深刻剖析与实战BCELoss详解(主)和BCEWithLogitsLoss(次)以及与普通CrossEntropyLoss的区别(次)
文章目录
-
-
- 前言
- BCELoss原理
- BCELoss实操
-
- 二分类情况
- 多分类情况
- CrossEntropyLoss
- BCEWithLogitsLoss
-
前言
import torch
import torch.nn as nn
import torch.nn.functional as tnf
大家首先要注意一下哈,在pytorch里面,类是一回事,函数是另外一回事,比如上面我说的BCELoss,BCEWithLogitsLoss等都是类,所以我们要先进行构造对象,然后在调用其方法(函数)求损失。
但是,pytorch为了方便大家,在torch.nn.functional提供了直接求损失的函数,但是其原理还是上面的红色,只是帮你做了而已。
例如:
#标准形式
loss_function=nn.BCELoss()
loss_function(pred,label)
#或者
tnf.binary_cross_entropy(pred,lable)
也就是说,有一一对应关系,例如:
BCEWithLogitsLoss对应
tnf.binary_cross_entropy_with_logits
CrossEntropyLoss对应
tnf.cross_entropy
等等。
BCELoss原理
本文先讲解原理,然后实操。
BCE:binary cross entropy。所以,其也是交叉熵的一个应用,但针对的是二分类,所以有其特殊形式。
为什么二分类有其特殊形式?对于二分类问题,我们模型需要输出[0.3,0.7],但我们完全可以让我们的模型只输出一个数例如0.3就好了,由于归一化的原因,属于另外一个类别的概率一定是0.7。从而,其特殊形式如下:
l o s s ( x , y ) = − [ y log x + ( 1 − y ) log ( 1 − x ) ] loss(x,y)=-[y\log x+(1-y)\log (1-x)] loss(x,y)=−[ylogx+(1−y)log(1−x)]
原理就已经讲完了,但是我发现一个有意思的地方,这个东西在实际用的过程中,不仅可以用作二分类,也可以用作多分类。各位看官且看实操部分。
BCELoss实操
二分类情况
原理如下图,x是我们的模型输出,和上面原理部分不同,这里的x是一个向量, x = ( x 1 , . . . , x N ) x=(x_1,...,x_N) x=(x1,...,xN),其中的 x i x_i xi才是原理部分的x,所以,你应该看出来了,向量x是一个batch,N是batch_size。
所以,我们可以分别计算这个batch中的每个样本的损失 l i l_i li,并且可以赋予不同样本不同的权重 w i w_i wi,即:
![]()
然后,对于这个batch而言,我们得到了如下这样一个损失向量:
![]()
我们接下来要做的一般就是把这些损失向量加起来或者平均起来,得到一个数字,作为整个批的loss。
data_input=torch.Tensor([0.3980, 0.8603, 0.1073])#3个样本的二分类问题,批大小是3.
data_target=torch.Tensor([0., 1., 1.])
loss=nn.BCELoss(reduction="none")#reduction="none"得到的是loss向量
loss(data_input,data_target)
![]()
我们可以验证一下,我们说的是否正确:
print(-np.log(1-0.3980))#带原理部分的公式计算第一个样本的loss。
print(-np.log(0.8603))
print(-np.log(0.1073))

可以发现和上面得到的loss向量一模一样。
接下来,我们可以求和或者取平均得到这个批的整体loss情况。
loss_sum=nn.BCELoss(reduction="sum")
loss_mean=nn.BCELoss()#默认
print(loss_sum(data_input,data_target))
print(loss_mean(data_input,data_target))

可以自己试一试,loss向量加起来或者求平均是不是这个。
更有甚者,我们可以给这个batch中不同样本不同的权重,从而使用如下公式计算。
![]()
loss_weight_none=nn.BCELoss(reduction="none",weight=torch.Tensor([1,1,2]))
print(loss_weight_none(data_input,data_target))#得到loss向量。
![]()
大家对比一下之前最开始哪个权重默认是[1,1,1]的,
![]()
是不是发现最后一个样本的loss变成了2倍。
最后,我还要说,这个BCELoss还支持多批同时处理,例如:
import torch
import torch.nn as nn
data_input=torch.Tensor([[0.3980, 0.8603, 0.1073],[0.3980, 0.8603, 0.1073]])#一共6个样本,2批。
data_target=torch.Tensor([[0., 1., 1.],[0., 1., 1.]])
loss=nn.BCELoss(reduction="none")
loss(data_input,data_target)

