【自动化测试】转行人员在面试中被问及计算机基础知识该怎么办????(长文,预计三小时阅读)
看前提示,本文共4W字,76道题(附答案)
全部看完预计三个小时,如果觉得时间长,可以直接跳转到文末,有本文的word版提供下载
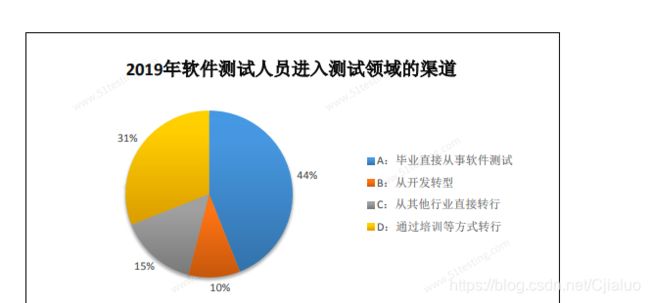
近些年软件测试岗位从转行的来人越来越多,占比高达44%
软件测试已经算半个IT行业,区别仅在于手工测试和自动化测试,要晋升自动化测试,计算机基础知识是必不可少的,下图有一份自动化测试的学习路线,需要的可以
点击并输入暗号:CSDN

最近就有不少面试官反映,有好多来面试自动化测试岗位的,对自动化技术有些了解,但提起一些计算机基础知识就支支吾吾,再追问一下就一问三不知了
为方便各行业转行至自动化测试的人员,这里整理了一些软件测试行业面试会问及的计算机基础问题和参考回答,觉得有用的记得点个收藏点个赞哦~~
计算机基础面试题
linux linux linux linux
1.请问linux两台机器之间传文件,用的什么端口
2.请你说一说关于linux查看进程
3.请你说几个基本Linux命令
4. 请你说一说Linux命令(查看进程、top命令、查看磁盘)
5. 请你说一下vector的特性
6.查看端口号、进程的指令是?动态查看日志的指令?怎么判断一个端口存不存在,磁盘满了怎么处理,删除一个目录下的txt文件,你还熟悉其他什么linux指令?
7. 请你说一下vi里面怎么替换字符串
8. 请问contrab,uptime,du,netstat这几个指令有什么作用,如何查看磁盘分区状态
9.请问如何将文本中的T全部替换成t,将其中的一行复制新的一行出来
网络协议 网络协议 网络协议 网络协议
1. 请你说一下HTTP的报文段是什么样的?
2. 请你回答一下HTTP用的什么连接?
3. 请你说一说TCP的三次握手?
4. 请你说一下在浏览器中输入一个网址它的运行过程是怎样的?
5. 请你说一说http rest
6. 请你说一说get和 post区别
7. 请你说一下tcp和udp的区别
8. 请你说一下为什么tcp可靠,哪些方法保证可靠
9. 请你说一说TCP的流量控制
10. 请你回答一下TCP三次握手,以及为什么不是两次
11. 请你回答一下ipv6的位数
12. 请你说一说osi七层模型
13. 请你说一说DNS解析过程
14. 请你说一说http和https区别
15. 请你说一下https中SSL层原理
16. 请你说一说TCP断连过程,以及单向连接关闭后还能否通信
17. 请你说说TCP和UDP用一个端口发送信息是否冲突
18.请你说说HTTP常见头
19. 请你说说HTTP状态码
20. 请你说说soket编程和http协议
21.请你说一说http缓存问题,缓存寿命,以及怎么判断文件在服务器是否更改的
22. 请你回答一下搜索敏感词汇时,页面被重置的原理
23.请你说一说两个机器之间的通讯过程?以及计算机网络为什么有七层?
24. 请你说一说什么是http协议,http的数据段包括什么?http 为什么是无状态的,http和https的区别?ip地址的abcd类是怎样分的,ABCD分层协议为什么如此分层,什么是长连接和短链接
25.请你说一说tcp数据段都包括什么?tcp三次握手四次挥手过程、为什么挥手是四次
26. 请你说一下tcp滑动窗口,同传,拆包组装包是如何实现的
27. 请你说一下tcp/ip四层网络协议
28. 手写代码:从网络日志中,提取出date 字段,并排序。
29. 从打开浏览器输入url到到达服务器上项目中某一个Controller上,请你来描述一下这一串过程
31. 请问你知道跨域吗,条件是什么,在header里需要加什么,有几种方案
32. 请你来回答一下,比如淘宝的搜索算法,输入关键词,会给出搜索出来的商品结果,对于这样的算法,如何评价它的好坏?
33. 商品的种类有几十万种,在这种大数据的情况下,如何评价搜索算法的好坏?
数据库 数据库 数据库 数据库
1. 请问什么是数据库事物,数据库事务的特性
2. 请你说一下数据库连接泄露的含义
3. 请你写一下mysql删除语句
4. 说下数据库mysql中CHAR和VCHAR的区别
5. 请你写两个sql语句,统计XX人数、选出课程编号不为XX的学生学号
6. 请你说一下SQL左连接以及使用场景
7.请你写一下SQL查询、更新的某一列语句
8.请你写一下SQL语句的多表查询
9.请你说说redis
10.请你写一些基本的SQL语句
11.某个表格中有10条一模一样的数据,现在要删掉其中的9条,请你写一下sql语句
12. 某个表格存着s_name subject score 三个字段,比如某一行是 张三 数学 76,现在要选取出所有科目成绩都大于80分的学生名字,请写出sql语句
13. 请你说一说数据库中的聚类查询
14. 请问如果mysql中用户密码丢了怎么办,建一个数据库表,授权命令是什么
15. 写出sql语句:数据库统计总成绩取前十名的学生
16. 请你说一下数据库事务、主键与外键的区别?
17. 请问对缓存技术了解吗
18. 请问count和sum的区别,以及count(*)和count(列名)的区别
19. 请问你数据库是用的MySQL吗?平常数据库的语句都是怎么写的? join作用,想删除一行怎么做
20. 请问如何对数据库作优化
21. 请问什么是幻读
22. 请你说一下MyBatis有什么优势,他如何做事务管理
23.请你说一下事务的隔离级别,以及你一般使用的事务是哪种
操作系统 操作系统 操作系统 操作系统
1.请你说一下多进程、多线程,操作系统层面的差别和联系
2. 请你说一下线程通信的方法、线程的五种状态
3. 请你说一下虚拟内存
4. 请你说一下线程的同步和互斥以及应用常见
5. 请你说一下线程的五种状态以及转换
6.请你说一说消息队列、信号量的实现方式
7. 请你说一下进程和线程的区别
8.请你说一下死锁的概念、原因、解决方法
9.请你说一下线程之间通信的手段
10.请你回答一下进程同步的方法
11. 请问进程线程的区别,进程间怎么相互通信,什么是多线程,什么是并发
后话
linux linux linux linux
1.请问linux两台机器之间传文件,用的什么端口
参考回答
Linux主机之间传输文件的几种方法:
- scp传输
scp传输速度较慢,但使用ssh通道保证了传输的安全性。
命令:
将本地文件拷贝到远程:scp 文件名 –用户名@计算机IP或者计算机名称:远程路径
从远程将文件拷回本地:scp –用户名@计算机IP或者计算机名称:文件名 本地路径
- rsync差异化传输(支持断点续传,数据同步)
rsync是Linux系统下的文件同步和数据传输工具,它采用“rsync”算法,可以将一个客户机和远程文件服务器之间的文件同步,也可以在本地系统中将数据从一个分区备份到另一个分区上。
如果rsync在备份过程中出现了数据传输中断,恢复后可以继续传输不一致的部分。rsync可以执行完整备份或增量备份。
- 管道传输(降低IO开销)
gzip -c sda.img | ssh [email protected] “gunzip -c - > /image/sda.img”
#对sda.img使用gzip压缩,-c参数表示输出到stdout,即通过管道传送
#gunzip -c - 中的"-"表示接收从管道传进的sdtin
- nc传输(一种网络的数据流重定向)
nc所做的就是在两台电脑之间建立tcp或udp链接,并在两个端口之间传输数据流,是一种网络的数据流重定向。
使用dd结合nc命令网络克隆磁盘分区:
主机:dd if=/dev/vda | gzip -c | nc -l 50522
待恢复机:nc 192.168.215.63 50522 | gzip -dc | dd of=/dev/sda
dd命令克隆/dev/vda磁盘,并使用gzip压缩,把数据流重定向到本机50522端口,待恢复机上使用nc连接主机50522端口,就能接收主机50522端口的比特数据流,然后使用gzip解压缩,并恢复到/dev/sda磁盘。
dd命令读取的是磁盘扇区,所以不论磁盘文件系统,或者分区表,磁盘MBR信息,dd都能够复制,可以使用bs,count参数控制要克隆的大小
- 建立文件服务器
通过建立文件服务器,然后通过网络挂载的方式传输,适用于经常性的拷贝。
2.请你说一说关于linux查看进程
参考回答:
ps命令:
ps命令查找与进程相关的PID号:
-
ps a 显示现行终端机下的所有程序,包括其他用户的程序。
-
ps -A 显示所有程序。
-
ps c 列出程序时,显示每个程序真正的指令名称,而不包含路径,参数或常驻服务的标示。
-
ps -e 此参数的效果和指定"A"参数相同。
-
ps e 列出程序时,显示每个程序所使用的环境变量。
-
ps f 用ASCII字符显示树状结构,表达程序间的相互关系。
-
ps -H 显示树状结构,表示程序间的相互关系。
-
ps -N 显示所有的程序,除了执行ps指令终端机下的程序之外。
-
ps s 采用程序信号的格式显示程序状况。
-
ps S 列出程序时,包括已中断的子程序资料。
-
ps -t<终端机编号> 指定终端机编号,并列出属于该终端机的程序的状况。
-
ps u 以用户为主的格式来显示程序状况。
-
ps x 显示所有程序,不以终端机来区分。
最常用的方法是ps aux
3.请你说几个基本Linux命令
参考回答:
-
file
作用:file通过探测文件内容判断文件类型,使用权限是所有用户。
格式:file [options] 文件名
==[options]==主要参数
-v:在标准输出后显示版本信息,并且退出。
-z:探测压缩过的文件类型。
-L:允许符合连接。 -
mkdir
作用:mkdir命令的作用是建立名称为dirname的子目录,与MS DOS下的md命令类似,它的使用权限是所有用户。
格式:mkdir [options] 目录名
[options]主要参数
-m, --mode=模式:设定权限<模式>;,与chmod类似。
-p, --parents:需要时创建上层目录;如果目录早已存在,则不当作错误。
-v, --verbose:每次创建新目录都显示信息。
--version:显示版本信息后离开。 -
grep
作用:grep命令可以指定文件中搜索特定的内容,并将含有这些内容的行标准输出。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
格式:grep [options]
[options]主要参数:
-c:只输出匹配行的计数。
-i:不区分大小写(只适用于单字符)。
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名
-n:显示匹配行及行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。 -
find
作用:find命令的作用是在目录中搜索文件,它的使用权限是所有用户。
格式:find [path][options][expression]path指定目录路径,系统从这里开始沿着目录树向下查找文件。它是一个路径列表,相互用空格分离,如果不写path,那么默认为当前目录。
