【LMM 008】Instruction Tuning with GPT-4
论文标题:Instruction Tuning with GPT-4
论文作者:Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, Jianfeng Gao
作者单位:Microsoft Research
论文原文:https://arxiv.org/abs/2304.03277
论文出处:–
论文被引:254(12/31/2023)
论文代码:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM,3.7k star
项目主页:https://instruction-tuning-with-gpt-4.github.io/
ABSTRACT
先前的工作表明,使用机器生成的指令遵循(instruction-following)数据对大型语言模型(LLM)进行微调,可使这些模型在新任务上实现出色的零样本能力,而且无需人类编写指令。在本文中,我们首次尝试使用 GPT-4 生成用于 LLM 微调的指令遵循数据。我们对经过指令微调的 LLaMA 模型进行的早期实验表明,GPT-4 生成的 52K 中英文指令遵循数据在新任务上的零样本性能优于之前最先进模型生成的指令遵循数据。我们还收集了来自 GPT-4 的反馈和对比数据,以便进行综合评估和奖励模型训练。
1 INTRODUCTION
大型语言模型(LLMs)已显示出令人印象深刻的泛化能力,如上下文学习(in-context learning)(Brown et al., 2020)和思维链推理(chain-of-thoughts reasoning)(Wei et al., 2022)。为了让 LLMs 遵循自然语言指令完成现实世界的任务,研究人员一直在探索对 LLMs 进行指令微调的方法。
- 具体做法是利用人工标注的提示和反馈,在各种任务中对模型进行微调(Ouyang et al., 2022);
- 或者利用人工或自动生成指令的公共基准和数据集进行有监督的微调(Wang et al., 2022b)。
- 在这些方法中,Self-Instruct tuning(Wang et al., 2022a)是一种简单有效的方法,它通过学习最先进的指令微调教师 LLM 生成的指令遵循数据,使 LLM 与人类意图保持一致。
事实证明,指令微调研究已经产生了有效的方法来提高 LLMs 的零样本泛化能力和小样本泛化能力。
- 最近,ChatGPT(OpenAI, 2023a)和 GPT-4(OpenAI, 2023b)的成功为利用指令微调改进开源 LLM 提供了巨大的机会。
- LLaMA(Touvron et al., 2023)是一系列开源 LLM,其性能与 GPT-3 等专有 LLM 不相上下。为了让 LLaMA 遵循指令,Self-Instruct 微调技术以其卓越的性能和低廉的成本被迅速采用。
- 斯坦福大学的 Alpaca(Taori et al., 2023)使用由 GPT-3.5 生成的 52K 指令遵循样本。
- Vicuna(Vicuna,2023)使用 shared user-ChatGPT(ShareGPT,2023)的约 700K 指令遵循样本(70K 对话数据)。
为了提升 LLM 的指令微调技术水平,我们首次提出使用 GPT-4 作为self-instruct微调(self-instruct tuning)的教师。我们的论文有以下贡献:
-
GPT-4 数据。我们发布了由 GPT-4 生成的数据,包括 52K 中英文指令遵循数据集,以及由 GPT-4 生成的对三个指令微调模型的输出进行评级的反馈数据。
-
模型与评估。基于 GPT-4 生成的数据,我们开发了经过指令微调的 LLaMA 模型和奖励模型。为了评估经过指令微调的 LLM 的质量,我们使用了在测试样本(即未见过的指令)上进行评估的三个指标:
- 根据三个对齐标准进行的人工评估
- 使用 GPT-4 反馈进行的自动评估
- 在非自然指令上进行的 ROUGE-L 评估(Honovich et al., 2022)
我们的研究验证了使用 GPT-4 生成的数据进行 LLM 指令微调的有效性,并提出了构建由 LLM 驱动的通用指令遵循智能体(Agent)的实用技巧。

2 DATASET
Data Collection.
