ZB级的大数据探索与应用实践【附PPT】
据报告显示到2025年,全球将产生180ZB的数据。这些海量的数据正是企业进行数字化转型的核心生产因素,然而真正被有效存储、使用和分析的数据不到百分之十。如何从ZB级的数据中寻找分析有价值的信息并回馈到业务发展才是关键。11月30日UCan技术沙龙大数据专场(北京站)邀请了5位资深大数据技术专家分享他们对大数据的探索和应用实践。
大数据业务常态化的处理手段与架构衍变
很多开发人员在解决实际的业务问题时,经常会面临如何选择大数据框架的困惑。比如有十亿条数据需要进行聚合操作,是把数据放在HBase+Phoenix还是Kudu+Impala或是Spark上进行呢?到底哪种方案才能够达到降低开发运营成本且性能足够高的效果呢? UCloud大数据工程师刘景泽分享了他的思考。
要想对数据进行分析决策,首先要有数据来源,其次要将采集到的数据进行存储,然后把这些数据进行汇总、聚合、计算,最后反馈到数据应用层。目前市面上主流的大数据框架有几百种,总结下来主要分为数据采集层、数据存储层、数据计算层和数据应用层。除此之外,一套完整的大数据技术栈还包括了任务调度、集群监控、权限管理和元数据管理。

面对数量众多、种类繁杂的技术栈,选择的自由度很高,但前提是不能把强依赖的框架给拆分开。这里刘景泽给出了一个通用型架构如下图所示:

图中左边OLTP SDK指的是后台接口,可以调用很多大数据的服务。从接口或者从Flume采集到的数据,直接送到Kafka,然后送到ES,再通过ES进行建模。整个过程相当于只使用了ELK这套系统,虽然很简单,但这也是一个大数据框架。对于数据量比较大、业务范围比较广的公司,往往要求原始数据要做冷备留存,这时HDFS就可以作为一个数据冷备的集群,HDFS + Hive作为冷备也是非常常见的方案。
当业务规模发展到足够大的时候,需要进行一些聚合操作,如果从单独的一个框架拉出来的数据是不完整的,可能需要多个框架同时操作然后进行join,这样操作的效率非常低。要解决这个问题,可以用大宽表的思路:第一步先把业务数据存放在MySQL或者HBase里面。然后通过Spark或Flink,从MySQL或 HBase里面通过异步IO的方式把所需要的维度数据拿出来进行join,join好的数据可以存在HBase中。到这一层的时候,所有的数据维度已经非常完整了。当进行一个重要指标分析的时候,我们只需要从HBase里面拿数据就可以了。对于业务不是非常重的指标可以直接通过Phoenix或者HBase、Impala和Trafodion对接业务需求,把想要的结果输出。
再往后发展,如果业务还是异常繁重,数据处理不过来,我们就可以把明细数据层HBase里面的数据拿出来,放到Spark和 Flink这两个流计算框架中进行预聚合,然后对接到OLTP系统,提供后台服务。
可见,大数据技术栈的选择并没有统一的标准,不同业务场景需要不同的处理方式。正如刘景泽所说:“在很多场景里面,我们面对框架的时候要一以贯之,发现它真正的自由度在哪里?而不要被它们所局限了。”
存储计算分离与数据抽象实践
大数据诞生的初期,很多公司的大数据集群是由一个庞大的Cluster阵列组成,里面包括很多台服务器,也就是集群的计算能力和存储能力分布在一个数据中心。这是由于当时的网络条件较差,导致任务处理中的数据传输开销非常大,而本地磁盘比网络传输更快,因此当时的主要理念就是要以数据为中心做计算,为的是减少数据的迁移,提高计算效率,这里最典型的代表就是MapReduce。
实际上,这种”资源池”方案不能同时充分利用存储和计算资源,造成了大量浪费,还面临着各种组件升级困难、无法区别对待不同数据、定位问题困难、临时调配资源困难等一系列问题。随着网络速度的大幅提升、内存和磁盘的大规模扩容、大数据软件的迭代更新,之前的存储+计算集群的方案该如何改进呢?BLUECITY 大数据总监刘宝亮提出了存储计算分离架构,如下图所示:

要实现存储计算分离,首先存储计算要分开,同时存储内部要分离,计算内部也要分离。存储集群是该架构的核心,因为大数据最重要的就是数据;计算集群是这个架构的灵魂,因为一切的灵活性都是由计算集群带来的。此外,无阻塞网络是此架构最重要的依赖,因为一旦出现网络问题,存储集群的读取和写入操作就不能持平。说到存储计算分离的优点,刘宝亮特别强调了“弹性”,这是由于多集群的软硬件升级更容易、数据可分级对待、可临时创建新集群应对紧急问题等等都更加灵活,从而进一步提升了计算速度。
数据驱动——从方法到实践
所谓数据驱动,就是通过各种技术手段采集海量数据,并进行汇总形成信息,之后对相关的信息进行整合分析并形成决策指导。在这里神策联合创始人&首席架构师付力力将整个数据驱动的环节总结为四步,分别是数据采集、数据建模、数据分析、数据反馈,并且这四个环节要形成闭环,也就是数据反馈最终要回归到数据采集。
数据采集是一切数据应用的根基,可以通过客户端、业务端、第三方数据、线下数据四个方面进行采集,无论以何种方式进行,建议在内部做技术架构设计的时候,要设定统一的数据接入API,通过SDK或服务端的数据采集工具将数据做统一处理接收,方便后续的数据建模。

