(10-2-01)贷款预测模型
请大家关注我,本文章粉丝可见,我会一直更新下去,完整代码进QQ群获取:323140750,大家一起进步、学习。
贷款预测模型是一种机器学习模型,用于预测个人或机构是否有资格获得贷款,以及贷款的条件,如贷款金额和利率。这种模型在银行和金融机构中广泛应用,有助于自动化贷款批准流程、提高效率、减少风险和改善客户体验。在本节的内容中,将详细讲解为某银行信贷部门开发一个贷款预测模型,使用各种机器学习技术实现了多种模型供用户选择。
实例10-1:基于机器学习的银行贷款预测模型(源码路径:daima/10/loan-prediction- models.ipynb)
10.2.1 项目背景
假设某银行信贷人员需要根据客户在在线申请表格中提供的信息,实时自动化贷款资格审查程序。银行期望开发人员可以帮助其预测贷款批准的机器学习模型,以加速决策流程,确定申请人是否有获得贷款的资格。
10.2.2 数据集介绍
本项目的数据集是CSV文件,整个数据集包含13个样本变量:8个分类变量,4个连续变量,以及1个变量用于存储贷款ID。数据集中各个样本变量的具体说明如下:
- Loan_ID:贷款编号(唯一ID),例如LP001002; LP001003。
- Gender:申请人性别(男性或女性)。
- Married:申请人婚姻状况(已婚或未婚)。
- Dependents:家庭成员数量,例如1、2、3。
- Education:申请人教育状况(毕业或未毕业)。
- Self_Employed:申请人就业状况(是/否) 。
- ApplicantIncome:申请人的月薪/收入,例如5849、4583。
- CoapplicantIncome:额外申请人的月薪/收入,例如1508、2358; ...
- LoanAmount:贷款金额,例如128,66,2900。
- Loan_Amount_Term:贷款的还款期限(以天为单位),例如3,600,12,000。
- Credit_History:先前信用历史的记录(0: 不良信用历史, 1: 良好信用历史),例如0,1。
- Property_Area:房产的位置(农村/半城市/城市),例如农村,半城市,城市。
- Loan_Status:贷款状态(Y: 已接受, N: 未接受)。
10.2.3 数据探索
数据探索是用来了解数据、发现潜在关系、识别异常值和数据分布等的过程,在数据探索阶段通常会执行以下操作:
- 计算描述性统计,如均值、中位数、标准差等,以了解数据的基本特性。
- 绘制直方图、箱线图、散点图等可视化图表,以可视化数据的分布和关系。
- 检查缺失值,异常值和重复数据,并决定如何处理它们。
- 探索不同特征之间的关系,例如特征之间的相关性。
数据探索的目标是帮助我们更好地理解数据,为数据预处理和建模过程提供指导。一旦您对数据有了更深入的了解,就可以采取适当的预处理步骤,以确保数据质量和适用性,然后继续建立和训练模型。注意,数据探索通常是数据预处理的一部分,但并不等同于数据预处理。
1. Categorical Variable(分类变量)分析
"Categorical Variable" 是指在统计学和数据分析中,用于表示不同类别或离散取值的变量。这些类别可以是有限的、固定的,通常代表某种特定属性或特征,而不是具有连续数值的变化。举例来说,性别(男、女)、教育程度(高中、本科、硕士)、婚姻状况(已婚、未婚)等都属于分类变量的示例。这些变量通常不能进行数学上的常规运算,而是用于描述和分类数据。
在数据分析中,对分类变量的处理通常包括创建虚拟变量(或称为独热编码),以便在机器学习模型中使用。这些虚拟变量将每个类别分成不同的二进制特征,使得机器学习算法能够处理它们。
(1)读取数据集文件train_u6lujuX_CVtuZ9i (1).csv,并将其加载到一个名为"df"的Pandas DataFrame中。接下来,通过调用"df.head()"来显示DataFrame的前几行数据,以便查看数据的样本。具体实现代码如下所示。
df = pd.read_csv("../input/loan-predication/train_u6lujuX_CVtuZ9i (1).csv")
df.head()
执行后输出前5行信息:
Loan_ID Gender Married Dependents Education Self_Employed ApplicantIncome CoapplicantIncome LoanAmount Loan_Amount_Term Credit_History Property_Area Loan_Status
0 LP001002 Male No 0 Graduate No 5849 0.0 NaN 360.0 1.0 Urban Y
1 LP001003 Male Yes 1 Graduate No 4583 1508.0 128.0 360.0 1.0 Rural N
2 LP001005 Male Yes 0 Graduate Yes 3000 0.0 66.0 360.0 1.0 Urban Y
3 LP001006 Male Yes 0 Not Graduate No 2583 2358.0 120.0 360.0 1.0 Urban Y
4 LP001008 Male No 0 Graduate No 6000 0.0 141.0 360.0 1.0 Urban Y
(2)打印DataFrame "df" 的形状信息,即行数和列数。具体实现代码如下所示。
print(df.shape)
执行后输出:
(614, 13)
(3)统计数据框(DataFrame) df 中 "Loan_ID" 列中每个唯一值的出现次数。value_counts() 函数用于计算分类或离散变量的直方图,这里是用于 "Loan_ID" 列。具体实现代码如下所示。
df.Loan_ID.value_counts(dropna=False)
执行后会输出:
LP001002 1
LP002328 1
LP002305 1
LP002308 1
LP002314 1
..
