最容易出错的 Hive Sql 详解
前言
在进行数仓搭建和数据分析时最常用的就是 sql,其语法简洁明了,易于理解,目前大数据领域的几大主流框架全部都支持sql语法,包括 hive,spark,flink等,所以sql在大数据领域有着不可替代的作用,需要我们重点掌握。
在使用sql时如果不熟悉或不仔细,那么在进行查询分析时极容易出错,接下来我们就来看下几个容易出错的sql语句及使用注意事项。
正文开始
1. decimal
hive 除了支持 int,double,string等常用类型,也支持 decimal 类型,用于在数据库中存储精确的数值,常用在表示金额的字段上
注意事项:
如:decimal(11,2) 代表最多有11位数字,其中后2位是小数,整数部分是9位;
如果整数部分超过9位,则这个字段就会变成null,如果整数部分不超过9位,则原字段显示;
如果小数部分不足2位,则后面用0补齐两位,如果小数部分超过两位,则超出部分四舍五入;
也可直接写 decimal,后面不指定位数,默认是 decimal(10,0) 整数10位,没有小数
2. location
表创建的时候可以用 location 指定一个文件或者文件夹
create table stu(id int ,name string) location '/user/stu2';注意事项:
创建表时使用location,
当指定文件夹时,hive会加载文件夹下的所有文件,当表中无分区时,这个文件夹下不能再有文件夹,否则报错。
当表是分区表时,比如 partitioned by (day string), 则这个文件夹下的每一个文件夹就是一个分区,且文件夹名为 day=20201123
这种格式,然后使用:msck repair table score; 修复表结构,成功之后即可看到数据已经全部加载到表当中去了
3. load data 和 load data local
从hdfs上加载文件
load data inpath '/hivedatas/techer.csv' into table techer;
从本地系统加载文件
load data local inpath '/user/test/techer.csv' into table techer;注意事项:
(1) 使用 load data local 表示从本地文件系统加载,文件会拷贝到hdfs上
(2) 使用 load data 表示从hdfs文件系统加载,文件会直接移动到hive相关目录下,注意不是拷贝过去,因为hive认为hdfs文件已经有3副本了,没必要再次拷贝了
(3) 如果表是分区表,load 时不指定分区会报错
(4) 如果加载相同文件名的文件,会被自动重命名
4. drop 和 truncate
删除表操作
drop table score1;
清空表操作
truncate table score2;
注意事项:
如果 hdfs 开启了回收站,drop 删除的表数据是可以从回收站恢复的,表结构恢复不了,需要自己重新创建;truncate 清空的表是不进回收站的,所以无法恢复truncate清空的表。
所以 truncate 一定慎用,一旦清空除物理恢复外将无力回天
5. join 连接
INNER JOIN 内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来
select * from techer t [inner] join course c on t.t_id = c.t_id; -- inner 可省略
LEFT OUTER JOIN 左外连接:左边所有数据会被返回,右边符合条件的被返回
select * from techer t left join course c on t.t_id = c.t_id; -- outer可省略
RIGHT OUTER JOIN 右外连接:右边所有数据会被返回,左边符合条件的被返回、
select * from techer t right join course c on t.t_id = c.t_id;
FULL OUTER JOIN 满外(全外)连接: 将会返回所有表中符合条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
SELECT * FROM techer t FULL JOIN course c ON t.t_id = c.t_id ;注意事项:
(1) hive2版本已经支持不等值连接,就是 join on条件后面可以使用大于小于符号;并且也支持 join on 条件后跟or (早前版本 on 后只支持 = 和 and,不支持 > < 和 or)
(2) 如hive执行引擎使用MapReduce,一个join就会启动一个job,一条sql语句中如有多个join,则会启动多个job
注意:表之间用逗号(,)连接和 inner join 是一样的,例:
select tableA.id, tableB.name from tableA , tableB where tableA.id=tableB.id;
和
