数字后端IC设计基本概念
1、Electro Migaration(EM)——电迁移现象
EM:由于金属导体中电场的作用导致金属离子的迁移。
Effect:后造成芯片中的net短路或者断路,从而影响芯片的寿命。在芯片设计中往往通过电流密度判断EM的影响,两者为正比关系,即电流密度大的地方,EM影响大。一般需要遵守EM spec(每个金属层规定的最大电流密度)。
Solution: 当设计中的电流密度超过上述的spec时,需要通过减小电流密度的方法解决。金属的电流密度由其通过的电流大小和相应的横截面积有关,所以可以通过减小电流和增大横截面积的方法来减小电流密度。由于,金属的厚度一般不能改变,因此一般通过增加net宽度和并联一段shape减小电流的方式来减小电流密度。
Tips:对于PG,siginal,clock所有的net都会产生EM效应,PG上的EM称为PEM,一般通过增加PG mesh的方法处理violation。SEM 和clock一般通过NDR的方法解决。
2、Crosstalk——串扰
crosstalk:一条信号线上的信号跳变对另一条信号线上的信号产生了影响。(变化的电流产生了变化的电磁场)
两段很近的导线发生串扰时,假设一段导线从0跳变为1,会影响另一段导线电势小幅上升一点,再回落下来。我们称产生跳变的导线为attacker,受影响的导线为victim,那一小段电势的变化称为glitch。相应的,如果attacker从1变0,victim会有一个电势下降的glitch。如果这个glitch过大,就可能产生一个错误的逻辑信号出来,这个时候就发生了glitch的violation。Attacker和victim的角色是可以互相转化的,一个victim在需要翻转的时候就成为了attacker,attacker信号保持不变的时候就是victim。如果两段信号线同时反转,他们就都既是attacker又是victim。另一种情况,如果attacker和victim同时跳变,如果attacker和victim的跳变方向一致,比如说都从0变为1,victim受attacker的影响跳变速度会更快一些,也就是transition/slew time更小。注意这个时候两者都既是attacker也是victim,所以两根导线的transition都会变快。相反地,如果attacker和victim跳变方向不同,transition会变慢。Transition的变化可能会产生timing的violation,这一类violation也可以说是由SI带来的。但是一般这种violation不如glitch来的严重。
一种比较严重的violation叫做DS(double switch),也是由于串扰带来的逻辑错误。就是说attacker和victim同时跳变并且方向相反,假设attacker从1到0,victim从0到1,假设某个时刻victim已经过了逻辑1的电压阈值,后面的cell已经可以捕捉到信号1了,但之后由于crosstalk,victim的电势会有一个向下(逻辑0方向)的glitch。而这个glitch可能导致后级cell捕捉到信号0,之后victim电势再升高为逻辑1,所以总的来说victim的信号传播就从0、1变为0、1、0、1.这就叫做double switch violation。
消除SI violation的方法还是要从绕线着手。第一就是加shielding net,就是在attacker旁边加一段地线,称为shielding,减弱attacker与victim的耦合电容。一般的时钟trunk都会加一定比例的shielding。第二种就是把发生violation的两段shape分开,距离越远越好,具体做法可以把很直的一段shape让它拐一下,做个detour出来。第三种就是把其中一个net换到另一层去,因为我们metal layer的preferred routing direction都是一层横的一层竖的,换层之后能有效减少耦合电容。
3、Placement Blockage
Placement blockage是在floorplan时经常用的一种人为约束。可以有效控制区域的density。从而避免congestion的问题,提高routing的效率。
