大数据StarRocks(二) StarRocks集群部署
一、生产机器资源评估
1.梳理数据量,包括每天增量数据接入和全量数据接入
2.数据存储时间长度(1个月/3个月/半年/1年/三年等)
3.报表的SQL查询数量,SQL查询占用资源的统计,需要提前做好压测
4.压测可以采用官网提供的压测工具先进行测试,根据测试数据进行资源调整,然后再要业务数据进行压测一遍
最终以压测中预期结果最好的机器配置进行申请,如果公司很rich的话,直接用80c/256G的机器配置。
二、部署
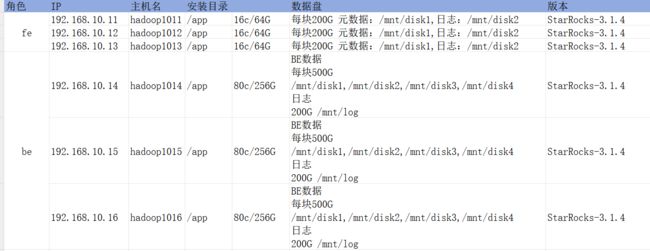
划分角色
(1)安装之前先使用命令检查CPU是否支持,有信息输出则支持,没信息输出则不支持建议更换机器
[root@hadoop1011 /app]# cat /proc/cpuinfo |grep avx2|head -1
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid tsc_known_freq pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm cmp_legacy cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw topoext invpcid_single vmmcall tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves clzero xsaveerptr rdpru wbnoinvd arat vaes vpclmulqdq rdpid
另外检查数据盘挂载情况,cpu核数,内存大小
机器直接的网络连通性
(2)下载tar包,并重命名
[root@hadoop1011 /app]# wget https://releases.starrocks.io/starrocks/StarRocks-3.1.4.tar.gz
(3)解压tar包
[root@hadoop1011 /app]# tar -zxvf StarRocks-3.1.4.tar.gz
(4)部署FE,修改配置文件,添加jvm参数,建议-Xmx参数设置到16G以上
[root@hadoop1011 /app]# cd /app/StarRocks-3.1.4/fe/conf/
[root@hadoop1011 conf]# vim fe.conf
LOG_DIR = ${STARROCKS_HOME}/log
DATE = "$(date +%Y%m%d-%H%M%S)"
JAVA_OPTS="-Dlog4j2.formatMsgNoLookups=true -Xmx32768m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:${LOG_DIR}/fe.gc.log.$DATE -XX:+PrintConcurrentLocks"
JAVA_OPTS_FOR_JDK_9="-Dlog4j2.formatMsgNoLookups=true -Xmx32768m -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xlog:gc*:${LOG_DIR}/fe.gc.log.$DATE:time"
meta_dir = ${STARROCKS_HOME}/meta
sys_log_level = INFO
http_port = 8030
rpc_port = 9020
query_port = 9030
edit_log_port = 9010
mysql_service_nio_enabled = true
[root@hadoop1011 /app]# cd /app/StarRocks-3.1.4/be/conf/
[root@hadoop1011 conf]# vim be.conf
default_rowset_type=beta
be_port=9060
sys_log_level=INFO
sys_log_verbose_modules=
storage_root_path=/mnt/disk1/starrocks/storage;/mnt/disk2/starrocks/storage;/mnt/disk3/starrocks/storage;/mnt/disk4/starrocks/storage;
priority_networks=192.168.10.14/24
webserver_port=8040
brpc_port=8060
heartbeat_service_port=9050
sys_log_roll_num=10
sys_log_roll_mode=SIZE-MB-1024
[root@hadoop1011 /app]# tar -zcvf StarRocks-3.1.4-new.tar.gz StarRocks-3.1.4/
[root@hadoop1011 /app]# python -m SimpleHTTPServer
priority_networks配置随be主机的IP
hadoop1015/hadoop1016
priority_networks=192.168.10.15/24
priority_networks=192.168.10.16/24
其他节点下载安装包并解压
示例:
[root@hadoop1012 /app]# wget 192.168.10.11:8000/StarRocks-3.1.4-new.tar.gz
[root@hadoop1012 /app]# tar -zxvf StarRocks-3.1.4-new.tar.gz
(5)hadoop1011/hadoop1012/hadoop103机器上创建元数据目录
[root@hadoop1011 ]# cd /app/StarRocks-3.1.4/fe
[root@hadoop1011 ]# mkdir -p meta
(6)启动hadoop1011 FE节点
[root@hadoop1011 ]#cd /app/StarRocks-3.1.4/fe
[root@hadoop1011 fe]# bin/start_fe.sh --daemon
(7)启动mysql客户端,访问FE,查看FE状况
[root@hadoop1011 fe]# mysql -h hadoop1011 -uroot -P9030
mysql> SHOW PROC '/frontends'\G
MySQL [(none)]> show frontends \G;
*************************** 1. row ***************************
Name: 192.168.10.11_9010_1698302659926
IP: 192.168.10.11
EditLogPort: 9010
HttpPort: 8030
QueryPort: 9030
RpcPort: 9020
Role: LEADER
ClusterId: 1085778829
Join: true