select tableA.id, tableB.name from tableA join tableB on tableA.id=tableB.id; 它们的执行效率没有区别,只是书写方式不同,用逗号是sql 89标准,join 是sql 92标准。用逗号连接后面过滤条件用 where ,用 join 连接后面过滤条件是 on。
6. left semi join
为什么把这个单独拿出来说,因为它和其他的 join 语句不太一样,
这个语句的作用和 in/exists 作用是一样的,是 in/exists 更高效的实现
SELECT A.* FROM A where id in (select id from B)
SELECT A.* FROM A left semi join B ON A.id=B.id
上述两个 sql 语句执行结果完全一样,只不过第二个执行效率高注意事项:
(1)left semi join 的限制是:join 子句中右边的表只能在 on 子句中设置过滤条件,在 where 子句、select 子句或其他地方过滤都不行。
(2) left semi join 中 on 后面的过滤条件只能是等于号,不能是其他的。
(3) left semi join 是只传递表的 join key 给 map 阶段,因此left semi join 中最后 select 的结果只许出现左表。
(4) 因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过
7. 聚合函数中 null
hive支持 count(),max(),min(),sum(),avg() 等常用的聚合函数
注意事项:
聚合操作时要注意 null 值:
count(*) 包含 null 值,统计所有行数;
count(id) 不包含id为 null 的值;
min 求最小值是不包含 null,除非所有值都是 null;
avg 求平均值也是不包含 null。
以上需要特别注意,null 值最容易导致算出错误的结果
8. 运算符中 null 值
hive 中支持常用的算术运算符(+,-,*,/)
比较运算符(>, <, =)
逻辑运算符(in, not in)
以上运算符计算时要特别注意 null 值
注意事项:
(1) 每行中的列字段相加或相减,如果含有 null 值,则结果为 null
例:有一张商品表(product)
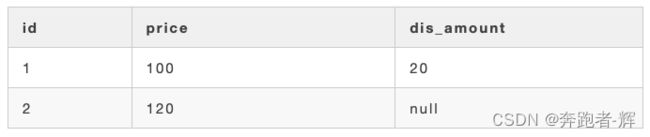
各字段含义:id (商品id)、price (价格)、dis_amount (优惠金额)
我想算每个商品优惠后实际的价格,sql如下:
select id, price - dis_amount as real_amount from product;
得到结果如下:

id=2的商品价格为 null,结果是错误的。
我们可以对 null 值进行处理,sql如下:
select id, price - coalesce(dis_amount,0) as real_amount from product;
使用 coalesce 函数进行 null 值处理下,得到的结果就是准确的
coalesce 函数是返回第一个不为空的值
如上sql:如果dis_amount不为空,则返回dis_amount,如果为空,则返回0
(2) 小于是不包含 null 值,如 id < 10;是不包含 id 为 null 值的。
(3) not in 是不包含 null 值的,如 city not in ('北京','上海'),这个条件得出的结果是 city 中不包含 北京,上海和 null 的城市。
9. and 和 or
在sql语句的过滤条件或运算中,如果有多个条件或多个运算,我们都会考虑优先级,如乘除优先级高于加减,乘除或者加减它们之间优先级平等,谁在前就先算谁。那 and 和 or 呢,看似 and 和 or 优先级平等,谁在前先算谁,但是,and 的优先级高于 or。
注意事项:
例:
还是一张商品表(product)
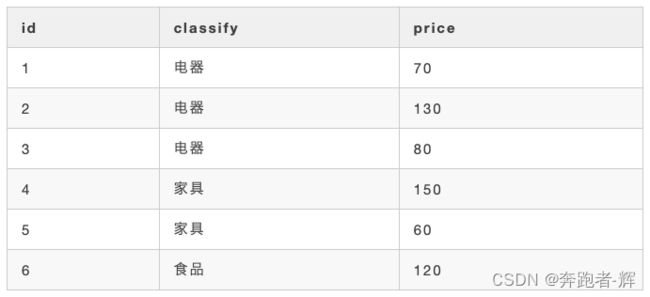
我想要统计下电器或者家具这两类中价格大于100的商品,sql如下:
select * from product where classify = '电器' or classify = '家具' and price>100得到结果
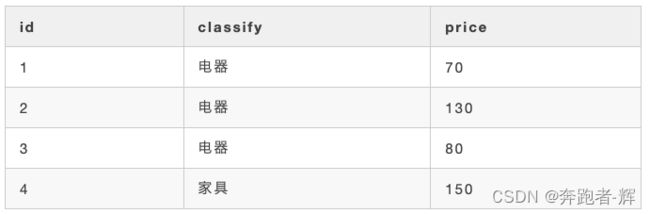 结果是错误的,把所有的电器类型都查询出来了,原因就是 and 优先级高于 or,上面的sql语句实际执行的是,先找出 classify = '家具' and price>100 的,然后在找出 classify = '电器' 的
结果是错误的,把所有的电器类型都查询出来了,原因就是 and 优先级高于 or,上面的sql语句实际执行的是,先找出 classify = '家具' and price>100 的,然后在找出 classify = '电器' 的
正确的 sql 就是加个括号,先计算括号里面的:
select * from product where (classify = '电器' or classify = '家具') and price>100