主要参数:
[options]参数:
-depth:使用深度级别的查找过程方式,在某层指定目录中优先查找文件内容。
-maxdepth levels:表示至多查找到开始目录的第level层子目录。level是一个非负数,如果level是0的话表示仅在当前目录中查找。
-mindepth levels:表示至少查找到开始目录的第level层子目录。
-mount:不在其它文件系统(如Msdos、Vfat等)的目录和文件中查找。
-version:打印版本。
4. 请你说一说Linux命令(查看进程、top命令、查看磁盘)
参考回答:
查看进程:ps命令:
-
ps命令查找与进程相关的PID号:
-
ps a 显示现行终端机下的所有程序,包括其他用户的程序。
-
ps -A 显示所有程序。
-
ps c 列出程序时,显示每个程序真正的指令名称,而不包含路径,参数或常驻服务的标示。
-
ps -e 此参数的效果和指定"A"参数相同。
-
ps e 列出程序时,显示每个程序所使用的环境变量。
-
ps f 用ASCII字符显示树状结构,表达程序间的相互关系。
-
ps -H 显示树状结构,表示程序间的相互关系。
-
ps -N 显示所有的程序,除了执行ps指令终端机下的程序之外。
-
ps s 采用程序信号的格式显示程序状况。
-
ps S 列出程序时,包括已中断的子程序资料。
-
ps -t<终端机编号> 指定终端机编号,并列出属于该终端机的程序的状况。
-
ps u 以用户为主的格式来显示程序状况。
-
ps x 显示所有程序,不以终端机来区分。
-
最常用的方法是ps aux
top命令:Linux top命令用于实时显示 process 的动态。
语法:top [-] [d delay] [q] [c] [S] [s] [i] [n] [b]
参数说明:
-
d : 改变显示的更新速度,或是在交谈式指令列( interactive command)按 s
-
q : 没有任何延迟的显示速度,如果使用者是有 superuser 的权限,则 top 将会以最高的优先序执行
-
c : 切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称S : 累积模式,会将己完成或消失的子行程 ( dead child process ) 的 CPU time 累积起来
-
s : 安全模式,将交谈式指令取消, 避免潜在的危机
-
i : 不显示任何闲置 (idle) 或无用 (zombie) 的行程
-
n : 更新的次数,完成后将会退出 top
-
b : 批次档模式,搭配 “n” 参数一起使用,可以用来将 top 的结果输出到档案内
实例:
显示进程信息# top
显示完整命令# top -c
以批处理模式显示程序信息# top -b
以累积模式显示程序信息# top -S
查看磁盘:Linux磁盘管理常用三个命令为df、du和fdisk。
-
df:列出文件系统的整体磁盘使用量。df命令参数功能:检查文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。语法:
-
df [-ahikHTm] [目录或文件名]
-
du:检查磁盘空间使用量。语法:du [-ahskm] 文件或目录名称
-
fdisk:用于磁盘分区。语法:fdisk [-l] 装置名称
选项与参数:-l :输出后面接的装置所有的分区内容。若仅有 fdisk -l 时, 则系统将会把整个系统内能够搜寻到的装置的分区均列出来。
5. 请你说一下vector的特性
参考回答:
vector特点是: 其容量在需要时可以自动分配,可以在运行时高效地添加元素,本质上是数组形式的存储方式。即在索引可以在常数时间内完成。缺点是在插入或者删除一项时,需要线性时间。但是在尾部插入或者删除,是常数时间的。
6.查看端口号、进程的指令是?动态查看日志的指令?怎么判断一个端口存不存在,磁盘满了怎么处理,删除一个目录下的txt文件,你还熟悉其他什么linux指令?
参考回答:查看端口号的两种指令:netstat –tunlp|grep 端口号和lsof -i:端口号
查询进程的指令:
- ps -ef |grep 进程
- ps:将某个进程显示出来
- -A 显示所有程序。
- -e 此参数的效果和指定"A"参数相同。
- -f 显示UID,PPIP,C与STIME栏位。
动态查看日志:
- 先切换到:cd usr/local/tomcat5/logs
- tail -f catalina.out
- 这样运行时就可以实时查看运行日志了
怎么判断一个端口存不存在:
netstat -anp |grep 端口号,在输出结果中看监控状态为LISTEN表示已经被占用,最后一列显示被服务mysqld占用,查看具体端口号,只要有如图这一行就表示被占用了。
磁盘满了怎么处理
-
df -h 查看是哪个挂在目录满了,常常是根目录/占满
-
快速定位一下应用日志大小情况,比如tomcat日志,应用系统自己的日志等。
-
如果能直观地看到日志文件过大,则酌情进行删除。有时候删除日志文件之后再df -h查看空间依然被占满,继续排查。
lsof file_name 查看文件占用进程情况,如果删除的日志正在被某个进程占用,则必须重启或者kill掉进程。 -
如果不能直观地排除出是某个日志多大的原因,就需要看一下指定目录下的文件和子目录大小情况,使用du命令。
删除一个目录下的txt文件
find . -name “*.txt” | xargs rm -rf
我还熟悉文本编辑指令。
7. 请你说一下vi里面怎么替换字符串
参考回答:
vi/vim 中可以使用 :s 命令来替换字符串。该命令有很多种不同细节使用方法,可以实现复杂的功能,记录几种在此,方便以后查询。
- :s/vivian/sky/ 替换当前行第一个 vivian 为 sky
- :s/vivian/sky/g 替换当前行所有 vivian 为 sky
- :n,$s/vivian/sky/ 替换第 n 行开始到最后一行中每一行的第一个 vivian 为 sky
- :n,$s/vivian/sky/g 替换第 n 行开始到最后一行中每一行所有 vivian 为 sky
n 为数字,若 n 为 .,表示从当前行开始到最后一行 - :%s/vivian/sky/(等同于 :g/vivian/s//sky/) 替换每一行的第一个 vivian 为 sky
- :%s/vivian/sky/g(等同于 :g/vivian/s//sky/g) 替换每一行中所有 vivian 为 sky
8. 请问contrab,uptime,du,netstat这几个指令有什么作用,如何查看磁盘分区状态
参考回答:
Crontab:被用来提交和管理用户的需要周期性执行的任务,当安装完成操作系统后,默认会安装此服务工具,并且会自动启动crond进程,crond进程每分钟会定期检查是否有要执行的任务,如果有要执行的任务,则自动执行该任务。
Uptime:查询服务器已经运行多久
Du:查看文件和目录磁盘使用的空间情况
Netstat: 显示网络状态,利用netstat可以让你得知整个Linux系统的网络情况
使用df命令可以查看磁盘的适用情况以及文件系统被挂载的位置
9.请问如何将文本中的T全部替换成t,将其中的一行复制新的一行出来
参考回答:
:%s/T/t/g
网络协议 网络协议 网络协议 网络协议
1. 请你说一下HTTP的报文段是什么样的?
参考回答:
-
请求方法
GET:请求获取Request——URL所标识的资源
POST:在Request——URL所标识的资源后附加资源
HEAD:请求获取由Request——URL所标识的资源的响应消息报头
PUT:请求服务器存储一个资源,由Request——URL作为其标识
DELETE:请求服务器删除由Request——URL所标识的资源
TRACE:请求服务器回送收到的请求信息(用于测试和诊断)
CONNECT:保留
OPTIONS:请求查询服务器性能 -
URL
URI全名为Uniform Resource Indentifier(统一资源标识),用来唯一的标识一个资源,是一个通用的概念,URI由两个主要的子集URL和URN组成。URL全名为Uniform Resource Locator(统一资源定位),通过描述资源的位置来标识资源。URN全名为Uniform Resource Name(统一资源命名),通过资源的名字来标识资源,与其所处的位置无关,这样即使资源的位置发生变动,其URN也不会变化。 -
协议版本
格式为HTTP/主版本号.次版本号,常用为:HTTP/1.1 HTTP/1.0 -
请求头部
Host:接受请求的服务器地址,可以是IP或者是域名
User-Agent:发送请求的应用名称
Connection:指定与连接相关的属性,例如(Keep_Alive,长连接)
Accept-Charset:通知服务器端可以发送的编码格式
Accept-Encoding:通知服务器端可以发送的数据压缩格式
Accept-Language:通知服务器端可以发送的语言
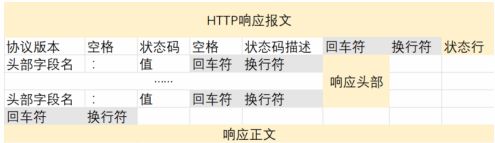
-
协议版本(请求报文)
-
状态码,100~ 199表示请求已收到继续处理,200~ 299表示成功,300~ 399表示资源重定向,400~ 499表示客户端请求出错,500~599表示服务器端出错
200:响应成功
302:跳转,重定向
400:客户端有语法错误
403:服务器拒绝提供服务
404:请求资源不存在
500:服务器内部错误 -
响应头部
Server:服务器应用软件的名称和版本
Content-Type:响应正文的类型
Content-Length:响应正文的长度
Content-Charset:响应正文所使用的编码
Content-Encoding:响应正文使用的数据压缩格式
Content-Language:响应正文使用的语言
2. 请你回答一下HTTP用的什么连接?
参考回答:
在HTTP/1.0中,默认使用的是短连接。也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。如果客户端浏览器访问的某个HTML或其他类型的 Web页中包含有其他的Web资源,如JavaScript文件、图像文件、CSS文件等;当浏览器每遇到这样一个Web资源,就会建立一个HTTP会话。
但从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头有加入这行代码:Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的 TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。
实现长连接要客户端和服务端都支持长连接。
3. 请你说一说TCP的三次握手?
参考回答: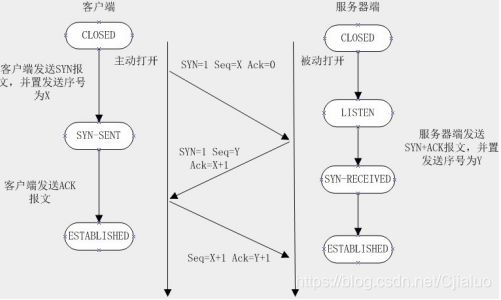
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
4. 请你说一下在浏览器中输入一个网址它的运行过程是怎样的?
