技术概述:ARMv8体系结构
John Goodacre, Director Program Management
ARM Processor Division, November 2011
背景:ARM体系结构
从ARM精简指令集体系结构提出到现在已经有20多年了;ARMv7系列处理器是在ARMv4基础上设计的,随着ARMv7系列处理器大量应用,ARM精简指令集体系结构才获得业界广泛认可。ARM一直致力于低功耗设计;最初的ARM处理器没有浮点部件,没有复杂的数学指令,没有SIMD,甚至都不支持两个整数类型的除法指令。到了2011年,ARM Cortex系列处理器都是基于ARMv7体系结构。
随着ARM处理器应用到移动设备之外的领域,ARMv7体系结构自身虽然具有一致性,依然分成三大类型:应用型A、实时型R和微控制器型M。
Cortex处理器迅速成为业界主流处理器。Cortex-A9处理器在Cortex-A8基础上研制的、支持SMP架构的、A型大处理器;而内部互连了嵌入式处理器ARM926的Cortex-A5处理器是低成本低功耗处理器方案。这些Cortex处理器拓展了ARM的很多新业务。2011年10月,Cortex-A7支持大小核提升能效管理,从而增强了电池使用寿命,已经成为智能手机入门级配置要求。
自从ARM引入ARMv7体系结构之后,随着软件生态和应用商店的发展,ARM体系结构的发展必须完全向后兼容。首先,新体系结构必须比先前体系结构有更大的优势;新体系结构还要支持先前体系结构上可运行的软件,即使该软件不使用任何新特性,也能正确运行在新体系结构之上。
一般说来,新体系结构都是在先前体系结构上增加新功能;然而,为了解决旧体系结构上的历史遗留错误,就会提出一个新的体系结构。这也是提出ARMv8体系结构的主要因素。
在最近几年,PC市场上已经有很多ARM处理器设备了。很多平板类设备都采用了Cortex-A9处理器,为各种主流PC用户提供低功耗方案;很多主流企业的设备和服务器为了提升单位功耗上的性能,也采用ARM处理器。
随着SoC集成度越来越高,亚纳米制造技术允许在一颗芯片封装内部集成很多功能模块。ARM设备性能越来越高,需要支持更多更复杂的应用软件,这些应用软件对内存的需求也越来越多;32位体系结构上的内存容量很可能不能满足这样的应用需求。
Cortex-A15处理器是遵循ARMv7体系结构,并引入了两个可选扩展功能来满足关键市场需求:大物理内存寻址扩展LPAE和虚拟化。为了在单一内存空间上集成更多设备,设备和设备之间的通信(共享内存)必须具有相同的地址映射。PC市场上的CPU和GPU具有不同的地址空间,与此不同的是,低功耗和低成本要求它们能共享内存空间。因此,LPAE就是一种解决方案;Cortex-A15支持一种新的页表格式,允许用4KB的页长度将多个32位虚拟地址空间映射最多到一个40位物理地址空间上。这种方案不仅解决了SoC高集成度与地址映射限制之间的矛盾,当前很多SoC设备都遇到地址映射限制;这种方案还解决了多个应用同时访问同一个设备的问题,与此同时针对最大访问4GB内存的应用,还不需要诸如硬盘的设备用于内存换出。绝大多数手机用户都不喜欢基于硬盘的内存换出方案。
Cortex-A15还引入了完整的虚拟化的硬件加速功能。虚拟化可以满足两个日益增长的需求:软件定义设备机制;分区机制,即将软件部署到可管理、独立的实体上。
既然ARMv7+LPAE可以突破4GB的限制,ARMv8又会带来什么优势呢?ARMv8是否需要支持全64位指令集体系结构和更大的虚拟地址空间呢?以当前ARM的市场来看,对大部分的应用而言4GB地址空间足够了。在定义新的体系结构时,ARM主要看重趋势。从商业发展来看,我们需要更长远的规划。ARMv8是ARM公司历史上经历的最大项目。创新和改变世界的能力是由软件来实现的。站在ARM角度,底层硬件平台就是赋能;ARM更重要的角色,就是赋能软件将体验和价值传递给消费者。
