6.1810: Operating System Engineering 2023 <Lab6: Multithreading>
一、本节任务



二、要点
2.1 锁(Locking)
在多 CPU 或者单 CPU 多线程并发的场景中,对临界资源(或者说共享资源)的访问如果不加以限制,可能会引发一些严重的问题,比如当两个线程同时对一个共享数据写的时候,这个共享数据的值就会变为最后一个写的内容,并且会覆盖前一个写的内容。这时候,就有人引入了一些并发控制(concurrency control)技术来避免并发场景中的这些问题。
其中最常用的就是锁,锁提供了互斥性,保证了在任何时刻只能有一个线程持有它,并且对于锁所保护的对象,只有持有锁的线程才能操作它,其他想要操作该对象的线程必须等待锁的释放。虽然锁能很好地保护临界资源,但是过度使用锁也会导致系统的并发性能下降(毕竟其他想要访问该资源的线程只能等待或阻塞)。
比如,在 xv6 中访问临界资源时,可以使用 acquire 和 release 来获取和释放锁,在 acquire 和 release 之间的区域被称为临界区(critical section)。

在 xv6 中有两种类型的锁,一种是自旋锁(spinlock),另一种为睡眠锁(如信号量)。
自旋锁最多只能被一个可执行线程持有,持有自旋锁的线程无法让出 CPU。其他想要获取该锁的线程会一直进行忙循环-旋转-等待锁重新可用。自旋锁不应该被长时间持有,因为其他想要获取该锁的线程会循环等待。自旋锁可以用在中断处理程序中(此处不能使用信号量,因为信号量机制会导致睡眠,前面说过中断处理程序要求尽快执行完)。
信号量是一种睡眠锁。如果有一个线程试图获得一个已经被占用的信号量时,信号量会将其推进一个等待队列,然后让其睡眠。信号量适用于锁会被长时间持有的情况。信号量不能在中断程序中使用,因为在中断上下文中是不能进行调度的。在请求信号量的时候不能占用自旋锁,因为持有自旋锁时是不能睡眠的。可以使用信号量而不是自旋锁来使得在发生争用时,等待的线程能投入睡眠,而不是旋转。
在请求多个锁时,所有线程要使用相同的请求顺序,否则可能造成死锁(deadlock)的问题。
死锁详解和解决办法_避免死锁的三种方法-CSDN博客
xv6 为了避免线程在持有锁的时候进入中断处理函数,在获取自旋锁后,会关闭中断。
在某些场景中,编译器会对代码进行一些优化,比如打乱指令顺序来提高性能,这时候如果要保护的临界区域的内容被优化到临界区之外时,可能会导致一些问题,这时候可以使用内存屏障(memory barrier)来告诉编译器和 CPU 不要重新排序加载或存储。
对于需要长时间等待的操作来说,睡眠锁是十分好的,比如在需要操作一块磁盘区域的时候,该操作十分耗费时间,线程等待锁的时间也十分长,这时候使用睡眠锁可以让等待的线程进入阻塞状态,这时候就可以让其他线程先执行。
2.2 调度(Scheduling)
struct proc in proc.h
p->trapframe holds saved user thread's registers
p->context holds saved kernel thread's registers
p->kstack points to the thread's kernel stack
p->state is RUNNING, RUNNABLE, SLEEPING, &c
p->lock protects p->state (and other things...)
在 xv6 中,有两种情况会导致进程切换:
- 第一种,xv6 的 sleep 和 wakeup 机制可能会导致进程切换。
- 第二种,xv6 中的定时器中断每次会导致进程切换。
从一个线程切换到另外一个线程需要保存当前线程的寄存器,并且恢复新进程的寄存器;其中 program counter 和 stack pointer 两个寄存器意味着线程的执行位置和栈指针会被保存,因为 CPU 会切换到新进程的位置执行并且切换到新进程的栈。
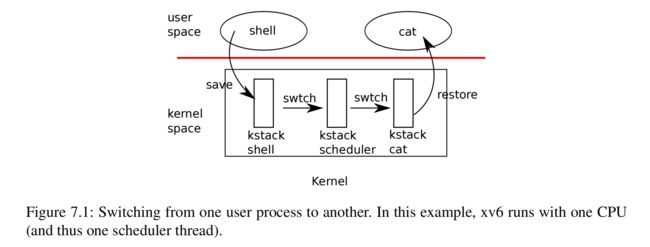
在 xv6 中,swtch 函数(kernel/swtch.S)实现内核线程的切换(如上图所示),swtch 会保存和恢复一系列的寄存器,这些寄存器被称为上下文(contexts)。当当前进程需要放弃 CPU 的时候,这个进程的内核线程调用 swtch 函数来保存当前上下文并且恢复调度器(scheduler)的上下文。swtch 函数的代码如下:
.globl swtch
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
retswtch 函数有两个参数,一个是 struct context *old,也就是当前线程的上下文,另外一个是 struct context *new,即新线程的上下文。从上述代码可以看出,swtch 函数仅仅保存了函数调用约定中 callee 需要保存的寄存器(保存 ra 的目的是为了在 ret 指令后能返回到新线程对应位置执行,因此也不需要保存 pc 寄存器),而返回的位置一般是调用 swtch 函数之后:

返回之后程序会恢复函数调用约定中 caller 需要保存的一系列寄存器(C 编译器在 caller 中生成代码,以在栈上保存 caller 保存的寄存器),从而完整恢复线程的上下文。

切换到当前 CPU 运行的 scheduler 线程后,由 scheduler 线程选择下一个需要运行的线程,然后调用 swtch 切换至该进程:

2.2 Sleep and wakeup
调度和锁能帮我们向其他进程隐藏执行细节,但是外面需要一些手段来帮助进程来进行有意地交互。例如,一个 pipe 的读进程必须等待写进程产生数据;一个父进程的 wait 必须等待子进程 exit;进程读写磁盘则需要磁盘硬件完成读写操作。在 xv6 中使用 sleep 和 wakeup 来解决这些问题,sleep 可以让内核线程等待某个特定事件的发生,而其他线程能使用 wakeup 来告诉另外一个线程其等待的某个事件需要被处理。sleep 和 wakeup 机制也被称为 sequence coordination 或者 conditional synchronization 机制(其实就是一种同步机制,并且和 spinlock 不一样,这种同步机制在等待的时候会让出 CPU,而不是轮询)。
下面是 sleep 函数的源码:
// Atomically release lock and sleep on chan.
// Reacquires lock when awakened.
void
sleep(void *chan, struct spinlock *lk)
{
struct proc *p = myproc();
// Must acquire p->lock in order to
// change p->state and then call sched.
// Once we hold p->lock, we can be
// guaranteed that we won't miss any wakeup
// (wakeup locks p->lock),
// so it's okay to release lk.
acquire(&p->lock); //DOC: sleeplock1
release(lk);
// Go to sleep.
p->chan = chan;
p->state = SLEEPING;
sched();
// Tidy up.
p->chan = 0;
// Reacquire original lock.
release(&p->lock);
acquire(lk);
}wakeup 函数的源码:
// Wake up all processes sleeping on chan.
// Must be called without any p->lock.
void
wakeup(void *chan)
{
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
if(p != myproc()){
acquire(&p->lock);
if(p->state == SLEEPING && p->chan == chan) {
p->state = RUNNABLE;
}
release(&p->lock);
}
}
}想象一下,如果在 sleep 函数将线程设置为 SLEEPING 状态之前调用 wakeup 函数,会发生什么问题。很明显,这会导致被 sleep 线程永远都无法被唤醒。
xv6 使用锁来避免这种情况,如下图,在调用 sleep 函数之前,会先申请请求对象的锁 s->lock:

然后 sleep 再去获取线程的锁 p->lock,获取到线程的锁之后,这时候再释放请求对象的锁 s->lock 就是安全的了,因为就算此时 wakeup 函数开始执行,也会卡在 acquire(&p->lock); 这一步,只有等待当前线程设置状态为 SLEEPING,并且切换到其他线程释放 p->lock 后,wakeup 函数才能开始判断线程状态,并且将其唤醒。