我们在 Alpaca 数据集(Taori et al., 2023) 中收集的指令遵循数据中重用了 52K 个独特的指令。每条 instruction 都描述了模型应该执行的任务。我们遵循相同的提示策略来考虑有和没有 input 入的情况,这是任务的可选上下文或输入。output 是使用 LLM 对指令实例的答案。在 Alpaca 数据集中,输出是使用 GPT-3.5(text-davinci-003)生成的,但我们改为考虑 GPT-4 进行数据生成。具体来说,我们使用 GPT-4 生成以下四个数据集:
- 1)English Instruction-Following Data: 对于 Alpaca(Taori et al., 2023)中收集的 52K 条指令,我们为每条指令提供一个英文 GPT-4 答案。具体细节见 Algorithm 1。我们将在今后的工作中使用 GPT-4 和 self-instruct(Wang et al., 2022a)迭代构建我们自己的指令集。
- 2)Chinese Instruction-Following Data: 我们使用 ChatGPT 将 52K 指令翻译成中文,并要求 GPT-4 用中文回答。这样,我们就可以建立一个基于 LLaMA 的中文指令遵循模型,并研究指令调优的跨语言泛化能力。
- 3)Comparison Data: 我们要求 GPT-4 对自己的回答从 1 到 10 进行评分。此外,我们还要求 GPT-4 比较和对三个模型的响应进行评分,包括:GPT-4,GPT-3.5 和 OPT-IML (Iyer et al., 2022) 。这将用于训练奖励模型。
- 4)Answers on Unnatural Instructions:GPT-4 答案是在 68K instruction-input-output 三元组的核心数据集上解码的(Honovich et al., 2022)。该子集用于量化 GPT-4 与我们的指令微调模型在规模上的差距。
Data Statistics.
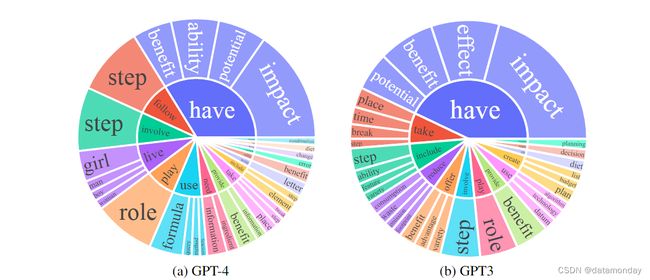
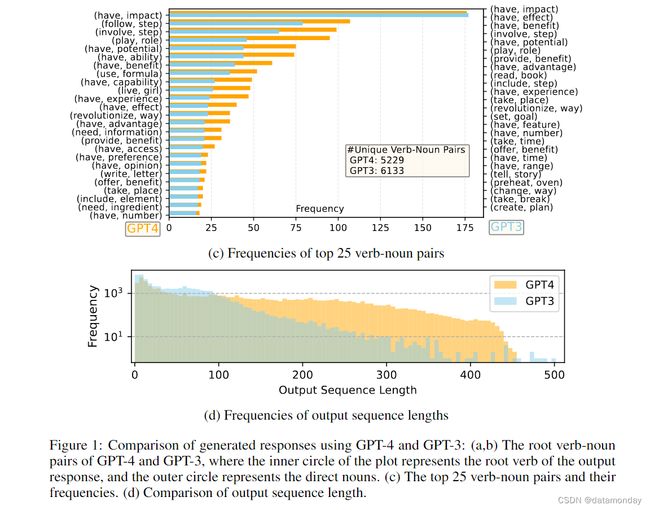
图 1 比较了 GPT-4 和 GPT-3.5 的英语输出响应集合。提取了每个输出的动词词根和直接宾语名词;计算了每个响应集合上唯一的动词名词对的频率。
- 图 1 (a) 和 (b) 显示了频率高于 10 的动名词对
- 图 1 © 比较了两组中频率最高的 25 对动名词对
- 图 1(d) 比较了序列长度的频率分布
GPT-4 产生的序列往往比 GPT-3.5 长。Alpaca 中的 GPT-3.5 数据显示的输出分布比 GPT-4 生成的输出分布的尾部更长,这可能是因为 Alpaca 数据集涉及一个迭代数据收集过程,每次迭代都会删除类似的指令实例,而我们目前的一次性数据生成过程中不存在这种情况。尽管过程简单,GPT-4 生成的指令遵循数据还是表现出了更出色的对齐性能,这一点在后面的实验中将有所体现。
3 INSTRUCTION-TUNING LANGUAGE MODELS
3.1 SELF-INSTRUCT TUNING
