Python爬虫理论 | (7) 进阶反反爬虫技术 --- 搭建IP代理池、Cookies池
目录
1. 代理的使用
2. 搭建IP代理池
3. 模拟登陆
1. 代理的使用
服务器会检测某个IP在单位时间内的请求次数,如果超过了某个阈值,那么服务器会直接拒绝服务,返回一些错误信息。这种情况可以称为封IP,于是网站就成功把爬虫禁掉了。
绕过IP限制 反爬虫:借助代理方式来伪装IP,让服务器无法识别由我们本机发起的请求,这样就可以成功防止封IP。
- 常用免费代理网址
http://www.ip3366.net/free/
https://www.kuaidaili.com/free/
https://www.xicidaili.com/nn/
上述网站由很多免费的IP,可以供使用,不过效果可能不太好,有的IP可以,有的则不行;也可以尝试购买一些高校代理。
- 代理的使用 --- requests
import requests
proxy = '122.193.244.22:9999'
proxies = {
'http':'http://'+proxy,
'https':'https://'+proxy
}
response = requests.get('http://httpbin.org/get',proxies=proxies)
print(response.text)1) 不使用IP代理
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)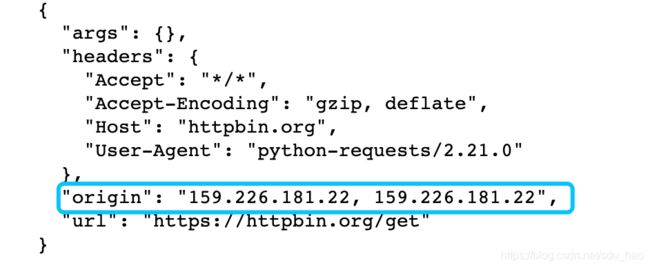
当前的origin就是本机的IP,如果频繁用本机的IP来爬取数据,就会被服务器封掉。
2) 使用IP代理
import requests
proxy = '60.167.75.175:8118' #从代理网站上找的
proxies = {
'http':'http://'+proxy,
'https':'https://'+proxy
}
response = requests.get('http://httpbin.org/get',proxies=proxies)
print(response.text)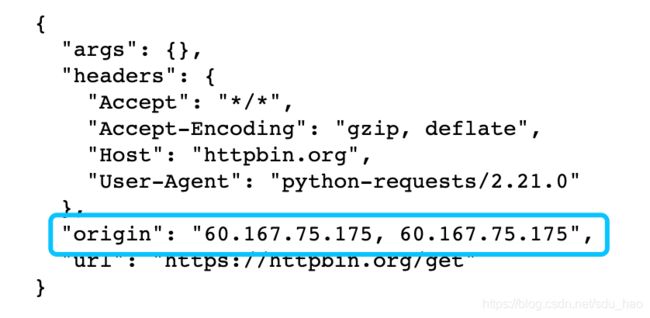
当前的origin就是我们使用的代理IP。
- 代理的使用 --- selenium
from selenium import webdriver
proxy = '122.193.244.22:9999'
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=http://' + proxy)
browser = webdriver.Chrome(options=options)
browser.get('http://httpbin.org/get')
1)不使用IP代理
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://httpbin.org/get')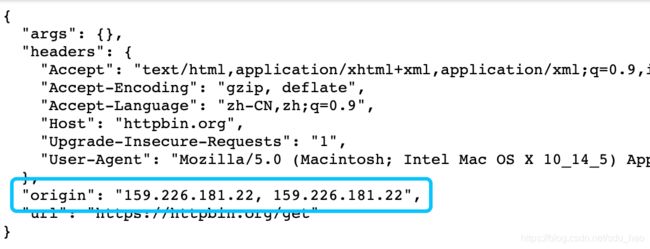
此时显示为本机IP。
2)使用IP代理
from selenium import webdriver
proxy = '60.167.75.175:8118' #从代理网站上找的
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=http://' + proxy)
browser = webdriver.Chrome(options=options)
browser.get('http://httpbin.org/get')
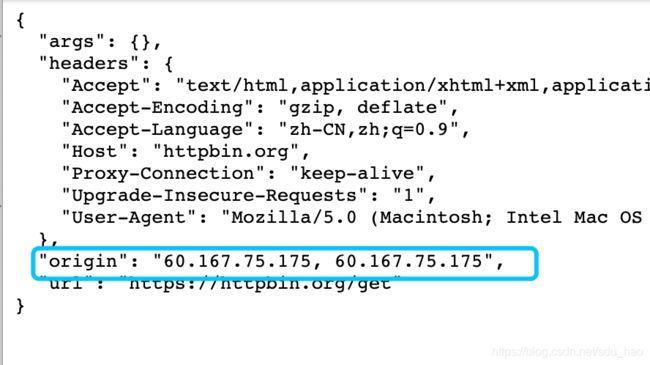
此时显示为代理IP。
2. 搭建IP代理池
基本模块分为4 块:存储模块、获取模块、检测模块、接口模块。
存储模块: 负责存储代理IP。
获取模块: 定时在各大代理网站抓取代理IP,并保存到数据库中。
检测模块: 定时检测数据库中的代理IP,判断能否正常访问网页。
接口模块: 提供代理IP的接口。
- 存储模块
负责存储抓取下来的代理。
首先要保证代理不重复, 要标识代理的可用情况(给代理IP一个分值),还要动态实时处理每个代理,所以一种比较高效和方便的存储方式就是使用Redis 的有序集合。
