导览
正则表达式模式
^:锚定行首
$:锚定行尾
.:特殊字符点号用来匹配换行符之外的任意单个字符,至少一个字符。
[]:字符组,配置方括号内的字符或数字,[ch],[Yy]
[^]:不包含字符组内的字符,[^ch]
区间:[c-h],[0-9]匹配c到h之间的单词特殊字符组:
[[:alpha:]]匹配任意字母字符,不管是大写还是小写
[[:alnum:]]匹配任意字母数字字符0~9、 AZ或az
[[:blank:]]匹配空格或制表符
[[:digit:]]匹配0~9之间的数字
[[:lower:]]匹配小写字母字符a~z
[[:print:]]匹配任意可打印字符
[[:punct:]]匹配标点符号
[[:space:]]匹配任意空白字符:空格、制表符、 NL、 FF、 VT和CR
[[:upper:]]匹配任意大写字母字符A~Z
*:匹配模式的文本中出现0次或多次扩展的正则表达式(gawk)
?:匹配前面的字符出现0次或1次
+:配置前面的字符出现1次或多次
{m}:配置至少出现m次
{,n}:配置至多出现n次
{m,n}:配置至少m次,至多n次
|用逻辑OR方式指定正则表达式引擎要用的两个或多个模式。
():表达式分组,正则表达式模式也可以用圆括号进行分组。当你将正则表达式模式分组时,该组会被视为一个标准字符。可以像对普通字符一样给该组使用特殊字符
--re- interval默认情况下, gawk程序不会识别正则表达式间隔。必须指定gawk程序的--re- interval命令行选项才能识别正则表达式间隔。
20.1 什么是正则表达式
20.1.1 定义
正则表达式是你定义的、Linux工具用来过滤文本的模式模板。正则表达式模式利用通配符来代表数据流中的一个或者多个字符
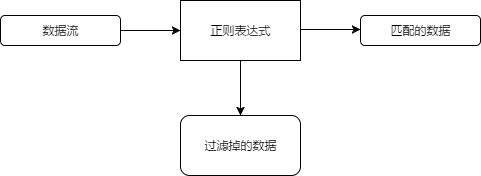
20.1.2 正则表达式类型
在Linux中,有两种流行的正则表达式引擎:
- POSIX基础正则表达式(BRE)引擎
sed - POSIX扩展正则表达式(ERE)引擎
gawk
20.2 定于BRE模式
20.2.1 纯文本
[ttxie@41 ~]$ echo "This is a test" |sed -n '/test/p'
This is a test
[ttxie@41 ~]$ echo "This is a test" |sed -n '/trial/p'
[ttxie@41 ~]$ echo "This is a test" |awk '/test/{print $0}'
This is a test
[ttxie@41 ~]$ echo "This is a test" |awk '/trial/{print $0}'
正则表达式并不关心模式在数据流中的位置,也不关心出现了多少次,只要匹配了就会将该字符串传会linux工具。
正则表达式模式区分大小写。
[ttxie@41 ~]$ echo "This is a test" |sed -n '/this/p'
[ttxie@41 ~]$ echo "This is a test" |sed -n '/This/p'
This is a test
模糊匹配
只要定义的文本出现在数据流中,正则就能匹配,反之则不成立
[ttxie@41 ~]$ echo "The books are expensive" |sed -n '/book/p'
The books are expensive
[ttxie@41 ~]$ echo "The book are expensive" |sed -n '/books/p'
20.2.2 特殊字符
正则表达式识别的特殊字符包括:.*[]^${}\+?|(),如果要用某个特殊字符作为文本字符,就必须转义。在前面加上反斜线\。
[ttxie@41 ~]$ echo "This cost is \$200" |sed -n '/\$/p'
This cost is $200
要使用正斜线也需要用转义字符
[ttxie@41 ~]$ echo "3 / 2" |sed '/\//p'
3 / 2
20.2.3 锚字符 ^ $
默认情况下,模式出现再数据流中的任何地方,它就能匹配。
有两个特殊字符可以用来将模式锁定在数据流中的行首或行尾。
20.2.3.1.锁定在行首(脱字符 ^)
^ 定义从数据流中文本行的行首开始的模式。如果模式出现在行首之外的位置,正则表达式模式则无法匹配。
需要用^,就必须将它放在正则表达式中指定的模式前面。
[ttxie@41 ~]$ echo "The book store" |sed -n '/^book/p'
[ttxie@41 ~]$ echo "Books are great" |sed -n '/^Book/p'
Books are great
还可以输入文件:
$sed -n ‘/^this/p’ data.txt