Placement blockage的类型很多,一共分为9种,分别对应hard, hard_macro, soft, partial, category, rp_group,allow_buffer_only,allow_rp_only,register
hard: 是约束最严格的blockage,该区域范围内,place,legalize, optimize,CTS等任何阶段都不能摆放instance。
hard_macro: 该区域内不允许摆放hard macro,在自动macro placement阶段工具不会摆放macro在该区域。
soft:该区域内,在placement阶段不允许摆放instance,但是在legalize,optimize阶段时允许摆放instance的
partial: 如果要使用partial blockage,首先要人为设计一个阻碍百分比值。在该区域内,工具会block住阻碍值的instance。如果设定了block百分比值是40%,就说明该区域至少会block40%的instance,也就是说该区域最多允许摆放60%的instance. 值得注意的是partial blockage也是只在placement阶段起作用,在legalize,optimize阶段时都不起作用。
category: 这是一种特殊的partial blockage,在某些区域,如果我们不想摆放某种指定的instance,可以把这些instance都指定为一个category,然后category blockage下面的区域就不会摆放这些instance
rp_group: 这也是一种特殊的partial blockage,rp_group blockage的区域不允许摆放relative placement instance,很少用到,如果有用relative placement flow的童鞋可能会用到
allow_buffer_only: 这也是一种特殊的partial blockage, 该blockage区域只允许摆放buffer,当然也是只在placement阶段起作用,在legalize,optimize阶段时都不起作用。
allow_rp_only:这也是一种特殊的partial blockage, 该blockage区域只允许摆放relative placement group,不过hard macro依然可以摆放。
register:这也是一种特殊的partial blockage, 该blockage区域不允许摆放register,当然也是只在placement阶段起作用,在legalize,optimize阶段时都不起作用。
4、闩锁(LATCH UP)效应
闩锁效应是CMOS工艺所特有的寄生效应,严重会导致电路的失效,甚至烧毁芯片。闩锁效应是由NMOS的有源区、P衬底、N阱、PMOS的有源区构成的n-p-n-p结构产生的,当其中一个三极管正偏时,就会构成正反馈形成闩锁。避免闩锁的方法就是要减小衬底和N阱的寄生电阻,使寄生的三极管不会处于正偏状态。 静电是一种看不见的破坏力,会对电子元器件产生影响。ESD 和相关的电压瞬变都会引起闩锁效应(latch-up),是半导体器件失效的主要原因之一。如果有一个强电场施加在器件结构中的氧化物薄膜上,则该氧化物薄膜就会因介质击穿而损坏。很细的金属化迹线会由于大电流而损坏,并会由于浪涌电流造成的过热而形成开路。这就是所谓的“闩锁效应”。在闩锁情况下,器件在电源与地之间形成短路,造成大电流、EOS(电过载)和器件损坏。
解决方法:
插入陷连接单元(well_tap cell) 限制电源或地与衬底之间的电阻大小。
5、天线效应
在芯片生产过程中,暴露的金属线或者多晶硅(polysilicon)等导体,就象是一根根天线,会收集电荷(如等离子刻蚀产生的带电粒子)导致电位升高。天线越长,收集的电荷也就越多,电压就越高。若这片导体碰巧只接了MOS 的栅,那么高电压就可能把薄栅氧化层击穿,使电路失效,这种现象我们称之为“天线效应”。随着工艺技术的发展,栅的尺寸越来越小,金属的层数越来越多,发生天线效应的可能性就越大。
消除方法:
