Go语言基础结构 —— Slice 切片
在Go语言中,切片(Slice)是一种数据结构,它是对数组一个连续片段的引用,这个数组称为切片的底层数组。
切片和数组的关系是非常紧密的。在Go语言中,数组是一个固定长度的序列,而切片则是一个可变长度的序列。切片是建立在数组之上的,它提供了动态数组的功能,可以根据需要动态地增加或缩小切片的长度。
基本使用
切片(Slice)是Go语言中非常重要的数据结构之一,它常用于对数组进行操作,提供了方便的动态扩容、切片、追加等操作。下面是一些切片的使用方法和场景,以及相应的Go语言代码示例。
-
切片声明与创建
切片类型的声明方式与数组有一些相似,不过由于切片的长度是动态的,所以声明时只需要指定切片中的元素类型,如下所示:
var s []int // 声明一个整型切片 var s1 []string // 声明一个字符串切片一个切片在初始化之前为空切片(
nil),长度为0,可以在声明切片时直接初始化切片,如下表示声明一个int切片,初始化值为{1, 2, 3}:s :=[]int {1, 2, 3}我们还可以使用
make函数来创建一个指定长度和容量的切片。make的第一个参数为切片类型;第二个参数为切片长度(即实际储的元素个数);第三个参数为切片容量,该参数为可选参数,如果为空则值默认为切片长度。代码示例如下:
// 创建一个长度为3、容量为5的整形切片 slice := make([]int, 3, 5) // 创建一个长度为3、容量为3的字符串切片 slice2 := make([]string, 3)我们还可以直接通过数组或切片来创建一个新的切片,新切片的长度等于从原始数组或切片中指定的开始和结束索引之间的元素个数,容量等于原始数组或切片的长度减去开始索引(
s := arr[startIndex:endIndex])。例如:// 创建一个包含5个整数的数组 arr := [5]int{1, 2, 3, 4, 5} // 创建一个从arr[1]开始到arr[3]结束的切片 slice1 := arr[1:4] // 创建一个新切片,容量等于原始切片的长度 slice2 := slice1[:]需要注意的是,当直接从另一个切片创建一个新的切片时,两个切片将共享相同的底层数组。因此,修改一个切片的元素也会影响到另一个切片。如下:
// 创建一个包含5个整数的数组 arr := [5]int{1, 2, 3, 4, 5} slice1 := arr[1:4] slice1[0] = 6 fmt.Println(arr) // 输出:[1 6 3 4 5] fmt.Println(slice1) // 输出:[6 3 4] -
访问切片元素
可以使用切片的索引操作符
[]来访问切片中的元素。切片的索引从0开始,最大值是切片长度减1。例如:// 创建一个包含3个元素的整数数组 arr := [3]int{1, 2, 3} // 创建一个包含arr[1]和arr[2]的切片 slice := arr[1:3] // 访问切片中的元素 fmt.Println(slice[0]) // 输出:2 fmt.Println(slice[1]) // 输出:3 -
切片追加元素
以使用内置的
append函数向切片中追加元素,如果切片的容量不够,则会自动扩容。例如:// 创建一个空的切片 var slice []int // 向切片中追加元素 slice = append(slice, 1, 2, 3) // 输出切片中的元素 fmt.Println(slice) // 输出:[1 2 3] // 向切片中追加元素 slice = append(slice, 4) fmt.Println(slice) // 输出:[1 2 3 4] -
切片的遍历
可以使用
for循环或者和for - range关键字来遍历切片中的元素。例如:// 创建一个包含5个整数的切片 s := []int{1, 2, 3, 4, 5} // for循环遍历切片 for i := 0; i < len(s); i++ { println(s[i]) } // for range遍历切片 for key, value := range s { println(key, value) } -
切片的复制
可以使用内置的
copy函数将一个切片中的元素复制到另一个切片中,例如:// 创建一个包含3个元素的整数数组 arr1 := [3]int{1, 2, 3} // 创建一个包含arr1[1]和arr1[2]的切片 slice1 := arr1[1:3] // 创建一个长度为2、容量为4的空切片 slice2 := make([]int, 2, 4) // 将slice1中的元素复制到slice2中 copy(slice2, slice1) // 输出slice2中的元素 fmt.Println(slice2) // 输出:[2 3] -
切片排序
可以使用
sort包中的函数对切片进行排序,例如:// 创建一个包含5个元素的整数切片 slice := []int{5, 2, 6, 3, 1} // 对切片进行排序 sort.Ints(slice) // 输出排序后的切片 fmt.Println(slice) // 输出:[1 2 3 5 6] -
切片去重
可以使用
map类型(后续讲解)实现切片去重,例如:// 创建一个包含重复元素的整数切片 slice := []int{1, 2, 3, 2, 1} // 创建一个空的map,用于存储不重复的元素 m := make(map[int]bool) // 遍历切片中的元素,并将其存储到map中 for _, v := range slice { m[v] = true } // 将map中的元素存储到一个新的切片中 newSlice := []int{} for k := range m { newSlice = append(newSlice, k) } // 输出去重后的切片 fmt.Println(newSlice) // 输出:[1 2 3]
底层实现原理
数据结构
在前面说到过切片是建立在数组之上的,就像是文件描述符之于文件。数组退居幕后,承担起底层存储空间,而切片走向前台,给开发者一个更便捷使用数组的窗口。
来看看切片的底层类型定义:
//go 1.20.3 path: /src/runtime/slice.go
type slice struct {
