Elasticsearch基本操作
1、数据格式
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档。
为了方便理解,我们将Elasticsearch里存储文档数据和关系型数据库MySQL存储数据的概念进行类比。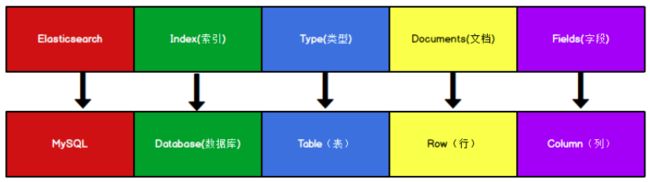
这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个 type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
这里我们着重的讲一下ES里面的各种概念!
1.1、Elasticsearch基本概念
ES中的几个基本概念:索引(index)、类型(type)、文档(document)、映射(mapping)等。我们将这几个概念与传统的关系型数据库做对比:
| RDBS | ES |
|---|---|
| 数据库(database) | 索引(index) |
| 表(table) | 类型(type)(6.0被废弃,7.0之后完全删除) |
| 表结构(schema) | 映射(mapping) |
| 行(row) | 文档(document) |
| 列(column) | 字段(field) |
| SQL | 查询DSL |
索引(index)
索引是es的一个逻辑存储,对应关系型数据剧中的库,es可以把索引数据存放到服务器中,也可以sharding(分片)后存储到多台服务器上。每个索引有一个或多个分片,每个分片可以有多个副本。
类型(type)
es中,一个索引可以存储多个用于不同用途的对象,可以通过类型来区分索引中的不同对象,对应关系型数据库中表的概念。但是在ES6.0开始,类型的概念被废弃,ES7中将它完全删除。删除type的原因:
我们一直认为es中的“index”类似于关系型数据库的“database”,而“type”相当于一个数据表。ES的开发者们认为这是一个糟糕的认识。例如:关系型数据库中两个数据表是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。
我们都知道elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的。举个例子,两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。
去掉type能够使数据存储在独立的index中,这样即使有相同的字段名称也不会出现冲突,就像ElasticSearch出现的第一句话一样“你知道的,为了搜索····”,去掉type就是为了提高ES处理数据的效率。
除此之外,在同一个索引的不同type下存储字段数不一样的实体会导致存储中出现稀疏数据,影响Lucene压缩文档的能力,导致ES查询效率的降低。
文档(document)
存储在es中的主要实体叫文档,可以理解为关系型数据库中的表的一行数据记录。每个文档由多个字段(field)组成。区别与关系型数据库的是,es是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个为唯一标识。
映射(mapping)
映射是对索引库中的索引字段及其数据类型进行定义,类似于关系型数据库中的表结构。es默认动态创建索引与索引类型之间映射,这就像关系型数据,区别于关系型数据库中的表,无需定义表结构,更不用指定字段的数据类型,当然也可以手动指定映射类型。
用json作为文档序列化的格式,比如一条用户信息:
{
"name": "John",
"sex": "Male",
