【论文笔记】Learned Fusion: 3D Object Detection using Calibration-Free Transformer Feature Fusion
原文链接:https://arxiv.org/abs/2312.09082
1. 引言
目前的3D目标检测一来传感器的校准信息。这种情况下,校准信息需要及其精确,但在产品尺度上,获取高质量校准信息是很困难的(需要逐传感器校准,且运行过程中可能会变化)。
本文基于Transformer,提出无需校准信息的传感器融合方法。
3. 方法
从基于Transformer的方法中直接移除校准信息会导致训练困难。
3.1 TransFuseDet
本文的模型包含融合编码器、上采样和任务头。使用两个ResNet分别编码激光雷达和相机的特征,然后在不同特征尺度上使用Transformer融合,类似TransFuser。但不同的是,本文最后没有合并两个特征图。
然后使用CenterNet风格的检测器,分别在激光雷达BEV特征图和图像前视特征图上进行2D检测。
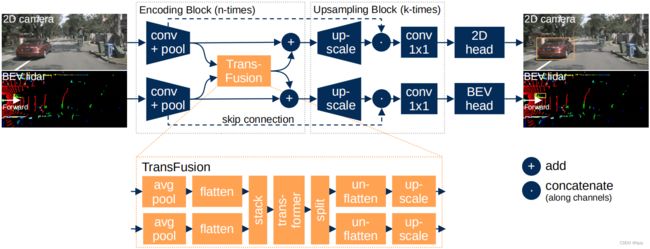
3.2 特征提取:通过Transformer提取多视图特征
首先对输入特征进行池化、拉直和拼接。通过Transformer后,将输出向量分割、变形和上采样,以便与输入特征相加。
此外,还引入上采样以避免融合编码器的最终输出分辨率太低。具体来说,将输出特征上采样并与之前的高分辨率特征拼接,再通过 1 × 1 1\times1 1×1卷积。
3.2.1 Transformer能实现无需校准融合的特性
传统的融合需要校准信息来将图像和激光雷达下物体的位置进行关联,本文使用注意力机制来关联相似特征。
具体来说,若某物体在图像特征图的 x I x_I xI处,在激光雷达BEV特征图的 x L x_L xL处,则其特征 f x I f_{x_I} fxI与 f x L f_{x_L} fxL应该有相似的语义,从而二者之间的注意力权重高,模型关注另一视图相应的位置。
3.2.2 融合中的池化减少计算复杂度
由于在注意力中,线性增大分辨率会使得计算量以二次方增大,因此本文在融合前将输入特征池化。
3.3 检测头
本文使用CenterNet的检测头,即为每个网格预测类别置信度、边界框和朝向角。朝向角的预测使用角度区间分类+偏移量预测的方法。
热图损失使用均方误差(MSE),并按前景(下标fg)与背景(下标bg)分开计算:
L h e a t = w f g L m s e , f g + w b g L m s e , b g L_{heat}=w_{fg}L_{mse,fg}+w_{bg}L_{mse,bg} Lheat=wfgLmse,fg+wbgLmse,bg
边界框与朝向角损失仅对有边界框的网格计算,其中前者为smooth L1损失,后者为交叉熵损失(角度区间分类)+Smooth L1损失(偏移量回归)。
2D检测作为辅助任务,其损失函数与前面类似,只是不含朝向角损失。
3.4 实施细节
对图像和激光雷达点云使用水平翻转增广。
4. 评估
本文使用nuScenes数据集,数据包含单帧未积累激光雷达点云和前后相机的图像。
4.1 相对单一传感器的优势
与仅使用本文方法单一分支的单一模态模型相比,本文的融合方法有更高的性能。其中图像单一模态前视2D目标检测性能的下降,比激光雷达单一模态的BEV目标检测性能的下降更低。这是因为图像通常足以进行2D检测。
但与基于校准的方法相比,本文的性能仍有较大差距。这是因为本文的模型较小,且方法做了很多简化,没有使用一些常用技巧。
4.2 融合层数
实验表明,在大于2个尺度进行融合对提高性能无积极影响,且可视化表明低级特征融合的注意力热图值很低且不集中。这可能是低级特征缺乏抽象性。
4.3 传感器偏移或旋转
为了验证本文方法对传感器偏移或旋转的鲁棒性,本文将输入随机旋转和平移。随机平移较大距离和旋转较大角度仅会导致性能的略微下降。即便是数米级别的平移,性能下降也有限。
4.4 损失和任务权重
实验表明,对于2D检测任务与BEV检测任务的损失权重而言,较大的BEV检测任务能提高性能,但过高会因为2D检测的辅助作用减弱而降低性能。
对于检测任务的热图与边界框权重,较大的热图权重能提高性能,因为准确的位置对检测最重要,而大小对同类物体而言差距不大。
4.5 注意力图分析
可视化注意力图表明,模型关注有物体的区域,且不同模态同一物体所在区域的相互响应较高。
5. 结论
5.1 局限性
由于全局注意力的使用,模型复杂度较高。此外,大型模型的训练会不稳定,这可能是由于训练初期的特征关联不稳定。