FrankMocap
FrankMocap
- 摘要
- 介绍
- 相关工作
-
- 3D参数化人体模型
- 单图像3D人体姿势估计
- 单图像3D手姿势估计
- 身体和手的联合3D姿势估计
- 方法
-
- SMPL-X模型概述
- 3D手估计模块
-
- 手模块结构
- 训练方法
- 数据集预处理
- 训练数据增强
- 3D身体估计模块
- 整个身体集成模块
-
- 快速的身体和手组成通过复制和粘贴
- 手和身体组成通过优化
- 实验
-
- 不同模型的速度
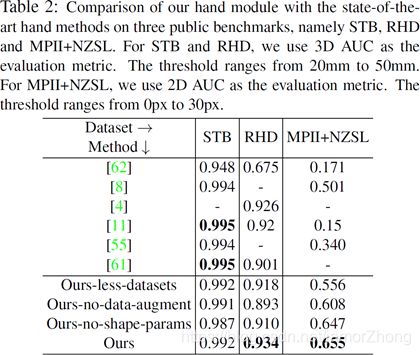
- 不同手模型的估计精度
- 数据集消融实验
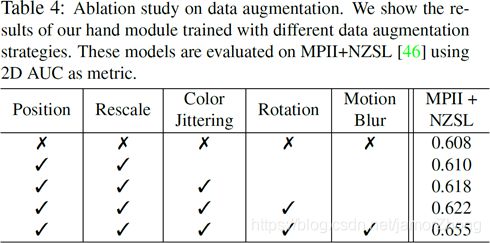
- 数据增强消融实验
- 结论
- 未来工作
- 附
摘要
问题:目前存在的动作捕捉方法要么只聚焦在身体动作捕捉,要么只聚焦在手部动作捕捉。
方法:提出了FrankMocap动作捕捉系统,既可以捕捉身体动作,也可以捕捉手部动作,在速度(9.5 fps)和准确率上都达到SOTA。
介绍
- 动作捕捉的应用:人机交互,社交人工智能和机器人。
- 当前存在的问题:
- 人体姿势估计准确率高但手指姿势被忽略。
- 手部姿势估计不适合更具挑战性的野外场景。
- 最近表达手和身体的3D模型相对较慢且不适合实时应用。
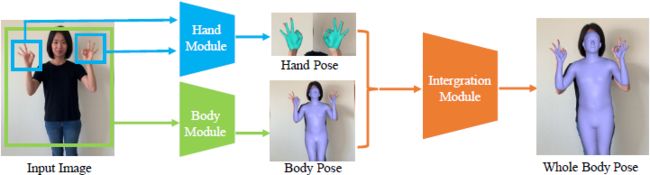
- 解决方法:提出一个快速准确的运动捕捉方法,单眼RGB.该方法由两个预测身体和手部3D姿势的回归模块和一个集成身体和手部姿势的模块组成。方法的主要思想是使身体姿势模块和手部姿势模块的输出尽可能地兼容,以便更有效地将两者集成一起。身体模块和手部模块基于SMPLX模型贡献了相同输出结构的不同部分,从而实现近实时性能人体3D运动捕捉。
相关工作
3D参数化人体模型
- SCAPE:解决了形状变化和姿势变化的问题。
- SMPL:在线性混合蒙皮的顶部学习局部姿势相关的混合形状,以实现整体网格变形和形状变化。
- MANO:手形变模型。
- SMPL+H:统一的身体手模型。
- Adam:身体,手和脸的统一模型。
- SMPL-X:统一的身体,手和脸模型。
单图像3D人体姿势估计
- 直接从单个图像中预测3D身体关键点位置-缺少3D关节角度并且不保存身体各部分的长度。
- 采用参数3D人体模型(SMPL或Adam)-将3D模型拟合到2D观测值,重构3D人体姿势。参数利用深度学习框架直接回归得到。
- 混合框架-先通过深度学习得到2D和深度的热点图,然后将其拟合到骨骼模型去重建关节角度。
- 数据集:混合数据集=室内数据集(Human3.6M)+野外数据集(COCO或3DPW)
- 输入:大多数为单帧图像,少数为序列图像(视频)。
单图像3D手姿势估计
- 基于深度图像的姿势估计-无法轻松应用于野生RGB图像和视频。
- 基于单眼RGB的姿势估计-关注3D关节位置而非关节角度。
- 使用OpenPose预测2D姿势并回归到MANO模型。
- 使用2D热点图预测模块,同样回归到MANO模型。
- 预测2D热点图,使用图卷积网络回归手模型顶点。
身体和手的联合3D姿势估计
缺乏用于全身捕捉的数据集-现有方法均采用优化方法,计算时间长。
- 使用SMPL-X代表整个身体姿势,通过拟合增加约束(身体姿势先验和碰撞惩罚器)的2D关键点优化模型参数。
- MTC:采用深度神经网络获得2.5D姿势,通过优化获得Adam模型参数。
方法
SMPL-X模型概述
SMPL-X模型可以通过低维形状和姿势参数的组合表示人体的形状变化和于姿势有关的变形。