"age": 25,
"birthDate": "1990/05/01",
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
2、HTTP操作
2.1、索引操作
1)创建索引
对比关系型数据库,创建索引就等同于创建数据库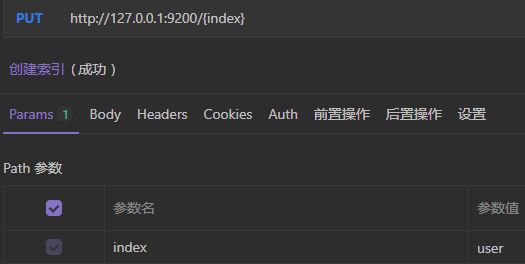
返回结果
{
"acknowledged": true, #响应结果
"shards_acknowledged": true, #分片结果
"index": "user" # 索引名称
}
如果重复添加索引,会返回错误信息
{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [user/NOB2i1dKT6CdVMQUEd2OcQ] already exists",
"index_uuid": "NOB2i1dKT6CdVMQUEd2OcQ",
"index": "user"
}
],
"type": "resource_already_exists_exception",
"reason": "index [user/NOB2i1dKT6CdVMQUEd2OcQ] already exists",
"index_uuid": "NOB2i1dKT6CdVMQUEd2OcQ",
"index": "user"
},
"status": 400
}
2)查询所有索引
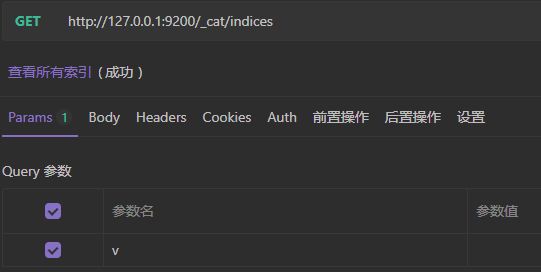
请求路径中的_cat表示查看的意思,indices表示索引,所以整体含义就是查看当前ES服务器中的所有索引,类比于mysql中的show tables
返回结果:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open user2 2XDDWwaESKSD-bU4nMQgYg 1 1 0 0 208b 208b
yellow open user NOB2i1dKT6CdVMQUEd2OcQ 1 1 0 0 208b 208b
| 表头 | 含义 |
|---|---|
| health | 当前服务器健康状态: green(集群完整) yellow(单点正常,集群不完整) red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引同意编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
3)查看单个索引
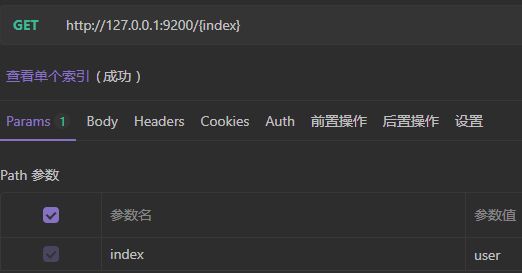
返回结果
{
"user": { #索引名
"aliases": {}, #别名
"mappings": {}, #映射
"settings": { #设置
"index": { # 索引
"creation_date": "1666861099378", #创建时间
"number_of_shards": "1", #主分片数量
"number_of_replicas": "1", #副分片数量
"uuid": "NOB2i1dKT6CdVMQUEd2OcQ", #唯一标识
"version": { #版本
"created": "7080099"
},
"provided_name": "user" #名称
}
}
}
}
4)删除索引
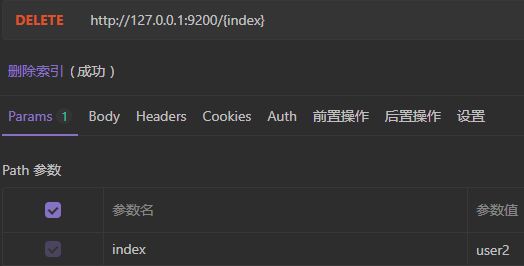
返回结果
{
"acknowledged": true
}
索引不能重复删除,再次访问会返回索引不存在!
