机器学习周记(第十周:RNN续)2023.9.25~2023.10.1
目录
摘要
ABSTRACT
1 文献阅读
2 The error surface is rough
2.1 Helpful Techniques
3 Different Type
3.1 Many to one
3.2 Many to many
3.3 Many to many(No Limitation)
3.4 Beyond Sequence
4 Sequence-to-sequence Auto-encoder-Text
5 Sequence-to-sequence Auto-encoder-Speech
6 相关代码
总结
摘要
本周我继续学习了RNN,在上周的周报上补上了RNN的手推过程,理解了RNN的Loss曲面为何崎岖的原因以及因为崎岖而导致模型不能得到好结果的解决办法。我还学习了根据输入数据的不同,RNN所能解决问题的类型,以及RNN作为自编码器运用的好处。本周我使用LSTM模型预测了北京的PM2.5,还阅读了一篇关于双向长短期记忆网络(BiLSTM)的论文,该论文的模型对于真实数据集的预测具有非常优秀的表现。
ABSTRACT
This week, I continued my studies on RNN. I filled in the gaps from last week's report by working through the manual calculations of RNN, gaining an understanding of why the loss surface of RNN is so rugged and the solutions to improve model performance in the presence of such ruggedness. I also delved into the different types of problems RNN can address depending on input data and explored the advantages of using RNN as autoencoders.
During this week, I utilized an LSTM model to forecast PM2.5 levels in Beijing. Additionally, I read a paper on Bidirectional Long Short-Term Memory networks (BiLSTM), which showcased exceptional performance in predicting real-world datasets.
1 文献阅读
论文标题:DAFA-BiLSTM: Deep Autoregression Feature Augmented BidirectionalLSTM network for time series prediction