ARMv8体系结构的基础
此时,ARMv8体系结构还是围绕Cortex-A型处理器市场需求来定义的。ARMv7体系结构依然能够满足实时和微控制器市场上好几代的需求。事实上,Cortex-A15在扩展LPAE功能后,已经满足了A型处理器市场对“超32位”地址空间的需求。LPAE定义了一种页表格式,虚地址(这里仍然是32位的虚地址吗?)可以映射到40位物理地址空间上。我们也可以用一个更大虚拟和物理地址空间来满足上述应用需求。ARMv8定义了虚地址长度最大支持48位符号位扩展,物理地址长度最大支持48位;这样一来,ARMv8体系结构就能够最大地兼容Cortex-A15上运行的老软件。

ARMv8还定义了一个新的指令集A64;指令编码的设计目标之一就是,应用程序能够充分利用64位机。ARM引入了全新的指令集,没有通过扩展老指令集,从而支持64位体系结构;这主要基于几个方面的考虑。第一个显而易见的原因就是相比扩展老指令集,开发全新指令集可以实现更低的功耗设计。当然, ARMv8体系结构为了向前兼容而支持ARMv7机器上的老软件,但在运行全新的64位软件时,兼容ARMv7机器的硬件部件并没有被激活;这一点,与扩展老指令方式(在32位模式上简单扩展64位模式)实现的体系结构不同。新指令集借鉴了多年来不同微架构的开发经验,所以新处理器更容易实现低功耗操作的优化——从ARMv4机器(经典的低功耗ARMv7处理器就是在ARMv4基础上研发的)问世以来,这些优化开发经验自还没有真正实践过,这次正好可以在ARMv8上获得验证的机会。
全新ARMv8体系结构还优化了软件的异常模型,提高了硅片利用率,并进步一步降低了全系统的功耗。
显然,新的体系结构需要支持32位老软件。ARMv8体系结构只能在异常边界(即异常触发和异常响应之间的瞬时过程)上才能发生32/64位运行模式的切换;而在早期,传统ARM为了支持Thumb指令集,需要建立从传统ARM到Thumb的互连硬件部件。这样一来,ARMv8上的软件栈就是基于异常级(执行权限级)来构建了。
A64指令集
指令集A64定义了,每条指令长度固定为32位。对于硬件而言,最初的想法是延用早先的译码表,32位指令集和64位指令集可以共用一套译码器;但是这样的想法很快被摒弃了,因为这会导致操作数和立即数被迫分散在不连续的位域上,译码结构显得很凌乱。64位指令集采用全新译码表设计,不仅简化了译码表硬件设计,而且为JIT编译器提供了很重要的加速能力,这有助于web浏览器等应用领域的性能提升。全新设计的译码还有助于实现先进的分支预测技术。A64指令集增加了通用寄存器数量。Cortex-A9引入了虚拟重命名寄存器池化技术,硬件可以自动对小循环进行展开,但该技术并没有给编译器提供更多的可编程寄存器,主要考虑到可编程寄存器越多软件算法的实现就会越复杂。因此,A64指令集仅引入31个64位通用寄存器。A64指令集在已有的指令集基础上进行了简化。对比ARM早期指令集,新的A64指令还删除了LDM/STM指令,这条指令耗时很长而且增加了内存系统实现的复杂度。考虑复杂度和性价比,A64指令集也减少了条件指令。
商用软件在使用浮点计算单元之前,一般都假定硬件浮点单元存在且有效,所以不会提前检测硬件浮点单元是否有效。因此,A64指令集提供了浮点计算指令。
A64指令集还提供了SIMD数据引擎指令集。SIMD提供了遵循IEEE754-2008标准的双精度数据计算指令。