1) 跳线法。又分为“向上跳线”和“向下跳线”两种方式。跳线即断开存在天线效应的金属层,通过通孔连接到其它层(向上跳线法接到天线层的上一层,向下跳线法接到下一层),最后再回到当前层。这种方法通过改变金属布线的层次来解决天线效应,但是同时增加了通孔,由于通孔的电阻很大,会直接影响到芯片的时序和串扰问题,所以在使用此方法时要严格控制布线层次变化和通孔的数量。
在版图设计中,向上跳线法用的较多,此法的原理是:考虑当前金属层对栅极的天线效应时,上一层金属还不存在,通过跳线,减小存在天线效应的导体面积来消除天线效应。现代的多层金属布线工艺,在低层金属里出现PAE 效应,一般都可采用向上跳线的方法消除。但当最高层出现天线效应时,采用什么方法呢?这就是下面要介绍的另一种消除天线效应的方法了。
2) 添加天线器件,给“天线”加上反偏二极管。通过给直接连接到栅的存在天线效应的金属层接上反偏二极管,形成一个电荷泄放回路,累积电荷就对栅氧构不成威胁,从而消除了天线效应。当金属层位置有足够空间时,可直接加上二极管,若遇到布线阻碍或金属层位于禁止区域时,就需要通过通孔将金属线延伸到附近有足够空间的地方,插入二极管。
3) 给所有器件的输入端口都加上保护二极管。此法能保证完全消除天线效应,但是会在没有天线效应的金属布线上浪费很多不必要的资源,且使芯片的面积增大数倍,这是VLSI 设计不允许出现的。所以这种方法是不合理,也是不可取的。
4) 对于上述方法都不能消除的长走线上的PAE,可通过插入缓冲器,切断长线来消除天线效应
6、MMMC(multi_mode multi-corner) 多模式多端角
MMMC用于在设计中考虑芯片的不同工作模式,且在不同的PVT条件下的为了让芯片在工作时性能可以保持在一定范围。
1) Mode
func:function mode 性能模式 scan:测试模式 sleep mode, standbymode, active mode
2)PVT
process corner
把NMOS和PMOS晶体管的速度波动范围限制在由四个角所确定的矩形内。这四个角分别是:快NFET和快 PFET,慢NFET和慢PFET,快NFET和慢PFET,慢NFET和快PFET。例如,具有较薄的栅氧、较低阈值电压的晶体管,就落在快角附近。从晶片中提取与每一个角相对应的器件模型时,片上NMOS和PMOS的测试结构显示出不同的门延时,而这些角的实际选取是为了得到可接受的成品率。各种工艺角和极限温度条件下对电路进行仿真是决定成品率的基础。TT:nmos -Typical corner & pmos -Typical corner
FF:nmos -Fast corner & pmos -Fast corner
SS:nmos -slow corner & pmos -slowl corner
FS:nmos -Fast corner & pmos -slow corner
SF:nmos -slowl corner & pmos -fast corner
注:Typical是指晶体管驱动电流(Ids)是一个平均值;
Fast是指晶体管驱动电流是最大值;
Slow是指晶体管驱动电流是最小值。
voltage
low nominal high 例:1v+10% 1v 1v-10%
temperature
low nominal high 例:-40C, 0C 25C,125C
PVT组合起来可以形成不同corner:
由于影响cell delay的因素主要有:工艺,电压和温度三种(PVT),由此产生各种corner:
wc:worst case slow,低电压,高温度,慢工艺 -> 一般情况下delay最大,setup 差。
wcl:worst case low-temperature,低电压,低温度,慢工艺 -> 温度反转效应时delay最大,setup差。
lt:即low-temperature,也叫bc(best case fast),高电压,低温度,快工艺 -> 一般情况下delay最小,hold差。
ml:max-leakage,高电压,高温度,快工艺 -> 温度反转效应下delay最小,hold差。
tc:typical,也叫tt,普通电压,普通温度,标准工艺 -> 各种typical。