array unsafe.Pointer
len int
cap int
}
array是一个指向底层数组的指针,这个数组存储着切片中的元素。len表示切片的长度,即切片中元素的数量。cap表示切片的容量,即切片底层数组中可用的元素数量。
这个结构体是 Go 语言内部使用的,我们通常不会直接使用它。它表示切片的底层结构,包括底层数组的指针、切片的长度和容量。
与slice 结构体相对应的结构体是 Slice 结构体, 该结构体跟slice 结构体一致,都是来表示切片的相关信息,包括底层数组指针、切片长度和切片容量。它被用于在 Go 代码中创建和操作切片,是 Go 语言中非常常用的数据类型。它是slice 结构体对外导出的版本。
Slice 结构体定义为:
//go 1.20.3 path: /src/internal/unsafeheader/unsafeheader.go
type Slice struct {
Data unsafe.Pointer
Len int
Cap int
}
通过这个结构体,Go 语言可以方便地实现切片的各种操作,如切片的扩容、切片的复制和切片的遍历等。在使用切片时,我们通常只需要操作切片本身,而不需要关注底层的数据结构和实现细节,这正是 Go 语言的一大特点,即“隐藏实现细节”。
因为切片可以动态增加或减少元素,所以 Slice 结构体中的三个成员都是可变的,可以在运行时进行修改。同时,由于 Data 字段是一个指针类型,所以需要注意在修改 Data 所指向的数组内容时,也会影响到其他指向同一数组的切片。因此,在并发编程中,需要注意切片的并发安全性。
再来看看 SliceHeader 结构体,是一个在 reflect 包中定义的类型,它表示切片运行时(runtime)的具体表现。它的结构定义如下:
//go 1.20.3 path: /src/reflect/value.go
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
它包含了一个指向底层数组的指针(Data)、当前切片的长度(Len)以及容量(Cap)。在 Go 语言中,切片本质上是一个结构体,它底层指向一个数组,并维护着数组的长度和容量。
在某些情况下,我们需要将一个切片转换成一个指针,或者将一个指针转换成一个切片,这时候就可以使用 SliceHeader 结构体。例如,当我们需要将一个切片传递给 C 函数时,由于 C 语言中没有切片的概念,需要将切片转换成指针传递。
下面是一个使用 SliceHeader 将切片转换成指针的示例:
func Foo(ptr unsafe.Pointer, len, cap int) {
// do something with ptr, len, cap
}
func main() {
s := []int{1, 2, 3, 4, 5}
header := (*reflect.SliceHeader)(unsafe.Pointer(&s))
Foo(unsafe.Pointer(header.Data), header.Len, header.Cap)
}
在上面的例子中,我们首先使用 unsafe.Pointer 将切片的地址转换成 *reflect.SliceHeader 类型的指针。然后,我们可以使用 SliceHeader 结构体的 Data、Len 和 Cap 字段构造一个新的指针,并将它传递给 C 函数 Foo。
需要注意的是,SliceHeader 结构体一般用是来反射和修改切片的内部状态的。一般情况下,您不需要使用后者,除非您有特殊的需求。而且SliceHeader 结构体包含了一个指针类型的字段 Data,因此在使用它时需要格外小心,避免出现指针问题导致的内存泄漏或错误。
声明
在 Go 语言中,切片类型的声明方式与数组有一些相似,不过由于切片的长度是动态的,所以声明时只需要指定切片中的元素类型:
var x []int
var y []interface{}
从切片的定义我们能推测出,切片在编译期间的生成的类型只会包含切片中的元素类型,即 int 或者 interface{} 等。
所以我们需要有个对应的结构体来满足声明中的只定义类型的情况,这个切片在编译期间对应的结构体如下:
//go 1.20.3 path: /src/cmd/complie/internal/types/type.go
type Slice struct {
Elem *Type // element type
}
这个结构体的作用是用于实现动态类型的切片。在 Go 语言中,切片的元素类型是静态的,也就是说,一旦定义了切片的元素类型,就无法改变。
但是,有时候我们需要在运行时动态地确定切片的元素类型,比如需要从配置文件中读取数据类型,或者需要根据用户输入动态地选择元素类型。这时候就可以使用这个自定义的 Slice 结构体来实现。
具体地说,我们可以使用这个结构体来创建一个动态类型的切片,如下所示:
s := Slice{Elem: (*int)(nil)}
这个切片的元素类型是 int,但是在运行时可以根据需要修改元素类型,如下所示:
s.Elem = (*string)(nil)
这样就可以将元素类型修改为 string 类型。需要注意的是,由于 Go 语言是静态类型语言,因此在使用这个结构体时需要小心使用,避免出现潜在的类型错误和问题。
编译期间用于创建切片类型的函数NewSlice也使用了这个 Slice 结构体来实现切片的类型创建:
func NewSlice(elem *Type) *Type {
if t := elem.Cache.slice; t != nil {
if t.Elem() != elem {
Fatalf("elem mismatch")
}
return t
}
t := New(TSLICE)
t.Extra = Slice{Elem: elem}
elem.Cache.slice = t
return t
}
上述方法返回结构体中的 Extra 字段是一个只包含切片内元素类型的结构,也就是说切片内元素的类型都是在编译期间确定的,编译器确定了类型之后,会将类型存储在 Extra 字段中帮助程序在运行时动态获取。
初始化
Go 语言中包含三种初始化切片的方式:
-
通过下标的方式获得数组或者切片的一部分;
slice := []int{1, 2, 3, 4, 5} newSlice := slice[0:3]使用下标创建切片是最原始也最接近汇编语言的方式,它是所有方法中最为底层的一种,编译器会将