异常级
AArch64的异常级和Cortex-A15处理器的一样,在操作系统内核态和TrustZone监控态之间增加了虚拟机监控HYP态。出于安全软件简单实现的考虑,安全世界依然只能支持一个操作系统实例。
异常层次结构还定义了32位操作模式和64位操作模式之间的切换的规则。当异常级提升时,操作模式的位宽要么保持,要么增大。当虚拟机监控HYP态为32位操作模式时,它是不可能支持64位的操作系统内核态的。

为了支持新型异常级模型,A64还引入了一个专门的异常链接寄存器ELR,在异常级入口该寄存器自动写入。如果从32位操作模式切换到64位操作模式,该寄存器的高32位会自动进行零扩展。在异常级入口,自动设置中断屏蔽。每个异常级都有自己的向量基地址寄存器,每个向量都对应到四种类型中的一个:同步、IRQ、FIQ或错误。每个向量都对应特定的触发异常原因,也可根据症状寄存器获得异常原因的详细信息。这样设计有一个特别有用的优点,就是支持IO设备虚拟化,即虚拟机一旦访问设备就会陷入到虚拟机监控态,虚拟机监控软件通过读取症状寄存器来获悉哪个操作被虚拟化了。
内存管理单元
在原理上,AArch64定义的内存管理单元和Cortex-A15的一样,增加了48位虚拟地址和物理地址支持。采用四级页表就能支持48位地址,这样的地址编码简化了硬件设计,还降低了验证的复杂度。实际上,AArch64支持4KB和64KB两种最小页长度,如果采用42位地址长度方案,就只需要两级页表。
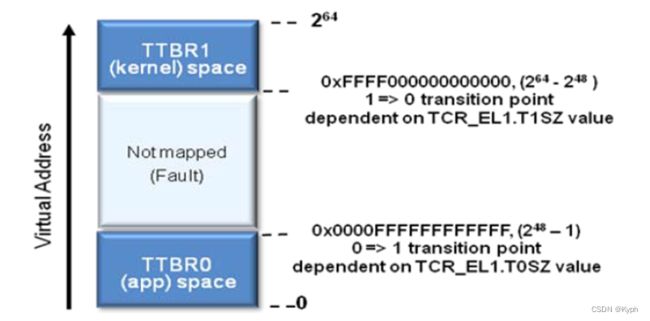
当然,32位的代码只能被限制在第一个4GB地址空间,硬件会自动用零扩展方式实现32位地址到64位地址转换。64位地址空间的虚拟地址分为三个地址范围:最底段地址范围(长度为232或248字节)用于应用程序;最高段地址范围(长度为232或248字节)用于操作系统内核;中间部分是空洞,参见上图。
在Cortex-A15处理器中,ARMv8内存管理单元提供两阶段地址翻译:从应用虚拟地址VA,到中间物理地址IPA,然后再到内存总线的实际物理地址PA;虚拟机监控器负责IPA到PA的地址翻译。IPA和PA的地址长度实现为在32位到48位之间。
程序寄存器
汇编程序员或编译器开发者对A64指令集最大不同的感受是来自,30个通用寄存器。每个寄存器都是64位宽,寄存器名称为X0~X30;看上去是31个通用寄存器,但X30不是严格意义上的通用寄存器,而主要用作程序链接寄存器PLR。
与AArch32环境的每个操作状态都有一组专属的banked寄存器;与此不同,在AArch64中,只有堆栈指针寄存器SP,异常链接寄存器ELR和处理状态保存寄存器SPSR是banked寄存器,其他的寄存器都不是。与AArch32的当前处理器状态不同,AArch64的PState分类相互独立访问,例如标志位NZCV,因此对寄存器中的某一位的读/写/修改几乎不需要用原子操作来实现。
| X0-X7 |
X8-X5 |
X16-X23 |
X24-X30 |
|
| 0 |
R0 |
R8_usr |
R14_irq |
R8_fiq |
| 1 |
R1 |
R9_usr |
R13_irq |
R9_fiq |
| 2 |
R2 |
R10_usr |
R14_svc |
R10_fiq |
| 3 |
R3 |
R11_usr |
R13_svc |
R11_fiq |
| 4 |
R4 |
R12_usr |
R14_abt |
R12_fiq |
| 5 |
R5 |
R13_usr |
R13_abt |
R13_fiq |
| 6 |
R6 |
R14_usr |
R14_und |
