Data-to-Text Generation with Content Selection and Planning 阅读笔记
原文:https://arxiv.org/pdf/1809.00582.pdf
代码:https://github.com/ratishsp/data2text-plan-py
Abstract
数据到文本生成的最新进展已经导致使用大规模数据集和神经网络模型,这些模型是端到端训练的,没有明确地模拟说什么和按什么顺序。 在这项工作中,我们提出了一个神经网络架构,其中包含内容选择和规划,而不会牺牲端到端的培训。 我们将生成任务分解为两个阶段。 给定一组数据记录(与描述性文档配对),我们首先生成一个内容计划,突出显示应该提及哪些信息以及以何种顺序,然后在考虑内容计划的同时生成文档。 自动和基于人工的评估实验表明,我们的模型优于强基线,改善了最近发布的ROTOWIRE数据集的最新技术水平。
Introduction
输入可以是各种形式,包括记录数据库,电子表格,专家系统知识库,物理系统模拟等。 表1示出了包含NBA篮球比赛统计数据的数据库形式的示例,以及相应的比赛概要。
传统的数据到文本生成方法实现了一系列模块,包括内容规划(content planning 从某些输入中选择特定内容并确定输出文本的结构),句子规划(sentence planning 确定每个句子的结构和词汇内容)和表面实现 (surface realization将句子计划转换为表面字符串)。最近的神经生成系统没有明确地模拟这些阶段中的任何阶段,而是使用非常成功的编码器 - 解码器架构作为其主干,以端到端的方式训练它们。
神经网络生成系统的缺陷:
神经系统难以捕获长期结构并且生成多于几句长的文档。 Wiseman表明,神经文本生成技术在内容选择方面表现不佳,他们努力维持句子间的一致性,更常见的是输出文本中所选事实的合理排序。 其他挑战包括避免冗余和忠实于输入。 有趣的是,与基于模板的方法的比较表明,神经技术在内容选择召回和事实输出生成的度量上表现不佳(即,它们经常产生数据库中事实不支持的语句)。
文章解决方案:
我们通过在神经数据到文本架构中明确地建模内容选择和规划来解决这些缺点。Our model learns a content plan from the input and conditions on the content plan in order to generate the output document (see Figure 1 for an illustration).
三个优点:
它代表了文档结构的高级组织,使解码器能够专注于更轻松的句子规划和表面实现任务; 它通过生成中间表示使得数据到文档生成的过程更具有解释性; 并减少输出中的冗余,因为内容计划不太可能在多个位置包含相同的信息。
Problem Formulation
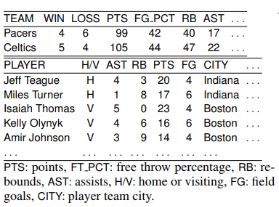


图2显示了我们模型的整体架构,它包括两个阶段:(a)内容选择和规划对数据库的输入记录进行操作,并生成一个内容计划,指定哪些记录将在文档中以及以何种顺序进行语言描述( 见表2);(b)文本生成产生输出文本给定内容计划作为输入; 在每个解码步骤中,生成模型参与内容计划中的记录的向量表示。
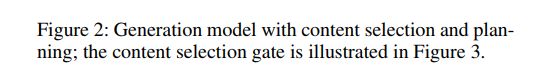

Record Encoder
我们模型的输入是一个无序记录表,每个记录表示为特征。 在之前的工作之后,我们将特征嵌入到向量中,然后使用多层感知器获得每个记录的向量表示:
[;] 代表了向量拼接,是参数。
Content Selection Gate
记录的上下文可用于确定其对表中其他记录的重要性。 例如,如果玩家得分很多,很可能会在输出摘要中提及其他有意义的相关记录,例如场地目标,三分球或篮板。 为了更好地捕获记录之间的依赖关系,我们使用了内容选择门机制,如图3所示。
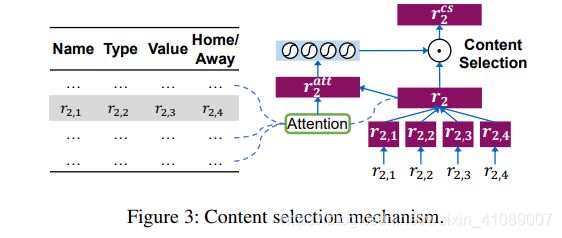

Content Planning
我们假设生成将受益于明确的计划,该计划既指定了“what to say”又指定“in which order”。我们可以根据信息提取方法(我们在第4节中解释)相对直接地获得这些方法。
可以说通过将摘要中的文本映射到输入表中的实体,它们的值和类型(即,关系)来提取计划。