data.txt 中以this开头的行就能找出来。
注意如果将^放到模式开头之外的其他位置,那么就跟普通字符一样了。
[ttxie@41 ~]$ echo "This is ^ test" |sed -n '/s ^/p'
This is ^ test
注意:
如果指定正则表达式模式时只用了脱字符,就不需要用反斜线来转义。
如果你在模式中先指定了脱字符,随后还有一些其他文本,那么你必须在脱字符前用转义字符。
20.2.3.2. 锁定在行尾
用美元符$
[ttxie@41 ~]$ echo "This is a good book" |sed -n '/book$/p'
This is a good book
[ttxie@41 ~]$ echo "This is a good book" |sed -n '/good$/p'
[ttxie@41 ~]$ echo "This is a good book" |sed -n '/books$/p'
要想匹配,文本模式必须是行的最后一部分。
20.2.3.3. 组合锚点
比如想到匹配指定内容
$sed ‘/^this is test line$/p’ data.txt匹配行 this is test line将两个锚点直接组合在一起,之间不加任何东西,这样就过滤出数据流中的空白行。
$sed -n ‘/^$/p’ data.txt 这样可以把data.txt 中的空白行过滤出来。
- 过滤掉空白行
[ttxie@41 part20]$ cat data5.txt
This is one line
this is another line
[ttxie@41 part20]$ sed '/^$/d' data5.txt
This is one line
this is another line
20.2.4 点号字符 .
用来匹配除换行符之外的任意单个字符。它必须匹配一个字符,如果点字符的位置没有字符那么模式就不成立。
[ttxie@41 part20]$ cat data6.txt
this is a test line
the cat is sleeping
that is a very nice hat
this test is at line four
at ten o'clock we'll go home
[ttxie@41 part20]$ sed -n '/.at/p' data6.txt
the cat is sleeping
that is a very nice hat
this test is at line four
第4行空格也算一个字符。注意第5行没有匹配到。at前面没有字符了。
20.2.5 字符组 []
可以限定待匹配的具体字符,在正则表达式中,这称为字符组。用[]括起来
[ttxie@41 part20]$ cat data6.txt
this is a test line
the cat is sleeping
that is a very nice hat
this test is at line four
at ten o'clock we'll go home
[ttxie@41 part20]$ sed -n '/[ch]at/p' data6.txt
the cat is sleeping
that is a very nice hat
相当于只匹配cat 或者 hat。其他的at就不匹配了。
在不确定大小写的时候,字符组会非常有用:
[ttxie@41 part20]$ echo "yes" |sed -n '/[Yy]es/p'
yes
[ttxie@41 part20]$ echo "Yes" |sed -n '/[Yy]es/p'
Yes
还可以用多个字符组:
[ttxie@41 part20]$ echo "Yes" |sed -n '/[Yy][Ee][Ss]/p'
Yes
[ttxie@41 part20]$ echo "yEs" |sed -n '/[Yy][Ee][Ss]/p'
yEs
[ttxie@41 part20]$ echo "yES" |sed -n '/[Yy][Ee][Ss]/p'
yES
这样就相当于可以限制行的字符个数和区间了
20.2.6 排除型字符组
相当于字符组取反,可以寻找字符组中没有的字符。在前面加个脱字符就好了。
[ttxie@41 part20]$ cat data6.txt
this is a test line
the cat is sleeping
that is a very nice hat
this test is at line four
at ten o'clock we'll go home
[ttxie@41 part20]$ sed -n '/[^ch]at/p' data6.txt