tips:温度反转效应:传统工艺下,随着温度的降低,单元延时随之减小。但是在先进工艺下,随着温度的降低,单元延时反而增加的一个现象叫作温度反转效应,可以用下面的图形形象地刻画。所以最差的延时既可能发生在温度最高的情况,也可能发生在温度最低的时候。

原因:温度对晶体管有两个影响,一个是晶体管阈值电压,一个是晶体管的迁移率。随着温度降低,晶体管阈值电压增高,晶体管的迁移率提高。但是阈值电压增高会使延时变大,迁移率增加会使延时变小,因而说明在低电压时,对阈值电压的影响起主导作用。
7、静态时序分析(STA)--时序验证
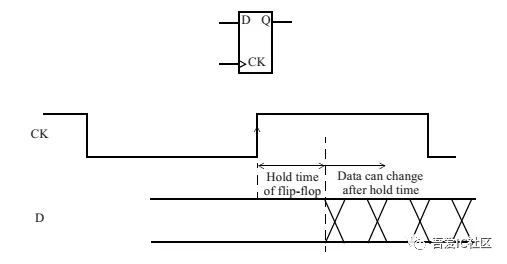
- Setup Time : 在时钟有效沿之前,输入数据必须保持稳定的最小时间,称之为建立时间。(确保从前一时钟周期启动的数据,在一个周期后能够正确捕获。)
- Hold Time : 在时钟的有效沿之后,输入数据必须保持稳定的最小时间,称之为保持时间。(确保该时钟周期捕获的数据可以准确保存)

Setup timing checks:
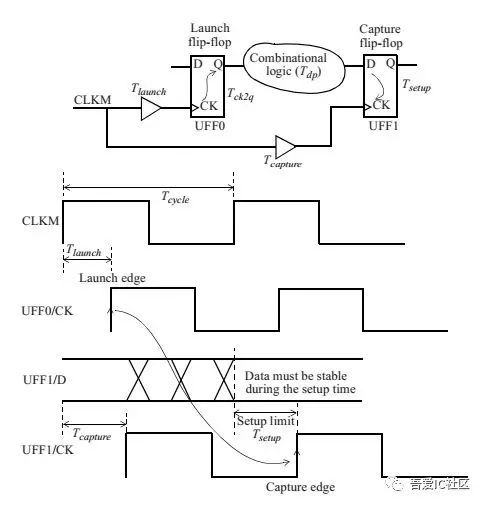
[Tlaunch + Tck2q + Tdp] <= [Tcapture + TCLK – Tsetup]
slack计算:
Data Arrival Time : 数据在datapath上传输的时间 ([Tlaunch + Tck2q + Tdp])
Data Required Time : 时钟在clock path上传输的时间([Tcapture + TCLK – Tsetup])
Setup Slack = Data Required Time – Data Arrival Time
Hold timing checks :
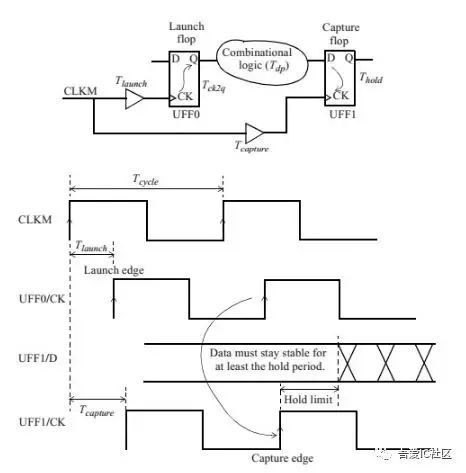
[Tlaunch (时钟延滞)+ Tck2q(门延迟) + Tdp(组合逻辑延迟)] >= [Tcapture + Thold]
slack计算:
Data Arrival Time : 数据在datapath上传输的时间 ([Tlaunch (时钟延滞)+ Tck2q(门延迟) + Tdp(组合逻辑延迟)])
Data Required Time : 时钟在clock path上传输的时间([Tcapture + Thold])
Hold Slack = Data Arrival Time – Data Required Time
Tips:
skew:时钟到达不同寄存器的时间不同,设计时往往需要让其相同以满足时序要求。但是有时利用偏差可以修复时序违例,即为有用偏差。
(14条消息) 时序分析基本概念介绍
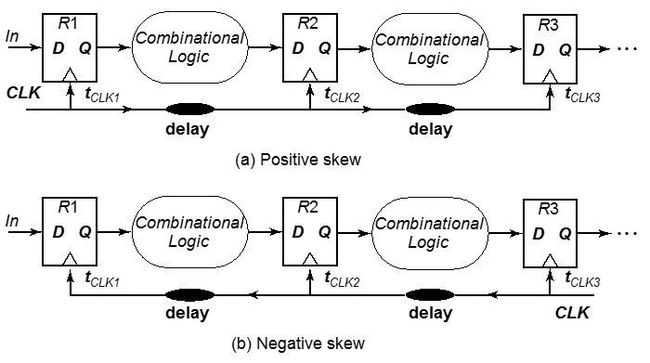
对于positive skew来说,它可以减少T的时间,相当于提升芯片的performace。但是它的hold时间会变得更加难以满足
对于negative skew来说,它的hold时间更加容易满足,取而代之的是,它会降低芯片的性能。
还有另外一种skew的分类方法,是我们更为常见的,根据时钟域以及路径关系, skew 可以分为 global skew ,local skew ,interclock skew。
Global skew 是指,同一时钟域,任意两个路径的最大 skew 。如下图所示,注意是任意两条路径,不管是不是timing path,都会算作gloabl skew计算的对象。CTS时,工具更关注的是global skew, 会尽可能地将global skew做小。

Local skew 是指,同一时钟域,任意两个有逻辑关联关系的路径最大 skew 。这边需要注明,必须是存在逻辑关系的path才会计算local skew,也就是说必须要是timing path。如下图所示,我们在分析timing的时候,更多地是关注local skew。

interClock skew 是指,不同时钟域之间路径的最大 skew,如下图所示:

————————————————
版权声明:本文为CSDN博主「Tao_ZT」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Tao_ZT/article/details/102456828
