MNL——多项Logit模型学习笔记(二)
本节将会通过案例举例,介绍Logit模型的建模思路和过程
内容为摘抄他人学习资料的个人学习笔记,如有侵权则删
1.正确打开/解读Logit模型系数的方式
本节的具体内容在笔记里不详细表示了,大家在软件里拟合Logit模型时,对于其中的参数不懂的话,可以到时候点击下面的链接看,需要哪里看哪里
正确打开/解读Logit模型系数的方式——离散选择模型之四 (qq.com)
本节讨论如何解读Logit模型系数。先来回顾一下之前的内容。

系数解读方法之1:从概率的角度(方法一比较麻烦)
系数解读方法之2:从胜率(Odds)的角度
本节就只对方法二做一个简单归纳:

举例:
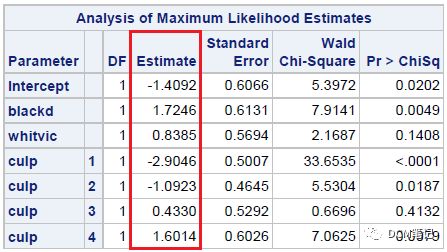
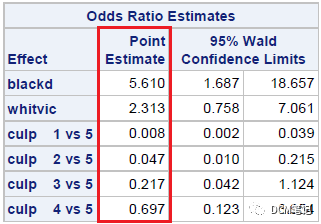

mnrfit 函数是MATLAB中用于拟合Logistic模型的函数,有关此函数的更多介绍可以参见:Multinomial logistic regression - MATLAB mnrfit - MathWorks 中国
最后提醒:在对系数进行解释时,“其它变量保持不变 (given all other variables remain unchanged/given all else equal)”这句话很重要——否则会显得不严谨!
Logit模型拟合实战案例(Python)——离散选择模型之六 (qq.com)
实战练习
2.离散选择模型的核心——效用最大化

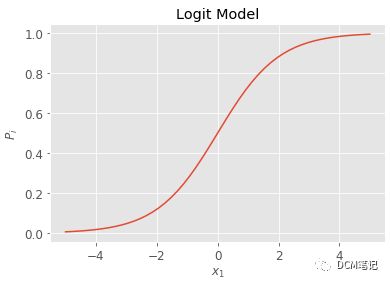
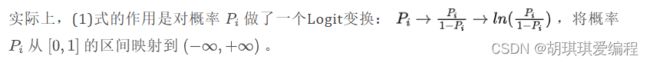
除了Logit变换,我们还可以使用其他函数将概率Pi从[0,1]映射到(+∞,-∞),比如说正切函数。
类似的函数还可以构造出很多个。那问题来了:我们为什么要选择Logit变换?能不能选择其它的变换函数?要回答这些问题,就要从选择行为的建模过程来看。
从经济学的角度来说,决策者在面临多个可选方案的时候,通常会选择效用最大的那个方案。在中文里面,效用这个词的使用并不普遍;在英文里,效用所对应的英文单词是utility。
你可以把这里的效用(utility)理解成每一个方案所能提供的价值,或者是某个方案所能够给你带来的满足感/幸福感。举个例子,在买车的时候,你可能会考虑多个品牌的多款车型,你最终选择了某款车型是因为你觉得该车型的外形设计比较新颖时尚、加速性能好、安全系数较高,等等。
如果我们假设每一个决策主体都是理性的(经济学中的“理性经济人”的假设),其所追求的目标都是使自己的效用最大化——这就是所谓的“效用最大化准则”。

3.探究效用与自变量X之间的关系
决策者在选择某一方案的时候,通常会考虑该方案在不同的维度上所带来的效用。
比如,在选择出行方式的时候(公交 vs 地铁),出行者可能会考虑每一种出行方式在不同的维度上所带来的效用:
-
出行时间的长短
-
费用的高低
-
可靠性的高低
在建模的时候,有些参数是可以观测到的,比如上面提到的时间、费用、可靠性——时间、价格不必说,可靠性我们可以用准点率或者运行时间的方差来衡量;然而有些因素则是无法测量或者说很难测量——比方说你们家楼下就有一个公交站点,下班的时候,你一般都会选择坐公交;但某天下班后,你打算先和朋友去地铁站附近撸个窜,然后顺道坐地铁回去——这些偶然的因素就是不可观测的。此外,测量的过程中的可能还会存在误差。
因此,建模的时候,我们可以把效用当作一个随机变量;它由两部分组成——可观测到的确定性部分(deterministic component) 和随机部分(random component)。


4.确定Probit模型
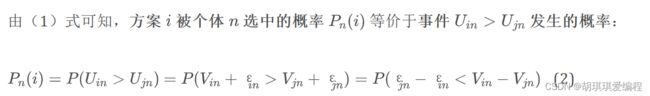
对于随即效用变量 εin、εjn,我们并不知道其确切的分布形式,采用不同的分布形式就会得到不同的离散选择模型,在Probit模型中,我们假设ε服从正态分布。(在Logit模型中,会假设ε服从Logistic分布)
由中心极限定理可知:大量的独立随机变量之和近似于服从正态分布。如果我们把效用的随机部分εin以及εjn看成多个不可观测的随机变量的组合,那么,根据中心极限定理,我们可以假设它们都近似服从正态分布,为研究方便,我们可以有如下假设:
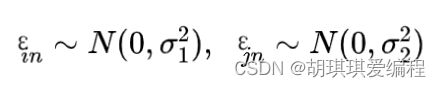
那么,两者相减就有:(其中用到了方差运算的性质)
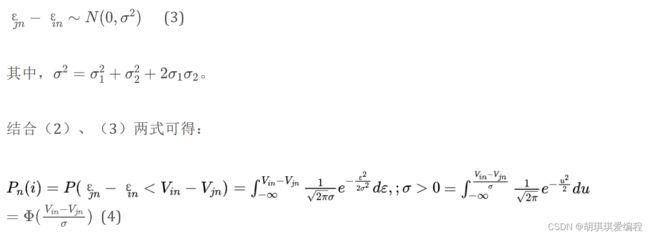

(4)、(5)两式就是Probit模型的表达式。
还需补充的几点说明:
-
尽管最后的表达式中没有变量效用,但是在整个建模的过程中,变量效用 可以看成是一个潜变量(latent variable),或者说是一个中间变量;
-
(4)式也说明,不同方案的效用的差值才会决定选择概率的大小,而非效用的绝对大小


5.summary
本节第一部分提到如何理解Logit模型的各项参数;第二节&第三节讨论了离散选择模型的核心——效用最大化,给出了utility的定义以及数学表达式,并将效用最大化问题转化为概率问题,为后文的模型建立打下基础;第四节进行了Probit模型构建的讨论,重点内容Logit模型将在下一节展示。