pandas---groupby多条数据时的聚合函数min或max用法
问题描述
pandas使用groupby进行多条数据的min或max时,发现一个问题,先上代码:
import pandas as pd
df = pd.DataFrame({'Gender' : ['男', '女', '男', '男', '男', '男', '女', '女', '女'],
'name' : ['周杰伦', '蔡依林', '林俊杰', '周杰伦', '林俊杰', '周杰伦', '田馥甄', '蔡依林', '田馥甄'],
'income' : [4.5, 2.9, 3.8, 3.7, 4.0, 4.1, 1.9, 4.1, 3.2],
'expenditure' : [1.5, 1.9, 2.8, 1.7, 4.1, 2.5, 1.1, 3.4, 1.2]
})
print(df)
print(df.groupby(['name', 'Gender']).min('income'))
df的输出:
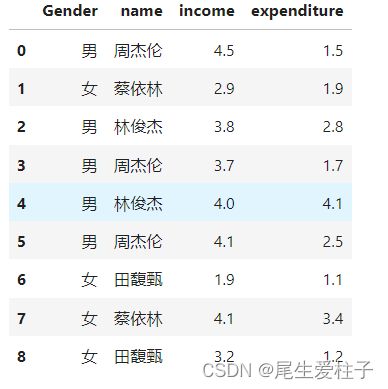
min之后输出:
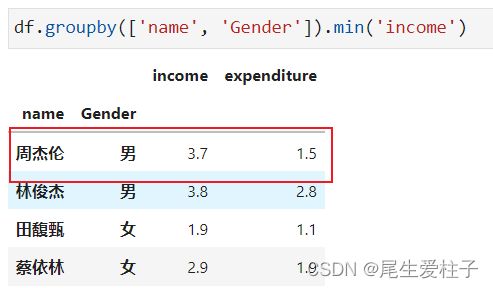
注意看“周杰伦”这条,‘income’和’expenditure’分别取的这一组的最小值,而不是’income’最小值对应的’expenditure’
原因分析:
首先查阅了groupby的参数含义,没有参数指向聚合函数的列选择
然后就是聚合函数min的问题了,按照df.min()函数的定义,返回数据表所有列的最小值
如下图
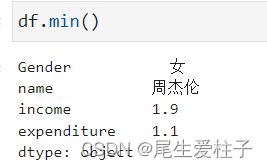
返回所有列的最小值,所以这里要取某一列的最小值需要修改df的值
解决方案:
在进行聚合时只对’income’列操作,完成后再merge

总结:
因为这个错浪费了我半下午时间,爆一句国粹不过分吧。
groupby以后可不能这么用了,害!