LP001692 1
LP001693 1
LP001698 1
LP001699 1
LP002990 1
Name: Loan_ID, Length: 614, dtype: int64
由此可以看到,在数据集中有614个唯一的ID。
(4)统计数据集中性别(Gender)这一列的不同取值的数量,使用了value_counts()函数来完成这个任务。具体实现代码如下所示。
df.Gender.value_counts(dropna=False)
执行后输出:
Male 489
Female 112
NaN 13
Name: Gender, dtype: int64
结果显示在数据集中,男性(Male)有489人,女性(Female)有112人,同时还有13个缺失数据(NaN)。这可以帮助我们了解性别数据的分布情况。
(5)使用Seaborn库创建一个计数图(countplot),用于可视化性别(Gender)列在数据集中的分布情况。具体实现代码如下所示。
sns.countplot(x="Gender", data=df, palette="hls")
plt.show()
执行效果如图10-1所示,该计数图以性别为横坐标,纵坐标表示每个性别的数量。
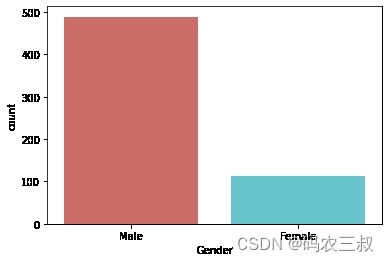
图10-1 性别分布情况可视化图
(6)计算性别(Gender)列中不同性别的数量以及缺失值的百分比,并将计算结果打印出来。具体实现代码如下所示。
countMale = len(df[df.Gender == 'Male'])
countFemale = len(df[df.Gender == 'Female'])
countNull = len(df[df.Gender.isnull()])
print("Percentage of Male applicant: {:.2f}%".format((countMale / (len(df.Gender))*100)))
print("Percentage of Female applicant: {:.2f}%".format((countFemale / (len(df.Gender))*100)))
print("Missing values percentage: {:.2f}%".format((countNull / (len(df.Gender))*100)))执行后输出:
Percentage of Male applicant: 79.64%
Percentage of Female applicant: 18.24%
Missing values percentage: 2.12%(7)计算数据框(DataFrame)中“Married”列的不同取值的数量,包括缺失值(NaN)。这个列的含义是申请人的婚姻状况。通过 value_counts 方法,可以得到每个不同取值的计数。具体实现代码如下所示。
df.Married.value_counts(dropna=False)执行后输出:
Yes 398
No 213
NaN 3
Name: Married, dtype: int64(8)使用Seaborn库创建一个柱状图(countplot)来可视化婚姻状况("Married"列)的数据分布。具体实现代码如下所示。
sns.countplot(x="Married", data=df, palette="Paired")
plt.show()执行效果如图10-2所示,x轴显示了婚姻状况的两个可能取值:“已婚”和“未婚”。通过这个图表,可以直观地看到数据中已婚和未婚申请人的数量分布情况。
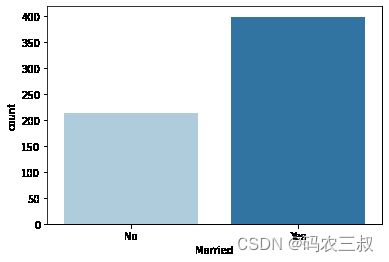
图10-2 婚姻状况可视化图
(9)计算了婚姻状况("Married"列)的不同类别数量以及缺失值的百分比,通过除以总样本数来计算每个类别的百分比,并使用.format格式化字符串来打印这些百分比值。具体实现代码如下所示。
countMarried = len(df[df.Married == 'Yes'])
countNotMarried = len(df[df.Married == 'No'])
countNull = len(df[df.Married.isnull()])
print("Percentage of married: {:.2f}%".format((countMarried / (len(df.Married))*100)))