概要:本文提出了一种新的深度双向LSTM网络架构,名为DAFA-BiLSTM,用于时间序列预测。该模型通过引入向量自回归转换模块(Vector Autoregressive module,VAR)和增强特征,能够更好地提取时间序列数据的瞬态特征,并在真实世界的时间序列应用中展现出卓越的性能和鲁棒性。
研究意义:时间序列预测模型在现实世界中起着重要作用,因为大多数真实世界的时间序列数据集都富含时间相关信息。然而,传统的时间序列预测模型通常无法充分利用变量之间的潜在空间依赖关系,导致耗时且具有复杂限制。因此,本文旨在提出一种新的深度双向LSTM网络架构,以更好地解决这些问题。
过去方案:过去的时间序列预测模型包括线性统计模型和机器学习算法,但它们无法很好地捕捉到时间序列数据中的非线性动态特征和空间依赖关系。
论文方案:鉴于传统模型的局限性,本文引入了深度双向LSTM网络,并通过向量自回归转换模块和增强特征的方式,提高了模型对时间序列数据的特征提取能力和非线性动力学建模能力。
模型结构:DAFA-BiLSTM模型结合了向量自回归(VA)机制和深度双向LSTM(BiLSTM)的优势,以提高预测准确性和特征表示。VA层用于获取输入序列的线性和非线性特征观测,然后将其连接到深度增强的BiLSTM模块。这样结合了VA层的多个BiLSTM模块就组成了DA-BiLSTM层,在DA-BiLSTM中,前一层的输出与VA层的外部时延线性输入向量进行连接,形成下一相邻层的新的额外输入。每个BiLSTM层通过VA模块转换的特征向量的动态特征映射能力来进行动态特征映射。DA-BiLSTM的模型预测结果不仅受到前一层BiLSTM的输出的连续学习的影响,还受到每个BiLSTM层中添加更多的时延线性特征的影响。因此,DA-BiLSTM相对于传统的深度LSTM结构在预测时间序列数据集方面更加灵活和稳健。DAFA-BiLSTM模型由多个DA-BiLSTM层组成,每个层映射提取的非线性观测的动态特性。
 The process of input vector autoregression consists of linear and nonlinear observations
The process of input vector autoregression consists of linear and nonlinear observations
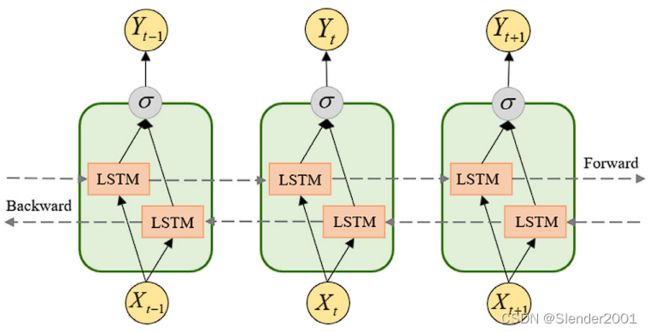 Architecture diagram of the BiLSTM network
Architecture diagram of the BiLSTM network
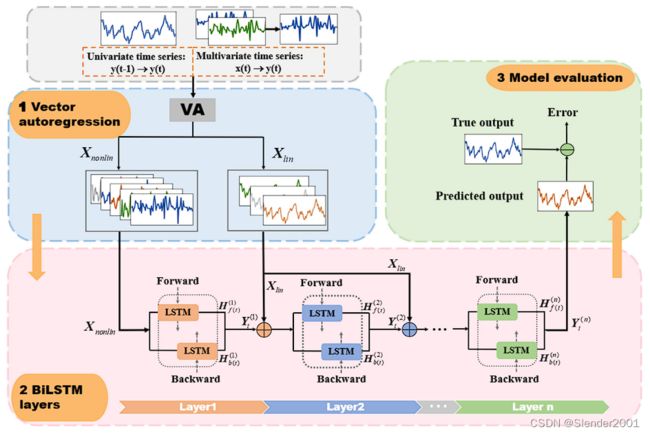 The proposed DAFA-BiLSTM structure
The proposed DAFA-BiLSTM structure