参考回答:
- 查询DNS,获取域名对应的IP。
1)检查浏览器缓存、检查本地hosts文件是否有这个网址的映射,如果有,就调用这个IP地址映射,解析完成。
2)如果没有,则查找本地DNS解析器缓存是否有这个网址的映射,如果有,返回映射,解析完成。
3)如果没有,则查找填写或分配的首选DNS服务器,称为本地DNS服务器。
服务器接收到查询时:
如果要查询的域名包含在本地配置区域资源中,返回解析结果,查询结束,此解析具有权威性;
如果要查询的域名不由本地DNS服务器区域解析,但服务器缓存了此网址的映射关系,返回解析结果,查询结束,此解析不具有权威性。
4)如果本地DNS服务器也失效:
如果未采用转发模式(迭代),本地DNS就把请求发至13台根DNS,根DNS服务器收到请求后,会判断这个域名(如.com)是谁来授权管理,并返回一个负责该顶级域名服务器的IP,本地DNS服务器收到顶级域名服务器IP信息后,继续向该顶级域名服务器IP发送请求,该服务器如果无法解析,则会找到负责这个域名的下一级DNS服务器(如http://baidu.com)的IP给本地DNS服务器,循环往复直至查询到映射,将解析结果返回本地DNS服务器,再由本地DNS服务器返回解析结果,查询完成。
如果采用转发模式(递归),则此DNS服务器就会把请求转发至上一级DNS服务器,如果上一级DNS服务器不能解析,则继续向上请求。最终将解析结果依次返回本地DNS服务器,本地DNS服务器再返回给客户机,查询完成。
-
得到目标服务器的IP地址及端口号(http 80端口,https 443端口),会调用系统库函数socket,请求一个TCP流套接字。客户端向服务器发送HTTP请求报文:
1)应用层:客户端发送HTTP请求报文。
2)传输层:(加入源端口、目的端口)建立连接。实际发送数据之前,三次握手客户端和服务器建立起一个TCP连接。
3)网络层:(加入IP头)路由寻址。
4)数据链路层:(加入frame头)传输数据。
5)物理层:物理传输bit。 -
服务器端经过物理层→数据链路层→网络层→传输层→应用层,解析请求报文,发送HTTP响应报文。
-
关闭连接,TCP四次挥手。
-
客户端解析HTTP响应报文,浏览器开始显示HTML
5. 请你说一说http rest
参考回答:
REST(Representational State Transfer)一种轻量级的Web Service架构。
可以完全通过HTTP协议实现。其实现和操作比SOAP和XML-RPC更为简洁,还可以利用缓存Cache来提高响应速度,性能、效率和易用性上都优于SOAP协议。
REST架构对资源的操作包括获取、创建、修改和删除资源的操作对应HTTP协议提供的GET、POST、PUT和DELETE方法。
REST提供了一组架构约束,当作为一个整体来应用时,强调组件交互的可伸缩性、接口的通用性、组件的独立部署、以及用来减少交互延迟、增强安全性、封装遗留系统的中间组件。
REST架构约束:
-
客户-服务器(Client-Server),提供服务的服务器和使用服务的客户需要被隔离对待,客户和服务器之间通过一个统一的接口来互相通讯。
-
无状态(Stateless),服务端并不会保存有关客户的任何状态,客户端自身负责用户状态的维持,并在每次发送请求时都需要提供足够的信息。
-
可缓存(Cachable),REST系统需要能够恰当地缓存请求,以尽量减少服务端和客户端之间的信息传输,以提高性能。
-
分层系统(Layered System),服务器和客户之间的通信必须被这样标准化:允许服务器和客户之间的中间层(Ross:代理,网关等)可以代替服务器对客户的请求进行回应,而且这些对客户来说不需要特别支持。
-
统一接口(Uniform Interface),客户和服务器之间通信的方法必须是统一化的。
6. 请你说一说get和 post区别
参考回答:
GET:从指定的资源请求数据。
POST:向指定的资源提交要被处理的数据。
由于HTTP的规定和浏览器/服务器的限制,导致它们在应用过程中体现出一些不同。
| GET | POST | |
|---|---|---|
| 后退按钮/刷新 | 无害数据会被重新提交(浏览器应该告知用户数据会被重新提交)。 | |
| 缓存 | 能被缓存 | 不能缓存 |
| 编码方式 | 只能进行url编码 | 支持多种编码方式 |
| 是否保留在浏览历史 | 参数保留在浏览器历史中。 | 参数不会保存在浏览器历史中。 |
| 对数据长度的限制 | 发送数据,GET 方法向 URL 添加数据,但URL的长度是受限制的。 | 无限制。 |
| 对数据类型的限制 | 只允许 ASCII 字符。 | 没有限制。也允许二进制数据。 |
| 安全性 | 安全性较差,因为参数直接暴露在url中 | 因为参数不会被保存在浏览器历史或 web 服务器日志中。 |
| 可见性 | 数据在 URL 中对所有人都是可见的。 | 数据不会显示在 URL 中。 |
| 传参方式 | get参数通过url传递 | post放在request body中。 |
7. 请你说一下tcp和udp的区别
参考回答:
-
TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
-
TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付
-
TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的,应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
-
每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
-
TCP首部开销20字节;UDP的首部开销小,只有8个字节
-
TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道

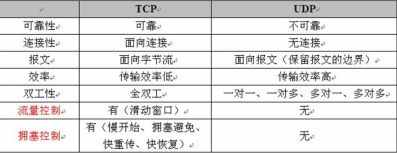
8. 请你说一下为什么tcp可靠,哪些方法保证可靠
参考回答:
-
确认和重传机制
建立连接时三次握手同步双方的“序列号 + 确认号 + 窗口大小信息”,是确认重传、流控的基础
传输过程中,如果Checksum校验失败、丢包或延时,发送端重传。 -
数据排序
TCP有专门的序列号SN字段,可提供数据re-order -
流量控制
滑动窗口和计时器的使用。TCP窗口中会指明双方能够发送接收的最大数据量,发送方通过维持一个发送滑动窗口来确保不会发生由于发送方报文发送太快接收方无法及时处理的问题。 -
拥塞控制
TCP的拥塞控制由4个核心算法组成:
“慢启动”(Slow Start)
“拥塞避免”(Congestion avoidance)
“快速重传 ”(Fast Retransmit)
“快速恢复”(Fast Recovery)
9. 请你说一说TCP的流量控制
参考回答:
滑动窗口机制:
滑动窗口协议的基本原理就是在任意时刻,发送方都维持了一个连续的允许发送的帧的序号,称为发送窗口;同时,接收方也维持了一个连续的允许接收的帧的序号,称为接收窗口。
发送窗口和接收窗口的序号的上下界不一定要一样,甚至大小也可以不同。不同的滑动窗口协议窗口大小一般不同。
发送方窗口内的序列号代表了那些已经被发送,但是还没有被确认的帧,或者是那些可以被发送的帧。
举例:

发送和接受方都会维护一个数据帧的序列,这个序列被称作窗口。
发送方的窗口大小由接受方确定,目的在于控制发送速度,以免接受方的缓存不够大,而导致溢出,同时控制流量也可以避免网络拥塞。
图中的4,5,6号数据帧已经被发送出去,但是未收到关联的ACK,7,8,9帧则是等待发送。可以看出发送端的窗口大小为6,这是由接受端告知的(事实上必须考虑拥塞窗口cwnd,这里暂且考虑cwnd>rwnd)。
此时如果发送端收到4号ACK,则窗口的左边缘向右收缩,窗口的右边缘则向右扩展,此时窗口就向前“滑动了”,即数据帧10也可以被发送。
10. 请你回答一下TCP三次握手,以及为什么不是两次
参考回答:结合上面的问题:TCP的三次握手
为什么不是两次:在服务端对客户端的请求进行回应(第二次握手)后,就会理所当然的认为连接已建立,而如果客户端并没有收到服务端的回应呢?
此时,客户端仍认为连接未建立,服务端会对已建立的连接保存必要的资源,如果大量的这种情况,服务端会崩溃。
11. 请你回答一下ipv6的位数
参考回答:
IPv6的128位地址通常写成8组,每组由四个十六进制数组成。
12. 请你说一说osi七层模型
参考回答:
- 物理层
在OSI参考模型中,物理层(Physical Layer)是参考模型的最低层,也是OSI模型的第一层。
物理层的主要功能是:利用传输介质为数据链路层提供物理连接,实现比特流的透明传输。
物理层的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么。
“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
- 数据链路层
数据链路层(Data Link Layer)是OSI模型的第二层,负责建立和管理节点间的链路。
该层的主要功能是:通过各种控制协议,将有差错的物理信道变为无差错的、能可靠传输数据帧的数据链路。
在计算机网络中由于各种干扰的存在,物理链路是不可靠的。
因此,这一层的主要功能是在物理层提供的比特流的基础上,通过差错控制、流量控制方法,使有差错的物理线路变为无差错的数据链路,即提供可靠的通过物理介质传输数据的方法。
该层通常又被分为介质访问控制(MAC)和逻辑链路控制(LLC)两个子层。
MAC子层的主要任务是解决共享型网络中多用户对信道竞争的问题,完成网络介质的访问控制;
LLC子层的主要任务是建立和维护网络连接,执行差错校验、流量控制和链路控制。
数据链路层的具体工作是接收来自物理层的位流形式的数据,并封装成帧,传送到上一层;同样,也将来自上层的数据帧,拆装为位流形式的数据转发到物理层;并且,还负责处理接收端发回的确认帧的信息,以便提供可靠的数据传输。
- 网络层
网络层(Network Layer)是OSI模型的第三层,它是OSI参考模型中最复杂的一层,也是通信子网的最高一层。它在下两层的基础上向资源子网提供服务。
其主要任务是:通过路由选择算法,为报文或分组通过通信子网选择最适当的路径。该层控制数据链路层与传输层之间的信息转发,建立、维持和终止网络的连接。
具体地说,数据链路层的数据在这一层被转换为数据包,然后通过路径选择、分段组合、顺序、进/出路由等控制,将信息从一个网络设备传送到另一个网络设备。
一般地,数据链路层是解决同一网络内节点之间的通信,而网络层主要解决不同子网间的通信。例如在广域网之间通信时,必然会遇到路由(即两节点间可能有多条路径)选择问题。
在实现网络层功能时,需要解决的主要问题如下:
寻址:数据链路层中使用的物理地址(如MAC地址)仅解决网络内部的寻址问题。在不同子网之间通信时,为了识别和找到网络中的设备,每一子网中的设备都会被分配一个唯一的地址。由于各子网使用的物理技术可能不同,因此这个地址应当是逻辑地址(如IP地址)。
交换:规定不同的信息交换方式。常见的交换技术有:线路交换技术和存储转发技术,后者又包括报文交换技术和分组交换技术。
路由算法:当源节点和目的节点之间存在多条路径时,本层可以根据路由算法,通过网络为数据分组选择最佳路径,并将信息从最合适的路径由发送端传送到接收端。
连接服务:与数据链路层流量控制不同的是,前者控制的是网络相邻节点间的流量,后者控制的是从源节点到目的节点间的流量。其目的在于防止阻塞,并进行差错检测。
- 传输层
OSI下3层的主要任务是数据通信,上3层的任务是数据处理。而传输层(Transport Layer)是OSI模型的第4层。因此该层是通信子网和资源子网的接口和桥梁,起到承上启下的作用。
该层的主要任务是:向用户提供可靠的端到端的差错和流量控制,保证报文的正确传输。传输层的作用是向高层屏蔽下层数据通信的细节,即向用户透明地传送报文。该层常见的协议:TCP/IP中的TCP协议、Novell网络中的SPX协议和微软的NetBIOS/NetBEUI协议。
传输层提供会话层和网络层之间的传输服务,这种服务从会话层获得数据,并在必要时,对数据进行分割。然后,传输层将数据传递到网络层,并确保数据能正确无误地传送到网络层。因此,传输层负责提供两节点之间数据的可靠传送,当两节点的联系确定之后,传输层则负责监督工作。综上,传输层的主要功能如下:
传输连接管理:提供建立、维护和拆除传输连接的功能。传输层在网络层的基础上为高层提供“面向连接”和“面向无接连”的两种服务。