Redis:REmoteDIctionaryServer是一个基于内存的高效的key-value形式的非关系型数据库,支持存储多种数据结构:字符串(String), 哈希(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
需要安装redis数据库服务和可视化管理工具,可根据系统配置自行百度安装。
实例:
Python操作redis数据库:
from redis import StrictRedis
db = StrictRedis(host='localhost', port=6379, db=0, password=None) #创建数据库
db.set('name', 'Bob') #增加一个key:value
print(db.get('name')) #输出key为‘name’的值
- 获取模块
定时在各大代理网站抓取代理IP,并保存到数据库中。
代理可以是免费公开代理也可以是付费代理,付费代理会更加稳定。代理的形式都是IP 加端口,此模块尽量从不同来源获取,尽量抓取高匿代理。
- 检测模块
定时检测数据库中的代理,判断能否正常访问网页。
设置一个检测链接,通常爬取哪个网站就检测哪个网站,这样更有针对性,如果要做一个通用型的代理,那可以设置百度等链接用于检测。
需标识每一个代理的状态,为其设置分数标识,初始值为10。以100 分为最高值,代表可用,分数越少代表越不可用。检测一次,如果代理可用,可以将分数标识设置为100 分;如果代理不可用,将分数标识减1分,当分数减到一定阈值(如0)后删除该代理。
- 接口模块
提供代理IP的接口。
如果直接连接数据库获取对应的数据,就需要知道数据库的连接信息,并且要配置连接,比较安全和方便的方式是提供一个Web API 接口,通过访问接口拿到可用代理。
另外,需要随机返回某个代理,获取排名中最高分数(100分)的代理,若存在多个,从中随机选取一个;否则随机返回一个代理。
实战:
将四个模块分别实现,以完成IP代理池的搭建。IP代理池是通用的,创建好后,可供多个爬虫任务共同使用。
完整项目
3. 模拟登陆
服务器根据Cookies 判断出对应的SessionID,进而找到会话。如果当前会话是有效的,那么服务器就判断用户当前已经登录,返回请求的页面信息。
模拟登录:通过修改cookie实现登录。
- 模拟登陆 --- requests
import requests
headers = {
'User-Agent': '……',
'cookie': '.......'
}
response = requests.get('https://www.zhihu.com/', headers=headers)
print(response.text)
- 模拟登陆 --- selenium
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.weibo.com')
cookies = [{'domain': '.weibo.com', 'httpOnly': False, 'name': 'login_sid_t', 'path': '/', 'secure': False, 'value': 'b10509d8eeeb7792842fc48dbe473ec6'}, .......]
for cookie in cookies:
browser.add_cookie(cookie)
browser.get('https://www.weibo.com')
有些网站必须登陆后才能访问,如知乎、微博等。所以我们要使用用户名和密码产生的cookies来进行登陆。但是一个用户名和密码用的时间长了也会被封,所以我们需要搭建一个cookies池,使用多个用户名和密码。
4. 搭建cookies池
基本模块分为4 块:存储模块、生成模块、检测模块和接口模块。
存储模块:负责存储每个账号的用户名密码以及每个账号对应的Cookies 信息。
生成模块:负责生成新的Cookies 。此模块会从存储模块逐个拿取账号的用户名和密码, 然后模拟登录目标页面,判断登录成功,就将Cookies返回并交给存储模块存储。
检测模块:定时检测数据库中的Cookies 。
接口模块:提供对外服务的接口。
账号可以自己收集也可以购买,cookies可以自己生成也可以购买。
与IP代理池不同,Cookies池具有针对性,如果你爬微博就要构建一个微博cookies池,爬知乎就需要构建一个知乎cookies池;而IP代理池是通用的,可供不同的爬虫任务共同使用。
实战:
1)将四个模块分别实现,以完成新浪微博cookies池的搭建。
2)搭建知乎的cookies池