arr[0:3]或者slice[0:3]等语句转换成OpSliceMake操作,我们可以通过下面的代码来验证一下:package main func newSlice() []int { arr := [5]int{1, 2, 3, 4, 5} slice := arr[0:3] return slice } func main(){}通过
GOSSAFUNC变量编译(GOSSAFUNC=newSlice go build main.go)上述代码可以得到一系列SSA中间代码,其中slice := arr[0:3]语句在 “decompose builtin” 阶段对应的代码如下所示: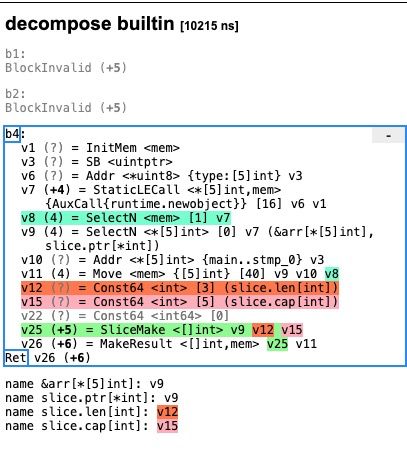
SliceMake操作会接受四个参数创建新的切片,元素类型、数组指针、切片大小和容量 ,需要注意的是使用下标初始化切片不会拷贝原数组或者原切片中的数据,它只会创建一个指向原数组的切片结构体,所以修改新切片的数据也会修改原切片。如下程序:
//创建并初始化一个slice s := []string{"a", "b", "c"} //基于slice创建一个新的slice:s1 s1 := s[0:1] //基于slice创建一个新的slice:s2 s2 := s[:] //获取s1,s2的SliceHeader结构 sc1 := (*reflect.SliceHeader)(unsafe.Pointer(&s1)) sc2 := (*reflect.SliceHeader)(unsafe.Pointer(&s2)) //输出s1,s2的底层数组指针、长度、容量 fmt.Println(sc1.Data, sc1.Len, sc1.Cap) //输出:824634322752 1 3 fmt.Println(sc2.Data, sc2.Len, sc2.Cap) //输出:824634322752 3 3从输出可以看出 两个切片的
Data属性所指向的底层数组是一致的,Len属性的值不一样,sc1和sc2分别是两个切片。为什么两个新切片所指向的
Data是同一个地址的呢?这其实是Go语言本身为了减少内存占用,提高整体的性能才这么设计的。将切片复制到任意函数的时候,对底层数组大小都不会影响。复制时只会复制切片本身(值传递),不会涉及底层数组。也就是在函数间传递切片,其只拷贝24个字节(指针字段8个字节,长度和容量分别需要8个字节),效率很高。正是因为共用了一个底层数组,所以无论修改
s、s1、s2中的任一切片,都会影响这几个切片的值,我们通过代码验证下://创建并初始化一个slice s := []string{"a", "b", "c"} //基于slice创建一个新的slice:s1 s1 := s[0:1] //基于slice创建一个新的slice:s2 s2 := s[:] s1[0] = "d" fmt.Println(s, s1, s2) //输出 [d b c] [d] [d b c] -
使用字面量初始化新的切片;
slice := []int{1, 2, 3}当我们使用字面量
[]int{1, 2, 3}创建新的切片时,cmd/compile/internal/gc.slicelit函数会在编译期间将它展开成如下所示的代码片段:var vstat [3]int vstat[0] = 1 vstat[1] = 2 vstat[2] = 3 var vauto *[3]int = new([3]int) *vauto = vstat slice := vauto[:]-
根据切片中的元素数量对底层数组的大小进行推断并创建一个数组;
-
将这些字面量元素存储到初始化的数组中;
-
创建一个同样指向
[3]int类型的数组指针; -
将静态存储区的数组
vstat赋值给vauto指针所在的地址; -
通过
[:]操作获取一个底层使用vauto的切片;
第 5 步中的
[:]就是使用下标创建切片的方法,从这一点我们也能看出[:]操作是创建切片最底层的一种方法。 -
-
使用关键字
make创建切片;slice := make([]int, 3, 3) slice1 := make([]int, 3)当我们使用
make关键字创建切片时,当使用make初始化一个切片时,会被编译器解析为一个OMAKESLICE操作:// go1.20.3 path:/src/cmd/compile/internal/walk/expr.go func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node { switch n.Op() { ...... case ir.OMAKESLICE: n := n.(*ir.MakeExpr) return walkMakeSlice(n, init) ...... } }OMAKESLICE操作主要调用了walkMakeSlice函数:// go1.20.3 path:/src/cmd/compile/internal/walk/builtin.go func walkMakeSlice(n *ir.MakeExpr, init *ir.Nodes) ir.Node { //获取切片的长度 l := n.Len //获取切片的容量 r := n.Cap //如果容量为空,那么容量等于长度 if r == nil { r = safeExpr(l, init) l = r } // 获取切片的类型 t := n.Type() // 判断元素类型是否不能在堆上分配内存 if t.Elem().NotInHeap() { base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", t.Elem()) } //如果切片的逃逸状态为EscNone,即不逃逸,在栈上分配内存 if n.Esc() == ir.EscNone { // 如果逃逸状态为EscNone,但是切片的逃逸状态为EscHeap,那么报错 if why := escape.HeapAllocReason(n); why != "" { base.Fatalf("%v has EscNone, but %v", n, why) } //获取切片容量的值 i := typecheck.IndexConst(r) if i < 0 { base.Fatalf("walkExpr: invalid index %v", r) } /** 检查切片长度和容量是否合法,不合法则报错 */ //判断切片的长度是否大于容量 nif := ir.NewIfStmt(base.Pos, ir.NewBinaryExpr(base.Pos, ir.OGT, typecheck.Conv(l, types.Types[types.TUINT64]), ir.NewInt(i)), nil, nil) //判断切片的长度是否小于0 niflen := ir.NewIfStmt(base.Pos, ir.NewBinaryExpr(base.Pos, ir.OLT, l, ir.NewInt(0)), nil, nil) niflen := ir.NewIfStmt(base.Pos, ir.NewBinaryExpr(base.Pos, ir.OLT, l, ir.NewInt(0)), nil, nil) //如果切片长度小于0,那么报错 niflen.Body = []ir.Node{mkcall("panicmakeslicelen", nil, init)} //如果切片的容量小于长度,那么报错 nif.Body.Append(niflen, mkcall("panicmakeslicecap", nil, init)) init.Append(typecheck.Stmt(nif)) //构造一个数组,类型为 [r]T t = types.NewArray(t.Elem(), i) //生成一个临时变量,类型为 [r]T var_ := typecheck.Temp(t) //将临时变量赋值为nil appendWalkStmt(init, ir.NewAssignStmt(base.Pos, var_, nil)) // zero temp //构造一个切片表达式,arr[:l] r := ir.NewSliceExpr(base.Pos, ir.OSLICE, var_, nil, l, nil) // arr[:l] //递归调用walkExpr,将切片表达式转换为语句 return walkExpr(typecheck.Expr(typecheck.Conv(r, n.Type())), init) } //获取切片的长度和容量 len, cap := l, r //默认调用makeslice64函数 fnname := "makeslice64" //默认参数类型为int64 argtype := types.Types[types.TINT64] // 如果 len 和 cap 都是 ideal 类型(即编译器无法确定其具体类型),或者它们的大小小于或等于 uint 类型的大小,那么它们可以被转换为 int 类型,并用于调用 makeslice 函数 if (len.Type().IsKind(types.TIDEAL) || len.Type().Size() <= types.Types[types.TUINT].Size()) && (cap.Type().IsKind(types.TIDEAL) || cap.Type().Size() <= types.Types[types.TUINT].Size()) { fnname = "makeslice" argtype = types.Types[types.TINT] } // 根据函数名查找对应的runtime函数 fn := typecheck.LookupRuntime(fnname) // 调用runtime函数进行slice初始化 ptr := mkcall1(fn, types.Types[types.TUNSAFEPTR], init, reflectdata.MakeSliceElemRType(base.Pos, n), typecheck.Conv(len, argtype), typecheck.Conv(cap, argtype)) // 标记slice的底层数组不为nil ptr.MarkNonNil() // 转换slice的长度为int类型 len = typecheck.Conv(len, types.Types[types.TINT]) // 转换slice的容量为int类型 cap = typecheck.Conv(cap, types.Types[types.TINT]) // 构造slice的头部信息 sh := ir.NewSliceHeaderExpr(base.Pos, t, ptr, len, cap) // 返回对slice头部信息的处理结果 return walkExpr(typecheck.Expr(sh), init) }该函数的主要作用是用于构造切片类型的节点,其流程如下:
- 首先获取切片的长度和容量,并且默认切片的容量为切片的长度。
- 判断切片的元素类型是否为无法被分配到堆上的类型,如果是则会报错。
- 判断切片的逃逸分析结果,如果逃逸结果为
EscNone,则判断切片长度是否为常量,如果是常量则获取切片长度的值并进行合法性检查,如果不是常量则会panic报错。同时将切片容量转化为整型值并检查其合法性。 - 通过调用
runtime库中的makeslice或者makeslice64函数来创建切片。如果切片的长度和容量都是无类型常量或者是uint类型,则调用makeslice函数,否则调用makeslice64函数。这个过程会传入切片元素类型的信息、切片长度和容量,并返回一个unsafe.Pointer类型的指针。 - 对切片长度和容量进行类型转换,将它们转换为
types.Types[types.TINT]类型的值,同时将上述返回的指针、长度和容量使用NewSliceHeaderExpr函数构造一个新的SliceHeader类型的表达式,最后使用walkExpr函数对其进行类型检查和转换,并返回这个表达式。
切片在栈中初始化还是在堆中初始化,存在一个临界值进行判断,临界值
maxImplicitStackVarSize默认为64kb。从下面的源代码可以看到,显式变量声明explicit variable declarations和隐式变量implicit variables逃逸的临界值并不一样。来看代码:
// go 1.20.3 path :/src/cmd/compile/internal/ir/cfg.go var ( // MaxStackVarSize is the maximum size variable which we will allocate on the stack. // This limit is for explicit variable declarations like "var x T" or "x := ...". // Note: the flag smallframes can update this value. MaxStackVarSize = int64(10 * 1024 * 1024) // MaxImplicitStackVarSize is the maximum size of implicit variables that we will allocate on the stack. // p := new(T) allocating T on the stack // p := &T{} allocating T on the stack // s := make([]T, n) allocating [n]T on the stack // s := []byte("...") allocating [n]byte on the stack // Note: the flag smallframes can update this value. MaxImplicitStackVarSize = int64(64 * 1024) )根据上面的注释,我们可以得出:
var x T或者x := ...方式声明定义的变量,内存逃逸的临界值为10M, 小于该值的对象会分配在栈中s := make([]T, n)或p := new(T)或p := &T{}或s := []byte("...")声明定义的变量,内存逃逸的临界值为64kb,小于该值的对象会分配在栈中
切片的
make初始化就属于s := make([]T, n)操作,当切片元素分配的内存大小大于64kb时, 切片会逃逸到堆中进行初始化。此时会调用运行时函数makeslice来完成这一个过程:// go 1.20.3 path :/src/runtime/slice.go func makeslice(et *_type, len, cap int) unsafe.Pointer { //计算 lice占用的内存大小,mem = element size * cap以及溢出检查 mem, overflow := math.MulUintptr(et.size, uintptr(cap)) // 如果溢出或者内存大小超过了 maxAlloc(最大可分配虚拟内存)或者如果len大于cap或者len小于0,则 panic if overflow || mem > maxAlloc || len < 0 || len > cap { //计算 slice 占用的内存大小,当容量不合法时会使用它来判断长度是否合法 mem, overflow := math.MulUintptr(et.size, uintptr(len)) if overflow || mem > maxAlloc || len < 0 { // slice 长度或容量不合法时 panic panicmakeslicelen() } // slice 长度或容量不合法时 panic panicmakeslicecap() } //调用mallocgc 函数分配内存 return mallocgc(mem, et, true) }上述函数的主要工作是计算切片占用的内存空间并在堆上申请一片连续的内存,它使用(内存空间 = 切片元素大小 * 切片容量)计算占用的内存:
m e m = e l e m e n t s i z e ∗ c a p mem = element size * cap mem=elementsize∗cap虽然编译期间可以检查出很多错误,但是在创建切片的过程中如果发生了以下错误会直接触发运行时错误并崩溃:
- 内存空间的大小发生了溢出;
- 申请的内存大于最大可分配的虚拟内存;
- 传入的长度小于 0 或者长度大于容量;
makeslice在最后调用的mallocgc是用于申请内存的函数,这里就不展开分析了。后续内存相关内容展开分析。
访问元素
使用 len 和 cap 获取长度或者容量是切片最常见的操作,如下:
slice := []int{1, 2, 3, 4, 5}
l := len(slice) //获取长度
c := cap(slice) //获取容量
编译器则将这它们看成两种特殊操作,即 OLEN 和 OCAP ,exprCheckPtr 函数会在 SSA 生成阶段将它们分别转换成 OpSliceLen 和 OpSliceCap:
// go 1.20.3 path: /src/cmd/compile/internal/ssagen/ssa.go
func (s *state) exprCheckPtr(n ir.Node, checkPtrOK bool) *ssa.Value {
......
switch n.Op() {
case OLEN, OCAP:
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))
......
}
......
}
}
访问切片中的字段可能会触发 “decompose builtin” 阶段的优化,len(slice) 或者 cap(slice) 在一些情况下会直接替换成切片的长度或者容量,不需要在运行时获取:
(SlicePtr (SliceMake ptr _ _ )) -> ptr
(SliceLen (SliceMake _ len _)) -> len
(SliceCap (SliceMake _ _ cap)) -> cap
除了获取切片的长度和容量之外,访问切片中元素使用的 OINDEX 操作也会在中间代码生成期间转换成对地址的直接访问,这是因为 OINDEX 操作符的语义是通过指针加偏移量来访问底层数据结构中的元素,无论是数组、切片还是映射:
func (s *state) exprCheckPtr(n ir.Node, checkPtrOK bool) *ssa.Value {
......
// 根据n的操作符进行分支
switch n.Op() {
......