SMPL-X模型公式: V w = W ( ϕ w , θ w , β w ) , \boldsymbol V_w = W(\phi_w,\theta_w,\beta_w), Vw=W(ϕw,θw,βw),
其中 ϕ w ∈ R 3 \phi_w\in\mathbb R^3 ϕw∈R3为整个人体的整体旋转, θ w ∈ R ( 21 + 15 + 15 ) × 3 \theta_w\in\mathbb R^{(21+15+15)\times3} θw∈R(21+15+15)×3为整个人体姿态相关的变形参数, β w ∈ R 10 \beta_w\in\mathbb R^{10} βw∈R10为人体和手形状的相关参数。将 θ w \theta_w θw分解, θ w = { θ w b , θ w l h , θ w r h } \theta_w=\{\theta_w^b,\theta_w^{lh},\theta_w^{rh}\} θw={θwb,θwlh,θwrh},其中 θ w b ∈ R 21 × 3 \theta_w^b\in\mathbb R^{21\times3} θwb∈R21×3为身体姿势参数, θ w l h ∈ R 15 × 3 \theta_w^{lh}\in\mathbb R^{15\times3} θwlh∈R15×3为左手姿势参数, θ w r h ∈ R 15 × 3 \theta_w^{rh}\in\mathbb R^{15\times3} θwrh∈R15×3为右手姿势参数。最后SMPL-X模型输出 V w ∈ R 10475 × 3 V_w\in\mathbb R^{10475\times3} Vw∈R10475×3,代表mesh的10475个点。3D关节点位置采用回归函数 R R R获得: J w 3 D = R w ( V w ) , \boldsymbol J_w^{3D}=R_w(\boldsymbol V_w), Jw3D=Rw(Vw),其中 J w 3 D ∈ R ( 21 + 15 + 15 ) × 3 \boldsymbol J_w^{3D}\in\mathbb R^{(21+15+15)\times3} Jw3D∈R(21+15+15)×3。
手模型-通过摘取SMPL-X的手部零件定义: V h = H ( ϕ h , θ h , β h ) , \boldsymbol V_h=H(\phi_h,\theta_h,\beta_h), Vh=H(ϕh,θh,βh),其中 ϕ h ∈ R 3 \phi_h\in\mathbb R^3 ϕh∈R3为手的整体旋转, θ h ∈ R 3 × 15 \theta_h\in\mathbb R^{3\times15} θh∈R3×15为手的姿势参数, β h \beta_h βh为手的形状参数。最后输入 V h ∈ R 778 × 3 , \boldsymbol V_h\in\mathbb R^{778\times3}, Vh∈R778×3,代表手mesh的778个点。通过回归函数得到3D手关节位置: J h 3 D = R h ( V h ) , \boldsymbol J_h^{3D}=R_h(\boldsymbol V_h), Jh3D=Rh(Vh),其中 J h 3 D ∈ R 21 × 3 \boldsymbol J_h^{3D}\in\mathbb R^{21\times3} Jh3D∈R21×3。

3D手估计模块

提出单眼3D手姿势估计模块-与最新的单眼身体姿势估计方法相似,用其预测SMPL-X手模型的输入。
手模块结构