处理传输差错:提供可靠的“面向连接”和不太可靠的“面向无连接”的数据传输服务、差错控制和流量控制。在提供“面向连接”服务时,通过这一层传输的数据将由目标设备确认,如果在指定的时间内未收到确认信息,数据将被重发。
监控服务质量。
- 会话层
会话层(Session Layer)是OSI模型的第5层,是用户应用程序和网络之间的接口,主要任务是:向两个实体的表示层提供建立和使用连接的方法。将不同实体之间的表示层的连接称为会话。因此会话层的任务就是组织和协调两个会话进程之间的通信,并对数据交换进行管理。
用户可以按照半双工、单工和全双工的方式建立会话。当建立会话时,用户必须提供他们想要连接的远程地址。而这些地址与MAC(介质访问控制子层)地址或网络层的逻辑地址不同,它们是为用户专门设计的,更便于用户记忆。域名(DN)就是一种网络上使用的远程地址例如:www.3721.com就是一个域名。会话层的具体功能如下:
会话管理:允许用户在两个实体设备之间建立、维持和终止会话,并支持它们之间的数据交换。例如提供单方向会话或双向同时会话,并管理会话中的发送顺序,以及会话所占用时间的长短。
会话流量控制:提供会话流量控制和交叉会话功能。
寻址:使用远程地址建立会话连接。l
出错控制:从逻辑上讲会话层主要负责数据交换的建立、保持和终止,但实际的工作却是接收来自传输层的数据,并负责纠正错误。会话控制和远程过程调用均属于这一层的功能。但应注意,此层检查的错误不是通信介质的错误,而是磁盘空间、打印机缺纸等类型的高级错误。
- 表示层
表示层(Presentation Layer)是OSI模型的第六层,它对来自应用层的命令和数据进行解释,对各种语法赋予相应的含义,并按照一定的格式传送给会话层。其主要功能是“处理用户信息的表示问题,如编码、数据格式转换和加密解密”等。表示层的具体功能如下:
数据格式处理:协商和建立数据交换的格式,解决各应用程序之间在数据格式表示上的差异。
数据的编码:处理字符集和数字的转换。例如由于用户程序中的数据类型(整型或实型、有符号或无符号等)、用户标识等都可以有不同的表示方式,因此,在设备之间需要具有在不同字符集或格式之间转换的功能。
压缩和解压缩:为了减少数据的传输量,这一层还负责数据的压缩与恢复。
数据的加密和解密:可以提高网络的安全性。
- 应用层
应用层(Application Layer)是OSI参考模型的最高层,它是计算机用户,以及各种应用程序和网络之间的接口,其功能是直接向用户提供服务,完成用户希望在网络上完成的各种工作。它在其他6层工作的基础上,负责完成网络中应用程序与网络操作系统之间的联系,建立与结束使用者之间的联系,并完成网络用户提出的各种网络服务及应用所需的监督、管理和服务等各种协议。此外,该层还负责协调各个应用程序间的工作。
应用层为用户提供的服务和协议有:文件服务、目录服务、文件传输服务(FTP)、远程登录服务(Telnet)、电子邮件服务(E-mail)、打印服务、安全服务、网络管理服务、数据库服务等。上述的各种网络服务由该层的不同应用协议和程序完成,不同的网络操作系统之间在功能、界面、实现技术、对硬件的支持、安全可靠性以及具有的各种应用程序接口等各个方面的差异是很大的。应用层的主要功能如下:
用户接口:应用层是用户与网络,以及应用程序与网络间的直接接口,使得用户能够与网络进行交互式联系。
实现各种服务:该层具有的各种应用程序可以完成和实现用户请求的各种服务。
13. 请你说一说DNS解析过程
参考回答:
- 浏览器先检查自身缓存中有没有被解析过的这个域名对应的ip地址,如果有,解析结束。同时域名被缓存的时间也可通过TTL属性来设置。
- 如果浏览器缓存中没有(专业点叫还没命中),浏览器会检查操作系统缓存中有没有对应的已解析过的结果。而操作系统也有一个域名解析的过程。在windows中可通过c盘里一个叫hosts的文件来设置,如果你在这里指定了一个域名对应的ip地址,那浏览器会首先使用这个ip地址。
但是这种操作系统级别的域名解析规程也被很多黑客利用,通过修改你的hosts文件里的内容把特定的域名解析到他指定的ip地址上,造成所谓的域名劫持。所以在windows7中将hosts文件设置成了readonly,防止被恶意篡改。
-
如果至此还没有命中域名,才会真正的请求本地域名服务器(LDNS)来解析这个域名,这台服务器一般在你的城市的某个角落,距离你不会很远,并且这台服务器的性能都很好,一般都会缓存域名解析结果,大约80%的域名解析到这里就完成了。
-
如果LDNS仍然没有命中,就直接跳到Root Server 域名服务器请求解析
-
根域名服务器返回给LDNS一个所查询域的主域名服务器(gTLD Server,国际顶尖域名服务器,如.com .cn .org等)地址
-
此时LDNS再发送请求给上一步返回的gTLD
-
接受请求的gTLD查找并返回这个域名对应的Name Server的地址,这个Name Server就是网站注册的域名服务器
-
Name Server根据映射关系表找到目标ip,返回给LDNS
-
LDNS缓存这个域名和对应的ip
-
LDNS把解析的结果返回给用户,用户根据TTL值缓存到本地系统缓存中,域名解析过程至此结束
14. 请你说一说http和https区别
参考回答:
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
-
https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
-
http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
-
http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
-
http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
15. 请你说一下https中SSL层原理
参考回答:
SSL利用数据加密、身份验证和消息完整性验证机制,为网络上数据的传输提供安全性保证。SSL支持各种应用层协议。由于SSL位于应用层和传输层之间,所以可以为任何基于TCP等可靠连接的应用层协议提供安全性保证。
- 身份验证机制
SSL利用数字签名来验证通信对端的身份。非对称密钥算法可以用来实现数字签名。由于通过私钥加密后的数据只能利用对应的公钥进行解密,因此根据解密是否成功,就可以判断发送者的身份,如同发送者对数据进行了“签名”。
例如,Alice使用自己的私钥对一段固定的信息加密后发给Bob,Bob利用Alice的公钥解密,如果解密结果与固定信息相同,那么就能够确认信息的发送者为Alice,这个过程就称为数字签名。使用数字签名验证身份时,需要确保被验证者的公钥是真实的,否则,非法用户可能会冒充被验证者与验证者通信。
如下图所示,Cindy冒充Bob,将自己的公钥发给Alice,并利用自己的私钥计算出签名发送给Alice,Alice利用“Bob”的公钥(实际上为Cindy的公钥)成功验证该签名,则Alice认为Bob的身份验证成功,而实际上与Alice通信的是冒充Bob的Cindy。SSL利用PKI提供的机制保证公钥的真实性。

- 数据传输的机密性
SSL加密通道上的数据加解密使用对称密钥算法,目前主要支持的算法有DES、3DES、AES等,这些算法都可以有效地防止交互数据被破解。对称密钥算法要求解密密钥和加密密钥完全一致。因此,利用对称密钥算法加密传输数据之前,需要在通信两端部署相同的密钥。
- 消息完整性验证
为了避免网络中传输的数据被非法篡改,SSL利用基于MD5或SHA的MAC算法来保证消息的完整性。MAC算法是在密钥参与下的数据摘要算法,能将密钥和任意长度的数据转换为固定长度的数据。利用MAC算法验证消息完整性的过程如下图所示。发送者在密钥的参与下,利用MAC算法计算出消息的MAC值,并将其加在消息之后发送给接收者。接收者利用同样的密钥和MAC算法计算出消息的MAC值,并与接收到的MAC值比较。如果二者相同,则报文没有改变;否则,报文在传输过程中被修改,接收者将丢弃该报文。

MAC算法要求通信双方具有相同的密钥,否则MAC值验证将会失败。因此,利用MAC算法验证消息完整性之前,需要在通信两端部署相同的密钥。
- 利用非对称密钥算法保证密钥本身的安全
对称密钥算法和MAC算法要求通信双方具有相同的密钥,否则解密或MAC值验证将失败。因此,要建立加密通道或验证消息完整性,必须先在通信双方部署一致的密钥。
SSL利用非对称密钥算法加密密钥的方法实现密钥交换,保证第三方无法获取该密钥。如下图所示,SSL客户端(如Web浏览器)利用SSL服务器(如Web服务器)的公钥加密密钥,将加密后的密钥发送给SSL服务器,只有拥有对应私钥的SSL服务器才能从密文中获取原始的密钥。SSL通常采用RSA算法加密传输密钥。(Server端公钥加密密钥,私钥解密密钥)
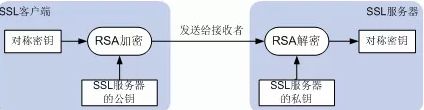
实际上,SSL客户端发送给SSL服务器的密钥不能直接用来加密数据或计算MAC值,该密钥是用来计算对称密钥和MAC密钥的信息,称为premaster secret。
SSL客户端和SSL服务器利用premaster secret计算出相同的主密钥(master secret),再利用master secret生成用于对称密钥算法、MAC算法等的密钥。premaster secret是计算对称密钥、MAC算法密钥的关键。
- 利用PKI保证公钥的真实性
PKI通过数字证书来发布用户的公钥,并提供了验证公钥真实性的机制。数字证书(简称证书)是一个包含用户的公钥及其身份信息的文件,证明了用户与公钥的关联。数字证书由权威机构——CA签发,并由CA保证数字证书的真实性。
SSL客户端把密钥加密传递给SSL服务器之前,SSL服务器需要将从CA获取的证书发送给SSL客户端,SSL客户端通过PKI判断该证书的真实性。如果该证书确实属于SSL服务器,则利用该证书中的公钥加密密钥,发送给SSL服务器。
验证SSL服务器/SSL客户端的身份之前,SSL服务器/SSL客户端需要将从CA获取的证书发送给对端,对端通过PKI判断该证书的真实性。如果该证书确实属于SSL服务器/SSL客户端,则对端利用该证书中的公钥验证SSL服务器/SSL客户端的身份。
16. 请你说一说TCP断连过程,以及单向连接关闭后还能否通信
参考回答:
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这个原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个 FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。四次挥手过程:
-
客户端A发送一个FIN,用来关闭客户A到服务器B的数据传送。
-
服务器B收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。
-
服务器B关闭与客户端A的连接,发送一个FIN给客户端A。
-
客户端A发回ACK报文确认,并将确认序号设置为收到序号加1。
四次挥手原因:这是因为服务端的LISTEN状态下的SOCKET当收到SYN报文的建连请求后,它可以把ACK和SYN(ACK起应答作用,而SYN起同步作用)放在一个报文里来发送。但关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可以未必会马上会关闭SOCKET,也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
17. 请你说说TCP和UDP用一个端口发送信息是否冲突
参考回答:
不冲突,TCP、UDP可以绑定同一端口来进行通信,许多协议已经这样做了,例如DNS适用于udp / 53和tcp / 53。
因为数据接收时时根据五元组{传输协议,源IP,目的IP,源端口,目的端口}判断接受者的。
18.请你说说HTTP常见头
参考回答:
- Accept:text/html, application/xhtml+xml, application/xml;q=0.9, image/webp, image/apng, /; q=0.8
作用:向服务器申明客户端(浏览器)可以接受的媒体类型(MIME)的资源
解释:浏览器可以接受text/html、application/xhtml+xml、application/xml类型,通配符*/* 表示任意类型的数据。并且浏览器按照该顺序进行接收。( text/html —> application/xhtml+xml —> application/xml)
- Accept-encoding: gzip, deflate, br