//如果 n 的操作符是 OINDEX,表示切片索引访问
case ir.OINDEX:
// 将 n 转换为 IndexExpr 类型,表示一个索引表达式,例如 x[i]
n := n.(*ir.IndexExpr)
switch {
//如果 n.X 的类型为切片类型,则获取该切片的指针地址 p,并读取该地址中的元素值,作为最终的返回值
case n.X.Type().IsSlice():
p := s.addr(n)
return s.load(n.X.Type().Elem(), p)
}
......
}
......
}
复制
当我们想要完整拷贝一个切片时,可以使用内置的copy函数,效果类似于"深拷贝":
s := []string{"a", "b", "c"}
s2 := make([]string, len(s))
copy(s2, s)
fmt.Println(s) //输出 [a b c]
fmt.Println(s2) //输出 [a b c]
完整复制后,新的切片指向了新的内存地址。切片的复制在运行时会调用slicecopy()函数,通过memmove移动数据到新的内存地址:
// go 1.20.3 path: /src/runtime/slice.go
// 定义一个函数,接收两个切片的指针、长度和元素宽度,返回复制的元素个数
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
// 如果源切片或目标切片的长度为 0
if fromLen == 0 || toLen == 0 {
// 返回 0,表示没有复制任何元素
return 0
}
// 将 n 赋值为源切片的长度
n := fromLen
// 如果目标切片的长度小于 n
if toLen < n {
// 将 n 赋值为目标切片的长度
n = toLen
}
// 如果元素宽度为 0
if width == 0 {
// 返回 n,表示复制了 n 个元素,但实际上没有复制任何数据
return n
}
// 计算需要复制的数据的总大小,等于 n 乘以元素宽度
size := uintptr(n) * width
......
// 如果数据大小为 1
if size == 1 {
// 直接将源切片指针指向的字节赋值给目标切片指针指向的字节
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
// 调用 memmove 函数,将源切片指针指向的 size 大小的数据移动到目标切片指针指向的位置
memmove(toPtr, fromPtr, size)
}
// 返回 n,表示复制了 n 个元素
return n
}
相比于依次拷贝元素,runtime.memmove 能够提供更好的性能。需要注意的是,整块拷贝内存仍然会占用非常多的资源,在大切片上执行拷贝操作时一定要注意对性能的影响。
上述流程如下图:
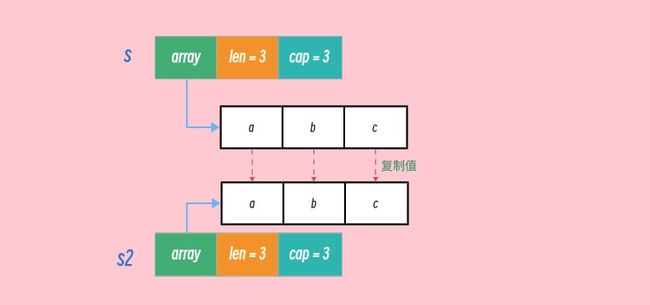
扩容
使用 append 关键字向切片中追加元素也是常见的切片操作,如下:
s := []int{1, 2, 3, 4, 5}
s = append(s, 7, 8, 9)
fmt.Println("s:", s)
//output:
s: [1 2 3 4 5 7 8 9]
在中间代码生成阶段的 /src/cmd/compile/internal/ssagen/ssa.go中的 append 方法中注释说明,根据返回值是否会覆盖原变量,选择进入两种流程:
-
append返回的新切片不需要赋值回原有的变量例如
append(s, e1, e2, e3),流程实现如下:// If inplace is false, process as expression "append(s, e1, e2, e3)": ptr, len, cap := s len += 3 if uint(len) > uint(cap) { ptr, len, cap = growslice(ptr, len, cap, 3, typ) } // with write barriers, if needed: *(ptr+(len-3)) = e1 *(ptr+(len-2)) = e2 *(ptr+(len-1)) = e3 return makeslice(ptr, len, cap)我们会先解构切片结构体获取它的数组指针、大小和容量,如果在追加元素后切片的大小大于容量,那么就会调用
runtime.growslice对切片进行扩容并将新的元素依次加入切片。
-
append返回的新切片需要赋值回原有的变量这时