this test is at line four
匹配出c和h以外的字符。由于空格字符属于这个范畴,所以它通过了模式匹配,但即使是排除,字符组必须匹配一个字符,所以以at为开头的行仍然未能通过匹配。
20.2.7 区间
- 0 – 9,可以直接这么写[0-9] 而不需要[0123456789]
[ttxie@41 part20]$ cat data_num.txt
60633
46201
223001
4353
22203
[ttxie@41 part20]$ sed -n '/[0-9][0-9][0-9][0-9][0-9]/p' data_num.txt
60633
46201
223001
22203
[ttxie@41 part20]$ sed -n '/^[0-9][0-9][0-9][0-9][0-9]$/p' data_num.txt
60633
46201
22203
第一种:它成功过滤掉了过短的数字,但是因为最后一个字符组没有字符可匹配,它也通过了6位数字的;
第二种:指明它的行首和行尾,可以确保只匹配五位数。
- 字母也可以
匹配c到h这个区间的字符。
[ttxie@41 part20]$ cat data6.txt
this is a test line
the cat is sleeping
that is a very nice hat
this test is at line four
at ten o'clock we'll go home
[ttxie@41 part20]$ sed -n '/[c-h]at/p' data6.txt
the cat is sleeping
that is a very nice hat
还可以指定多个不连续的区间:指定 a-c 和 h-m区间的字母
[ttxie@41 part20]$ sed -n '/[a-ch-m]at/p' data6.txt
the cat is sleeping
that is a very nice hat
20.2.8 特殊的字符组
除了自定义的区间(比如[0-9] [a-f])之外,BRE还包含了一些特殊的字符组。见下表
使用:
[ttxie@41 part20]$ echo "abc" |sed -n '/[[:digit:]]/p'
[ttxie@41 part20]$ echo "abc" |sed -n '/[[:alpha:]]/p'
abc
[ttxie@41 part20]$ echo "abc123" |sed -n '/[[:digit:]]/p'
abc123
[ttxie@41 part20]$ echo "This is , a test" |sed -n '/[[:punct:]]/p'
This is , a test
20.2.9 星号 *
在字符后面放置星号用来表明该字符必须在匹配模式的文本中出现0次或多次。
[ttxie@41 part20]$ echo "ik" |sed -n '/ie*k/p' ##出现0次
ik
[ttxie@41 part20]$ echo "iek" |sed -n '/ie*k/p'
iek
[ttxie@41 part20]$ echo "ieek" |sed -n '/ie*k/p'
ieek
*还能用到字符组上,它允许指定可能在文本中出现多次的字符组或区间:
[ttxie@41 part20]$ echo "bt" |sed -n '/b[ae]*t/p'
bt
[ttxie@41 part20]$ echo "bat" |sed -n '/b[ae]*t/p'
bat
[ttxie@41 part20]$ echo "bet" |sed -n '/b[ae]*t/p'
bet
[ttxie@41 part20]$ echo "btt" |sed -n '/b[ae]*t/p'
btt
[ttxie@41 part20]$ echo "baat" |sed -n '/b[ae]*t/p'
baat
[ttxie@41 part20]$ echo "baaeeeet" |sed -n '/b[ae]*t/p'
baaeeeet
[ttxie@41 part20]$ echo "baaeeaeet" |sed -n '/b[ae]*t/p'
baaeeaeet
[ttxie@41 part20]$ echo "baaekaeet" |sed -n '/b[ae]*t/p'
[ttxie@41 part20]$ echo "baaetaeet" |sed -n '/b[ae]*t/p'
baaetaeet
出现t也行?
20.3 扩展正则表达式(POSIX ERE)
提供了一些可以供linux应用和工具使用的额外符号。
gawk程序能够识别ERE模式(会慢一点),sed编辑器不能识别(查找比较快)。
20.3.1 问号?