作用:向服务器申明客户端(浏览器)接收的编码方法,通常为压缩方法
解释:浏览器支持采用经过gzip,deflate 或 br 压缩过的资源
- Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7
作用:向服务器申明客户端(浏览器)接收的语言
解释:浏览器能够接受en-US, en 和 zh-CN 三种语言,其中 en-US 的权重最高 ( q 最高为1,最低为 0),服务器优先返回 en-US 语言
延伸:语言与字符集的区别:zh-CN 为汉语,汉语中有许多的编码:gbk2312 等
- Cache-control: max-age=0
作用:控制浏览器的缓存,常见值为private、no-cache、max-age、alidate,默认为 private,根据浏览器查看页面不同的方式来进行区别
解释:浏览器在访问了该页面后,不再会访问服务器
- Cookie:
作用:告诉服务器关于Session 的信息,存储让服务器辨识用户身份的信息。
- Refer:https://www.baidu.com/xxxxxxxxxx
作用:告诉服务器该页面从哪个页面链接的
解释:该页面从https://www.baidu.com 中的搜索结果中点击过来的
- Upgrade-insecure-requests:1
作用:申明浏览器支持从http 请求自动升级为 https 请求,并且在以后发送请求的时候都使用 https
解释:当页面中包含大量的http 资源的时候(图片、iframe),如果服务器发现一旦存在上述的响应头的时候,会在加载 http 资源的时候自动替换为 https 请求
- User-agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
作用:向服务器发送浏览器的版本、系统、应用程序的信息。
解释:Chrome 浏览器的版本信息为 63.0.3239.132,并将自己伪装成 Safari,使用的是 WebKit 引擎,WebKit伪装成 KHTML,KHTML伪装成Gecko(伪装是为了接收那些为Mozilla、safari、gecko编写的界面)
延伸:可以随便填(但不应该随便填)不过一般用于统计。
- X-Chrome-UMA-Enabled、X-Client-Data :与 Chrome 浏览器相关的数据
Response Headers
19. 请你说说HTTP状态码
参考回答:
状态码,100199表示请求已收到继续处理,200299表示成功,300399表示资源重定向,400499表示客户端请求出错,500~599表示服务器端出错
- 200:响应成功
- 302:跳转,重定向
- 400:客户端有语法错误
- 403:服务器拒绝提供服务
- 404:请求资源不存在
- 500:服务器内部错误
20. 请你说说soket编程和http协议
参考回答:
由于通常情况下Socket连接就是TCP连接,因此Socket连接一旦建立,通信双方即可开始相互发送数据内容,直到双方连接断开。但在实际网络应用中,客户端到服务器之间的通信往往需要穿越多个中间节点,例如路由器、网关、防火墙等,大部分防火墙默认会关闭长时间处于非活跃状态的连接而导致 Socket 连接断连,因此需要通过轮询告诉网络,该连接处于活跃状态。
而HTTP连接使用的是“请求—响应”的方式,不仅在请求时需要先建立连接,而且需要客户端向服务器发出请求后,服务器端才能回复数据。
很多情况下,需要服务器端主动向客户端推送数据,保持客户端与服务器数据的实时与同步。此时若双方建立的是Socket连接,服务器就可以直接将数据传送给客户端;若双方建立的是HTTP连接,则服务器需要等到客户端发送一次请求后才能将数据传回给客户端,因此,客户端定时向服务器端发送连接请求,不仅可以保持在线,同时也是在“询问”服务器是否有新的数据,如果有就将数据传给客户端。
21.请你说一说http缓存问题,缓存寿命,以及怎么判断文件在服务器是否更改的
参考回答:
- 缓存的类型:
缓存是一种保存资源副本并在下次请求中直接使用该副本的技术,缓存能够节约网络资源,提升页面响应速度。常见的缓存类型分为共享缓存和私有缓存
- 1.1 私有缓存
私有缓存只能用于单独用户,常见的浏览器缓存便是私有缓存。私有缓存能够存储用户通过http下载过的文档,从而在用户再次访问时直接提供给用户,而不用向服务器发送请求。
- 1.2 共享缓存
共享缓存能够被多个用户使用,常用的web代理中便使用的共享缓存
- 缓存寿命
缓存寿命的计算的依据依次是:
请求头中的Cache-Control: max-age=N。相应的缓存寿命即为 N,从设置开始,N秒之后过期。
Expires属性,Expires属性的值为过期的时间点,在这个时间点后,该缓存被认为过期
Last-Modified信息。缓存的寿命为头里面 Date表示的事件点减去 Last-Modified的时间点的结果乘以 10%
判断文件是否更改可以看文件时间戳
22. 请你回答一下搜索敏感词汇时,页面被重置的原理
参考回答:
根据TCP协议的规定,用户和服务器建立连接需要三次握手:第一次握手用户向服务器发送SYN数据包发出请求(SYN, x:0),第二次握手服务器向用户发送SYN/ACK数据包发出回应(SYN/ACK, y:x+1),第三次握手用户向服务器发送ACK数据包发出确认(ACK, x+1:y+1),至此一个TCP连接建立成功。
其中x为用户向服务器发送的序列号,y为服务器向用户发送的序列号。
关键字检测,针对明文或者base64等弱加密通讯内容,与准备好的敏感词库进行匹配,当发现敏感词时,将服务器发回的SYN/ACK包改成SYN/ACK, Y:0,这代表TCP连接被重置,用户便主动放弃了连接,提示连接失败。让用户误认为服务器拒绝连接,而主动放弃继续与服务器连接,自动阻断记录含有敏感词的网页
23.请你说一说两个机器之间的通讯过程?以及计算机网络为什么有七层?
参考回答:
PC1 首先判断目标ip是否和自己在同一网段,是就进行ARP广播,解析出MAC地址。不是,则将网关的MAC地址作为MAC地址。
PC1封装的数据包括目标、源的端口号、IP、MAC地址。
交换机收到数据后,对比MAC地址表,知道从哪个口发出数据。
路由收到数据后根据路由表将数据发往下一个目标地。
最后一个路由通过ARP解析出PC2的MAC地址。
路由封装的数据包括目标、源的端口号、IP、MAC地址。
建立七层模型的主要目的是为解决异种网络互连时所遇到的兼容性问题。它的最大优点是将服务、接口和协议这三个概念明确地区分开来:服务说明某一层为上一层提供一些什么功能,接口说明上一层如何使用下层的服务,而协议涉及如何实现本层的服务;这样各层之间具有很强的独立性,互连网络中各实体采用什么样的协议是没有限制的,只要向上提供相同的服务并且不改变相邻层的接口就可以了。网络七层的划分也是为了使网络的不同功能模块(不同层次)分担起不同的职责,从而带来如下好处:
- 减轻问题的复杂程度,一旦网络发生故障,可迅速定位故障所处层次,便于查找和纠错;
- 在各层分别定义标准接口,使具备相同对等层的不同网络设备能实现互操作,各层之间则相对独立,一种高层协议可放在多种低层协议上运行;
- 能有效刺激网络技术革新,因为每次更新都可以在小范围内进行,不需对整个网络动大手术;
24. 请你说一说什么是http协议,http的数据段包括什么?http 为什么是无状态的,http和https的区别?ip地址的abcd类是怎样分的,ABCD分层协议为什么如此分层,什么是长连接和短链接
参考回答:
- 什么是http协议?
http(hyperText transport Protocol)是超文本传输协议的缩写,它用于传送www方式的数据,关于http协议采用了请求/响应模型,客户端向服务器发送了一个请求,服务器以一个状态行作为响应
- http的数据段包括什么?
通常http消息包括客户机向服务器请求消息和服务器向客户机的响应消息,这两种类型的消息由一个起始行,一个或多个头域,一个指示头域结束的空行和可选的消息体组成,http的头域包括通用头,请求头,响应头,和实体头四个部分,每个头域由一个域名,冒号,和域值三部分组成,域名是大小写无关的,域值前可以添加任何数量的空格符,头域可以被扩张成多行,在每行开始处,使用至少一个空格或制表符。
- http为什么是无状态的?
无状态是指协议对于事务处理没有记忆能力,因为http协议目的在于支持超文本的传输,更加广义一点就是支持资源的传输,那么在客户端浏览器向服务器发送请求,继而服务器将相应的资源发回客户这样一个过程中,无论对于客户端还是服务器,都没有必要记录这个过程,因为每一次请求和响应都是相对独立的,一般而言,一个url对应唯一的超文本,正因为这样d唯一性,所以http协议被设计为无状态的链接协议符合他本身的需求。
- http和https的区别?
http和https的区别主要如下:
-
https需要到ca申请证书,因而需要一定费用
-
http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议
-
http的连接很简单,是无状态的,https协议是由ssl+http协议构建的可进行加密串苏,身份验证的网络协议
-
http用的端口是80,https用的端口是443
- ip地址的abcd类是怎样分的
-
A类地址的表示范围是:0.0.0.0-126.255.255.255,默认网络掩码为:255.0.0.0,A类地址分配给规模特别大的网络使用,
-
B类地址表示范围是:128.0.0.0-191.255.255.255,默认网络掩码为欸:255.255.0.0,B类地址分配给一般的中型网络
-
C类地址的表示范围是192.0.0.0-223.255.255.255,默认网络掩码是:255.255.255.0,C类地址分配给小型网络,如局域网
-
D类地址称为广播地址,共特殊协议向选定的节点发送信息使用。
这样便于寻址和层次化的构造网络。
- 什么是长连接和短连接?
http1.0中默认使用短连接,服务器和客户端没进行一次http操作,就建立一次连接,任务结束就终端连接,http1.1起。默认使用长连接,用以保持连接特性,当一个网页打开完成后,服务器和客户端之间用于传输http数据的tcp连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立好的连接。
25.请你说一说tcp数据段都包括什么?tcp三次握手四次挥手过程、为什么挥手是四次
参考回答:
-
TCP数据段:
源端口(Source port) 和 目的端口(Destination port):
字段标明了一个连接的两个端点用来跟踪同一时间内通过网络的不同会话。一般每个端口对应一个应用程序 -
序列号(Sequence number):字节号 (32 位),表示一个字节的编号
-
初始序列号ISNs(initial sequence numbers ):随机产生的
-
SYN:携带了ISNs 和SYN 控制位的数据段
-
确认号(Acknowledgement number):期望接收的字节号 (32位)
-
TCP段头长度(TCP header length): TCP段头长度, 单位32位(4字节)
-
保留域/字段:逐步启用,如做拥塞控制等
-
URG:当紧急指针使用的时候,URG 被置为1。紧急指针是一个对于当前序列号的字节偏移量,标明紧急数据从哪里开始
当URG=1时,表明有紧急数据,必须首先处理收方收到这样的数据后,马上处理,处理完后恢复正常操作即使win=0,也可以发送这样的数据 -
ACK:为1 表示确认号有效,为0 标明确认号无效
-
PSH:表示这是带有PUSH标志的数据,接收方收到这样的数据,应该立刻送到上层,而不需要缓存它
-
RST:被用来重置一个已经混乱的连接
-
SYN:用在连接建立过程中
SYN=1,ACK=0 连接请求,当SYN=1,ACK=1 连接接受 -
FIN: 被用来释放连接,它表示发送方已经没有数据要传输了,但是可以继续接收数据
-
Window size: 告诉对方可以发送的数据字节数,从确认字节号开始(决定于接收方)
-
Checksum:提供额外的可靠性,校验的范围包括头部、数据和概念性的伪头部
-
选项域:选项域提供了一种增加基本头没有包含内容的方法
Tcp三次握手:
-
第一次握手,客户端发送syn=j到服务器
-
服务器返回syn=k,ack=j+1,
-
客户端再向服务器发送ack=k+1;
三次握手结束,客户端和服务器建立连接
TCP四次挥手:
-
客户端发送fin=j包关闭连接
-
服务器返回ack=j+1
-
服务器发送fin=k包关闭连接
-
客户端返回ack=k+1
四次挥手结束,连接断开
为什么连接三次,断开连接四次?