/src/cmd/compile/internal/ssagen/ssa.go中的append方法会使用另一种方式展开关键字,还是以append(s, e1, e2, e3)为例子:// If inplace is true, process as statement "s = append(s, e1, e2, e3)": a := &s ptr, len, cap := s len += 3 if uint(len) > uint(cap) { ptr, len, cap = growslice(ptr, len, cap, 3, typ) vardef(a) // if necessary, advise liveness we are writing a new a *a.cap = cap // write before ptr to avoid a spill *a.ptr = ptr // with write barrier } *a.len = len // with write barriers, if needed: *(ptr+(len-3)) = e1 *(ptr+(len-2)) = e2 *(ptr+(len-1)) = e3示意图如下:
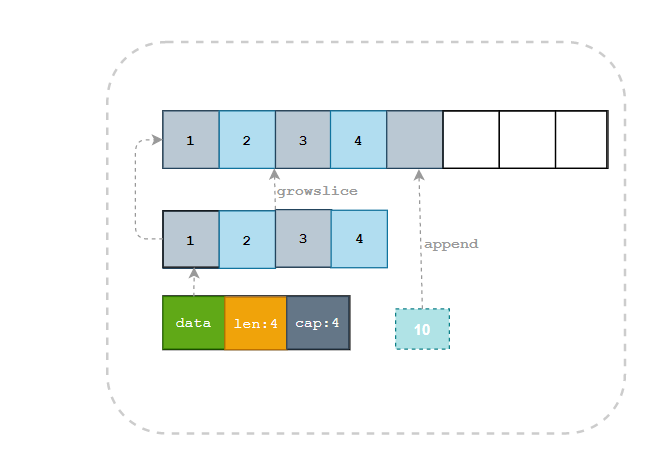
是否覆盖原变量的逻辑其实差不多,最大的区别在于得到的新切片是否会赋值回原变量。如果我们选择覆盖原有的变量,就不需要担心切片发生拷贝影响性能,因为 Go 语言编译器已经对这种常见的情况做出了优化。
到这里我们已经清楚了 Go 语言如何在切片容量足够时向切片中追加元素,不过仍然需要研究切片容量不足时的处理流程。当切片的容量不足时,我们会调用 runtime.growslice函数为切片扩容,扩容是为切片分配新的内存空间并拷贝原切片中元素的过程,我们先来看新切片的容量是如何确定的:
//go 1.20.3 path: /src/runtime/slice.go
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
// 计算旧切片的长度,等于新切片的长度减去要添加的元素个数
oldLen := newLen - num
......
// 如果新切片的长度为负数,说明溢出了,直接panic
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
//如果元素类型的大小为0,说明是空切片,直接返回一个新的切片
if et.size == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
// 定义一个新的切片容量newcap,初始值为旧切片的容量
newcap := oldCap
//定义一个新的切片doublecap,初始值为旧切片容量的两倍
doublecap := newcap + newcap
if newLen > doublecap {
//如果新切片长度大于doublecap(旧切片容量的两倍),则新切片容量为新切片长度
newcap = newLen
} else {
//否则,定义一个常量threshold,等于256
const threshold = 256
if oldCap < threshold {
//如果旧切片容量小于256,则新切片容量为(doublecap)旧切片容量的两倍
newcap = doublecap
} else {
//循环增加新切片容量,直到大于或者等于新切片长度或者溢出
for 0 < newcap && newcap < newLen {
//每次增加新切片容量的四分之一
newcap += (newcap + 3*threshold) / 4
}
//如果新切片容量小于等于0,则新切片容量等于新切片长度
if newcap <= 0 {
newcap = newLen
}
}
}
......
}
这段代码是用来扩展切片的容量的,代码的逻辑如下:
- 首先计算旧切片(
oldLen)的长度,等于新切片的长度减去要添加的元素个数(newLen - num) - 然后检查新切片的长度,为负数则则抛出异常;如果元素类型的大小为
0,则返回一个空切片 - 计算新切片的容量,根据旧切片的容量和新切片的长度来决定:
- 如果新切片的长度大于旧切片容量的两倍,则新切片的容量等于新切片的长度
- 否则,如果旧切片的容量小于一个阈值(256),则新切片的容量等于旧切片容量的两倍
- 否则,循环增加新切片的容量,每次增加四分之一左右,直到新切片的容量大于或等于新切片的长度
- 如果新切片的容量溢出,则新切片的容量等于新切片的长度
上述代码片段仅会确定切片的大致容量,下面还需要根据切片中的元素大小对齐内存,当数组中元素所占的字节大小为 1、8 或者 2 的倍数时,运行时会使用如下所示的代码对齐内存:
//go 1.20.3 path: /src/runtime/slice.go
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
......