有用偏差(useful sknew):ps 107-数字集成电路
8、max capacitance and max transition
max transition
net上的transition time是其driving pin改变逻辑值所需要的最长的时间; 决定于上升时间和下降时间,这个约束是基于library给的信息,对于NLDM (非线性延迟模型), 输出的transition time是输入的transition和输出负载的函数;
有很多原因会造成slew的violation,但最主要的分为以下几类:
1)cell的驱动能力太弱
一般情况下,如果我们看到某个cell的output transition比input transition大很多,那说明这个cell的驱动不够,我们可以尝试size up一下,将cell换成可以大驱动的cell,可以驱动更多的fanout
2)fanout数目过大
也是常见的一类容易造成slew violation的情况。过多的fanout会显著恶化pin的transition。
对于这种情况,我们可以通过插入buffer来减少fanout数目
3)net长度太长
过长的net长度也会恶化slew,造成max transition的violation。对于这种情况,我们可以在net的中间插入一个buffer来打断这根net,就可以解掉这个max transition的violation。
max capcitance
max_cap的约束可以限制一个driver的output pin驱动的最大电容,电容包括它驱动的所有load pin上的cap和互连线上的电容。 该约束不允许output pin驱动的电容值大于或者等于约束值。
如果设计中报告存在max_cap的违反,首先看一下最大违反是多少,违反的路径多不多,违反都发生在哪里,然后去分析出现违反的原因。
这种问题出现的原因无非两种:
1、扇出太大;
对于第一种情况,如果出现违反的net很多,那么很有可能是这个原因导致的,可以在sdc时序约束文件中将max_fanout的值设置的小一些,加紧约束。
2、连线太长
对于第二种情况,可以采用手工ECO或者用PT进行ECO,在net中间插入buffer。在ECO的时候要注意物理上的一些问题,例如是否存在filler,是否有足够的空间来size,如何连线等等。
发现的确是由于net太长导致的,那么可以在中间插入buffer,注意buffer的驱动一定要合适,否则可能会引起max_tran的违反。
>insert_buffer[get_nets {mimo_inst/n819}] [get_lib_cells */BUFV8_9TUH35]
>legalize_placement-cells {mimo_inst/eco_cell}或者用legalize_placement -eco
>route_zrt_eco -reroutemodified_nets_first_then_others
>report_constraint-all_violators -scenarios [all_active_scenarios] -significant_digits 4 >../rpts/all_violators.rpt
>update_timing
>create_qor_snapshot-clock_tree -name $ICC_CHIP_FINISH_CEL
9、HVT,SVT和RVT
先介绍一下背景,现在的design对功耗的要求很高,代工厂会提供多种电压阈值的单元库,大致可以分为三类,分别为HVT,SVT,LVT。这里的H/S/L分别为 high/standard/low阈值电压。
HVT cell:阈值电压高,但是功耗低,速度慢,延迟大
LVT cell:阈值电压低,但是功耗高,速度快,延迟小
SVT cell:介于两者之间
10、时序分析模式-pba和gba