在连接中,服务器的ack和syn包是同时发送的,而在断开连接的时候,服务器向客户端发送的ack和fin包是分两次发送的,因为服务器收到客户端发送的fin包时,可能还有数据要传送,所以先发送ack,等数据传输结束后再发送fin断开这边的连接。
26. 请你说一下tcp滑动窗口,同传,拆包组装包是如何实现的
- TCP滑动窗口
TCP建立连接时,各端分配一个缓冲区用来存储接受的数据,并将缓冲区的尺寸发送给另一端,接收方发送的确认消息中包含了自己剩余的缓冲区尺寸,剩余缓冲区空间的数量叫做窗口,所谓滑动窗口,就是接收端可以根据自己的状况通告窗口大小,从而控制发送端的接收,进行流量控制.
-
Tcp如何进行拆包、组装包?
-
拆包:
对于拆包目前常用的是以下两种方式:
- 动态缓冲区暂存方式。之所以说缓冲区是动态的是因为当需要缓冲的数据长度超出缓冲区的长度时会增大缓冲区长度。
大概过程描述如下:
- A 为每一个连接动态分配一个缓冲区,同时把此缓冲区和 SOCKET 关联,常用的是通过结构体关联。
- B 当接收到数据时首先把此段数据存放在缓冲区中。
- C 判断缓存区中的数据长度是否够一个包头的长度,如不够,则不进行拆包操作。
- D 根据包头数据解析出里面代表包体长度的变量。
- E 判断缓存区中除包头外的数据长度是否够一个包体的长度,如不够,则不进行拆包操作。
- F 取出整个数据包,这里的"取"的意思是不光从缓冲区中拷贝出数据包,而且要把此数据包从缓存区中删除掉。删除的办法就是把此包后面的数据移动到缓冲区的起始地址。
这种方法有两个缺点:
1)为每个连接动态分配一个缓冲区增大了内存的使用;
2)有三个地方需要拷贝数据,一个地方是把数据存放在缓冲区,一个地方是把完整的数据包从缓冲区取出来,一个地方是把数据包从缓冲区中删除。这种拆包的改进方法会解决和完善部分缺点。
- 利用底层的缓冲区来进行拆包
由于TCP也维护了一个缓冲区,所以我们完全可以利用TCP的缓冲区来缓存我们的数据,这样一来就不需要为每一个连接分配一个缓冲区了。另一方面我们知道 recv 或者 wsarecv 都有一个参数,用来表示我们要接收多长长度的数据。利用这两个条件我们就可以对第一种方法进行优化了。
对于阻塞 SOCKET 来说,我们可以利用一个循环来接收包头长度的数据,然后解析出代表包体长度的那个变量,再用一个循环来接收包体长度的数据。
27. 请你说一下tcp/ip四层网络协议
参考回答:
TCP/IP四层网络协议分别是应用层,网络层,传输层,数据链路层
28. 手写代码:从网络日志中,提取出date 字段,并排序。
参考回答:
首先在grok中要用%{DATESTAMP:date}或者自定义模式去匹配你的时间
然后在filter里
filter{
date{
match =>{"date","yyyy-MM-dd HH:mm:ss:SSS"}
}
}
29. 从打开浏览器输入url到到达服务器上项目中某一个Controller上,请你来描述一下这一串过程
参考回答:
这个过程中发生了网络通信,即利用tcp/ip协议簇进行网络通信,发送端由应用层往下走,接收端由数据链路层往上走,步骤如下:
-
浏览器输入url,其中http是协议
-
应用层DNS解析,返回对应的ip地址
-
应用层客户端发送http请求,
-
网络层ip查询mac地址,
-
传输层tcp传输报文
-
数据到达数据链路层,此时客户端发送请求结束
-
服务器在数据链路层收到数据包,再层层下上直到应用层,
-
服务器响应请求,查找客户端请求的资源并返回响应报文
30. 请你介绍下session,Session和cookie的区别是什么
参考回答:
Session:在web开发中,服务器可以为每个用户创建一个会话对象(session对象),默认情况下一个浏览器独占一个session对象,因此在需要保存用户数据时,服务器程序可以把用户数据写到用户浏览器独占的session中,当用户使用浏览器访问其他程序时,其他程序可以从用户的session中取出该用户的数据,为用户服务,其实现原理是服务器创建session出来后,会把session的id号,以cookie的形式回写给客户机,这样只要客户机的浏览器不关,再去访问服务器时,都会带着session的id号去,服务器发现客户机浏览器带session id过来了,就会使用内存中与之对应的session服务。
Session和cookie的区别:
-
cookie是把用户的数据写给用户浏览器
-
session是把用户的数据写到用户独占的session中
-
session对象由服务器创建,开发人员可以调用request对象的getsession方法得到session对象
31. 请问你知道跨域吗,条件是什么,在header里需要加什么,有几种方案
参考回答:
什么是跨域?
浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域
跨域的几种方案:
-
基于script标签实现跨域
-
基于jquery跨域
-
通过iframe来跨子域
32. 请你来回答一下,比如淘宝的搜索算法,输入关键词,会给出搜索出来的商品结果,对于这样的算法,如何评价它的好坏?
参考回答:
淘宝的搜索算法:
-
目标性比较强,当然,这个相对而言,从query来看,用户对目标商品的认知度相对较强
-
短query/符合query较多,传统搜索引擎里的xxx的商品这种query较少,当然,这与淘宝搜索的处理能力也有关系,用户对query进行分词的情况很常见
-
属性类query较为常见,如雪纺、鱼嘴等等表明用户特征的query较为常见
-
用户对结果的判断,基本上是价格敏感+信用敏感+销量敏感,其中销量敏感和信用敏感其实是一回事
对于这样的算法,我认为是很符合淘宝搜索要求的,能够更加精准
33. 商品的种类有几十万种,在这种大数据的情况下,如何评价搜索算法的好坏?
参考回答:
在大数据时代,搜索算法最重要有三点,足够快,能够将用户所潜在需要的商品全部搜索出来,性能稳定。
数据库 数据库 数据库 数据库
1. 请问什么是数据库事物,数据库事务的特性
参考回答:
数据库事务是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
一个数据库事务通常包含了一个序列的对数据库的读/写操作。它的存在包含有以下两个目的:
-
为数据库操作序列提供了一个从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持一致性的方法。
-
当多个应用程序在并发访问数据库时,可以在这些应用程序之间提供一个隔离方法,以防止彼此的操作互相干扰。
当事务被提交给了DBMS(数据库管理系统),则DBMS(数据库管理系统)需要确保该事务中的所有操作都成功完成且其结果被永久保存在数据库中,如果事务中有的操作没有成功完成,则事务中的所有操作都需要被回滚,回到事务执行前的状态;
同时,该事务对数据库或者其他事务的执行无影响,所有的事务都好像在独立的运行。
数据库事务拥有以下四个特性,被称之为ACID特性:
-
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
-
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
-
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
-
持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。
请你说一下数据库连接泄露的含义
参考回答:
数据库连接泄露指的是如果在某次使用或者某段程序中没有正确地关闭Connection、Statement和ResultSet资源,那么每次执行都会留下一些没有关闭的连接,这些连接失去了引用而不能得到重新使用,因此就造成了数据库连接的泄漏。
数据库连接的资源是宝贵而且是有限的,如果在某段使用频率很高的代码中出现这种泄漏,那么数据库连接资源将被耗尽,影响系统的正常运转。
2. 请你说一下数据库连接泄露的含义
参考回答:
数据库连接泄露指的是如果在某次使用或者某段程序中没有正确地关闭Connection、Statement和ResultSet资源,那么每次执行都会留下一些没有关闭的连接,这些连接失去了引用而不能得到重新使用,因此就造成了数据库连接的泄漏。
数据库连接的资源是宝贵而且是有限的,如果在某段使用频率很高的代码中出现这种泄漏,那么数据库连接资源将被耗尽,影响系统的正常运转。
3. 请你写一下mysql删除语句
参考回答:
-
drop语句。可以用来删除数据库和表。
用drop语句来删除数据库:drop database db;
用drop语句来删除表:drop table tb; -
delete语句。用来删除表中的字段。
delete from tb where id=1;
如果delete语句中没有加入where就会把表中的所有记录全部删除: -
用truncate来删除表中的所有字段:
truncate table tb;
4. 说下数据库mysql中CHAR和VCHAR的区别
参考回答:
- char(n)类型
char类型是定长的类型,即当定义的是char(10),输入的是"abc"这三个字符时,它们占的空间一样是10个字节,包括7个空字节。
当输入的字符长度超过指定的数时,char会截取超出的字符。
而且,当存储char值时,MySQL是自动删除输入字符串末尾的空格。
char是适合存储很短的、一般固定长度的字符串。例如,char非常适合存储密码的MD5值,因为这是一个定长的值。对于非常短的列,char比varchar在存储空间上也更有效率。
取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要。
- varchar(n)类型
varchar(n)类型用于存储可变长的,长度为n个字节的可变长度且非Unicode的字符数据。
n必须是介于1和8000之间的数值,存储大小为输入数据的字节的实际长度+1/2. 比如varchar(10), 然后输入abc三个字符,那么实际存储大小为3个字节。
除此之外,varchar还需要使用1或2个额外字节记录字符串的长度,如果列的最大长度小于等于255字节(是定义的最长长度,不是实际长度),则使用1个字节表示长度,否则使用2个字节来表示。取数据的时候,不需要去掉多余的空格。
5. 请你写两个sql语句,统计XX人数、选出课程编号不为XX的学生学号
参考回答:
select sClass 班级,count(*) 班级学生总人数,
SELECT 学号,
FROM S
WHERE NOT EXISTS (SELECT *
FROM SC
WHERE SC.课程号 = 'XX'
AND S.学号 = SC.学号);
6. 请你说一下SQL左连接以及使用场景
参考回答:
left join(左连接) 返回包括 LEFT OUTER子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。
使用场景:可以保持左表完整加入另一表中的数据。
7.请你写一下SQL查询、更新的某一列语句
参考回答:
SELECT 要查询的数据类型 FROM 表名 WHERE 条件
UPDATE 表名 SET 列名=更新的值 WHERE 条件
8.请你写一下SQL语句的多表查询
参考回答:
例如:按照department_id 查询 employees(员工表)和 departments(部门表) 的信息。
SELECT ... FROM ... WHERE SELECT e.last_name,e.department_id,d.department_name FROM employees e,departments d where e.department_id = d.department_id
9.请你说说redis
参考回答:
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。
与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
10.请你写一些基本的SQL语句
参考回答:
选择:select * from table1 where 范围
插入:insert into table1(field1,field2) values(value1,value2)
删除:delete from table1 where 范围
更新:update table1 set field1=value1 where 范围
查找:select * from table1 where field1 like ‘%value1%’ —like的语法很精妙,查资料!
