面向搜索引擎优化初学者的 Google PageRank
即使你认为搜索已经摆脱了 PageRank 的影响,但时至今日,PageRank 很可能仍然存在于许多搜索巨头的系统中。

PageRank 曾经是搜索的核心,也是谷歌成为今天这个帝国的基础。
即使你认为搜索已经脱离了 PageRank,但不可否认的是,PageRank 长期以来一直是搜索行业的一个普遍概念。
每一位搜索引擎优化专家都应该很好地掌握 PageRank 的过去和现在。
本文将介绍
-
- 什么是 PageRank?
- PageRank 的发展历史。
-
- Google Dance
- Trusted Seeds
- Reasonable Surfer
- PageRank 的衰退
- PageRank 如何彻底改变搜索
- 工具栏 PageRank 与 PageRank 的对比
- PageRank 如何工作
-
- 问题与公式迭代
- PageRank 如何在页面之间流动
- PageRank 是否仍在使用?
什么是 PageRank?
PageRank 由谷歌创始人拉里-佩奇(Larry Page)和谢尔盖-布林(Sergey Brin)创建,是一种基于互联网上所有超链接的综合相对强度的算法。
大多数人认为,PageRank 这个名字是基于拉里-佩奇的姓氏,也有人认为 "Page "指的是网页。这两种说法都有可能是对的,而且这种重叠很可能是有意为之。
当佩奇和布林还在斯坦福大学就读时,他们写了一篇题为《PageRank 引用排名》的论文:为网络带来秩序》一文。
这篇论文发表于 1999 年 1 月,展示了一种相对简单的评估网页强度的算法。
这篇论文后来在美国获得了专利(但在欧洲没有,因为在欧洲数学公式不能申请专利)。
斯坦福大学拥有这项专利,并已将其转让给谷歌。目前,该专利将于 2027 年到期。
PageRank 的发展历史。
20 世纪 90 年代末,布林和佩奇在斯坦福大学就读期间,一直在研究信息检索方法。
当时,使用链接来计算每个页面相对于另一个页面的 "重要性 "是一种革命性的页面排序方法。这种方法在计算上很困难,但绝非不可能。
这个想法很快变成了谷歌,而当时的谷歌还是搜索领域的一条小鱼。
一些方面对谷歌的做法深信不疑,以至于谷歌在推出搜索引擎之初,并不具备赚取收入的能力。
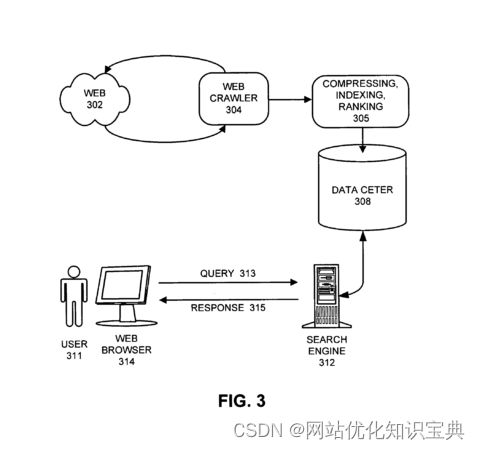
谷歌(当时被称为 “BackRub”)是搜索引擎,而 PageRank 则是它用来在搜索引擎结果页面(SERPs)中对网页进行排名的算法。
Google Dance
PageRank 面临的挑战之一是,计算虽然简单,但需要反复处理。计算需要在互联网上的每个页面和每个链接上运行多次。在千禧年之初,这种计算需要几天的时间。
在此期间,谷歌的 SERP 不断上下波动。这些变化往往是不稳定的,因为每个页面都在计算新的页面排名。
这种情况被称为 “Google Dance”,每次谷歌开始每月更新时,都会让当时的搜索引擎优化专业人员止步不前。
(后来,"Google Dance "成了谷歌在山景城总部为搜索引擎优化专家举办的年度聚会的名称)。
Trusted Seeds
PageRank 的后期迭代引入了 "Trusted Seeds "的概念,以启动算法,而不是给互联网上的每个页面都设置相同的初始值。
Reasonable Surfer