我们使用 LLaMA 7B 检查点进行监督微调,训练了两个模型:
- i)LLaMA-GPT4 是在由 GPT-4 生成的 52K 英文指令遵循数据上训练的,其分布如图 1 所示;
- ii)LLaMA-GPT4-CN 是在由 GPT-4 生成的 52K 中文指令遵循数据上训练的。
为了进行公平比较,我们按照(Taori et al. 2023)中的训练计划进行公平比较。这些模型用于研究 GPT-4 的数据质量以及在一种语言中对 LLM 进行指令调优时的跨语言泛化特性。
3.2 REWARD MODELS
从人类反馈中强化学习(RLHF)旨在使 LLM 行为符合人类偏好,从而使其更加有用。奖励建模是 RLHF 的一个关键组成部分,它将问题表述为一项回归任务,即根据提示(prompt)和响应(response)预测标量奖励(Askell et al., 2021 ;Ouyang et al., 2022)。这种方法通常需要大规模的比较数据,对同一提示下的两个模型响应进行比较(Ouyang et al., 2022)。由于标注对比数据的成本较高,Alpaca,Vicuna,Dolly(Databricks,2023)等现有开源工作不涉及 RLHF。同时,最近的研究表明,GPT-4 能够识别和修正自身的错误,并准确判断响应的质量(Peng et al., 2023;Bai et al., 2022;Madaan et al., 2023;Kim et al., 2023)。因此,为了促进对 RLHF 的研究,我们使用 GPT-4 创建了对比数据,详见第 2 节。
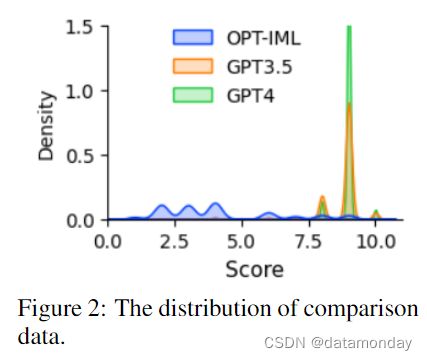
为了评估数据质量,我们训练了一个基于 OPT 1.3B 的奖励模型(Iyer et al., 2022)来对不同的回答进行评分。对于涉及一个提示 x 和 K 个回答的每个对比数据实例,GPT-4 会为每个回答分配一个分数 s∈ [1, 10]。从这个实例中构建出 C 2 K C^K_2 C2K 个唯一的对,每个对为(yl, yh),其对应的分数为 sl < sh。以 θ 为参数的奖励模型 rθ 的训练目标为:min log(σ(rθ (x, yh) - rθ (x, yl))),其中 σ 为 sigmoid 函数。对比数据的分布如图 2 所示。
4 EXPERIMENTAL RESULTS
4.1 BENCHMARKS
众所周知,LLM 评估仍然是一项重大挑战。我们的目标是在 GPT-4 数据上对未见指令的self-instruct微调模型进行评估,以研究它们在任意任务中遵循指令的能力。具体来说,我们在研究中使用了三个已建立的数据集:
- User-Oriented-Instructions-252(Wang et al., 2022a)是一个人工编辑的数据集,包含 252 个指令,其动机来自 71 个面向用户的应用程序,如 Grammarly,StackOverflow,Overleaf,而不是经过充分研究的 NLP 任务。
- Vicuna-Instructions-80(Vicuna,2023)是由 gpt-4 合成的数据集,包含 80 个基线模型认为具有挑战性的问题。除通用指令外,还有 8 个类别,包括:knowledge, math, Fermi, counterfactual, roleplay, generic, coding, writing, common-sense。