第二步是数据建模,一个基础的数据模型分为三部分:事件、用户、实体,在此之上,还可以做用户分群,例如根据用户的年龄、性别、省份、手机设备等属性进行划分。数据建模的过程中有一个难点就是ETL,在多数据源采集的情况下,很难找到直接可用的 ETL 产品,因此我们可以搭建好调度、计算框架、质量管理和元数据管理等通用工作,尽量把数据的源头建设好,从而降低运营成本。
第三步数据分析,这里有两种非常典型的思路:一种是通过例行的报表满足基本的指标获取需求,如果是临时性的需求就要通过新的开发解决;另一种是使用抽象的模型覆盖指标体系以及大部分分析需求,通过友好的交互让需要数据的人自主获取数据。后者的灵活性远远大于前者,而数据分析对灵活性的要求会远大于对响应时间的要求。除此之外,数据的可解释性以及整体架构的简洁性也是非常重要的考量因素。
数字时代业务风控的挑战与机遇
企业的业务、营销、生态、数据等正面临日益严重的黑产威胁,面对黑产链条完备、分工明确的形势,现有的风控方案面临着哪些挑战?
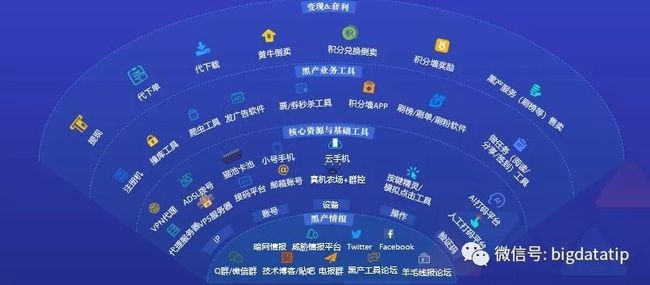
数美科技CTO梁堃归纳了三点:第一,防御能力单薄,依赖黑名单、依赖简单人工规则、单点防御(SDK、验证码);第二,防御时效性差,依赖T+1离线挖掘、策略生效周期长;第三,防御进化慢,缺乏策略迭代闭环、无自学习机制。那么如何改善以上这些问题并建立完整的风控体系呢?
梁堃认为一个全栈式风控体系应该包括布控体系、策略体系、画像体系和运营体系。在布控体系上,我们可以增加设备风险SDK、增加登录注册保护、 提供业务行为保护。在策略体系上,可以对虚拟机设备农场等风险设备、对机器注册撞库攻击等风险操作、对欺诈团伙高危群体进行识别检测等。画像体系可以在多个场景进行数据打通,多行业联防联控,共同对抗黑产。运营体系可通过案例分析、攻防研究、策略的设计、研发、验证、上线、运营等环节形成完整的闭环进行运转,这样才能保证风控一直有效。
这些体系跑在什么样的架构上呢?首先风控系统要跟业务系统解耦,这样业务规则随时升级变化不会影响风控,风控规则的变化不会影响业务。另外一个风控平台结构需要包括多场景策略体系、实时风控平台和风险画像网络,如下图所示:

最后,这整个风控平台的架构是运行在云服务基础设施上的7个全球服务集群,每日请求量达30亿,峰值QPS高达10万+。该架构可分为接入层、策略引擎层、模型引擎层和存储层,通过负载均衡管理每一层的节点,实现动态的横向扩展。
Spark在MobTech应用实操分享
MobTech作为全球领先的数据智能科技平台,目前累计覆盖设备量有120亿,服务开发者32万,累计接入APP数量达50万,庞大的数据量也给MobTech带来了诸多挑战,例如运行的Yarn/Spark任务多、数据体量大、资源开销大、运算时间较长等。
在Mob有大量复杂的任务,业务需求促使其将部分慢任务、Hive任务迁移到Spark上面,取得性能的提升,同时还对一些Spark任务进行优化。MobTech大数据技术架构师张峻滔围绕复杂的Spark使用分享了两个案例:第一个是Spark动态裁减在MobTech的应用。
所谓动态分区裁剪,就是基于运行时(run time)推断出来的信息来进一步进行分区裁剪。假设A表有20亿数据,B表有1000万数据,然后把A表和B表join起来,怎么才能过滤掉A表中无用的数据,这里我们引入了bloomfilter。它的主要特性就是节省空间,如果bloomfilter判断key不存在,那么就一定不存在;如果bloomfilter判断key存在,那么可能存在,也可能不存在。简而言之,这是一种牺牲精度来换取空间的数据结构。Bloomfilter在MobTech具体应用实现如下图所示:

其逻辑SQL如下:
SELECT /*+ bloomfilter(b.id) */
a.*,b.*
FROM a join b on a.id = b.id
第二个案例是Spark在千亿级别数据上的检索与计算。MobTech有4000多个标签需要历史回溯,且回溯时间周期长达2年,回溯频次很低,面对这样的冷数据,如何在资源开销比较小的情况下完成业务检索要求?由于数据分布太散, 4000多标签分布在各个不同的表里面(横向), 历史数据又分布在日表里面(纵向),间接造成搜索要在千亿的数据中进行查找。这里,建立索引的思路有两个:
横向数据整合: 将4000多个标签的日数据索引整合到一个表里面;
纵向数据整合: 将日数据进行周级别/月级别整合。
横向整合的日表数据还是太大, 于是决定将日期和数据ID整合做出一个索引表,来加快日表的查询,确保能直接通过ID定位到具体在事实表中的哪个文件,哪一行有该ID的信息。日表的数据通过Spark RDD的API 获取ID,ORC文件名,行号的信息, 生成增量索引;增量索引通过UDAF合并入全量索引。具体方案如下:

![]()
由于篇幅有限,更多精彩技术内容敬请关注浪尖,并回复“大数据”即可获取讲师PPT~