该模型的另一次迭代引入了 "Reasonable Surfer "的概念。
该模型认为,一个页面的 PageRank 可能不会与它链接的页面平均分享,而是根据用户点击链接的可能性来权衡每个链接的相对价值。
PageRank 的衰退
谷歌的算法最初被认为在内部是 "无垃圾 "的,因为一个网页的重要性不仅取决于其内容,还取决于该网页链接所产生的一种 “投票系统”。
然而,谷歌的信心并没有持续多久。
随着反向链接行业的发展,PageRank 开始出现问题。于是,谷歌将其从公众视野中撤出,但在排名算法中继续依赖它。
到 2016 年,PageRank 工具栏被撤销,最终,所有对 PageRank 的公开访问都被限制了。但此时,Majestic(搜索引擎优化工具)已经能够将自己的计算结果与 PageRank 很好地联系起来。
多年来,谷歌一直通过 "谷歌指南 "文件和由马特-卡特斯(Matt Cutts)领导的垃圾邮件团队提供的建议,鼓励搜索引擎优化专业人员不要操纵链接,直到 2017 年 1 月。
在此期间,谷歌的算法也在发生变化。
在收购 MetaWeb 及其专有知识图谱(2014 年称为 “Freebase”)之后,谷歌开始以不同的方式对全球信息进行索引,从而减少了对 PageRank 的依赖。
PageRank 如何彻底改变搜索
其他搜索引擎在很大程度上依赖于单独分析每个页面的内容。这些方法几乎无法识别有影响力的页面与只是用随机(或篡改)文本编写的页面之间的区别。
这意味着,其他搜索引擎的检索方法极易被搜索引擎优化专家操纵。
因此,谷歌的 PageRank 算法具有革命性意义。
结合相对简单的 "nGrams "概念来帮助建立相关性,谷歌找到了一个制胜之道。
它很快就超越了当时的主要竞争对手,如 AltaVista 和 Inktomi(为 MSN 等提供支持)。
与雅虎和后来的 DMOZ 采用的基于 "目录 "的方法相比,Google 还找到了一种在页面级别上运行的更具可扩展性的解决方案–尽管 DMOZ(也称为开放目录项目)最初能够为 Google 提供自己的开放源代码目录。
工具栏 PageRank 与 PageRank 的对比
谷歌最初对自己的算法引以为傲,乐于向任何想看的人公开分享计算结果。
最显著的表现形式是火狐等浏览器的工具栏扩展,它显示了互联网上每个页面的 0 到 10 分。
事实上,PageRank 的评分范围要宽泛得多,但 0-10 分为搜索引擎优化专业人员和消费者提供了一种即时评估互联网上任何网页重要性的方法。
PageRank 工具栏让这一算法变得非常明显,但也带来了一些复杂问题。尤其是,这意味着链接显然是 "玩弄 "谷歌的最简单方法。
链接越多(或者更准确地说,链接越好),页面在谷歌搜索结果中的目标关键词排名就越靠前。
这意味着形成了一个二级市场,根据出售链接的 URL 的 PageRank 值买卖链接。
Yahoo推出了一款名为 "Yahoo Search Explorer "的免费工具,让任何人都可以开始查找任何给定页面的链接,这加剧了这一问题。
后来,Moz 和 Majestic 这两个工具在免费工具的基础上建立了自己的互联网索引,并分别对链接进行评估。
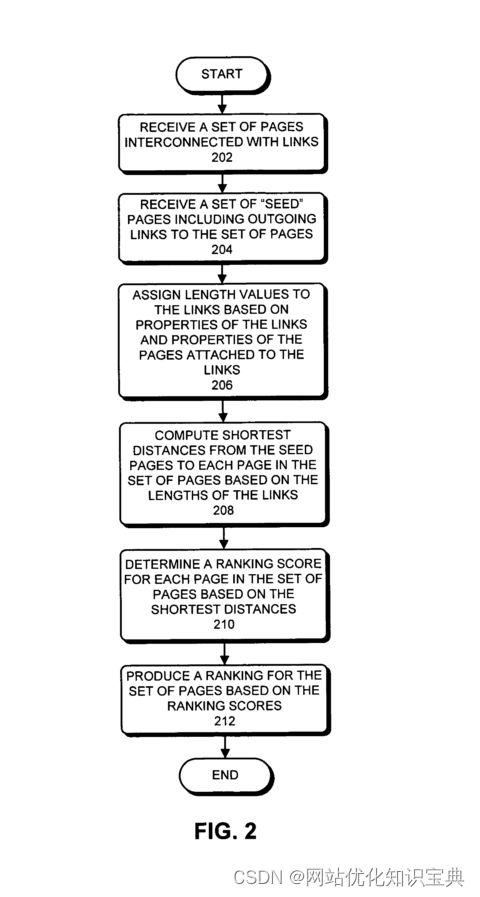
PageRank 如何工作
PageRank 的计算公式有多种形式,但可以用几句话来解释。
