LDC: Lightweight Dense CNN for Edge Detection
摘要
本文提出了一种用于边缘检测的轻量级密集卷积(LDC)神经网络。所提出的模型是对两种最先进方法的改编,但与这些方法相比,它所需的参数不到4%。与轻量级模型(参数小于100万的模型)相比,所提出的体系结构生成了薄边缘图,并达到了最高分数(即ODS),与重型体系结构(参数约为3500万的型号)相比,达到了类似的性能。提供了使用不同边缘检测数据集的定量和定性结果以及与现有技术模型的比较。所提出的LDC不使用预先训练的权重,并且需要直接的超参数设置。代码:https://github.com/xavysp/LDC
一、引言
由于深度学习方法的快速发展,近年来,用于执行图像边缘检测的卷积神经网络(CNN)模型爆炸性地传播。但边缘检测的大多数工作都致力于通过设计非常深入的网络来实现更高的度量(即ODS、OIS、AP),这导致了计算操作数量的增加。遗憾的是,这些边缘检测方法对于低容量设备和现实世界的应用都不实用。考虑到上述缺点,本文提出了一种新的轻量级结构LDC——用于边缘检测的轻量级密集CNN模型。它旨在成为现实世界应用程序的实用网络,它可以自适应地学习关注高频信息的最有价值的特征。所提出的体系结构基于DexiNed,但为了在性能和适用性之间寻求更好的折衷,考虑了较小的滤波器尺寸和紧凑的模块。作为所提出的修改的结果,获得了一个参数小于1M的模型,并且比大多数最先进的方法轻。
贡献可以总结如下:
• 提出了一种轻量级 CNN 架构,它只有 674K 个参数,而 DexiNed 中有 35M 个参数。
• 与最先进的边缘检测器(参数少于1M)进行了广泛的比较研究。本文完全致力于边缘检测,即所有考虑进行定量比较的模型都使用 BIPED、MDBD 和新的 BRIND 数据集来训练和验证模型。此外,每个模型都使用其他数据集进行交叉验证。
• 进行深入的消融研究,直至达到稳健的LDC。
二、相关工作
A. 基于深度学习的边缘检测器
HED是一种基于 VGG16 架构的深度监督模型,HED 中使用的交叉熵损失函数有助于设计具有端到端边缘训练过程的模型。基于 HED 架构,已经提出了几种模型(例如 CED [21]、RCF [10]、BDCN [8]),大多数使用VGG16作为主干架构,其中有一些使用 ResNet作为主干架构;上述最先进的模型提出了不同的中间边缘融合和轻微的损失函数修改。这些模型仍然使用预训练权重和层级超参数设置。为了减轻这些缺点,DexiNed 建议使用部分基于Xception的 CNN 架构以及新的训练数据集。尽管 DexiNed 有大约 35M 个参数,但它可以从头开始训练,需要较少的超参数调整;它在用于边缘检测的数据集上达到了最佳结果。一种新的边缘检测算法称为 CATS,它基于新型损失函数的使用,除了边界跟踪和纹理抑制损失之外,还使用交叉熵。由于该损失函数,可以获得更干净、更薄的边缘图。除了上述方法之外,还有基于使用GAN模型的贡献,称为 ContourGan ,以及最近的 Transformers 。尽管通过设计新的架构或引入新的损失函数已经取得了实质性的改进,但大多数方法都需要增加计算操作的数量。因此,它们对于低容量设备和实际应用都不实用。这一缺点促使轻量级模型(通常参数少于 1M)的开发取得了吸引人的结果。作为这些轻量级模型的例子,我们可以提到 TIN和 PiDiNet架构;这些模型的主要特点是减小内核大小以及手动内核设置。就 PiDiNet 而言,它仍然使用 CNN 层级别的超参数调整。
B. 边缘检测数据集
第一个数据集是 CID,它不是用于边缘检测,而是用于轮廓检测的密切相关问题;它由一组 40 个灰度图像组成。由于该数据集用于轮廓检测,因此有一些边缘没有注释。
另一个广泛使用的数据集是BSDS300,然后扩展到BSDS500;尽管 BSDS 中的注释旨在用于边界检测,但有一些图像在边缘级别进行了注释,这一事实使得训练基于学习的算法变得困难。
同样与边缘检测相关的是,我们可以提到纽约大学室内数据集,其中包含语义分割问题的注释,以边缘检测为条件。与语义分割相关,还有其他数据集也被考虑用于解决边缘检测问题(例如,PASCAL-Context、CITYSCAPES 等)。
