新手可理解的PyTorch线性层解析:神经网络的构建基石
目录
torch.nn子模块Linear Layers详解
nn.Identity
Identity 类描述
Identity 类的功能和作用
Identity 类的参数
形状
示例代码
nn.Linear
Linear 类描述
Linear 类的功能和作用
Linear 类的参数
形状
变量
示例代码
nn.Bilinear
Bilinear 类的功能和作用
Bilinear 类的参数
形状
变量
示例代码
nn.LazyLinear
LazyLinear 类描述
LazyLinear 类的功能和作用
LazyLinear 类的参数
变量
cls_to_become
示例代码
总结
torch.nn子模块Linear Layers详解
nn.Identity
Identity 类描述
torch.nn.Identity 类在 PyTorch 中提供了一个占位的恒等操作符,该操作符对传入的参数不敏感。它基本上是一个通过层,不对数据进行任何改变。
Identity 类的功能和作用
- 数据传递: 在网络中,
Identity类用作一个占位符,允许数据无修改地通过。 - 结构保持: 在修改或调试网络结构时,可以临时替换其他层,而不改变输入和输出的形状。
- 参数灵活性: 该类可以接受任意参数 (
*args, **kwargs),但这些参数不会被使用。
Identity 类的参数
- args (Any): 任何参数(未使用)。
- kwargs (Any): 任何关键字参数(未使用)。
形状
- 输入:
(∗),其中∗表示任意数量的维度。 - 输出:
(∗),与输入形状相同。
示例代码
import torch
import torch.nn as nn
# 创建 Identity 实例
m = nn.Identity()
# 输入数据
input = torch.randn(128, 20)
# 通过 Identity 层
output = m(input)
# 输出形状
print(output.size()) # torch.Size([128, 20])
在这个例子中,Identity 层被用作一个简单的传递层,输入和输出形状完全相同。torch.nn.Identity 类是一个非常简单但有时非常有用的工具,特别是在需要保持网络结构但又不想改变数据流的情况下。它的存在使得网络架构的调整变得更加灵活和方便。
nn.Linear
Linear 类描述
torch.nn.Linear 类在 PyTorch 中实现了一个全连接层,也被称为线性层或密集层。它对输入数据应用一个线性变换。
Linear 类的功能和作用
- 线性变换: 对输入数据应用线性变换
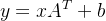 。
。 - 适用于多种网络架构: 作为神经网络中最基本的组件之一,用于构建各种复杂网络结构。
Linear 类的参数
- in_features (int): 每个输入样本的大小。
- out_features (int): 每个输出样本的大小。
- bias (bool): 如果设置为 False,则层不会学习附加的偏置。默认值:True。
形状
- 输入:
(∗, H_in),其中∗表示任意数量的额外维度,H_in是in_features。 - 输出:
(∗, H_out),除最后一维外,其他维度与输入相同,H_out是out_features。
变量
- weight (torch.Tensor): 形状为
(out_features, in_features)的可学习权重。值从均匀分布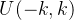 初始化,其中
初始化,其中  用于初始化神经网络中
用于初始化神经网络中 Linear(全连接) 层的权重。这里的 k 是一个根据输入特征数 (in_features) 计算出的值,用于确定权重初始化时均匀分布的范围。在这个公式中:
in_featuresin_features 指的是输入层的特征数量。
k 的值是 in_featuresin_features 的平方根的倒数。
- bias (torch.Tensor): 形状为
(out_features)的可学习偏置。如果bias为 True,则值从相同的均匀分布初始化。
示例代码
import torch
import torch.nn as nn
# 创建 Linear 实例
m = nn.Linear(20, 30)
# 输入数据
input = torch.randn(128, 20)
# 前向传播
output = m(input)
# 输出形状
print(output.size()) # torch.Size([128, 30])
这段代码展示了如何创建并使用 Linear 层。在这个例子中,输入数据的形状是 (128, 20),Linear 层将其转换为形状 (128, 30) 的输出。
nn.Bilinear
torch.nn.Bilinear 类在 PyTorch 中实现了一个双线性变换层。这个层对两个不同的输入执行双线性变换,这种变换涉及到两个输入的元素乘积。
Bilinear 类的功能和作用
- 双线性变换: 对两个输入数据
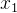 和
和  应用双线性变换
应用双线性变换 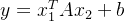 。
