Actor-Critic 跑 CartPole-v1
gym-0.26.1
CartPole-v1
Actor-Critic
这里采用 时序差分残差
ψ t = r t + γ V π θ ( s t + 1 ) − V π θ ( s t ) \psi_t = r_t + \gamma V_{\pi _ \theta} (s_{t+1}) - V_{\pi _ \theta}({s_t}) ψt=rt+γVπθ(st+1)−Vπθ(st)
详细请参考 动手学强化学习
简单来说就是reforce是采用蒙特卡洛搜索方法来估计Q(s,a),然后这里先是把状态价值函数V作为基线, 然后利用Q = r + gamma * V得到上式。
代码如下
import gym
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
import matplotlib.pyplot as plt
from d2l import torch as d2l
import rl_utils
from tqdm import tqdm
class PolicyNet(nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super().__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, action_dim)
def forward(self, X):
X = F.relu(self.fc1(X))
return F.softmax(self.fc2(X), dim=1)
class ValueNet(nn.Module):
def __init__(self, state_dim, hidden_dim):
super().__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 1)
def forward(self, X):
X = F.relu(self.fc1(X))
return self.fc2(X)
class ActorCritic:
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma, device):
# 策略网络
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
# 价值网络
self.critic = ValueNet(state_dim, hidden_dim).to(device)
# 策略网络优化器
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr = actor_lr)
#价值网络优化器
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr = critic_lr)
self.gamma = gamma
self.device = device
def take_action(self, state):
state = torch.tensor(np.array([state]), dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).reshape(-1,1).to(self.device)
rewards = torch.tensor(transition_dict['rewards']).reshape(-1,1).to(device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).reshape(-1,1).to(self.device)
# 时分差分目标
td_target = rewards + self.gamma * self.critic(next_states) * (1- dones)
# 时分差序目标
td_delta = td_target - self.critic(states)
log_probs = torch.log(self.actor(states).gather(1, actions))
actor_loss = torch.mean(-log_probs * td_delta.detach())
# 均方误差
critic_loss= torch.mean(F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
# 计算策略网络的梯度
actor_loss.backward()
# 计算价值网络的梯度
critic_loss.backward()
# 更新策略网络梯度
self.actor_optimizer.step()
# 跟新价值网络梯度
self.critic_optimizer.step()
def train(env, agent, num_episodes):
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes/10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes/10)):
episode_return = 0
transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}
state = env.reset()[0]
done ,truncated = False, False
while not done and not truncated:
action = agent.take_action(state)
next_state, reward, done, truncated, info = env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
return_list.append(episode_return)
agent.update(transition_dict)
if (i_episode+1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes/10 * i + i_episode+1), 'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
return return_list
actor_lr = 1e-3
critic_lr = 1e-2
num_episodes = 1000
hidden_dim = 128
gamma = 0.98
device = d2l.try_gpu()
env_name = 'CartPole-v1'
env = gym.make(env_name)
torch.manual_seed(0)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = ActorCritic(state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma, device)
return_list = train(env, agent, num_episodes)
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Return')
plt.title(f'Actor-Critic on {env_name}')
plt.show()
mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Return')
plt.title(f'Actor-Critic on {env_name}')
plt.show()
jupyter运行结果如下

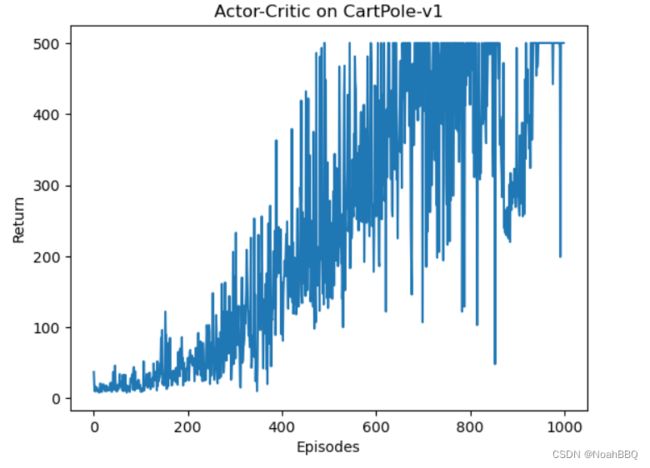
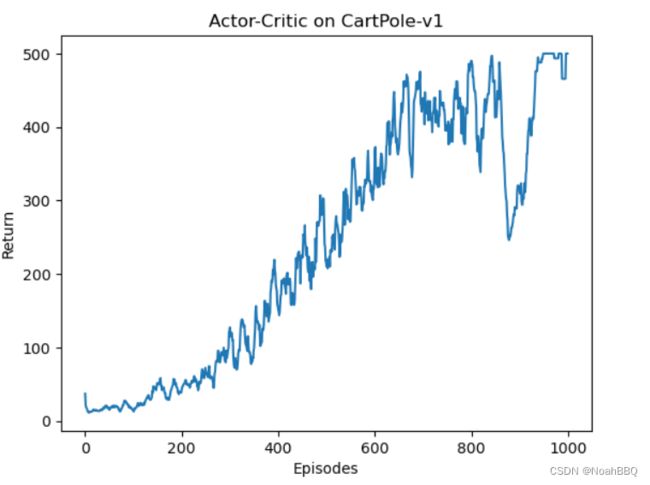
比reforce学习更加稳定,而且总体return也要高一些。