python生成器的原理和业务场景下的使用
最近接触到了python生成器的具体使用场景,很有必要对之进行总结,下面就python生成器的原理和业务场景下的使用做一个简单的分析和记录。
目录
一、什么是生成器
二、生成器的实现和优点
2.1生成器表达式
2.2生成器函数
2.3 生成器的优点
三、生成器的应用实战
四、可迭代对象、迭代器和生成器
4.1可迭代对象(iterable)
4.2迭代器(iterator)
4.3生成器generator
五、yield关键字
一、什么是生成器
Python中有一种机制或者类型,它能够实现循环过程中,在有需要的时候进行生成做后续处理的一种机制——这个就是generator——生成器。
print(g)
print(type(g))
*******************
at 0x7f02713e8a50>
如在代码中输出的形式,这个时候我们就称g是生成器。
二、生成器的实现和优点
我们已经知道了生成器的一个模糊的定义,那么生成器是如何实现的呢?在Python中,常常有2种方式。
2.1生成器表达式
"""
计算1到5之间数的平方
"""
(ele*ele for ele in range(1,6))
如上面的代码中,()这种类似[]列表的表达式,最后生成的结果就是一个生成器——生成器表达式。遍历的时候一般都是直接使用for循环来遍历的,假如使用next(),会在结尾的时候抛出一个停止的异常,这种遍历方式就不太友好。直接for循环:
"""
计算1到5之间数的平方
"""
s = (ele*ele for ele in range(1,6))
print(s)
#生成器的遍历
for ele in s:
print(ele)结果如下:

2.2生成器函数
生成器函数这里和普通函数有一些差别,普通函数在返回值的时候,使用的return关键字,而在生成器函数中就是用的是yield关键字。可以理解为,只要函数中有yield关键字那么该函数就是一个生成器函数。
"""
生成器函数
"""
def produce_generator():
temp = []
for ele in range(1,5):
s = list(range(1,ele+1))
temp.extend(s)
if len(temp)>=3:
yield temp
temp = []代码中的produce_generator()就使用了yield关键字,这里的含义就是每当程序执行到yield的时候,程序就暂停在这里,处于挂起状态,有点JAVA中多线程的挂起的意味。然后把返回的东西返回以后,再继续执行原来的程序,不是重新开始,而是接着暂停的地方继续执行,有点断点续传的意味。
那么这个生成器函数返回的东西也是需要for循环遍历,才能获取到其中的值的。
"""
生成器函数
"""
def produce_generator():
temp = []
for ele in range(1,5):
s = list(range(1,ele+1))
temp.extend(s)
if len(temp)>=3:
yield temp
temp = []
gen = produce_generator()
print(gen)
#生成器遍历
for ele in gen:
print(type(ele))
print(len(ele))
print(ele)
print('*'*len(ele))遍历结果如下:

2.3 生成器的优点
就上而言,看了生成器的定义和实现方式,那么生成器到底具有什么样的优点呢?
首先从代码可读性上来说,有人说合理使用生成器会增加代码的可读性,但是我个人觉得,这个几乎算不上生成器的优点。当然我也不认为生成器能增加代码的可读性,不管是生成器表达式还是生成器函数,感觉并没有和其他非生成器在代码可读性上有什么不一样。
那么优点我认为就是生成器在没有牺牲很多的速度情况下,释放了内存,再一定的业务场景下,支持大数据的操作。举例,上代码:
if __name__ == '__main__':
a = []
for i in tqdm(range(100000000)):
temp = ['你好']*2000
a.append(temp)
for ele in a:
continuelist a得到结果后,做下游处理——下游处理的时候应该是单次处理的。这里是1亿词次循环,每次往list a中添加一个list元素,这样最后的结果是list a非常巨大,消耗内存就要爆炸呀。如图:

可以看到32G内存已经占用了80%左右的内存,而数据才跑了1%。这里就可以使用生成器来解决这个问题——这个就是生成器的核心优势——不一次全部把数据加载进来,在需要的时候才加载进来。这样就能够避免大量的内存消耗,当然这里肯定是有一部分速度的损失的。
那么改用生成器来实现
def get_list_element():
for i in tqdm(range(100000000)):
temp = ['你好']*2000
yield temp
if __name__ == '__main__':
a = get_list_element()
for ele in a:
# print(ele)
continue看看运行内存情况:

可以看到数据运行了27%,内存占用还是4G,没有增大。这就使得这个程序能够正常的运行下去,而不用生成器的话就会导致内存爆炸,从而程序中断,电脑卡死。
三、生成器的应用实战
OK,来感受一下,实战的魅力!
场景需求
一个保存了400W条分词后的中文文本数据的文件,每条数据大概200-400个词,电脑内存32G,现在需要统计词频,用做后续算法的处理。
这个问题该怎么处理呢?我理解到的方法,就是很简单直接用生成器,然后喂给Collection.Counter()就可以统计出词频了,也恰好Collection.Counter()支持生成器输入。
上代码:
def get_sentence_words(path):
files = os.listdir(path)
for file in files:
file_path = os.path.join(path, file)
with open(file_path, 'r') as f:
for line in tqdm(f, desc='read sentence_cuts'):
line = line.strip().split(' ')
for word in line:
yield word
if __name__ == '__main__':
words_gen = get_sentence_words('data_set/sentence_cut')
weight_dict = Counter(words_gen)
print('len(weight_dict)',len(weight_dict))
total = 0
for v in weight_dict.values():
total += v
print('total words is %d'% total)看结果显示:

可以看到490W条数据84秒读完,总计4.17亿词,去重还剩下91W词。内存也没有爆炸
四、可迭代对象、迭代器和生成器
在Python中,这三个概念还是容易混淆的,很有必要做一个学习总结。
4.1可迭代对象(iterable)
什么是可迭代对象,简单的理解就是可以用作for循环上的一些对象就是可迭代对象。常见的可以迭代对象有哪些呢?
列表、元组、字典、集合字符串和open()打开的文件
从代码角度来说,对象内部实现了__iter__()方法或者实现了__getitem__()的方法。
4.2迭代器(iterator)
迭代器是相对于可迭代对象(iterable)来说的,迭代器是继承了可迭代对象的。它相对于It而able而言,它实现了__iter__()和__next()__方法。另外,迭代器不会一次性把所有的元素都加载到内存中,只是在需要的时候才返回结果。可以把一个可迭代对象通过一定的方法转变为迭代器。
pro_lau = ['Python','Java','C++'] # 列表是一个可迭代对象
a = iter(pro_lau) # 由可迭代对象的iter方法返回一个迭代器4.3生成器generator
生成器就是一种特殊的迭代器,可以由关键字yield来实现;同时迭代器并不是生成器,因为迭代器并没有生成器的部分功能,如数据传入功能。
总之迭代器和生成器在一定的功能上具有很高的相似性,都能起到节约内存的作用——就这个特点,就值得我们去学习,然后应用到编程中。
最后附上一张图,来自博客——Python中的可迭代对象、迭代器和生成器的异同点
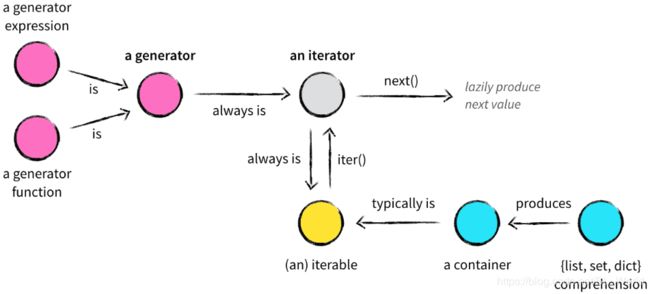
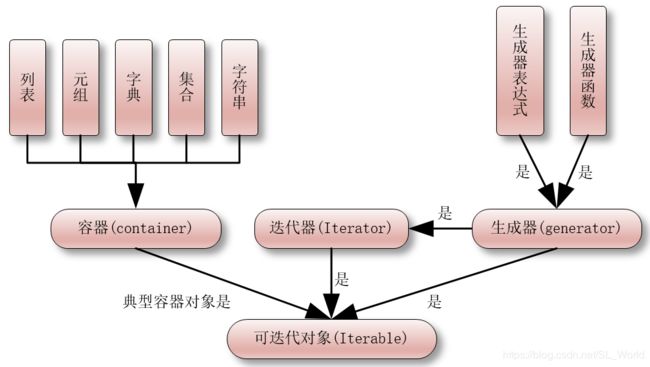
五、yield关键字
这个知识点对我来说感觉有点冷门,我也是第一次看到生成器了才遇到它。语义上,屈服让步,产出等,我的理解它的作用就是让步,让某个任务先执行。常见的一些用途和用法主要有以下4个:
1、形成生成器
2、协程
3.上下文管理器
4、yield from
推荐知乎上有关yield关键字的一个全面的回到——Python 的关键字 yield 有哪些用法和用途?