- Unnatural Instructions(Honovich et al., 2022)是由 text-davinci-002 根据 15 个手动构建的示例,使用 3-shot in-context-learning 合成的数据集,包含 68,478 个样本。
4.2 HUMAN EVALUATION WITH ALIGNMENT CRITERIA
为了评估经过指令微调的 LLM 的对齐质量,我们遵循了 Anthropic Askell et al.(2021)提出的对齐标准:如果一个助手是有益的,诚实的和无害的(Helpful, Honest, and Harmless,HHH),那么它就是对齐的。这些标准用于评估人工智能系统与人类价值观的一致性。
- Helpfulness:是否有助于人类实现目标。能准确回答问题的模型就是有用的。
- Honesty:是否提供真实信息,并在必要时表达其不确定性,以避免误导人类用户。提供虚假信息的模型是不诚实的。
- Harmlessness:是否不会对人类造成伤害。产生仇恨言论或宣扬暴力的模型不是无害的。
根据 HHH 对齐标准,我们使用 Amazon Mechanical Turk 对模型生成结果进行人工评估。界面见附录 A.1 节。按照(Wang et al., 2022a;Taori et al., 2023),我们考虑使用 252 个面向用户的指令进行评估。我们在图 3 中以饼图的形式显示了人工评估结果。
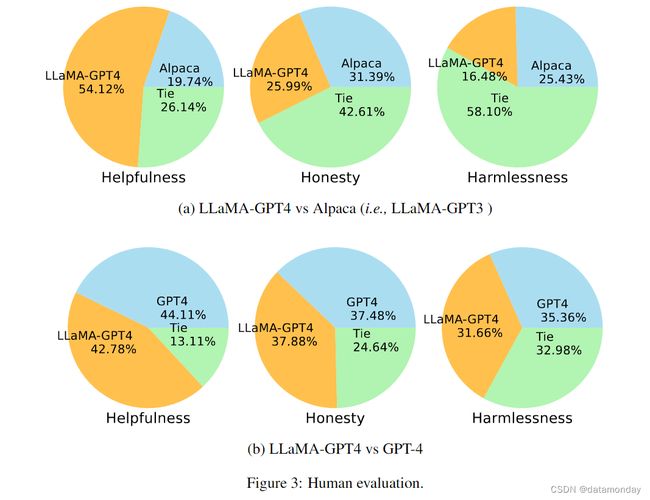
首先,我们比较了两个经过指令微调的 LLaMA 模型生成的响应质量,这两个模型分别根据 GPT-4 和 GPT-3 生成的数据进行了微调。请注意,将 LLaMA 与 GPT-3 对齐相当于斯坦福 Alpaca 模型。从图 3(a)中,我们可以观察到:
- (i) 在 “Helpfulness” 标准方面,GPT-4 以 54.12% 的票数明显胜出。而 GPT-3 只赢得了 19.74% 的选票。
- (ii) 在 “Honesty” 和 “Harmlessness” 标准方面,大多数投票属于平局(Tie)类别,大大高于获胜类别,但 GPT-3 (Alpaca) 略胜一筹。
其次,我们在图 3(b) 中比较了 GPT-4 和教师模型 GPT-4 的 LLaMA 模型。这三个标准的观察结果非常一致: 经过 GPT-4 指令微调的 LLaMA 与原始 GPT-4 的表现类似。我们的结论是,从 GPT-4 生成的数据中学习,可以在未见过的教学任务中获得与原始 GPT-4 非常相似的性能,这为开发最先进的指令遵循 LLM 提供了一个很好的方向。
4.3 COMPARISONS WITH SOTA USING AUTOMATIC EVALUATION
Automatic Evaluation with GPT-4.