此时,求和或者平均是所有一共6个样本一起求和和平均。
多分类情况
讲了上面,其实这里就很简单了,对下下述tensor
data_input=torch.Tensor([[0.3980, 0.8603, 0.1073],[0.3980, 0.8603, 0.1073]])#一共6个样本,2批。
data_target=torch.Tensor([[0., 1., 1.],[0., 1., 1.]])
对于上面二分类情况中,我们的解释是:
- 有2批,批大小为3,一共6个样本。
- 模型输出,或者叫做样本输出是一个数。
对于我们现在的多分类情况,我们的解释是:
- 有1批,批大小为2,一共2个样本,一个样本的输出是一个向量,维度是3,表示是3分类问题。
- 对于模型输出的向量x,其每一个分量值需要在0-1之间,所以我们使用sigmoid进行激活就会在这个区间。在多分类的解释下,并不需要归一化,因此我们就用sigmoid,不需要使用softmax。
- 此时 w i w_i wi解释为类别的权重,重视某个类别,则加大该类别权重即可。假设得到一个样本输出(sigmoid后的)为 x = ( x 1 , . . . , x N ) x=(x_1,...,x_N) x=(x1,...,xN),要计算其loss,还是使用之前的公式:
![]()
其中 l i l_i li解释为:预测这个样本为第i个类别的损失。计算也仍然和以前一样,我说了无非是换一种解释而已。
![]()
实操?还有什么难度吗,和以前一毛一样,如下:
import torch
import torch.nn as nn
data_input=torch.Tensor([[0.3980, 0.8603, 0.1073],[0.3980, 0.8603, 0.1073]])#三分类问题,批大小为2.只有一个批。
data_target=torch.Tensor([[0., 1., 1.],[0., 1., 1.]])#都属于类别1,属于哪个类别,该类别就是0.
loss=nn.BCELoss(reduction="none")
loss(data_input,data_target)
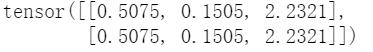
想要得到批整体的loss,也和以前一样。以求和为例,不同就在于二分类中的解释是两个批的一共loss,现在为一个批的loss。
CrossEntropyLoss
大家会看一下我上面那个紫色的语句,其暗示了BCELoss和CrossEntropyLoss的区别。
一般情况下,对于分类问题,我们的第一反应就是使用最熟悉,最经典的CrossEntropyLoss损失函数。这没有错,现在也可以继续用,这两个loss我觉得没有谁更好,都在从不同方面对loss进行刻画,下面学完了你可以体会一下。
为什么这么说,紫色语句我说了,BCELoss会计算每一个类别维度的loss,而CrossEntropyLoss是如下来计算的:

loss=nn.CrossEntropyLoss()
data_input=torch.Tensor([[0.3980, 0.8603, 0.1073]])#一个批,批里面只有一个样本。
data_target=torch.Tensor([0]).long()#这个样本属于第一个类别。
loss(data_input,data_target)
![]()
-np.log(np.exp(0.3980)/(np.exp(0.3980)+np.exp(0.8603)+np.exp(0.1073)))

BCEWithLogitsLoss
这个很简单,BCELoss需要将data_input事先sigmoid好,才能用,而BCEWithLogitsLoss会帮你sigmoid,如下:
input = torch.randn(3)#随机生成一个输入,没有被sigmoid。
target=torch.Tensor([0., 1., 1.])
loss1=nn.BCELoss()
loss2=nn.BCEWithLogitsLoss()
print("BCELoss:",loss1(torch.sigmoid(input), target))#需要sigmod
print("BCEWithLogitsLoss:",loss2(input,target))#不需要sigmoid

可以发现,两者结果一致。