排序:select * from table1 order by field1,field2 [desc]
总数:select count as totalcount from table1
求和:select sum(field1) as sumvalue from table1
平均:select avg(field1) as avgvalue from table1
最大:select max(field1) as maxvalue from table1
最小:select min(field1) as minvalue from table1
11.某个表格中有10条一模一样的数据,现在要删掉其中的9条,请你写一下sql语句
参考回答:
delete * from table_name limit 9
- 1
12. 某个表格存着s_name subject score 三个字段,比如某一行是 张三 数学 76,现在要选取出所有科目成绩都大于80分的学生名字,请写出sql语句
参考回答:
select s_name from table_name where s_name not in (select s_name from table_name where score <80)
13. 请你说一说数据库中的聚类查询
参考回答:
聚集索引中键值的逻辑顺序决定了表中相应行的物理顺序。聚集索引确定表中数据的物理顺序。聚集索引类似于电话簿,后者按姓氏排列数据。
由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。
但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样。聚集索引对于那些经常要搜索范围值的列特别有效。
使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。
例如,如果应用程序执行的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此类查询的性能。
同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节省成本。
当索引值唯一时,使用聚集索引查找特定的行也很有效率。例如,使用唯一雇员ID 列 emp_id 查找特定雇员的最快速的方法,是在 emp_id 列上创建聚集索引或 PRIMARY KEY 约束。
如果不创建索引,系统会自动创建一个隐含列作为表的聚集索引。
#1.创建表的时候指定主键(注意:SQL Sever默认主键为聚集索引,也可以指定为非聚集索引,而MySQL里主键就是聚集索引)
create table t1(
id int primary key,
name nvarchar(255)
)
#2.创建表后添加聚集索引
1 SQL Server:
2 create clustered index clustered_index on table_name(colum_name)
3 MySQL:
4 alter table table_name add primary key(colum_name)
14. 请问如果mysql中用户密码丢了怎么办,建一个数据库表,授权命令是什么
参考回答:
对于普通用户的密码丢失,直接用root超级管理员登录修改密码即可
若是root密码丢失,可通过mysqlld_saft方式找回
-
停止mysql:service mysqld stop
-
安全模式启动:mysql_safe-skip-grant-tables&
-
无密码回车键登录:mysql –uroot –p;
-
重置密码:use mysql update user set password=password(“)where user=’root’ and host=’localhost’;flush privileges
-
正常启动:service mysql restart
-
再使用mysqladmin:mysqladmin password ‘123456’
#Mysql创建数据库
Create database demodb default character set utf8 collate utf8_general_ci;
#授权
Grant all privileges on demodb. * [用户名称]@’%’
#立即启动修改
Flush privileges
15. 写出sql语句:数据库统计总成绩取前十名的学生
参考回答:
SELECT * FROM (
select T.*,ROW_NUMBER()OVER(PARTITION BY 班级 order by 成绩 desc) RN
FROM T
)WHERE RN<=10
16. 请你说一下数据库事务、主键与外键的区别?
参考回答:
数据库的事务:事务即用户定义的一个数据库操作序列,这些操作要么全做要全不做,是一个不可分割的工作单位,它具有四个特性,ACID,原子性,一致性,隔离性,持续性
主键和外键的区别:
- 主键是能确定一条记录的唯一标识,比如,一条记录包括身份正号,姓名,年龄。
身份证号是唯一能确定你这个人的,其他都可能有重复,所以,身份证号是主键。
- 外键用于与另一张表的关联。是能确定另一张表记录的字段,用于保持数据的一致性。
17. 请问对缓存技术了解吗
参考回答:
Redis可以实现缓存机制, Redis是一个key-value存储系统。
和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、 list(链表)、set(集合)和zset(有序集合)。
这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。
区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步,当前 Redis的应用已经非常广泛,国内像新浪、淘宝,国外像 Flickr、Github等均在使用Redis的缓存服务。
Redis 工作方式分析:Redis作为一个高性能的key-value数据库具有以下特征:
-
多样的数据模型
-
持久化
-
主从同步
Redis支持丰富的数据类型,最为常用的数据类型主要由五种:String、Hash、List、Set和Sorted Set。
Redis通常将数据存储于内存中,或被配置为使用虚拟内存。
Redis有一个很重要的特点就是它可以实现持久化数据,通过两种方式可以实现数据持久化:使用RDB快照的方式,将内存中的数据不断写入磁盘;或使用类似MySQL的AOF日志方式,记录每次更新的日志。前者性能较高,但是可能会引起一定程度的数据丢失;后者相反。
Redis支持将数据同步到多台从数据库上,这种特性对提高读取性能非常有益。
18. 请问count和sum的区别,以及count(*)和count(列名)的区别
参考回答:
Count和sum区别:求和用累加sum(),求行的个数用累计count
Count(*)包括了所有的列,在统计结果的时候不会忽略列值为null
Count(列名)只包括列名那一项,会忽略列值为空的计数
19. 请问你数据库是用的MySQL吗?平常数据库的语句都是怎么写的? join作用,想删除一行怎么做
参考回答:
Mysql和oracle都用过,mysql为主,join作用是连接两个表,假设有2个表——Student表和SC表(选课表)
-
内连接(自然连接):当使用内连接时,如果Student中某些学生没有选课,则在SC中没有相应元组。最终查询结果舍弃了这些学生的信息
-
外连接:如果想以Student表为主体列出每个学生的基本情况及其选课情况。即使某个学生没有选课,依然在查询结果中显示(SC表的属性上填空值)。就需要使用外连接
例子:
//内连接:查询每个学生及其选修课程的情况(没选课的学生不会列出)
SELECT Student.*, SC.*
FROM Student , SC
WHERE Student.Sno=SC.Sno;
//外连接:查询每个学生及其选修课程的情况(没选课的学生也会列出)
SELECT Student.*, SC.*
FROM Student LEFT JOIN SC ON(Student.Sno=SC.Sno);
20. 请问如何对数据库作优化
参考回答:
-
调整数据结构的设计,对于经常访问的数据库表建立索引
-
调整SQL语句, ORACLE公司推荐使用ORACLE语句优化器(Oracle Optimizer)和行锁管理器(row-level manager)来调整优化SQL语句。
-
调整服务器内存分配。内存分配是在信息系统运行过程中优化配置的,数据库管理员可以根据数据库运行状况调整数据库系统全局区(SGA区)的数据缓冲区、日志缓冲区和共享池的大小;还可以调整程序全局区(PGA区)的大小。
-
调整硬盘I/O,DBA可以将组成同一个表空间的数据文件放在不同的硬盘上,做到硬盘之间I/O负载均衡。
21. 请问什么是幻读
参考回答:
脏读就是指当一个事务正在访问数据,并且对数据进行了修改,但是还没有来得及提交到数据库中,这时,另一个事务也访问这个数据,然后使用了这个数据
22. 请你说一下MyBatis有什么优势,他如何做事务管理
参考回答:
MyBatis优点:
-
易于上手和掌握
-
sql写在xml里,便于统一管理和优化。
-
解除sql与程序代码的耦合。
-
提供映射标签,支持对象与数据库的orm字段关系映射
-
提供对象关系映射标签,支持对象关系组建维护
-
提供xml标签,支持编写动态sql。
Mybatis管理事务是分为两种方式:
1)使用JDBC的事务管理机制,就是利用java.sql.Connection对象完成对事务的提交
2)使用MANAGED的事务管理机制,这种机制mybatis自身不会去实现事务管理,而是让程序的容器(JBOSS,WebLogic)来实现对事务的管理
23.请你说一下事务的隔离级别,以及你一般使用的事务是哪种
参考回答:
事务的隔离性及时同一时间只允许一个事务请求同一数据,不同事物之间彼此没有任何干扰,
事务隔离级别如下:
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
操作系统 操作系统 操作系统 操作系统
1.请你说一下多进程、多线程,操作系统层面的差别和联系
参考回答:
进程:进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。
进程是一种抽象的概念,从来没有统一的标准定义。一般由程序、数据集合和进程控制块三部分组成。
程序用于描述进程要完成的功能,是控制进程执行的指令集;数据集合是程序在执行时所需要的数据和工作区;程序控制块(Program Control Block,简称PCB),包含进程的描述信息和控制信息,是进程存在的唯一标志。
线程:在早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。
任务调度采用的是时间片轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的一块内存,使得各个进程之间内存地址相互隔离。
后来,随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了。于是就发明了线程,线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。
一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。而进程由内存空间(代码、数据、进程空间、打开的文件)和一个或多个线程组成。
差别:
- 线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
- 一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线;
- 进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;
- 调度和切换:线程上下文切换比进程上下文切换要快得多。
联系:
原则上一个CPU只能分配给一个进程,以便运行这个进程。通常使用的计算机中只有一个CPU,同时运行多个进程,就必须使用并发技术。
通常采用时间片轮转进程调度算法,在操作系统的管理下,所有正在运行的进程轮流使用CPU,每个进程允许占用CPU的时间非常短(比如10毫秒),这样用户根本感觉不出来CPU是在轮流为多个进程服务,就好象所有的进程都在不间断地运行一样。
但实际上在任何一个时间内有且仅有一个进程占有CPU。如果一台计算机有多个CPU,情况就不同了,如果进程数小于CPU数,则不同的进程可以分配给不同的CPU来运行,这样,多个进程就是真正同时运行的,这便是并行。
但如果进程数大于CPU数,则仍然需要使用并发技术。在Windows中,进行CPU分配是以线程为单位的,一个进程可能由多个线程组成。
操作系统将CPU的时间片分配给多个线程,每个线程在操作系统指定的时间片内完成(注意,这里的多个线程是分属于不同进程的).操作系统不断的从一个线程的执行切换到另一个线程的执行,如此往复,宏观上看来,就好像是多个线程在一起执行.由于这多个线程分属于不同的进程,就好像是多个进程在同时执行,这样就实现了多任务。
总线程数<=CPU数量时并行运行,总线程数>CPU数量时并发运行。并行运行的效率显然高于并发运行,所以在多CPU的计算机中,多任务的效率比较高。但是,如果在多CPU计算机中只运行一个进程(线程),就不能发挥多CPU的优势。