。 - 应用场景: 在某些场景下,双线性变换能够有效地建模两个不同输入之间的复杂关系,如在推荐系统、关系建模等领域。
Bilinear 类的参数
- in1_features (int): 第一个输入样本的特征大小。
- in2_features (int): 第二个输入样本的特征大小。
- out_features (int): 输出样本的特征大小。
- bias (bool): 如果设置为 False,则层不会学习附加偏置。默认值:True。
形状
- 输入1:
(∗, H_{in1}),其中H_{in1} = in1_features,∗表示任意数量的额外维度。 - 输入2:
(∗, H_{in2}),其中H_{in2} = in2_features。 - 输出:
(∗, H_{out}),其中H_{out} = out_features,除最后一维外,其他维度与输入形状相同。
变量
- weight (torch.Tensor): 形状为
(out_features, in1_features, in2_features)的可学习权重。值从均匀分布 初始化,其中 。 - bias (torch.Tensor): 形状为
(out_features)的可学习偏置。如果bias为 True,则值从相同的均匀分布初始化。
示例代码
import torch
import torch.nn as nn
# 创建 Bilinear 实例
m = nn.Bilinear(20, 30, 40)
# 输入数据
input1 = torch.randn(128, 20)
input2 = torch.randn(128, 30)
# 前向传播
output = m(input1, input2)
# 输出形状
print(output.size()) # torch.Size([128, 40])
这段代码展示了如何创建并使用 Bilinear 层。在这个例子中,有两个不同形状的输入数据,Bilinear 层根据这两个输入生成形状为 (128, 40) 的输出。
torch.nn.Bilinear 类是一种特殊的神经网络层,它通过将两个输入数据的特征结合起来,提供了一种模拟复杂关系的有效方式。这种层在需要考虑两组不同特征之间交互的情况下特别有用。
nn.LazyLinear
LazyLinear 类描述
torch.nn.LazyLinear 类在 PyTorch 中提供了一种“懒加载”版本的线性层(Linear)。在这个模块中,in_features(输入特征的数量)是从第一次执行前向传播时输入数据的形状推断出来的。
LazyLinear 类的功能和作用
- 自动推断
in_features: 这个类允许用户在初始化时不指定输入特征的大小(in_features),该值会在模块第一次前向传播时自动推断。 - 延迟初始化: 权重和偏置参数在第一次前向传播时才被初始化,之前它们是未初始化的。
- 转换为常规 Linear 层: 一旦完成第一次前向传播,
LazyLinear模块就会变成常规的torch.nn.Linear模块。
LazyLinear 类的参数
- out_features (int): 每个输出样本的大小。
- bias (UninitializedParameter): 如果设置为 False,则层不会学习附加偏置。默认值:True。
变量
- weight (torch.nn.parameter.UninitializedParameter): 形状为
(out_features, in_features)的可学习权重。在第一次前向传播后,值将从均匀分布初始化。 - bias (torch.nn.parameter.UninitializedParameter): 形状为
(out_features)的可学习偏置。如果bias为 True,则值也将在第一次前向传播后从均匀分布初始化。
cls_to_become
- 别名:Linear
示例代码
import torch
import torch.nn as nn
# 创建 LazyLinear 实例
lazy_linear = nn.LazyLinear(out_features=30)
# 输入数据
input = torch.randn(128, 20) # 注意,这里没有指定 in_features
# 前向传播
output = lazy_linear(input)
# 输出形状
print(output.size()) # torch.Size([128, 30])
这段代码展示了如何创建并使用 LazyLinear 层。在这个例子中,初始时并不需要指定输入特征的大小,它会在第一次调用 forward 方法时自动确定。torch.nn.LazyLinear 类是一种方便的工具,特别适合于在模型设计阶段不确定输入大小的场景。它简化了模型初始化过程,允许更灵活的设计,并在确定实际输入大小后自动完成参数初始化。
总结
本篇博客探索了 PyTorch 中 torch.nn 子模块中的几种关键线性层,包括 Identity, Linear, Bilinear, 和 LazyLinear。每个类别都被详细解析,强调了它们在神经网络中的独特角色和应用场景。从基础的 Linear 层,负责标准的线性变换,到更复杂的 Bilinear 层,用于建模两组输入特征间的交互关系,再到灵活而方便的 LazyLinear 层,自动推断输入特征大小,每种层都提供了不同的机制来处理和学习数据。