//定义一个变量overflow,初始值为false,用来表示是否溢出
var overflow bool
//定义三个变量,分别表示旧切片、新切片、新切片的容量的内存大小
var lenmem, newlenmem, capmem uintptr
//根据元素类型的大小,计算旧切片的长度、新切片的长度、新切片的容量
switch {
/**
如果元素类型的大小为1
则旧切片长度内存大小等于旧切片长度
新切片长度内存大小等于新切片长度
新切片容量内存大小等于新容量向上取整到对齐边界
更新新容量为内存大小转换的整数类型
*/
case et.size == 1:
lenmem = uintptr(oldLen)
newlenmem = uintptr(newLen)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
/**
如果元素类型的大小等于指针的大小
则旧切片长度内存大小等于旧切片长度乘以指针的大小
新切片长度内存大小等于新切片长度乘以指针的大小
新切片容量内存大小等于新容量乘以指针的大小向上取整到对齐边界
更新新容量为新容量内存大小除以指针的大小的整数
*/
case et.size == goarch.PtrSize:
lenmem = uintptr(oldLen) * goarch.PtrSize
newlenmem = uintptr(newLen) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
/**
如果元素类型的大小是2的幂次方
*/
case isPowerOfTwo(et.size):
//定义一个变量shift,用来表示左移或者右移的位数
var shift uintptr
//主要是区分32位和64位系统
if goarch.PtrSize == 8 {
//如果指针的大小是8,则shift等于元素类型的大小转换为64位无符号整数末尾0的个数,并与63进行与运算
shift = uintptr(sys.TrailingZeros64(uint64(et.size))) & 63
} else {
//否则,shift等于元素类型的大小转换为32位无符号整数末尾0的个数,并与31进行与运算
shift = uintptr(sys.TrailingZeros32(uint32(et.size))) & 31
}
//旧切片长度内存大小等于旧切片长度左移shift位
lenmem = uintptr(oldLen) << shift
//新切片长度内存大小等于新切片长度左移shift位
newlenmem = uintptr(newLen) << shift
//新切片容量内存大小等于新容量左移shift位向上取整到对齐边界
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
//更新新容量为新容量内存大小右移shift位
newcap = int(capmem >> shift)
//更新新容量内存大小为新容量左移shift位
capmem = uintptr(newcap) << shift
/**
默认情况
旧切片长度内存大小等于旧切片长度乘以元素类型的大小
新切片长度内存大小等于新切片长度乘以元素类型的大小
新切片容量等于向上取整的新切片容量内存大小除以元素类型的大小
更新新容量内存大小为新切片容量乘以元素类型的大小
*/
default:
lenmem = uintptr(oldLen) * et.size
newlenmem = uintptr(newLen) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
capmem = uintptr(newcap) * et.size
}
//如果溢出或者新切片容量内存大小大于最大分配内存大小,则抛出异常
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}
......
}
这段代码的作用是根据新切片的长度和旧切片的容量,计算新切片的容量和内存大小,并检查是否溢出或超过最大分配限制。它根据元素类型的大小,采用不同的策略来扩展切片的容量,以提高内存利用率和性能。它是Go语言中切片的核心实现之一,对于理解和使用切片非常有意义。
代码中使用的runtime.roundupsize 函数则是会将待申请的内存向上取整,取整时会使用 runtime.class_to_size数组,使用该数组中的整数可以提高内存的分配效率并减少碎片,我们会在内存分配一节详细介绍该数组的作用:
var class_to_size = [_NumSizeClasses]uint16{
0,
8,
16,
32,
48,
64,
80,
...,
}
确认完新切片长度容量后,接下来执行下面代码:
//go 1.20.3 path: /src/runtime/slice.go
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
......
//定义一个变量p,用来表示新切片的指针
var p unsafe.Pointer
/**
如果元素类型的指针数据为0;
则调用mallocgc函数,分配新切片的内存,不指定类型,不需要扫描;
调用memclrNoHeapPointers函数,清零新切片未使用的内存部分;
否则,调用mallocgc函数,分配新切片的内存,指定类型,需要扫描;
如果旧切片的内存大小大于0,并且写屏障开启
则调用bulkBarrierPreWriteSrcOnly函数,对新旧切片的内存进行写屏障处理
*/
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(oldPtr), lenmem-et.size+et.ptrdata)
}
}
//调用memmove函数,将旧切片的内存内容复制到新切片的内存地址
memmove(p, oldPtr, lenmem)
//返回一个新的slice结构体,包含新切片的内存地址、长度和容量
return slice{p, newLen, newcap}
}
该段代码的作用是根据新切片的容量和元素类型,分配新切片的内存空间,并将旧切片的内容复制过去。它根据元素类型是否包含指针数据,采用不同的内存分配和清零策略,以提高内存安全性和效率。它还根据写屏障的状态,对新旧切片的内存进行必要的屏障处理,以保证垃圾回收的正确性。
小结
切片的使用和内部原理在Go语言中非常重要,因此有一些小结或者使用建议可以帮助我们更好地理解和使用切片,例如:
- 切片是对数组的引用,而不是复制,因此修改切片会影响底层数组。如果需要复制切片的内容,可以使用
copy函数; - 切片的长度和容量是不同的概念,长度是切片当前包含的元素个数,容量是切片可以扩展到的最大元素个数。如果需要增加切片的长度,可以使用
append函数; - 切片可以从数组或其他切片中截取,截取时需要注意起始索引和结束索引的含义。起始索引是包含在截取结果中的,结束索引是不包含在截取结果中的。如果省略起始索引,则默认为
0;如果省略结束索引,则默认为原数组或切片的长度。 - 切片可以用作函数的参数或返回值,这样可以避免复制数组的开销。但是也要注意切片可能会共享底层数组,因此可能会产生意外的副作用。
- 切片可以用来实现栈、队列等数据结构,但是要注意正确地处理内存释放和扩容问题。如果需要从切片中删除元素,可以使用
append函数来覆盖要删除的元素;如果需要扩容切片,可以使用make函数来创建一个新的切片,并复制原来的内容。
切片的很多功能都是由运行时实现的,无论是初始化切片,还是对切片进行追加或扩容都需要运行时的支持,需要注意的是在遇到大切片扩容或者复制时可能会发生大规模的内存拷贝,一定要减少类似操作避免影响程序的性能。
参考资料:
Draven https://draveness.me/golang/