CUDA初识(二)
第一章 CUDA初识(一)
第二章 CUDA初识(二)
文章目录
- 一、nvcc
-
- 1.1 nvcc是什么
- 1.2 nvcc工作流程
- 1.3 nvcc参数格式
- 二、CUDA内核函数
-
- 1.内核函数
- 2.HelloWorld内核
-
- 2.1内核函数限制条件
- 2.2 内核函数执行
- 2.1 索引定义
- 总结
接上节CUDA初识(一)
一、nvcc
1.1 nvcc是什么
nvcc(NVIDIA CUDA Compiler)本质上是编译器驱动程序(compiler driver),它根据传入命令参数执行一系列命令工具,完成对程序编译的各个阶段。它可以将CUDA C/C++代码编译为GPU可执行文件,使得程序能够在NVIDIA GPU上并行运行。
CUDA内核代码可以使用ISA(CUDA instruction set architecture,也叫PTX),或者扩展的C语言编写。nvcc将PTX或C语言编写的代码编译为可执行程序。
1.2 nvcc工作流程
CUDA程序默认编译模式为全编译模式(whole program compilation mode)
- 分离源文件中与GPU相关的内核代码,并将其编译为cubin或者PTX中间文件,并保存在fatbinary嵌入其中
- 分离源文件中与主机相关代码,使用系统中可用的编译器进行编译,并将fatbinary嵌入其中
- 程序链接时,相关的CUDA运行库(runtime library)会被链接,最后产生可执行程序
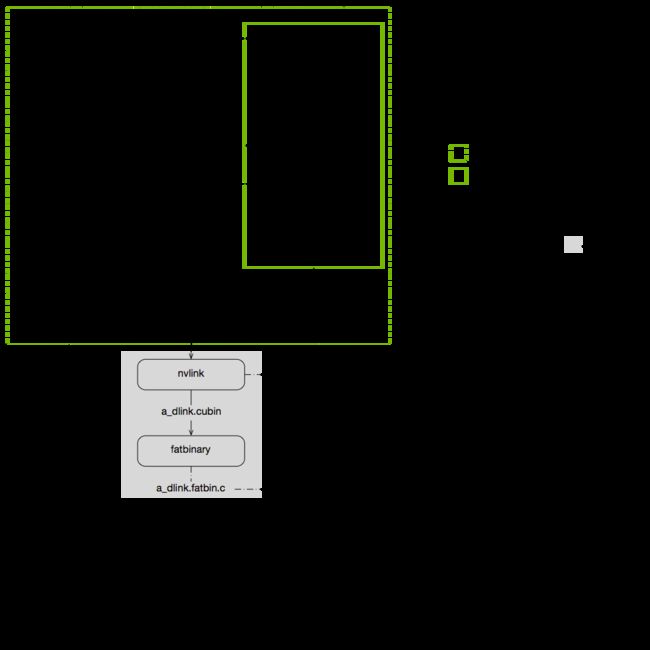
左边是Host 右边是Device,各种编译出.o/.obj 和 .fatbin.c,再进行链接,然后再产生可执行文件
1.3 nvcc参数格式
nvcc参数分为长名参数(用–标识:–include-path)、短名参数(用-标识:-i)。长名参数通常用于脚本中,短名参数通常用于交互式命令(命令行)中
nvcc参数
{ 布尔参数 单值参数 列表参数 \left\{ \begin{array}{c} 布尔参数 \\ 单值参数 \\ 列表参数\end{array}\right. ⎩ ⎨ ⎧布尔参数单值参数列表参数
具体参数使用方法见官方文档4.2节,官方文档链接
二、CUDA内核函数
1.内核函数
内核函数(kernel function)被GPU上线程并发执行
- 内核函数定义
- __ global__ void kernel_name(argument list) 返回值为空
函数修饰符有三种
| 函数修饰符 | 描述 |
|---|---|
| __ global__ | 在device上执行,在host或device上调用 |
| __device __ | 在device上执行,只device上调用 |
| __ host__ | 在host上执行,只host上调用 |
2.HelloWorld内核
2.1内核函数限制条件
- 只能访问GPU内存
- 必须返回void
- 不能使用变成函数
- 不能使用静态变量
- 不能使用函数指针
- 内核函数具有异步性
2.2 内核函数执行
-
设置GPU线程 { 内核执行配置 : < < < g r i d , b l o c k > > > 设置线程总数和线程布局 \left\{ \begin{array}{l} 内核执行配置:<<
-
内核调用
kernel_name << -
释放所有与当前进程相关的GPU资源
cudaDeviceReset
#helloFromGPU.cu文件
#include 使用<<<1,10>>>语法将helloFromGPU函数指定为GPU并行执行的内核函数。这将在一个GPU线程块中执行10次helloFromGPU函数。grid里面包含一个block,一个block里面包含10个Thead。
使用vscode编译器,注意需要提前安装Visual Studio,并且配置好路径。如果出现vs2019:nvcc fatal : Cannot find compiler ‘cl.exe‘ in PATH错误
解决方法:C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin\Hostx64\x64 添加至系统环境,重启即可。
2.1 索引定义
CUDA平台线程索引包含blockIdx和threadIdx.通过线程索引可以为线程分配数据,线程维度包含网格的维度gridDim和块维度blockDim.

(该图片引用自白老师的Tensort部署课程) 解析如下:
若向量大小为1<<20,即(10~10^20),而blcok大小为256,那么grid大小为4096,上图即为kernel的线程层级结构。
-
一个线程需要两个内置坐标向量(blockIdx,threadIdx)来唯一标识,他们都是dim3类型变量,其中,blockIdx指明线程所在grid的位置,thread指明线程所在block中的位置。
-
对于一个2-dim的block(Dx,Dy),线程(x,y)的ID值为(x+yDx),如果是3-dim的block(Dx,Dy,Dz),线程(x,y,z)的ID值为(x+yDx+zDxDy)。
-
不是block越大越好,而是要适当选择。目前GPU可达到1024threads/block。
-
gridDim表示一个grid中包含多少个block,gridDim.x表示横向block数量,gridDim.y表示纵向block数量。
-
blockDim表示一个block中包含多少个线程,blockDim.x表示横向thread数量,blockDim.y表示纵向thread数量。
#include "common/common.h"
#include 总结
承接第一章,后续将继续补充。
参考链接:白老师TensorRT实战部署