2.2、文档操作
1)创建文档
不指定ID
索引已经创建好了,接下来我们创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加数据格式为json格式
# 请求体的body是:
{
"name": "张三",
"age": 18,
"sex": "男",
"salary": 2000
}
#返回结果是
{
"_index": "user", #索引
"_type": "_doc", #类型-文档
"_id": "iHfHGIQB8uYYV2U5lsPY", #主键,不指定会随机生成
"_version": 1, #版本
"result": "created", #结果 created表示创建成功
"_shards": { #分片
"total": 2, #总数
"successful": 1, #成功
"failed": 0 #失败
},
"_seq_no": 2,
"_primary_term": 1
}
指定ID(post和put请求都可以)
返回结果
{
"_index": "user",
"_type": "_doc",
"_id": "1001", #这里的ID已经变成我们指定的ID
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
2)查看文档
需要指定文档ID,类似于MySQL中根据主键查询数据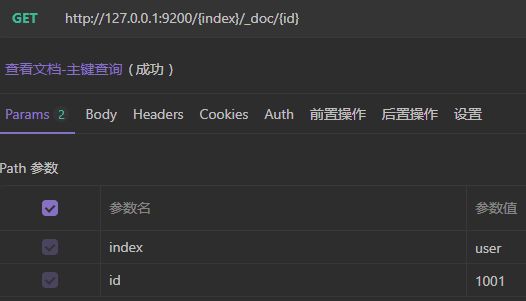
返回结果:
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"name": "李四",
"age": 19,
"sex": "女",
"salary": 3000
}
}
3)修改文档
和新增文档一样,输入相同的url地址请求,如果请求体变化,会将原有的数据覆盖。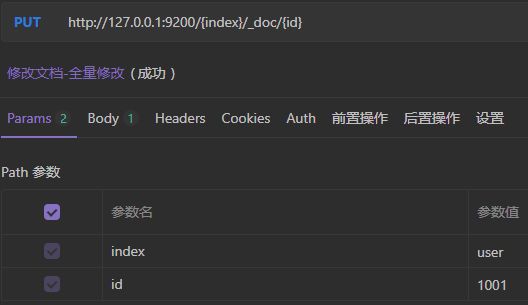
# body请求体
{
"name": "李四",
"age": 19,
"sex": "男",
"salary": 3001
}
# 返回结果
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_version": 2, # 版本号改变了
"result": "updated", # updated表示数据被更新
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
4)修改字段
修改数据时,也可以只修改某一条数据的局部信息
# body请求体
{
"doc": {
"name": "李四updated"
}
}
# 返回结果
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_version": 3, #版本号改变了
"result": "updated", #更新成功
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
5)删除文档
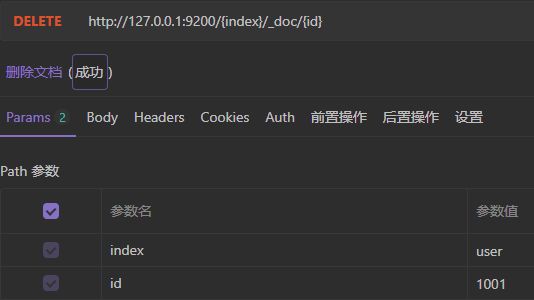
# 返回结果
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_version": 6,
"result": "deleted", #deleted 表示数据被标记为删除
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 6,
"_primary_term": 1
}
6)条件删除文档
一般删除数据都是根据文档的唯一性标识进行删除,实际操作时,也可以根据条件对多条数据进行删除
首先分别增加多条数据(前面已经讲到了怎么添加文档数据)
{
"name": "王五",
"age": 20,
"sex": "男",
"salary": 4000
}
{
"name": "赵六",
"age": 20,
"sex": "女",
"salary": 5000
}
我们来条件删除文档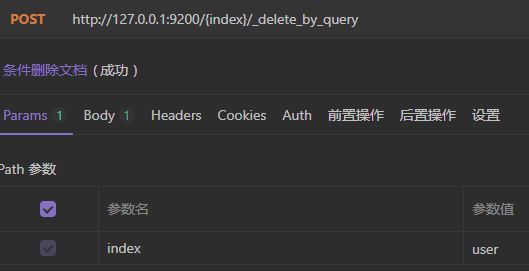
#请求体body
{
"query": {
"match": {
"age": 20
}
}
}
#返回结果
{
"took": 69, #耗时
"timed_out": false, #是否超市
"total": 2, #总数
"deleted": 2, #删除数量
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
2.3、映射操作
有了索引库,就等于有了数据库中的database
接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)
创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
映射数据说明:
- 字段名:任意填写
- type:类型,es中支持的数据类型非常丰富,说几个关键的:
- String类型,又分两种
- text:可分词
- keyword:不可分词,数据会作为完整字段进行匹配
- Numerical:数值类型,分两类
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- Date:日期类型
- Array:数组类型
- Object:对象
- String类型,又分两种
- index:是否索引,默认为true,也就是说你不进行配置,所有字段都会被索引
- true:字段会被索引,则可以用来进行搜索
- false:字段不会被索引,不能用来搜索、
- store:是否将数据进行独立存储,默认为false
- 原始文本会存储在_source里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source里面提出取出来的。当然你也可以独立的存储某个字段,只要设置
"store": true即可,获取独立存储的字段要比从_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置
- 原始文本会存储在_source里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source里面提出取出来的。当然你也可以独立的存储某个字段,只要设置
- analyzer:分词器。这里的
ik_max_word即使用ik分词器,我们后面专门讨论。
1)创建映射

#请求体
{
"properties": {
"name": {
"type": "text",
"index": true
},
"age": {
"type": "long",
"index": false #index设置为false的字段其实就是不能被检索
},
"sex": {
"type": "text",
"index": false