Text Generation
The probability of output text y conditioned on content plan z and input table r is modeled as:
我们使用带注意力机制的编码-解码器机制来计算。
我们首先使用一个双向LSTM将内容计划z编码进。因为内容计划是输入记录的序列,我们直接将相应的记录向量作为输入提供给LSTM单元,LSTM单元与第一阶段共享记录编码器。
文本解码器也是基于LSTM单元的。解码器被编码器的最终隐状态所初始化。在解码的第t步,LSTM单元的输入是上一个预测的单词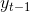 。用
。用 表示当前时刻LSTM单元的隐状态,从输出词汇表预测
表示当前时刻LSTM单元的隐状态,从输出词汇表预测 的概率通过以下方式计算:
的概率通过以下方式计算:
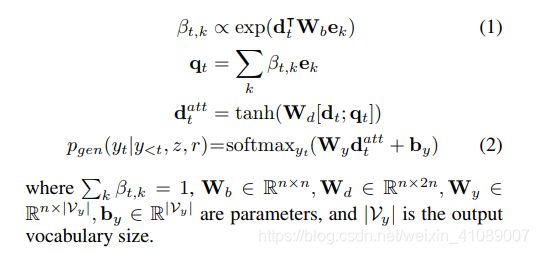
接着我们使用一个拷贝机制来增强解码器,即,能够直接从内容计划中的记录的值部分复制单词。我们尝试了联合和条件复制方法。 具体地,我们为每个时间步引入变量ut∈{0,1}以指示预测的标记yt是被复制(ut = 1)或不是(ut = 0)。生成yt的概率通过以下公式计算:
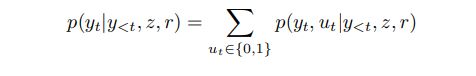
其中ut被边缘化了。
Joint Copy 从记录值复制和从词汇表生成的概率是全局标准化的:
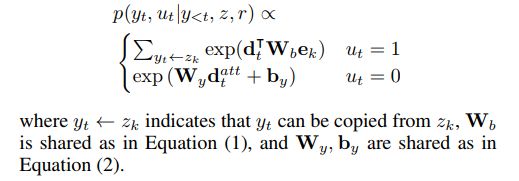
Conditional Copy 首先将变量ut计算为开关门,然后用于获得输出概率:

Training and Inference
我们的模型经过训练,可以根据表记录最大化最优内容计划的对数似然函数以及根据内容计划和表记录最大化最优输出文本的对数似然函数:

D代表训练样本(输入表格,计划,比赛摘要)。在推理期间,输入r的输出通过以下方式预测:
z'和y'分别代表content plan和output text的候选。对于每个阶段,我们利用集束搜索来近似获得最佳结果。
Experiment Setup
Data ROTOWIRE,Train 3398,Test 728,Valiadation 727。
Content Plan Extraction
我们使用一种信息抽取(information extraction,IE)技术来从ROTOWIRE比赛摘要中抽取content plan。我们使用了Wiseman等人中引入的IE系统,该系统识别出现在文本中的候选实体(即,玩家,团队和城市)和价值(即数字或字符串)对,然后预测每个候选对的类型(关系)。 For instance, in the document in Table 1, the IE system might identify the pair “Jeff Teague, 20” and then predict that their relation is “PTS”, extracting the record (Jeff Teague,20, PTS)。
Wiseman等人(2017)通过确定可以表示实体的词跨(即,通过将它们与数据库中的玩家,团队或城市匹配)和数字来训练ROTOWIRE上的IE系统。 然后,他们考虑同一句子中的每个实体 - 数字对,并且如果数据库中存在具有匹配实体和值的记录,则为该对分配相应的记录类型否则给出标签“无”以指示不相关的对。
我们采用了他们的IE系统架构,通过集成3个卷积模型和3个双向LSTM模型来预测关系。 我们在ROTOWIRE语料库的训练部分训练了这个系统。 在保留的数据上,它达到了94%的准确率,并召回了大约80%的记录许可关系。 给定IE系统的输出,内容计划仅包括(实体,值,记录类型,h / v)元组在游戏摘要中的出现顺序(表1中的摘要的内容计划显示在表2中)。 玩家姓名经过预处理,以表明个人的名字和姓氏(见表2中的Isaiah和Thomas); 球队记录也经过预处理,以表明球队城市的名称和球队本身(见表2中的波士顿和凯尔特人队)。
Training Configuration
embedding and LSTM hidden layers:600;
one-layer pointer networks during content planning, and two-layer LSTMs during text generation;
Dropout:0.3 Adam optimizer 25epoch lr: 0.15 lr decay{0.5,0.97} batch size 5