R14_fiq |
| 7 |
R7 |
R13_hyp |
R13_und |
No Register |
因为64位和32位寄存器之间存在关联关系,即32位寄存器简单地映射到64位寄存器的低32位上,所以64位OS或虚拟机监控软件可以支持32位代码的运行。
调试
ARMv7和ARMv8调试架构使用的概念和原理是相同的。调试器可以直接发送指令给处理器去运行,处理器有其他通道可以提取已经执行过的指令。有两种侵入式调试方法:self-host和halt。ARMv8调试与ARMv7设备中的调试类似,不同之处在于所有断点和观察点都已增长到64位地址长度,而且在调试状态下可直接执行的指令仅限于可用指令的一小部分。
然而,应该注意的是,halt调试视图与ARMv7目前支持的halt调试工具并不兼容,即使ARMv8处理器上仅运行32位代码;为了能正常调试ARMv8,必须更新调试器。但是对AArch32进行self-host调试不需要修改。
生态演变
显然,引入新指令集的主要挑战不是硬件开发,而是生态系统中工具和软件的迁移和支持。ARM拥有令人羡慕的生态系统,预计未来12个月将有100亿台ARM驱动的设备推向市场。
基于上述原因,ARM处理器要平滑支持现有32位软件,不能对生态系统造成冲击。只有部分核心软件才需要一开始就要基于A64指令进行扩展或修改;例如虚拟机监控器软件或安全监控器软件。Cortex-A15处理器首次引入了新硬件组件来提升虚拟化性能,例如Cortex-A15处理器支持了很多新的页表格式;因此,很多厂商可以接收虚拟机监控器软件的更新换代,而且已经开始进行了替换。
接下来需要考虑将操作系统升级为64位。ARMv8希望A型设备能够运行开源操作系统软件,这样的操作系统数量并不多。ARM及其合作伙伴已经工作数月,来扩展Linux和相关工具对64位ARM的支持。在Linux上的工作包括相同文件系统同时支持32位和64位的应用程序。这也是一个可以实现的任务,因为大部分情况下的操作系统已经迁移到64位体系结构上了;所以迁移到64位ARMv8也没什么风险。这样一来,绝大部分生态软件不需要修改。新的64位操作系统能够轻易高效地支持现存32位应用程序。另外,这样还能清晰地解决地址映射冲突问题和物理RAM限制问题。
如果应用对性能有要求,需要访问更大地址范围的RAM,或者需要获得更高效地执行,那么可以重新编译应用程序,如果有必要的话,可能需要将源代码移植到A64的指令集上。具体采用什么方案,还要看市场需求。
结束语
ARM为什么认为64位计算是趋势呢?下面我们从几个时间周期的角度来分析。从体系结构更新的时间周期来看,从某款芯片开始支持一个体系结构到符合该体系结构的最后一款设备之间,也就几年时间。在开源世界里,从Linux开始支持,到相关代码提交,最终进入生态圈,也需要花费几年时间。还存在设备开始生产制造到软件可用的过程,因此在芯片产品化之前就要将ARMv8体系结构公开并启动软件的移植工作。我们一边持续地做非常坚实的基础工作,包括制定规范,创建工具和模型,以及开展操作系统移植等;我们会有选择地公开新代码,或者提供新代码预览通道。然而,对于一些感兴趣的议题,我们会提供规范文档的预览通道,这样就能就技术进行公开讨论,我们也会回答讨论中的问题。
除非您是操作系统厂商或者虚拟机监控器软件厂商,现在你只需要考虑你们未来是否需要64位计算,其他的都不需要考虑。
当前,基于ARMv8体系结构研发处理器的工作主要是ARM及其关键伙伴来完成。面向各种市场领域,一些是新伙伴,一些是老伙伴;但一件事非常确定,未来不断向前发展,有了ARM您就拥有了任何技术中最大的支持和生态系统,随时可以支持任何需要的变革。