csSEnet注意力网络
csSEnet注意力网络
- 一、cSE网络模型(通道注意力机制)
-
- 1、Squeeze
-
- 全局平均池化(Global Average Pooling)
- 2、Excitation
- 3、完整CSE block的Pytorch实现
- 总结
- 二、sSE模块
- 三、scSE模块
一、cSE网络模型(通道注意力机制)
通道注意力机制:就是对于每个channel赋予不同的权重,比如1,2处马的形状比较明显,所以理所当然,对1,2通道的权重比较大,3,4处权重小。
CSEnet的模型结构,该注意力机制主要分为三部分:挤压(squeeze)、激励(excitation)、注意(scale)
计算机视觉研究领域的一个核心理论就是如何提高网络的表现力使其关注到图片的关键位置,从而提升网络性能。与一般网络通过空间维度优化不同,SENet(Squeeze-and-Excitation Networks)着手于优化channel维度,通过引入注意力机制,增加少量参数,使模型可以更好地获取不同channel上的特征,从而提高准确率。
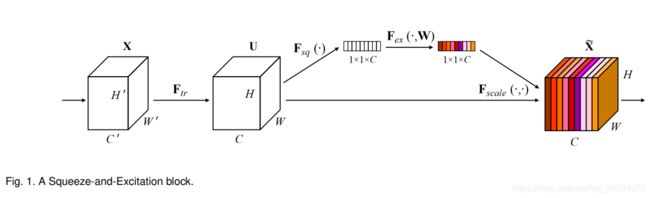
SE(Squeeze-and-Excitation),顾名思义:压缩-激活网络。如上图所示,输入X是C’×H’×W’的张量,经过卷积操作生成feature map U为C×H×W,对feature map进行压缩-激活操作。保留通道数C不变,将H×W变成1×1,接下来通过一系列激活操作,最后再将激活后的结果与U对位相乘得到最后的结果。那么S和E过程具体是如何操作的呢?
1、是squeeze操作,从空间维度进行特征压缩,将h * w * c的特征变为1 * 1* c的特征,得到向量某种程度上具有全域性的感受野,并且输出的通道数和输入的特征通道数相匹配,它表示在特征通道上响应的全域性分布。操作简单,全局平均池化
2、是excitation操作,通过引入w参数来为每个特征通道生成权重,其中w就是一个多层感知器,是可以学习的,中间经过一个降维,减少参数量。并通过一个sogmoid函数获得0——1之间归一化的权重,完成显式建模特征通道数间的相关性
3、是sacle操作,将excitation的输出的权重看作是经过选择后的每个特征通道的重要性,通过通道宽度相乘加权到先前特征上,完成在通道维度上的对原始特征的重构
1、Squeeze
将C×H×W的Feature map变为C×1×1大小。保留通道数不变,改变分辨率用的是池化操作,根据文章
此处为Global pooling。Pytorch实现如下:
self.avg_pool = nn.AdaptiveAvgPool2d((1,1) ) # 自适应池化,指定池化输出尺寸为 1 * 1
该步骤的目的是获取全局信息
作用:如果要预测K个类别,在卷积特征抽取部分的最后一层卷积层,就会生成K个特征图,然后通过全局平均池化就可以得到 K个1×1的特征图,将这些1×1的特征图输入到softmax layer之后,每一个输出结果代表着这K个类别的概率(或置信度 confidence),起到取代全连接层的效果
全局平均池化(Global Average Pooling)
定义:将特征图所有像素值相加求平局,得到一个数值,即用该数值表示对应特征图。
目的:替代全连接层
效果:减少参数数量,减少计算量,减少过拟合
思路:如下图所示。假设最终分成10类,则最后卷积层应该包含10个滤波器(即输出10个特征图),然后按照全局池化平均定义,分别对每个特征图,累加所有像素值并求平均,最后得到10个数值,将这10个数值输入到softmax层中,得到10个概率值,即这张图片属于每个类别的概率值。
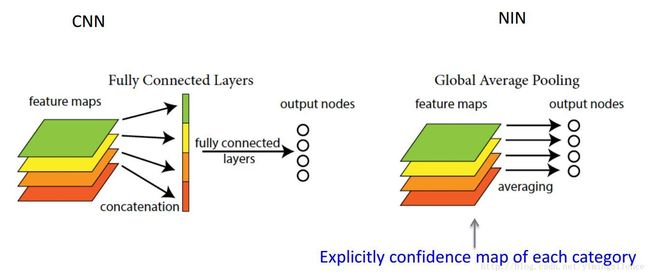
意义:对整个网络从结构上做正则化防止过拟合,剔除了全连接层黑箱子操作的特征,直接赋予了每个channel实际的类别意义。
2、Excitation
经过一系列激活操作,但不改变操作前后的大小和通道数。具体如何实现见下图:
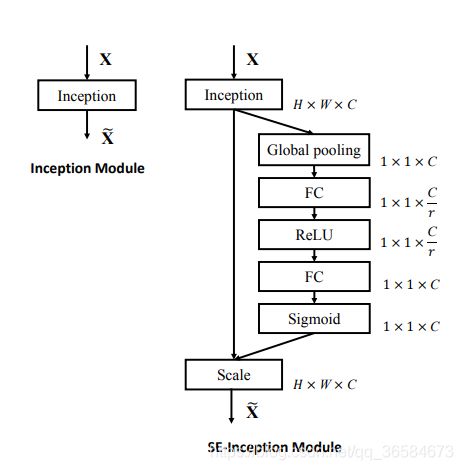
如图片右侧结构所示:Excitation为:FC→ReLU→FC→Sigmoid
具体细节如下:FC为一个全连接层Linear(C, C/r)将特征压缩到C/r通道(r为reduction是通道压缩倍率,一般取16可以平衡准确率和模型复杂性,详见论文6.1节),然后使用ReLU,接着再用一个FC层Linear(C/r, C)将特征还原至C通道,最后使用一个Simoid函数激活 Pytorch实现如下:
self.excitation = nn.Sequential(
nn.Linear(channel,channel//16,bias=False),
nn.ReLU(),
nn.Linear(channel//16,channel,bias=False),
nn.Sigmoid()
)
该步骤的目的是:Adaptive Recalibration(适合的再校准),重新校准特征,让上一步操作获得的通道信息特征相互响应
3、完整CSE block的Pytorch实现
import torch
import torch.nn as nn
class cSE_Module(nn.Module):
def __init__(self, channel,ratio = 16):
super(cSE_Module, self).__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
self.excitation = nn.Sequential(
nn.Linear(in_features=channel, out_features=channel // ratio),