继(Vicuna, 2023)之后,我们使用 GPT-4 自动评估不同模型对(Vicuna, 2023)中 80 个未见问题生成的回答。我们首先收集了两个聊天机器人的回答,包括 LLaMA-GPT-4 (7B) 和 GPT-4,然后使用(Vicuna, 2023)中其他聊天机器人发布的回答,包括 LLaMA (13B),Alpaca (13B),Vicuna (13B),Bard (Google, 2023) 和 ChatGPT。在每次评估中,我们都会要求 GPT-4 对两个模型的响应质量进行评分,分数从 1 到 10 不等。我们将所有模型分别与 ChatGPT 和 GPT-4 等强有力的竞争模型进行比较。结果如图 4 所示。
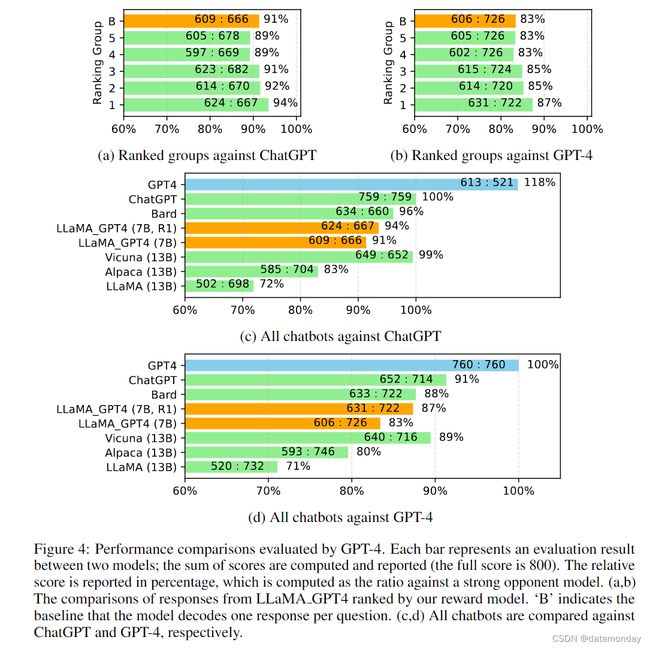
对于使用 GPT-4 指令微调的 LLaMA,我们提供了两组解码结果:
- i)每题一个答案,这被视为基准解码结果。
- ii)每个问题五个答案。对于后者,我们使用奖励模型对回答进行排序,然后将其分为五个子集,从最前面的 1 到最前面的 5 依次排列。我们将这五个分组与基线进行比较,并在图 4(a,b)中显示了相对分数。
ChatGPT 和 GPT-4 的评估结果与我们的奖励模型所建议的顺序一致,这证明了反馈数据的价值和奖励模型的有效性。
我们在图 4(c,d)中对所有聊天机器人进行了比较。使用 GPT-4 对 LLaMA 进行指令微调后,其性能往往高于使用 text-davinci-003 进行微调(Alpaca)和不进行微调(LLaMA): 7B LLaMA GPT4 的性能优于 13B Alpaca 和 LLaMA。但是,与 GPT-4 等大型商业聊天机器人相比仍有差距。
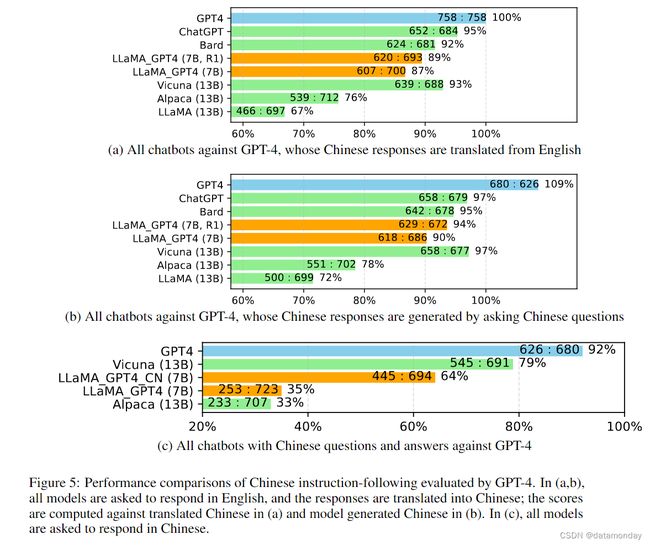
我们在图 5 中进一步研究了所有聊天机器人的中文性能。我们首先使用 GPT-4 将聊天机器人的英文回复翻译成中文。我们还用 GPT-4 将英文问题翻译成中文,以获得答案。图 5(a)和(b)分别显示了与 GPT-4 翻译和生成的中文回复的对比。有两个有趣的观察结果:
- i)我们发现 GPT-4 评估的相对分数指标(Vicuna,2023)在不同的对手模型(即 ChatGPT 或 GPT-4)和语言(即英语或中文)方面都是相当一致的;
- ii)仅就 GPT-4 的结果而言,翻译的回答比生成的中文回答表现更优,这可能是因为 GPT-4 是在比中文更丰富的英语语料库中训练的,这导致了更强的英语指令遵循能力。在图 5(c)中,我们展示了所有被要求用中文回答的模型的结果。
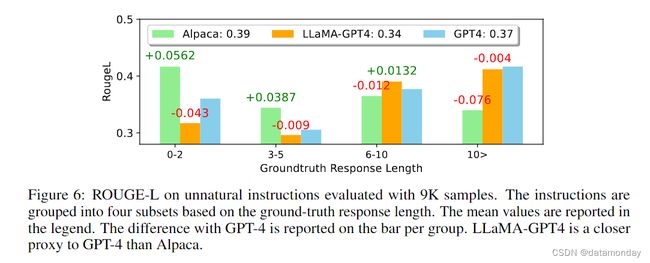
我们在图 6 中比较了 LLaMA-GPT4 与 GPT-4 和 Alpaca 非自然指令。从平均 ROUGE-L 分数来看,Alpaca 优于其他两个模型。我们注意到,LLaMA-GPT4 和 GPT4 的性能随着真实响应长度的增加而逐渐提高,最终在长度超过 4 时表现出更高的性能。在不同的子集中,LLaMA-GPT4 都能紧跟 GPT-4 的行为。当序列长度较短时,LLaMA-GPT4 和 GPT-4 都能生成包含简单基本答案的回复,但会添加额外的单词使回复更像聊天,这可能会导致 ROUGE-L 分数较低。
5 RELATED WORK
Instruction Tuning.