},
"salary": {
"type": "long",
"index": true
}
}
}
#返回结果
{
"acknowledged": true
}
2)查看映射
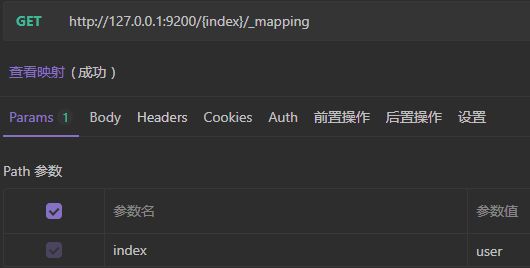
返回结果:
{
"user": {
"mappings": {
"properties": {
"age": {
"type": "long",
"index": false
},
"name": {
"type": "text"
},
"salary": {
"type": "long"
},
"sex": {
"type": "text",
"index": false
}
}
}
}
}
3)索引关联映射
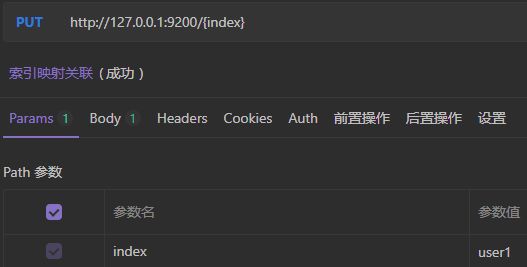
#请求体
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"index": true
},
"age": {
"type": "long",
"index": false
},
"sex": {
"type": "text",
"index": false
},
"salary": {
"type": "long",
"index": true
}
}
}
}
#返回结果
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "user1"
}
2.4、高级查询
es基于json提供了完整的DSL自定义查询:
{
"query": {
"match_all": {
}
}
}
# query:这里的query代表一个查询对象,里面可以有不同的查询属性
# match_all:查询类型,例如:match_all(代表查询所有),match,term,range等等
# {查询条件}:查询条件会根据类型的不同,写法也有差异
我们先插入几条数据:
# POST /student/_doc/1001
{
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
# POST /student/_doc/1002
{
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
# POST /student/_doc/1003
{
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
}
# POST /student/_doc/1004
{
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
# POST /student/_doc/1005
{
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
查询请求URL:
GET http://127.0.0.1:9200/{index}/_search
1)查询所有文档
全查询不需要入参,直接请求url
返回结果:
{
"took": 6, #查询花费时间,单位毫秒
"timed_out": false, #是否超市
"_shards": { #分片信息
"total": 1, #总数
"successful": 1, #成功
"skipped": 0, #忽略
"failed": 0 #失败
},
"hits": { #搜索命中结果
"total": { #搜索条件匹配的文档总数
"value": 5, #总命中计数的值
"relation": "eq" #计数规则,eq表示计数准确,gte表示计数不准确
},
"max_score": 1, #匹配度分值
"hits": [ #命中结果集合
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": 1,
"_source": {
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": 1,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
}
]
}
}
2)匹配查询
match匹配类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是**or**的关系。
#请求体
{
"query": {
"match": {
"name": "zhangsan lisi"
}
}
}
#返回结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1.3862942,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
}
]
}
}
3)字段匹配查询
multi_match与match类似,不同的是它可以在多个字段中查询。
#请求体
{
"query": {
"multi_match": {
"query": "zhangsan lisi",
"fields": [
"name",
"nickname"
]
}
}
}
#返回结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1.3862942,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
}
]
}
}
4)关键字精确查询
#请求体
{
"query": {
"term": {
"name": {
"value": "zhangsan"
}
}
}
}
# 返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
}
]
}
}
#请求体
{
"query": {
"term": {
"name": {
"value": "zhangsan wangwu"
}
}
}
}
#返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
5)多关键字精确查询
terms查询和term查询一样,但它允许你指定多值进行匹配。
如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件,类似于mysql中的in查询
#请求体
{
"query": {
"terms": {
"name": [
"zhangsan",
"lisi"
]
}
}
}
#返回结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
}
]
}
}
6)指定查询字段
#请求体
{
"_source": [
"name",
"nickname"
],
"query": {
"terms": {
"nickname": [
"zhangsan"
]
}
}
}
#返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan"