Alive: true
ReplayedJournalId: 1774256
LastHeartbeat: 2024-01-03 00:45:22
IsHelper: true
ErrMsg:
StartTime: 2023-11-24 09:53:06
Version: 3.1.4-0c4b2a3
(8)添加其他FE节点,角色也分为FOLLOWER,OBSERVER
mysql> ALTER SYSTEM ADD FOLLOWER "hadoop1012:9010";
mysql> ALTER SYSTEM ADD FOLLOWER "hadoop1013:9010";
(9)启动hadoop1012,hadoop1013 FE节点,第一次启动需指定–helper参数,后续再启动无需指定此参数
[root@hadoop1012 fe]# bin/start_fe.sh --helper hadoop1011:9010 --daemon
[root@hadoop1013 fe]# bin/start_fe.sh --helper hadoop1011:9010 --daemon
(10)全部启动完毕后,再使用mysql客户端查看FE的状况,alive全显示true则无问题
MySQL [(none)]> show frontends \G;
*************************** 1. row ***************************
Name: 192.168.10.11_9010_1698302659926
IP: 192.168.10.11
EditLogPort: 9010
HttpPort: 18030
QueryPort: 9030
RpcPort: 9020
Role: LEADER
ClusterId: 1085778829
Join: true
Alive: true
ReplayedJournalId: 1774256
LastHeartbeat: 2024-01-03 00:45:22
IsHelper: true
ErrMsg:
StartTime: 2023-11-24 09:53:06
Version: 3.1.4-0c4b2a3
*************************** 2. row ***************************
Name: 192.168.10.12_9010_1698303243473
IP: 192.168.10.12
EditLogPort: 9010
HttpPort: 8030
QueryPort: 9030
RpcPort: 9020
Role: FOLLOWER
ClusterId: 1085778829
Join: true
Alive: true
ReplayedJournalId: 1774256
LastHeartbeat: 2024-01-03 00:45:22
IsHelper: true
ErrMsg:
StartTime: 2023-11-21 15:56:57
Version: 3.1.4-0c4b2a3
*************************** 3. row ***************************
Name: 192.168.10.13_9010_1698303248816
IP: 192.168.10.13
EditLogPort: 9010
HttpPort: 8030
QueryPort: 9030
RpcPort: 9020
Role: FOLLOWER
ClusterId: 1085778829
Join: true
Alive: true
ReplayedJournalId: 1774256
LastHeartbeat: 2024-01-03 00:45:22
IsHelper: true
ErrMsg:
StartTime: 2023-11-21 15:57:49
Version: 3.1.4-0c4b2a3
(11) 添加BE
mysql> ALTER SYSTEM ADD BACKEND "hadoop1014:9050";
mysql> ALTER SYSTEM ADD BACKEND "hadoop1015:9050";
mysql> ALTER SYSTEM ADD BACKEND "hadoop1016:9050";
(12)部署BE,用户可以使用命令直接将BE添加到集群中,一般至少布置3个BE,每个BE实例添加步骤相同
[root@hadoop1014 app]# cd StarRocks-3.1.4/be/
[root@hadoop1014 be]# /mnt/disk{1..4}/starrocks/storage
[root@hadoop1014 be]# bin/start_be.sh --daemon
(13)在每个BE节点上部署Broker,Broker是无状态服务,此角色主要用于后续Broker load使用,启动安装目录的Broker服务
[root@hadoop1014 StarRocks-3.1.4]# cd apache_hdfs_broker/
[root@hadoop1014 apache_hdfs_broker]# bin/start_broker.sh --daemon
(14)添加对应BROKER 节点
mysql> ALTER SYSTEM ADD BROKER broker1 "hadoop1014:8000";
mysql> ALTER SYSTEM ADD BROKER broker2 "hadoop1015:8000";
mysql> ALTER SYSTEM ADD BROKER broker3 "hadoop1016:8000";
(15)查看状态
MySQL [(none)]> SHOW PROC "/brokers"\G
*************************** 1. row ***************************
Name: broker
IP: 192.168.10.14
Port: 8000
Alive: true
LastStartTime: 2023-04-10 21:43:32
LastUpdateTime: NULL
ErrMsg:
*************************** 2. row ***************************
Name: broker
IP: 192.168.10.15
Port: 8000
Alive: true
LastStartTime: 2023-04-10 21:44:32
LastUpdateTime: NULL
ErrMsg:
*************************** 3. row ***************************
Name: broker
IP: 192.168.10.16
Port: 8000
Alive: true
LastStartTime: 2023-04-10 21:45:32
LastUpdateTime: NULL
ErrMsg:
StarRocks集群部署介绍到这里,欢迎评论,收藏,转发~