LLM 的指令调优是 NLP 领域越来越热门的研究方向(Zhong et al., 2021;Ouyang et al., 2022;Weiet al., 2021)。现有工作旨在提高开发流水线中三个因素的质量和规模,包括:
- 指令遵循数据
- 基础语言模型
- 评估基准
每个小组通常维护自己的流水线。例如,
- 扩展指令微调语言模型(Chung et al., 2022)就是建立在 FLAN(Wei et al., 2021)之上的。
- PromptSource 包含一个不断增长的提示集合(也称为 P3:Public Pool of Prompts)(Bach et al., 2022)。
- T0 是通过多任务提示训练在 P3 上训练的一系列模型(Sanh et al., 2021)。
- (Iyer et al., 2022)考虑了 OPT 模型的指令微调问题,采用了一个更大,更全面的基准 OPT-IML Bench,涵盖了 FLAN(Wei et al., 2021),Super-NaturalInstructions(Wang et al., 2022b)和 UnifiedSKG(Xie et al., 2022)。
Open-Source Efforts.
鉴于 ChatGPT 所展示的 LLMs 的广泛能力,开源模型引起了人们的极大兴趣,并推动了开发开放,通用,基于文本且符合人类价值观的助手的工作。早期的基础 LLMs 尝试包括:
- BLOOM(Scao et al., 2022)
- GPT-J(Wang 和 Komatsuzaki,2021)
- GPT-NEO(Black et al., 2021)
- OPT(Zhang et al., 2022)
- LLaMA(Zhang et al., 2023)
为了对齐 LLM 与聊天助手,Open-Assistant(LAION-AI,2023)建立在 GPT-J 的基础上,而 Alpaca/Vicuna 则建立在 LLaMA 的基础上。此外,OpenFlamingo(Awadalla et al., 2023)和LLaMA-Adapter(Zhang et al., 2023)将LLaMA与图像输入连接起来,为构建开源多模态LLM铺平了道路。
6 CONCLUSIONS
本文展示了使用 GPT-4 进行指令微调的有效性。我们发布了使用 GPT-4 生成的 52K 个中英文指令遵循实例,以及由 LLaMA 微调的模型检查点。我们希望我们的经验观察和资源将有利于开源和通用 LLM 的开发,从而更好地配合人类完成任务的价值观。
这是一项正在进行的工作,可以从以下几个方面进行探索:
- i)数据和模型规模。GPT-4 数据大小为 52K,基础 LLaMA 模型大小为 7B。Vicuna 收集了约 70 万个转换回合(根据多回合 ShareGPT 数据估算),并使用 13B 的 LLaMA 模型。因此,继续收集更多的 GPT-4 指令遵循数据,并与 ShareGPT 数据相结合,训练更大的 LLaMA 模型以获得更高的性能,将是大有可为的。
- ii)RLHF。奖励模型仅用于解码阶段,这表明对比数据有望为 LLM 训练提供有用的反馈。继续使用奖励模型训练 LLM 是很自然的,例如使用机器生成的反馈进行强化学习。
A IMPLEMENTATION DETAILS
A.1 HUMAN EVALUATION
我们实现了HHH对齐标准(Askell et al.,2021),并使用Amazon Mechanical Turk来评估模型生成的响应,界面截图如图7所示。