GBA全称为graph based analysis,是工具默认的分析方式。它是说工具在从lib中读取cell的delay的时候,永远是读取由最差transition产生的delay。Transition又可以叫slew,是指信号跳变所需的时间,rise transition一般会定电压从10%到90%的时间,fall transition一般是90%到10%的时间。最差transition是什么意思呢?实际上电路在工作的过程中,一个cell收到的input transition是由前一级cell影响的,如果前一级cell的输入有多个,不同pin的输入所带来的output transition会有所不同。举一个简单的例子,一个二输入与门后面接了一级buffer,与门的input有A,B,输出Z,假设原来AB都是1,Z是1,当A从1变成0,B不变的时候,Z的transition假设是10ps,而当B从1变成0,A不变的时候,Z的transition可能不是10ps,可能是5ps。而读取后一级buffer lib的时候,是需要查input transition & output load那个二维表的,10ps和5ps所带来的delay是不一样的。这样工具就会疑惑,我在算这个buffer的delay时,到底用前一级带来的哪个transition呢?而我们的GBA模式,就是总是用最差的transition,10ps。假设某条timing path是经过B pin的,尽管对这条path来说,后一级buffer实际上应该用B所带来的5ps的transition,GBA模式下还是会用10ps。可想而知,这样的分析模式速度会比较快,它可以在timing分析之初就把所有cell的delay都算好,哪条path经过什么cell直接拿现成的结果就行了。但是GBA的结果较为悲观,可能有些path产生了violation,但实际芯片工作时这条path上的transition不可能是另外那个更大的值的。这样的悲观我们是需要剔除掉的,因此引入了PBA的概念。
了解了GBA,PBA也就很好理解了。PBA是path based analysis,指的是我要分析哪条timing path,就用这条timing path的transition来查cell的delay。对应上面的例子,如果用PBA模式就会用B的5ps来算buffer的delay值了。这种算法时间复杂度大大提高,但结果更为精确。
GBA和PBA都有其存在的意义。我们在做STA分析的时候,首先都要快速做一遍GBA,如果没有任何violation,那做PBA肯定也会没有violation,timing可以确保clean。而如果有violation,我们会再诉诸于PBA,但是也不必再分析所有的timing path了,只需要分析那些GBA模式下产生violation的path即可。如果这些path在PBA模式下都pass,那我们同样可以确保芯片timing clean;如果这些path在PBA模式下还遗留几条有violation,那么这几条就是我们真正需要去修的。这其中蕴含了一种很朴素的思想:首先用比实际更苛刻的标准快速筛选数据,再用实际的标准来筛选上一轮的数据,这样可以大大提高筛选效率。
在primetime中pba模式还有path与exhaustive的区别。Path是指重新计算指定的最差path,exhaustive是要重新计算所有产生violation的path。这就不展开讲了,因为我觉得path没什么用,一般项目都会用exhaustive模式。
————————————————
版权声明:本文为CSDN博主「伟酱的芯片后端之路」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_52636726/article/details/122271429
10 track/row/site/pitch

site: 最基本的布局单元,一般是最小cell 的size大小,size的高度和长度是site的整数倍
row: 多个site 排列在一起组成row
track: 布线轨道,7T,9T是说每个std cell 允许布线的最大轨道数目,metal 在布线轨道的中间
pitch :两条布线轨道的间距
halo: 布局晕环,随着cell一起移动
https://blog.csdn.net/XPhp95/article/details/107788308