类似于星号,但是有点不同。
- 问号表明前面的字符可以出现0次或1次,不会匹配出现多次的字符。
[ttxie@41 part20]$ echo "bt" |gawk '/be?t/{print $0}'
bt
[ttxie@41 part20]$ echo "bet" |gawk '/be?t/{print $0}'
bet
[ttxie@41 part20]$ echo "beeet" |gawk '/be?t/{print $0}' #e 出现了2次,这里就不输出了
- 还可以跟字符组一起使用:
[ttxie@41 part20]$ echo "bt" |gawk '/b[ae]?t/{print $0}'
bt
[ttxie@41 part20]$ echo "bat" |gawk '/b[ae]?t/{print $0}'
bat
[ttxie@41 part20]$ echo "bet" |gawk '/b[ae]?t/{print $0}'
bet
[ttxie@41 part20]$ echo "baet" |gawk '/b[ae]?t/{print $0}'
[ttxie@41 part20]$ echo "baat" |gawk '/b[ae]?t/{print $0}'
[ttxie@41 part20]$ echo "bot" |gawk '/b[ae]?t/{print $0}'
如果字符组中的字符出现了0次或1次,模式匹配就成立,但如果两个字符都出现了,或者一个字符出现了2次,模式匹配就不成立。
20.3.2 加号+
有点像*号。但是必须出现1次以上。可以有多次,但必须至少出现1次。
[ttxie@41 part20]$ echo "bt" |gawk '/be+t/{print $0}'
[ttxie@41 part20]$ echo "bet" |gawk '/be+t/{print $0}'
bet
[ttxie@41 part20]$ echo "beeeet" |gawk '/be+t/{print $0}'
beeeet
20.3.3 使用花括号{}
花括号允许你为可重复的正则表达式指定一个上限,这通常称为间隔。可以用两种格式来指定区间。
1)m:正则表达式准确出现m次
2)m,n:正则表达式至少出现m次,至多n次。
注意:默认情况下gawk程序不识别正则表达式间隔。必须指定gawk程序的–re-interval命令行选项才能识别正则表达式间隔。
[ttxie@41 part20]$ echo "bet" |gawk --re-interval '/be{1}t/{print $0}'
bet
[ttxie@41 part20]$ echo "bet" |gawk --re-interval '/be{1,2}t/{print $0}'
bet
[ttxie@41 part20]$ echo "beet" |gawk --re-interval '/be{1,2}t/{print $0}'
beet
[ttxie@41 part20]$ echo "beeeet" |gawk --re-interval '/be{1,2}t/{print $0}'
- 也适用于字符组
[ttxie@41 part20]$ echo "bt" |gawk --re-interval '/b[ae]{1,2}t/{print $0}'
[ttxie@41 part20]$ echo "bat" |gawk --re-interval '/b[ae]{1,2}t/{print $0}'
bat
[ttxie@41 part20]$ echo "bet" |gawk --re-interval '/b[ae]{1,2}t/{print $0}'
bet
[ttxie@41 part20]$ echo "baet" |gawk --re-interval '/b[ae]{1,2}t/{print $0}'
baet
[ttxie@41 part20]$ echo "baat" |gawk --re-interval '/b[ae]{1,2}t/{print $0}'
baat
[ttxie@41 part20]$ echo "baaeet" |gawk --re-interval '/b[ae]{1,2}t/{print $0}'
[ttxie@41 part20]$ echo "beaest" |gawk --re-interval '/b[ae]{1,2}t/{print $0}'
如果a或e单独持续1次或2次,模式匹配;ae组合出现1次模式匹配;否则,模式匹配失败;
20.3.4 管道符号|
管道符号允许你在检查数据流时,用逻辑or方式指定正则表达式引擎要用的两个或多个模式。
格式如下:expr1|expr2|……
[ttxie@41 part20]$ echo "The dog is asleep" |gawk '/cat|dog/{print $0}'
The dog is asleep
[ttxie@41 part20]$ echo "The dog is asleep" |gawk '/cat|[dp]og/{print $0}'
The dog is asleep
20.3.5 表达式分组()
正则表达式模式也可以用圆括号进行分组。
- 当你将正则表达式模式分组时,该组会被视为一个标准字符。可以像对普通字符一样给该组使用特殊字符。
?是匹配0次或1次。
[ttxie@41 part20]$ echo "Sat" |gawk '/Sat(urday)?/{print $0}'
Sat
[ttxie@41 part20]$ echo "Saturday" |gawk '/Sat(urday)?/{print $0}'
Saturday