print("Percentage of Not married applicant: {:.2f}%".format((countNotMarried / (len(df.Married))*100)))
print("Missing values percentage: {:.2f}%".format((countNull / (len(df.Married))*100)))执行后输出:
Percentage of married: 64.82%
Percentage of Not married applicant: 34.69%
Missing values percentage: 0.49%这样,可以了解在数据集中已婚和未婚申请人的比例,以及婚姻状况缺失值的百分比。这些信息有助于理解数据的分布和质量。
(10)计算教育水平("Education"列)的不同类别数量以及缺失值的百分比,通过除以总样本数来计算每个类别的百分比,并使用.format格式化字符串来打印这些百分比值。具体实现代码如下所示。
df.Education.value_counts(dropna=False)执行后会输出:
Graduate 480
Not Graduate 134
Name: Education, dtype: int64这样,可以了解在数据集中受过高等教育和未受过高等教育的申请人比例,以及教育水平缺失值的百分比。这些信息有助于理解数据的分布和质量。
(11)使用Seaborn库中的函countplot数生成了一个柱状图,用于可视化教育水平("Education"列)的不同类别在数据集中的分布情况。具体实现代码如下所示。
sns.countplot(x="Education", data=df, palette="rocket")
plt.show()执行效果如图10-3所示,这个图形可以帮助我们更好地理解受过高等教育和未受过高等教育的申请人在数据集中的分布情况。
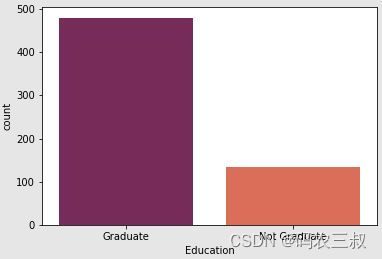
图10-3 可视化教育水平的分布情况
(12)计算数据集中教育水平("Education"列)不同类别的数量,并计算了缺失值的百分比。具体实现代码如下所示。
countGraduate = len(df[df.Education == 'Graduate'])
countNotGraduate = len(df[df.Education == 'Not Graduate'])
countNull = len(df[df.Education.isnull()])
print("Percentage of graduate applicant: {:.2f}%".format((countGraduate / (len(df.Education))*100)))
print("Percentage of Not graduate applicant: {:.2f}%".format((countNotGraduate / (len(df.Education))*100)))
print("Missing values percentage: {:.2f}%".format((countNull / (len(df.Education))*100)))执行后输出:
Percentage of graduate applicant: 78.18%
Percentage of Not graduate applicant: 21.82%
Missing values percentage: 0.00%(13)计算数据集中"Self_Employed"列的不同类别的数量,并计算了缺失值的百分比。通过百分比形式打印了这些数量和缺失值的百分比,这些百分比提供了有关数据集中自雇状态的分布以及缺失值的信息。具体实现代码如下所示。
df.Self_Employed.value_counts(dropna=False)执行后输出:
No 500
Yes 82
NaN 32
Name: Self_Employed, dtype: int64(14)使用Seaborn库的countplot函数创建了一个关于"Self_Employed"列的柱状图,其中x轴表示"Self_Employed"的不同类别("Yes"和"No"),y轴表示每个类别出现的次数。颜色使用了Seaborn的"crest"调色板。具体实现代码如下所示。
sns.countplot(x="Self_Employed", data=df, palette="crest")
plt.show()执行效果如图10-4所示。
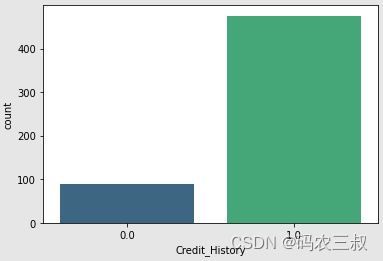
图10-4 Self_Employed列的柱状图