与之前用于轮廓和边界检测或提取语义分割注释的方法相反,2016 年提出了用于边界检测的 Multicue 数据集(MDBD)。它由边界和边缘级别的多个注释组成。最近,提出了用于感知边缘检测 (BIPED) 数据集的巴塞罗那图像;在[2]中对此进行了扩展。最后,[4] 提出了 BRIND,它使用 BSDS500 图像进行边缘级别注释。这三个数据集(即 MDBD、BIPED 和 BRIND)专门用于边缘检测,因此它们将用于训练 LDC。
三.提出的方法
A. 卷积神经网络架构
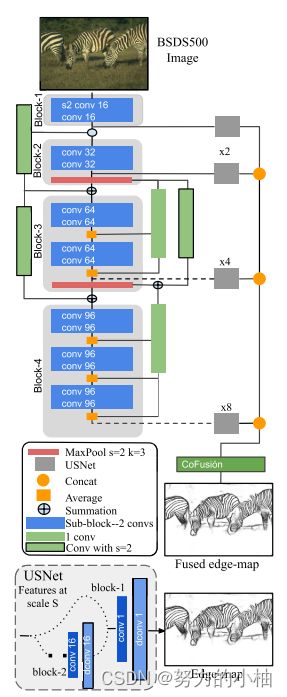
DexiNed体系结构由密集极端初始网络Dexi和上采样块USNet两个子网组成。一方面,Dexi由6个受 xception 网络启发的输出区块组成;来自第三个块的每个块都连接有两种类型的跳过连接。另一方面,USNet是一个条件CNN,用于升级和转换边缘图中的特征图,其大小与Dexi子网的输入图像相同。这种架构产生了一个具有35M参数的模型。
对DexiNed进行以下修改,以生成LDC架构:
•LDC仅使用DexiNed的四个区块。
•LDC没有使用与DexiNed相同的滤波器大小,而是为了对参数数量进行轻加权,大幅减少了Dexi滤波器的大小。
•LDC有四个中间边缘图预测,因此,最终结果来自这些预测的融合。用于融合这些边缘图的策略受到 CATS 的启发;它被称为上下文感知融合块或简称 CoFusion。这组操作也稍作修改,以减少参数数量而不影响鲁棒性。 LDC 提出的修改如下。 LDC没有使用3个卷积层和2组内核大小为64的归一化,而是将CoFusion减少为2个卷积层和1组内核大小为32的归一化。其他配置与CATS 中的相同。
•对于LDC中的中间边缘图形成,USNet与DexiNed中的配置相同。
•最后,为了训练LDC,CATS的损失函数也进行了轻微修改。
B.损失函数
CATS的损失函数已稍微修改以训练 LDC,这将被称为 CASTloss2。LDC 从给定的 RGB 图像 ![]() ,返回一组边缘图预测
,返回一组边缘图预测![]() ,并使用相应的GroundTruth Y 进行验证。
,并使用相应的GroundTruth Y 进行验证。![]() 表示最后的输出所提出的模型(即第五个输出)对应于 CoFusion 阶段的预测。在当前工作中,考虑
表示最后的输出所提出的模型(即第五个输出)对应于 CoFusion 阶段的预测。在当前工作中,考虑 ![]() 输出进行定性和定量比较。 CATSloss2 应用于每个
输出进行定性和定量比较。 CATSloss2 应用于每个![]() 。 CATSloss2 由三个损失组成:追踪(交叉熵)损失
。 CATSloss2 由三个损失组成:追踪(交叉熵)损失 ![]() 、边界追踪损失
、边界追踪损失 ![]() 和纹理抑制损失
和纹理抑制损失![]() 。因此,所得的 CATSloss2 (l) 计算如下:
。因此,所得的 CATSloss2 (l) 计算如下:

其中![]() 是正则化边界跟踪损失的权重,
是正则化边界跟踪损失的权重,![]() 是每个 LDC 预测的纹理抑制损失。最终损失是根据每个
是每个 LDC 预测的纹理抑制损失。最终损失是根据每个![]() 计算出的 l 损失之和--有五个预测。
计算出的 l 损失之和--有五个预测。
对于![]() 损失,定义如下:
损失,定义如下:
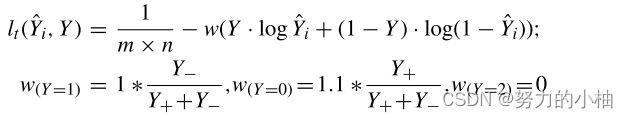
其中w是跟踪损失的权重,Y−和Y+分别表示给定Y中的负边缘样本和正边缘样本。
关于边界追踪损失(![]() ),定义如下:
),定义如下:
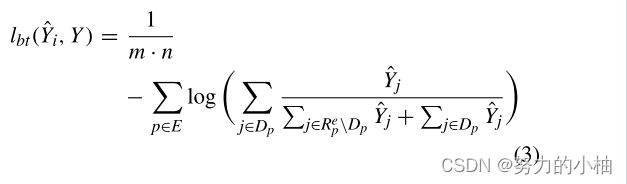
其中E是给定Y的边缘点。![]() 表示来自
表示来自![]() 的包含边缘片段的边缘图块,
的包含边缘片段的边缘图块,![]() 的中心是p。
的中心是p。 ![]() 中的边缘点用
中的边缘点用 ![]() 表示。
表示。
最后,纹理损失(![]() )定义如下:
)定义如下:

其中,![]() 是以非边缘点p为中心的边缘映射块,而
是以非边缘点p为中心的边缘映射块,而![]() 是包括所有边缘及其在
是包括所有边缘及其在![]() 中使用的混淆像素的集合。
中使用的混淆像素的集合。