该模块是将HMR模型用手姿势估计数据集训练得到的, M H M_H MH即手模型是端到端的深度神经网络,其定义如下: [ ϕ h , θ h , β h , c h ] = M H ( I H ) , [\phi_h,\theta_h,\beta_h,c_h]=M_H(\mathbf I_H), [ϕh,θh,βh,ch]=MH(IH),其中 I H \mathbf I_H IH为裁剪的手部区域RGB图像, c h = ( t h , s h ) c_h=(t_h,s_h) ch=(th,sh)为弱透视相机参数,可以将姿势3D手模型投影到输入图像。其中, t h ∈ R 2 t_h\in\mathbb R^2 th∈R2用于图像平面上的2D平移, s h ∈ R s_h\in\mathbb R sh∈R为缩放因子。第 i i i个3D手部关节可以被映射如下: J h , i 2 D = s h Π ( J h , i 3 D ) + t h , \boldsymbol J_{h,i}^{2D}=s_h\Pi(\boldsymbol J_{h,i}^{3D})+t_h, Jh,i2D=shΠ(Jh,i3D)+th,,其中 Π \Pi Π为正射投影。
手模块结构由一个编码器和一个解码器组成,编码器网络为ResNet-50,从输入图像中获取图像特征,解码器为全连接网络,用来从图像特征中回归手姿势参数。在训练时,使用右手作为训练数据,将左手的图像和标注使用垂直翻转后(相当于右手)进行训练。在测试时,左手先被翻转成右手,然后将输出再翻转回左手空间。
训练方法
三种不同类型标注的损失函数:
L θ = ∥ θ h − θ ^ h ∥ 2 2 , L 3 D = ∥ J h 3 D − J ^ h 3 D ∥ 2 2 , L 2 D = ∥ J h 2 D − J ^ h 2 D ∥ , L_\theta=\begin{Vmatrix}\theta_h-\hat{\theta}_h\end{Vmatrix}_2^2,\\ L_{3D}=\begin{Vmatrix}\boldsymbol J_h^{3D}-\hat{\boldsymbol J}_h^{3D}\end{Vmatrix}_2^2,\\ L_{2D}=\begin{Vmatrix}\boldsymbol J_h^{2D}-\hat{\boldsymbol J}_h^{2D}\end{Vmatrix}, Lθ=∥∥θh−θ^h∥∥22,L3D=∥∥∥Jh3D−J^h3D∥∥∥22,L2D=∥∥∥Jh2D−J^h2D∥∥∥,其中 L θ L_\theta Lθ为手姿势参数的损失函数, L 3 D L_{3D} L3D为3D关键点标注的损失函数, L 2 D L_{2D} L2D为2D关键点标注的损失函数。 θ ^ h \hat{\theta}_h θ^h为真实整体旋转标注, J ^ h 3 D \hat{\boldsymbol J}_h^{3D} J^h3D为真实3D关键点标注, J ^ h 2 D \hat{\boldsymbol J}_h^{2D} J^h2D真实2D关键点标注。
手部形状参数的正则项: L r e g = ∥ β h ∥ 2 2 , L_{reg}=\begin{Vmatrix}\beta_h\end{Vmatrix}_2^2, Lreg=∥∥βh∥∥22,用于惩罚不自然的手部形状。
总的损失函数: L = λ 1 L θ + λ 2 L 3 D + λ 3 L 2 D + λ 4 L r e g . L=\lambda_1L_\theta+\lambda_2L_{3D}+\lambda_3L_{2D}+\lambda_4L_{reg}. L=λ1Lθ+λ2L3D+λ3L2D+λ4Lreg.