}
}
]
}
}
7)过滤字段
我们可以通过:
- includes:来指定想要显示的字段
- excludes:来指定不想要显示的字段
//请求体
{
"_source": {
"includes": [ //includes:来指定想要显示的字段;excludes:来指定不想要显示的字段
"name",
"nickname"
]
},
"query": {
"terms": {
"nickname": [
"zhangsan"
]
}
}
}
//返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan"
}
}
]
}
}
8)组合查询
bool把各种其他查询通过must(必须)、must_not(必须不)、should(应该)的方式进行组合。
//请求体
{
"query": {
"bool": {
"must": [ //理解为and
{
"match": {
"name": "zhangsan"
}
}
],
"must_not": [ //理解为not
{
"match": {
"age": "40"
}
}
],
"should": [ //理解为or
{
"match": {
"sex": "男"
}
}
]
}
}
}
//返回结果
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.261763,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 2.261763,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
}
]
}
}
9)范围查询
range查询找出哪些落在指定区间内的数据或者时间。range查询允许以下字符
| 操作符 | 说明 |
|---|---|
| gt | 大于 > |
| gte | 大于等于 >= |
| lt | 小于 < |
| lte | 小于等于 <= |
#请求体
{
"query": {
"range": {
"age": {
"gte": 30,
"lte": 35
}
}
}
}
#返回结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
}
]
}
}
10)模糊查询
返回包含与搜索字词相似的字词的文档
编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数。这些更改可以包括:
- 更改字符(box -> fox)
- 删除字符(black -> lack)
- 插入字符(sic -> sick)
- 转置两个相邻字符(act -> cat)
为了找到相似的术语,fuzzy查询会在指定的编辑距离内创建一组搜索词的所有可能的变体或扩展。然后查询返回每个扩展的完全匹配。
通过fuzziness修改编辑距离。一般使用默认值AUTO,根据术语的长度生成编辑距离。
#请求体
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan"
}
}
}
}
#返回结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": 1.2130076,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1.2130076,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
}
]
}
}
#请求体
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan",
"fuzziness": 2
}
}
}
}
#返回结果
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": 1.2130076,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1.2130076,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
}
]
}
}
11)单字段排序
sort可以让我们按照不同的字段进行排序,并且通过order指定排序的方式。desc降序,asc升序。
#请求体
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan"
}
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
#返回结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": null,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
},
"sort": [
50
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": null,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
},
"sort": [
30
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": null,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
},
"sort": [
30
]
}
]
}
}
12)多字段排序
假定我们想要结合使用age和_score进行查询,并且匹配的结果首先按照年龄排序,然后按照相关性得分排序。
#请求体
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
},
{
"_score": {
"order": "desc"
}
}
]
}
#返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": 1,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
},
"sort": [
50,
1
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": 1,
"_source": {
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
},
"sort": [
40,
1
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
},
"sort": [
30,
1
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
},
"sort": [
30,