最初,互联网上的每个页面都会得到一个估计的 PageRank 分数。这个分数可以是任何数字。从历史上看,PageRank 是以介于 0 和 10 之间的分数向公众展示的,但实际上,估算的分数并不一定从这个范围开始。
然后,该页面的 PageRank 除以该页面外的链接数,得出一个较小的分数。
然后将 PageRank 分布到链接的页面上,互联网上的其他页面也是如此。
然后,在算法的下一次迭代中,每个页面的 PageRank 的新估计值就是链接到每个给定页面的所有页面分数的总和。
该公式还包含一个 “阻尼系数”,即上网者完全停止上网的可能性。
在算法的每次后续迭代开始之前,提出的新 PageRank 都会被阻尼系数减小。
这种方法不断重复,直到 PageRank 分数达到一个稳定的平衡点。然后,为了方便起见,一般会将得出的数字换算成 0 到 10 这样一个更容易辨认的范围。
一种数学表示方法是

其中
- PR = 算法下一次迭代的 PageRank。
- d = 阻尼系数。
- j = 互联网上的页面编号(如果每个页面都有唯一的编号)。
- n= 互联网页面总数。
- i = 算法的迭代次数(初始设置为 0)。
该公式也可以用矩阵形式表示。
问题与公式迭代
该公式存在一些问题。
如果一个页面没有链接到任何其他页面,那么公式将无法达到平衡。
因此,在这种情况下,PageRank 将被分配到互联网上的每一个页面。这样,即使一个没有任何链接的页面也能获得一些 PageRank,但积累的数量不足以产生重要影响。
另一个鲜为人知的挑战是,较新的网页虽然可能比旧网页更重要,但其 PageRank 却较低。这意味着,随着时间的推移,旧内容的 PageRank 会过高。
网页上线的时间并不计入算法。
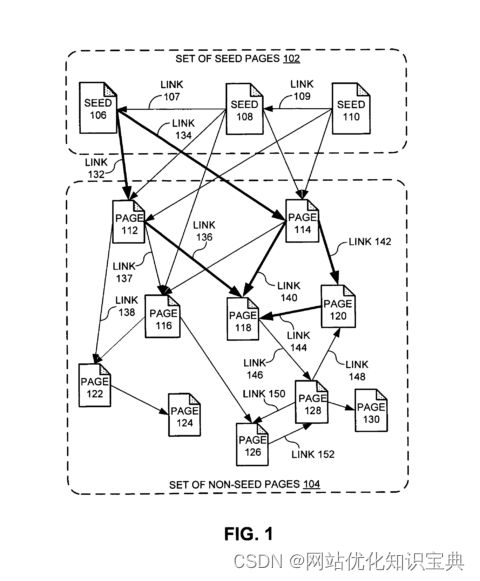
PageRank 如何在页面之间流动
如果一个页面的起始值为 5,并有 10 个链接,那么它链接到的每个页面都会获得 0.5 的 PageRank 值(减去阻尼系数)。
这样,PageRank 就会在互联网上循环流动。
当新网页出现在互联网上时,它们一开始只有极少量的 PageRank。但随着其他网页开始链接到这些网页,它们的 PageRank 就会随着时间的推移而增加。
PageRank 是否仍在使用?
虽然公众对 PageRank 的访问权限已于 2016 年取消,但据信,谷歌内部的搜索工程师仍可使用该评分。
对 Yandex 所用因素的泄露显示,PageRank 仍是其可以使用的一个因素。
谷歌工程师表示,PageRank 的原始形式已被一种新的近似值取代,计算时所需的处理能力更低。虽然计算公式在谷歌网页排名中的重要性降低了,但它对每个网页来说仍然是一个常数。
不管谷歌可能会选择使用其他什么算法,PageRank 很可能至今仍被嵌入这家搜索巨头的许多系统中。
更多SEO学习资料 可以扫码 解锁 《SEO学习资料文档》

- Core Web Vitals:完整指南
- Google E-A-T和SEO指南
- Google 初学者的SEO:SEO基础知识简介
- Google PPC 营销基础知识完整指南
- Google SEO 的链接建设:完整指南
- Google SEO入门教程
- SEO进阶教程:(网站优化排名之百度SEO快排·技术篇)
- Google 排名因素:系统、信号和页面体验
- WordPress SEO 指南:您需要了解的一切
- 本地 SEO :提高本地搜索排名的权威指南