nn.ReLU(inplace=True),
nn.Linear(in_features=channel // ratio, out_features=channel),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size() #1,16,64,64
y = self.squeeze(x).view(b, c) #1,16
z = self.excitation(y).view(b, c, 1, 1) #1,16,1,1
return x * z.expand_as(x) # y.expand_as(x) 把y变成和x一样的形状1,16,64,64
总结
1.专注网络的channel关系,而不是空间关系
2.Squeeze建立channel间的依赖关系;Excitation重新校准特征。二者结合强调有用特征抑制无用特征。
3.能有效提升模型性能,提高准确率。几乎可以无脑添加到backbone中。根据论文,SE block应该加在Inception block之后,ResNet网络应该加在shortcut之前,将前后对应的通道数对应上即可
二、sSE模块

空间注意力:
空间注意力是对64个通道进行mean的一个操作,得到一个(w x h)的权重,mean的操作就学到了所有通道的整体分布,而抛弃了奇异的通道。比如说1,2的图可以很好的描绘出马的形状,而3,4就不行(但本质上它也是要显示出马的形状),但是通过mean后,得到的w x h权值共享后,给了3,4一定的权值描述,相当于给3,4一定的注意力,这样它们也可以描绘出马的形状。
上图是空间注意力机制的实现
1、直接对feature map使用1×1×1卷积, 从[C, H, W]变为[1, H, W]的features
2、然后使用sigmoid进行激活得到spatial attention map
3、然后直接施加到原始feature map中,完成空间的信息校准
代码:
class sSE_Module(nn.Module):
def __init__(self, channel):
super(sSE_Module, self).__init__()
self.spatial_excitation = nn.Sequential(
nn.Conv2d(in_channels=channel, out_channels=1, kernel_size=1,stride=1,padding=0),
nn.Sigmoid()
)
def forward(self, x):
z = self.spatial_excitation(x)
return x * z.expand_as(x)
三、scSE模块

代码:
import torch
import torch.nn as nn
import torchvision
class cSE_Module(nn.Module):
def __init__(self, channel,ratio = 16):
super(cSE_Module, self).__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
self.excitation = nn.Sequential(
nn.Linear(in_features=channel, out_features=channel // ratio),
nn.ReLU(inplace=True),
nn.Linear(in_features=channel // ratio, out_features=channel),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.squeeze(x).view(b, c)
z = self.excitation(y).view(b, c, 1, 1)
return x * z.expand_as(x)
class sSE_Module(nn.Module):
def __init__(self, channel):
super(sSE_Module, self).__init__()
self.spatial_excitation = nn.Sequential(
nn.Conv2d(in_channels=channel, out_channels=1, kernel_size=1,stride=1,padding=0),
nn.Sigmoid()
)
def forward(self, x):
z = self.spatial_excitation(x)
return x * z.expand_as(x)
class scSE_Module(nn.Module):
def __init__(self, channel,ratio = 16):
super(scSE_Module, self).__init__()
self.cSE = cSE_Module(channel,ratio)
self.sSE = sSE_Module(channel)
def forward(self, x):
return self.cSE(x) + self.sSE(x)
if __name__=='__main__':
# model = cSE_Module(channel=16)
# model = sSE_Module(channel=16)
model = scSE_Module(channel=16)
print(model)
input = torch.randn(1, 16, 64, 64)
out = model(input)
print(out.shape)