近几年随着多模态及大语言模型模型(比如CLIP、GPT)的发展与应用,这一问题在一定程度上得到了缓解,后面我会讲到。
作者在Introduction的最后一段指出,本文所提出的CBM与end-to-end模型精度相当的同时也能达到较高的概念预测准确度。而相比之下,标注的black-box中间层神经元输出的线性组合无法高精度地预测人类所定义的概念——这也就意味着神经网络中间层的神经元学习的并不是我们人类可以理解的概念,因为我们无法通过线性组合预测我们想要的概念,那么像TCAV这样的方法在很多情况下也就不适用了。
二、方法
- 相关方法(Related works)
特征工程(Feature engineering)
CBM与特征工程类似,因为二者都需要指定中间概念/特征,但是CBM是学习从原始输入到高级概念的映射,而特征工程是通过手写函数计算图像的低级特征。
Concepts as auxiliary losses or features
(i) Concepts as auxiliary losses。如多任务学习,这类方法将concepts视为辅助损失/目标,但是并不支持对概念的intervention。原因在于,多任务模型的预测方式为 ![]() 。在test的时候,通过改变 并不会影响 的预测;
。在test的时候,通过改变 并不会影响 的预测;
(ii) Concepts as auxiliary features。这类方法首先预测 ![]() ,然后预测
,然后预测![]() 。“We cannot intervene in isolation on a single concept because of the side channel from
。“We cannot intervene in isolation on a single concept because of the side channel from  。”
。”
Causal models
虽然CBM可以表示为 ![]() 的因果关系,但是这不代表在现实世界中一定存在
的因果关系,但是这不代表在现实世界中一定存在 ![]() 的因果关系,不过这仍然不影响我们使用intervention提高预测的精准度。解释一下,比如,我们通过某种方式把一个人的腿变肿(虽然不太讲究...),但是这并不会影响这个人是否患有关节炎,因为二者不存在因果关系;但即使这样,我们也可以通过在test time对“肿胀”这一concept做intervention来提高预测准确度。
的因果关系,不过这仍然不影响我们使用intervention提高预测的精准度。解释一下,比如,我们通过某种方式把一个人的腿变肿(虽然不太讲究...),但是这并不会影响这个人是否患有关节炎,因为二者不存在因果关系;但即使这样,我们也可以通过在test time对“肿胀”这一concept做intervention来提高预测准确度。
Post-hoc concept analysis
作者在此处提到了几个事后概念分析的可解释工作,包括之前介绍的TCAV以及之后要讲的Network Dissection。但是如刚刚所说,这些技术依赖于模型能够自动学习到concepts,但是当模型做不到一点的时候,这种事后可解释方法就无法实现;并且,此类方法也不允许对这些概念进行intervention。而在CBM中,直接引导模型在训练时学习这些concepts。
- 本文方法
Coinsider predicting a target ![]() from input
from input ![]() ; for simplicity, we present regression first and discuss classification later. We observe training points
; for simplicity, we present regression first and discuss classification later. We observe training points ![]() ,where
,where ![]() is a vector of
is a vector of  concepts.
concepts.
CBM has the form  , where
, where ![]() ,
, ![]()
简而言之,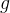 用来预测concepts,
用来预测concepts, 用来预测最终结果。即
用来预测最终结果。即 ![]() ,
, ![]() 。
。
网络有三种学习方式,independent,sequential,joint。

1. independent:其中 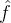 用真实的标签 训练,而
用真实的标签 训练,而 ![]() 以concept的预测损失训练;
以concept的预测损失训练;
2. sequential:先训练 ![]() ,再用
,再用 ![]() 预测得到的
预测得到的 ![]() 作为后续网络的输入训练 ;
作为后续网络的输入训练 ;
3. joint:设置一个权重  平衡两个损失联合训练。
平衡两个损失联合训练。
作为比较,作者还训练了一个standard model,即端到端的网络。
我们观察联合训练的损失函数:如果  ,对应的就是没有bottleneck的standard model;如果
,对应的就是没有bottleneck的standard model;如果 ![]() ,对应的就是顺序训练 。
,对应的就是顺序训练 。
将一个end-to-end的模型中间的某一层神经元个数resize成 个,以匹配定义的 个concepts,然后根据上面的training scheme进行训练即可。
需要注意的是,OAI是回归任务,而CUB是分类任务;在回归任务中,我们在中间层得到的输出是0-1的一个值;而在分类问题中,得到的并不是一个值而是一个logits向量,这个向量之后会通过sigmoid函数作为概念出现的概率,原文如下:

在实际操作上, 通过fine-tune Inception-v3得到, 通过单个线性层实现(i.e., logistic regression)
三、实验及结果

通过三种训练方式训练得到的CBM在准确度上均可以与标准的黑盒网络相比,其中joint最佳;当移除standard网络中间的bottleneck时对结果影响不大;Multitask网络更准确,但不允许再test time做intervention。

左图:再OAI任务上作者并没有观察到accuracy(task error)与interpretability(concept error)之间的compromise;但是在CUB任务上会存在一些trade-off,因为当设置 为不同的值时,task error与concept error总是有一个较低、另一个较高。
中图:单个概念准确程度直方图。每个单独的概念都能被CBM准确预测。
右图:数据效率。CBM可以用最少的训练点实现与标准模型相同的任务精度。(但是标注负担及利用的信息也是不一致的,毕竟standard model并没有用到concept labels;而且此处并没有对比multitask,也许是比不过?)
再来看一下test-time intervention的结果:

通过修改中间层对concept的错误预测,实现了最终的正确分类,成功进行了intervention。左侧是OAI任务,右侧是CUB。需要注意的是,对于OAI回归任务,我们在intervention时只需要将对应的预测值 调整为真实值 ;而对于CUB,由于是分类任务,我们是在logits上进行操作,使得“![]() is close to the true
is close to the true  ”,其中
”,其中 ![]() ,也就是bottleneck输出的logits;并且在改变这个logits的时候,往往不能只改变其中的某个值,因为该向量中的不同元素可能代表类似的含义,比如黑色翅膀与白色翅膀,这种情况下需要同时intervene不同元素的值以保证不会出现矛盾(比如翅膀既是白色也是黑色)。
,也就是bottleneck输出的logits;并且在改变这个logits的时候,往往不能只改变其中的某个值,因为该向量中的不同元素可能代表类似的含义,比如黑色翅膀与白色翅膀,这种情况下需要同时intervene不同元素的值以保证不会出现矛盾(比如翅膀既是白色也是黑色)。
一些讨论:如前所述,CBM的缺点就是需要额外的annotation;未来的工作可能会引入side channel form,即,这一点在发表于ICLR 2023的“post-hoc CBM”中已经实现,后面会讲到。