相当于把urday当做一个整体了, /SatF?/ 跟这个类似,F出现0次或1次。
- ()需要转义的用法:
[ttxie@41 part20]$ echo "Sat(urday)" | gawk '/Sat\(urday\)/ {print $0}'
Sat(urday)
[ttxie@41 part20]$ echo "Saturday" | gawk '/Sat\(urday\)/ {print $0}'
还可以将分组和管道符号一起使用来创建可能的模式匹配组:
[ttxie@41 part20]$ echo "cat" | gawk '/(b|c)a(b|t)/ {print $0}'
cat
[ttxie@41 part20]$ echo "cat" | gawk '/[b|c]a[b|t]/ {print $0}'
cat
这样相当于匹配 bab bat cab cat 四种。
20.4 正则表达式实战
20.4.1 目录文件计数
这个例子用于对PATH环境变量中各个目录里的可执行文件进行计数:
[ttxie@41 part20]$ cat countfiles.sh
#!/bin/bash
mypath=$(echo $PATH | sed 's/:/ /g')
count=0
for dir in $mypath
do
check=$(ls $dir)
for item in $check
do
count=$[ count + 1 ]
done
echo "$dir - $count"
count=0
done
[ttxie@41 part20]$ bash countfiles.sh
/home/ttxie/miniconda2/bin - 0
/usr/local/bin - 0
/usr/bin - 1679
/usr/local/sbin - 0
/usr/sbin - 644
/home/ttxie/.local/bin - 0
/home/ttxie/bin - 0
20.4.2 验证电话号码
美国的号码格式如下:
(223)456-7890
(223) 456-7890
223-456-7890
223.456.7890
- 最开始可能有
(可以写成:^\(? - 三位区号(第一位必须大于2):
[2-9][0-9]{2} - 然后又是括号:
\)? - 然后是分隔符(无空格,有空格,点,减号):
(| |-|\.)第一个|紧跟在(后面用来匹配没有空格的情况。 - 然后是3位数字:[0-9]{3}
- 又是分隔符:( |-|.)
- 最后四位数字:[0-9]{4}
- 连起来就是:
^\(?[2-9][0-9]{2}\)?(| |-|\.)[0-9]{3}( |-|\.)[0-9]{4}$
[ttxie@41 part20]$ cat isPhone.sh
#!/bin/bash
gawk --re-interval '/^\(?[2-9][0-9]{2}\)?(| |-|\.)[0-9]{3}( |-|\.)[0-9]{4}$/{print $0}'
[ttxie@41 part20]$ echo "317-555-1234" |bash isPhone.sh
317-555-1234
[ttxie@41 part20]$ echo "0317-555-1234" |bash isPhone.sh
还可以将整个文件重定向到脚本:
phonelist里面存放着一行一行的数据:
$cat phonelist | ./isphone
这个例子其实也不是特别合理,比如下面几种情况也算是合法号码:
(235.561-4430
- 451.4651
总之还是有待优化。
20.4.3 解析邮件地址
邮件地址的形式如下:
username@hostname
- username值可用字母数字字符以及以下特殊字符:
- 点号
- 单破折线
- 加号
- 下划线
- hostname部分由一个或多个域名和一个服务器名组成。只允许字母数字字符以及下面的特殊字符:比如([email protected])
- 点号
- 下划线
- username@相当于:
^([a-zA-Z0-9_\-\.\+]+)@
注意: [] 里面是字符组,相当于之前的[xcs]。() 里面是表达式分组
hostname相当于:
([a-zA-Z0-9_\-\.\]+)后面还要接顶级域名。.com .cn .org 等
只能是字母字符,必须不少于两个字符,长度不超多5个字符:\.([a-zA-Z]{2,5})$
- 连起来就是:
^([a-zA-Z0-9_\.\-\+]+)@([a-zA-Z0-9_\.\-]+)\.([a-zA-Z]{2,5})$
[ttxie@41 part20]$ cat isemail.sh
#!/bin/bash
gawk --re-interval '/^([a-zA-Z0-9_\.\-\+]+)\@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/ {print $0}'
[ttxie@41 part20]$ echo "[email protected]" | bash isemail.sh
[email protected]
[ttxie@41 part20]$ echo "222x2iaocho%[email protected]" | bash isemail.sh
[ttxie@41 part20]$ echo "222x2iaocho%[email protected]" |bash isemail.sh
20.5 小结
正则表达式定义了用来过滤数据流中文本的模式模板。
模式由标准文本字符和特殊字符的组成。
正则表达式引擎用特殊字符来匹配一系列单个或多个字符,这类似于其他应用程序中通配符的工作方式