1
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
},
"sort": [
20,
1
]
}
]
}
}
13)高亮查询
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为**高亮 **
比如在百度上搜索“京东”,则得到以下结果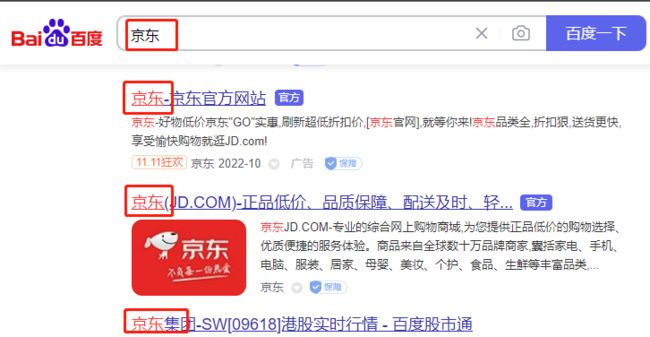
es可以对查询内容中的关键字部分,进行标签和样式(高亮)的设置。
在使用match查询的同时,加上一个highlight属性:
- pre_tags:前置标签
- post_tags:后置标签
- fields:需要高亮的字段
- title:这里声明title字段需要高亮,后面可以为这个字段设置特有配置,也可以空
#请求体
{
"query": {
"match": {
"name": "zhangsan"
}
},
"highlight": {
"pre_tags": "",
"post_tags": "",
"fields": {
"name": {}
}
}
}
#返回结果
{
"took": 47,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
},
"highlight": {
"name": [
"zhangsan"
]
}
}
]
}
}
14)分页查询
from:当前页的其实索引,默认从0开始。from=(pageNum - 1) * size
size:每页显示多少条
#请求体 查看第3页
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 4,
"size": 2
}
#返回结果
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": null,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
},
"sort": [
20
]
}
]
}
}
15)聚合查询
聚合查询使用者对es文档进行统计分析,类似与关系型数据库中的group by,当然还有很多其他聚合,例如取最大值、平均值等等。
对某个字段取最大值max
#请求体
{
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
},
"size": 0
}
#返回结果
{
"took": 18,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"max_age": {
"value": 50
}
}
}
对某个字段取最小值min
#请求体
{
"aggs": {
"min_age": {
"min": {
"field": "age"
}
}
},
"size": 0
}
#返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"min_age": {
"value": 20
}
}
}
对某个字段求和sum
#请求体
{
"aggs": {
"sum_age": {
"sum": {
"field": "age"
}
}
},
"size": 0
}
#返回结果
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"sum_age": {
"value": 170
}
}
}
对某个字段取平均值avg
#请求体
{
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
},
"size": 0
}
#返回结果
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"avg_age": {
"value": 34
}
}
}
取某个字段的值进行去重之后的总数量
#请求体
{
"aggs": {
"distinct_age": {
"cardinality": {
"field": "age"
}
}
},
"size": 0
}
#返回结果
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"distinct_age": {
"value": 4
}
}
}
Stats聚合
stats聚合,对某个字段一次性返回count,max,min,avg和sum五个指标
#请求体
{
"aggs": {
"stats_age": {
"stats": {
"field": "age"
}
}
},
"size": 0
}
#返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"stats_age": {
"count": 5,
"min": 20,
"max": 50,
"avg": 34,
"sum": 170
}
}
}
16)桶聚合查询
桶聚合相当于sql中的group by语句
terms聚合,分组统计
#请求体
{
"aggs": {
"age_groupby": {
"terms": {
"field": "age"
}
}
},
"size": 0
}
#返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"age_groupby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 30,
"doc_count": 2
},
{
"key": 20,
"doc_count": 1
},
{
"key": 40,
"doc_count": 1
},
{
"key": 50,
"doc_count": 1
}
]
}
}
}
在terms分组下再进行聚合
#请求体
{
"aggs": {
"age_groupby": {
"terms": {
"field": "age"
},
"aggs": {
"sum_age": {
"sum": {
"field": "age"
}
}
}
}
},
"size": 0
}
#返回结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"age_groupby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 30,
"doc_count": 2,
"sum_age": {
"value": 60
}
},
{
"key": 20,
"doc_count": 1,
"sum_age": {
"value": 20
}
},
{
"key": 40,
"doc_count": 1,
"sum_age": {
"value": 40
}
},
{
"key": 50,
"doc_count": 1,
"sum_age": {
"value": 50
}
}
]
}
}
}