数据集预处理
3D手势姿势数据集存在的问题:各种数据集的注释类型各不相同。
预处理:1.使用中指的指关节长度作为参考,将所有3D关键点注释缩放到与手模型相兼容。2.重新排序3D关键点,使其与手模型的骨架层次结构相同。
训练数据增强
数据增强策略:随机缩放、随机转换、颜色抖动和随机旋转。
使用模糊核在图像上增加运动模糊以增强模型在野外的表现能力。
3D身体估计模块
通过在训练管道用SMPL-X替换SMPL对SOTA方法进行微调,在训练时,仅使用与SMPL-X模型兼容的姿势参数和2D关键点标注。
身体模块公式:
[ ϕ b , θ b , β b , c b ] = M B ( I b ) , [\phi_b,\theta_b,\beta_b,c_b]=M_B(\boldsymbol I_b), [ϕb,θb,βb,cb]=MB(Ib),其中 I b \boldsymbol I_b Ib是人整个身体的裁剪图像, ϕ b ∈ R 3 \phi_b\in\mathbb R^3 ϕb∈R3为身体整体旋转, θ b ∈ R 21 × 3 \theta_b\in\mathbb R^{21\times3} θb∈R21×3为身体姿势参数, β b ∈ R 10 \beta_b\in\mathbb R^{10} βb∈R10和 β w \beta_w βw共享参数。弱透视相机参数 c b = ( t b , s b ) c_b=(t_b,s_b) cb=(tb,sb)和手模型的参数类似。
由于不正确或不充足的标注,存在的身体姿势估计以及本文的身体模块都不能准确的估计手腕和手臂的旋转。
整个身体集成模块
集成模块的作用:将手模块和身体模块的输出集成到SMPL-X模型。
快速的身体和手组成通过复制和粘贴
由于手模块和身体模块输出的手腕格式不同,因此做如下处理: θ b = θ ~ b ∪ { θ b r w r i s t , θ b l w r i s t } \theta_b=\tilde{\theta}_b\cup\{\theta_b^{\bf{rwrist}},\theta_b^{\bf{lwrist}}\} θb=θ~b∪{θbrwrist,θblwrist},其中 θ ~ \tilde{\theta} θ~为身体模型除手腕之外的姿势参数。整个身体集成表示如下: ϕ w = ϕ b , β w = β b , c w = w b , \phi_w=\phi_b,\\ \beta_w=\beta_b,\\ c_w=w_b, ϕw=ϕb,βw=βb,cw=wb, ( θ ~ w b , θ w l h , θ w r h ) = ( θ ~ b , θ l h , θ r h ) , ( θ w l w r i s t , θ w r w r i s t ) = ( Γ l ( θ b , ϕ l h ) , Γ r ( θ b , ϕ r h ) ) , (\tilde\theta_w^b,\theta_w^{lh},\theta_w^{rh})=(\tilde\theta_b,\theta_{lh},\theta_{rh}),\\ (\theta_w^{\bf{lwrist}},\theta_w^{\bf{rwrist}})=(\Gamma_l(\theta_b,\phi_{lh}),\Gamma_r(\theta_b,\phi_{rh})), (θ~wb,θwlh,θwrh)=(θ~b,θlh,θrh),(θwlwrist,θwrwrist)=(Γl(θb,ϕlh),Γr(θb,ϕrh)),其中 Γ l \Gamma_l Γl和 Γ r \Gamma_r Γr是将手模块获得的整体手腕方向转换为SMPL-X骨架层次结构中父关节局部手腕姿势参数的函数。
手和身体组成通过优化
F ( [ ϕ w , θ w , β w , c w ] ) = F 2 d + F p r i , \mathcal F([\phi_w,\theta_w,\beta_w,c_w])=\mathcal F^{2d}+\mathcal F^{pri}, F([ϕw,θw,βw,cw])=F2d+Fpri,其中, F 2 d \mathcal F^{2d} F2d为二维关键点重构三维关键点的代价项, F p r i \mathcal F^{pri} Fpri即先验项,它是三维姿势和形状参数保持在一个可信的空间。
实验
不同模型的速度

不同手模型的估计精度

数据集消融实验
数据增强消融实验
结论
- 设计了一个专业的同时捕捉身体和手的模型
- 提出两种集成策略
- 在手模型上精度达到的了SOTA,且提出的捕捉模型速度快于其他方法。
未来工作
- 双手交互时,手姿势估计效果不佳。
- 在估计人体姿势和手部姿势的时候,人体和手的边界框是需要的。
- 多人交互
附
论文
github