三、Lab: Multithreading
这个 lab 会让你熟悉多线程,实现一个用户级别的线程包,并且实现一个屏障(barrier)。
3.1 Uthread: switching between threads (moderate)
在这部分你需要为用户级别的线程设计一个上下文切换机制,并且实现它。在 user 目录下有 uthread.c 和 uthread_switch.S,uthread.c 里包括了用户级别的线程包的实现(部分代码要你自己写),uthread_switch.S 则为上下文切换的汇编(也需要你自己实现)。
实现:
首先在 uthread.c 中声明线程上下文结构体(之所以不需要全部寄存器的原因在上面已经说到了,和内核实现 swtch 的原理是一样的),然后到 thread 结构体中添加 context 成员:
struct thread_context {
/* 0 */ uint64 ra;
/* 8 */ uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
struct thread {
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
struct thread_context context;
};thread_create 函数会初始化线程, sp 寄存器指向线程的栈顶,ra 寄存器指向线程的入口函数:
void
thread_create(void (*func)())
{
struct thread *t;
for (t = all_thread; t < all_thread + MAX_THREAD; t++) {
if (t->state == FREE) break;
}
t->state = RUNNABLE;
// YOUR CODE HERE
t->context.sp = (uint64)((char *)t->stack + STACK_SIZE);
t->context.ra = (uint64)func;
}
thread_schedule 函数在找到可执行的线程后,使用 thread_switch() 函数切换到下一个线程执行:
thread_schedule(void)
{
struct thread *t, *next_thread;
/* Find another runnable thread. */
next_thread = 0;
t = current_thread + 1;
for(int i = 0; i < MAX_THREAD; i++){
if(t >= all_thread + MAX_THREAD)
t = all_thread;
if(t->state == RUNNABLE) {
next_thread = t;
break;
}
t = t + 1;
}
if (next_thread == 0) {
printf("thread_schedule: no runnable threads\n");
exit(-1);
}
if (current_thread != next_thread) { /* switch threads? */
next_thread->state = RUNNING;
t = current_thread;
current_thread = next_thread;
/* YOUR CODE HERE
* Invoke thread_switch to switch from t to next_thread:
* thread_switch(??, ??);
*/
thread_switch((uint64)&t->context, (uint64)&next_thread->context);
} else
next_thread = 0;
}
thread_switch 函数保存当前线程的上下文,并且恢复新线程的上下文:
thread_switch:
/* YOUR CODE HERE */
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret /* return to ra */使用 gdb 调试:
file user/_uthread
b uthread.c:60 // thread_switch 函数的位置
p/x *next_thread // p/x 表示以 16 进制的格式打印 next_thread 指向的内容
x/x next_thread->stack // x/x 表示以 16 进制打印 next_thread->stack 的地址
b thread_switch // 在 thread_switch 函数处设置断点3.2 Using threads (moderate)
这部分给我们一个程序 ph.c,里面程序会 put 数据到一个 hashtable 中,然后再从 hashtable 中 get 数据,单线程运行的时候是正常的,但是在多线程运行的时候会出现 key missing 的情况,需要我们使用锁来保护多线程中对 hashtable 的修改,并且修改后还要保证多线程相比于单线程的加速。代码如下:
每个 hash bucket 都使用一个锁来保护,使用 init_locks() 函数来初始化该锁:
pthread_mutex_t lock[NBUCKET];
void init_locks()
{
for(int i = 0; i < NBUCKET; i++){
pthread_mutex_init(&lock[i], NULL);
}
}
在 put 中使用对应的锁来保护对 hashtable 的写操作,读和写并不冲突(因为该例中并不关心 value 的内容,只关心 key 是否插入) ,当两个线程同时对一个 hashtable 进行 insert 操作时,可能会由于并发导致某个 key 丢失,所以对这部分加锁即可:
static
void put(int key, int value)
{
int i = key % NBUCKET;
// is the key already present?
struct entry *e = 0;
for (e = table[i]; e != 0; e = e->next) {
if (e->key == key)
break;
}
pthread_mutex_lock(&lock[i]);
if(e){
// update the existing key.
e->value = value;
} else {
// the new is new.
insert(key, value, &table[i], table[i]);
}
pthread_mutex_unlock(&lock[i]);
}
pthread_create() 可以创建线程,pthread_join() 会挂起调用线程,等待被调用线程被终止,pthread_mutex_lock() 则是请求互斥锁的函数。
pthread_create()
pthread_join()
pthread_mutex_lock()
3.3 Barrier(moderate)
这部分需要我们实现一个屏障,即在所有线程到达屏障之前,都必须等待,直到所有线程到达才能继续往下执行,其实就是一种同步方法。代码如下,使用互斥锁 bstate.barrier_mutex 来保证对 barrier 修改是原子的,使用 pthread_cond_wait() 函数让当前线程在 cond 上睡眠,等待最后一个线程到来使用 pthread_cond_broadcast() 来将所有在 cond 上睡眠的线程唤醒:
static void
barrier()
{
// YOUR CODE HERE
//
// Block until all threads have called barrier() and
// then increment bstate.round.
//
pthread_mutex_lock(&bstate.barrier_mutex);
bstate.nthread++;
if(bstate.nthread == nthread){
pthread_cond_broadcast(&bstate.barrier_cond);
bstate.round++;
bstate.nthread = 0;
}
else
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
pthread_mutex_unlock(&bstate.barrier_mutex);
}
最后成功通过测验。