2. 请你说一下线程通信的方法、线程的五种状态
参考回答:
线程通信的方法:
-
同步:多个线程通过synchronized关键字这种方式来实现线程间的通信。
-
while轮询的方式
-
wait/notify机制
-
管道通信就是使用java.io.PipedInputStream 和 java.io.PipedOutputStream进行通信
线程的五种状态:
-
新建(NEW):新创建了一个线程对象。
-
可运行(RUNNABLE):线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取cpu 的使用权 。
-
运行(RUNNING):可运行状态(runnable)的线程获得了cpu 时间片(timeslice) ,执行程序代码。
-
阻塞(BLOCKED):阻塞状态是指线程因为某种原因放弃了cpu 使用权,也即让出了cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有机会再次获得cpu timeslice 转到运行(running)状态。
阻塞的情况分三种:
-
等待阻塞:运行(running)的线程执行o.wait()方法,JVM会把该线程放入等待队列(waitting queue)中。
-
同步阻塞:运行(running)的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
-
其他阻塞:运行(running)的线程执行Thread.sleep(long ms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
- 死亡(DEAD):线程run()、main() 方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
3. 请你说一下虚拟内存
参考回答:
虚拟内存是计算机系统内存管理的一种技术。
它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换
4. 请你说一下线程的同步和互斥以及应用常见
参考回答:
-
互斥:指在某一时刻指允许一个进程运行其中的程序片,具有排他性和唯一性。
对于线程A和线程B来讲,在同一时刻,只允许一个线程对临界资源进行操作,即当A进入临界区对资源操作时,B就必须等待;当A执行完,退出临界区后,B才能对临界资源进行操作。 -
同步:指的是在互斥的基础上,实现进程之间的有序访问。假设现有线程A和线程B,线程A需要往缓冲区写数据,线程B需要从缓冲区读数据,但他们之间存在一种制约关系,即当线程A写的时候,B不能来拿数据;B在拿数据的时候A不能往缓冲区写,也就是说,只有当A写完数据(或B取走数据),B才能来读数据(或A才能往里写数据)。这种关系就是一种线程的同步关系。
-
应用常见:多线程编程中,难免会遇到多个线程同时访问临界资源的问题,如果不对其加以保护,那么结果肯定是不如预期的,因此需要线程同步与互斥。
5. 请你说一下线程的五种状态以及转换
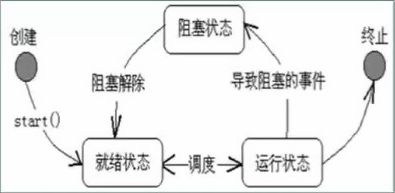
1. 新生状态
在程序中用构造方法(new操作符)创建一个新线程时,如new Thread®,该线程就是创建状态,此时它已经有了相应的内存空间和其它资源,但是还没有开始执行。
2. 就绪状态
新建线程对象后,调用该线程的start()方法就可以启动线程。当线程启动时,线程进入就绪状态(runnable)。由于还没有分配CPU,线程将进入线程队列排队,等待 CPU 服务,这表明它已经具备了运行条件。当系统挑选一个等待执行的Thread对象后,它就会从等待执行状态进入执行状态。系统挑选的动作称之为“CPU调度"。一旦获得CPU线程就进入运行状态并自动调用自己的run方法。
3. 运行状态
当就绪状态的线程被调用并获得处理器资源时,线程就进入了运行状态。此时,自动调用该线程对象的run()方法。run()方法定义了该线程的操作和功能。运行状态中的线程执行自己的run方法中代码。直到调用其他方法或者发生阻塞而终止。
4. 阻塞状态
一个正在执行的线程在某些特殊情况下,如被人为挂起或需要执行耗时的输入输出操作时,suspend()、 wait()等方法,线程都将进入堵塞状态。堵塞时,线程不能进入排队队列,只有当引起堵塞的原因被消除后,线程转入就绪状态。重将让出 CPU 并暂时中止自己的执行,进入堵塞状态。在可执行状态下,如果调用 sleep()、 新到就绪队列中排队等待,这时被CPU调度选中后会从原来停止的位置开始继续执行。
5. 死亡状态
线程调用stop()方法、destory()方法或 run()方法执行结束后,线程即处于死亡状态。处于死亡状态的线程不具有继续运行的能力
6.请你说一说消息队列、信号量的实现方式
参考回答:
消息队列是消息的链接表,存储在内核中,由消息队列ID来标识。每个队列都有一个msgid_ds结构与其相关联:
struct msgid_ds
{
struct ipc_perm msg_perm;
msgqnum_t msg_qnum; /* # of messages on queue */
msglen_t msg_qbytes; /* max # of bytes on queue */
pid_t msg_lspid; /* pid of last msgsnd() */
pid_t msg_lrpid; /* pid of last msgrcv() */
time_t msg_stime; /* last-msgsnd() time */
time_t msg_rtime; /* last-msgrcv() time */
time_t msg_ctime; /* last-change time */
...
};
每个信号量由一个无名结构体表示,至少包含下列成员:
struct
{
unsigned short semval; /* semaphore value, always >= 0 */
pid_t sempid; /* pid for last operation */
unsigned short semncnt; /* # processes awaiting semval > curval */
unsigned short semzcnt; /* # processes awaiting semval == 0 */
...
};
7. 请你说一下进程和线程的区别
参考回答:
进程:是具有一定独立功能的程序、它是系统进行资源分配和调度的一个独立单位,重点在系统调度和单独的单位,也就是说进程是可以独立运行的一段程序。
线程:是进程的一个实体,是CPU调度和分派的基本单位,比进程更小的能独立运行的基本单位,线程自己基本上不拥有系统资源,在运行时,只是暂用一些计数器、寄存器和栈 。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间。
一个程序至少有一个进程,一个进程至少有一个线程。
8.请你说一下死锁的概念、原因、解决方法
参考回答:
- 死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资源而处于的一种永久等待状态。死锁的四个必要条件:
-
互斥条件(Mutual exclusion):资源不能被共享,只能由一个进程使用。
-
请求与保持条件(Hold and wait):已经得到资源的进程可以再次申请新的资源。
-
非剥夺条件(No pre-emption):已经分配的资源不能从相应的进程中被强制地剥夺。
-
循环等待条件(Circular wait):系统中若干进程组成环路,该环路中每个进程都在等待相邻进程正占用的资源。
java中产生死锁可能性的最根本原因是:
1)是多个线程涉及到多个锁,这些锁存在着交叉,所以可能会导致了一个锁依赖的闭环;
2)默认的锁申请操作是阻塞的。
线程在获得一个锁L1的情况下再去申请另外一个锁L2,也就是锁L1想要包含了锁L2,在获得了锁L1,并且没有释放锁L1的情况下,又去申请获得锁L2,这个是产生死锁的最根本原因。
- 避免死锁:
-
方案一:破坏死锁的循环等待条件。
-
方法二:破坏死锁的请求与保持条件,使用lock的特性,为获取锁操作设置超时时间。这样不会死锁(至少不会无尽的死锁)
-
方法三:设置一个条件遍历与一个锁关联。该方法只用一把锁,没有chopstick类,将竞争从对筷子的争夺转换成了对状态的判断。仅当左右邻座都没有进餐时才可以进餐。提升了并发度。
9.请你说一下线程之间通信的手段
参考回答:
使用全局变量
主要由于多个线程可能更改全局变量,因此全局变量最好声明为volatile
使用消息实现通信
在Windows程序设计中,每一个线程都可以拥有自己的消息队列(UI线程默认自带消息队列和消息循环,工作线程需要手动实现消息循环),因此可以采用消息进行线程间通信sendMessage,postMessage。
使用事件CEvent类实现线程间通信
Event对象有两种状态:有信号和无信号,线程可以监视处于有信号状态的事件,以便在适当的时候执行对事件的操作。
10.请你回答一下进程同步的方法
参考回答:
- 临界区(Critical Section):通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。
优点:保证在某一时刻只有一个线程能访问数据的简便办法
缺点:虽然临界区同步速度很快,但却只能用来同步本进程内的线程,而不可用来同步多个进程中的线程。
- 互斥量(Mutex):为协调共同对一个共享资源的单独访问而设计的。
互斥量跟临界区很相似,比临界区复杂,互斥对象只有一个,只有拥有互斥对象的线程才具有访问资源的权限。
优点:使用互斥不仅仅能够在同一应用程序不同线程中实现资源的安全共享,而且可以在不同应用程序的线程之间实现对资源的安全共享。
缺点:①互斥量是可以命名的,也就是说它可以跨越进程使用,所以创建互斥量需要的资源更多,所以如果只为了在进程内部是用的话使用临界区会带来速度上的优势并能够减少资源占用量。因为互斥量是跨进程的互斥量一旦被创建,就可以通过名字打开它。
②通过互斥量可以指定资源被独占的方式使用,但如果有下面一种情况通过互斥量就无法处理,比如现在一位用户购买了一份三个并发访问许可的数据库系统,可以根据用户购买的访问许可数量来决定有多少个线程/进程能同时进行数据库操作,这时候如果利用互斥量就没有办法完成这个要求,信号量对象可以说是一种资源计数器。
- 信号量(Semaphore):为控制一个具有有限数量用户资源而设计。它允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问此资源的最大线程数目。互斥量是信号量的一种特殊情况,当信号量的最大资源数=1就是互斥量了。
优点:适用于对Socket(套接字)程序中线程的同步。(例如,网络上的HTTP服务器要对同一时间内访问同一页面的用户数加以限制,只有不大于设定的最大用户数目的线程能够进行访问,而其他的访问企图则被挂起,只有在有用户退出对此页面的访问后才有可能进入。)
缺点:①信号量机制必须有公共内存,不能用于分布式操作系统,这是它最大的弱点;
②信号量机制功能强大,但使用时对信号量的操作分散, 而且难以控制,读写和维护都很困难,加重了程序员的编码负担;
③核心操作P-V分散在各用户程序的代码中,不易控制和管理,一旦错误,后果严重,且不易发现和纠正。
- 事件(Event): 用来通知线程有一些事件已发生,从而启动后继任务的开始。
优点:事件对象通过通知操作的方式来保持线程的同步,并且可以实现不同进程中的线程同步操作。
11. 请问进程线程的区别,进程间怎么相互通信,什么是多线程,什么是并发
参考回答:
进程和线程的区别有以下几点
-
进程是资源分配的最小单位,线程是程序执行的最小单位
-
进程有自己独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段,堆栈段,数据段,而线程是共享进程中的数据的,使用相同的地址空间,但是CPU切换一个线程的花费远比进程要小,
-
线程之间通信方式更方便,同一进程下的线程共享全局变量等数据,而进程之间的通信方式需要以通信的方式进行,
-
多线程程序中只要有一个线程死掉了,整个进程也死掉了,而一个进程死掉了,并不会对另一个进程造成影响,因为进程有自己独立的地址空间
进程间的通信方式:
-
无名管道通信,数据只能单向流动,只能在具有亲缘的进程间使用
-
高级管道通信,将领一个程序当作一个新的进程在当前程序中启动,则他算是当前进程的子进程
-
有名管道通信,允许无亲缘关系进程间的通信
-
消息队列通信,消息队列是由消息的链表,存放在内核中并由消息队列标识符标识,消息队列克服了信息传递信息少等缺点
-
信号量通信,信号量用于控制多个进程对共享资源的访问
-
信号通信,用于通知接受进程某个事件已经发生
-
共享内存通信,共享内存映射一段能被其他进程所访问的内存,往往与其他通信机制配合使用,来实现进程间的同步和通信
-
套接字通信,他用于不同机器之间的进程通信
什么是多线程
多线程就是指一个进程中同时有多个执行路径正在执行
并发指在操作系统中,一个时间段中有几个程序都已处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上面,但任意时刻点上只有一个程序在处理机上运行。
后话
本文资料已经整理在这个word文档里,需要的伙伴请移步一下点击并输入暗号:CSDN