 Algorithm
Algorithm
损失函数:
1.归一化均方误差(normalized mean squared error,NMSE)
![]()
2.平均绝对误差(mean absolute error,MAE)
![]()
3.平均绝对百分比误差(mean absolute percentage error,MAPE)
![]()

2 The error surface is rough
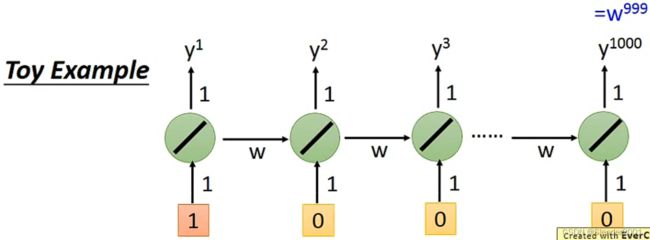
通过实验可知,一个RNN模型并总不是能够轻易地训练出让人满意的结果,有时候它的Total Loss会变得高低起伏,最终得到的不好的Loss。

RNN之所以具有这样的缺陷,是因为它的Loss曲面通常是要么非常平坦,要么非常陡峭。当模型开始训练时,下一步Loss可能跳到“悬崖”上面,导致Loss一下变得非常大,也可能正好跳到“悬崖”上,导致参数微分变得非常大,使得下一步更新的步长变得非常大。因此RNN模型才会出现Loss高低起伏的更新状态。解决这个问题的方案就是Clipping,即当参数微分非常大时,将微分限定在一个阈值之内,这样参数更新就不会一下跳的很远。

如下一个简单的例子可以解释为什么RNN的Error Surface具有这样的特性。
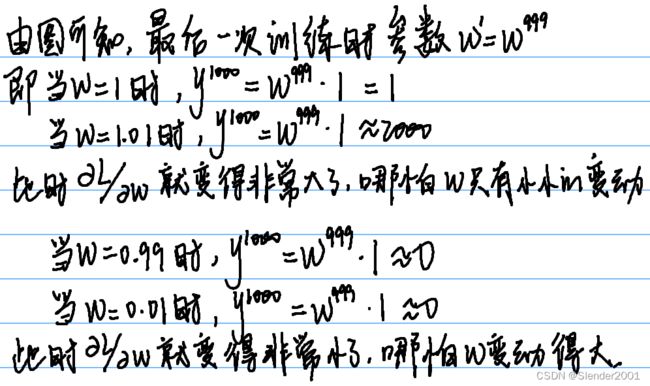
2.1 Helpful Techniques
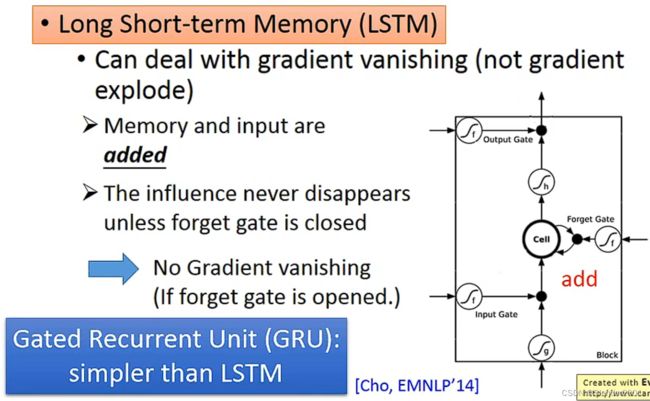
除了使用Clipping来限制参数的梯度,还可以使用LSTM来直接降低Error Surface的“崎岖”程度。LSTM能够解决梯度消失的问题,是因为Memory和Input是同时作为输入的,并且只要Forget Gate不关闭,那么上一次输出的结果永远会对下一次输出的结果产生影响,因此梯度永远不会消失(Forget Gate大部分情况下是打开的)。基于这种原理,为了让Forget Gate不关闭,就干脆舍去Forget Gate,使用一个相似于LSTM的模型Gate Recurrent Unit(GRU)。GRU只有两个门,秉承的原则就是“旧的不去新的不来”。
3 Different Type
使用RNN模型能够解决不同类型的任务,按照输入和输出的不同进行划分。这些任务可以是回归、分类或者聚类等等。
3.1 Many to one
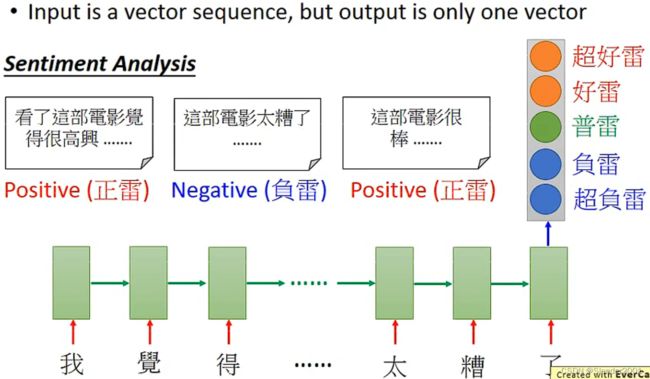
有些任务中,输入一个Vector Sequence但是只需要输出一个Vector。比如说语句情感分析任务,输入一个评论(Vector Sequence),只需要得到这个评论的情感是什么(Vector,每一个维度代表不同的情感)。
3.2 Many to many
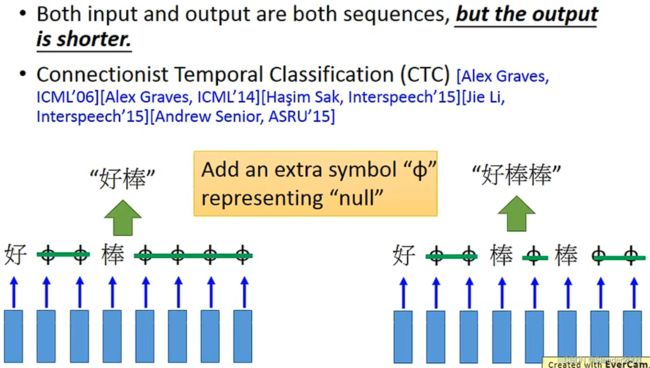
还有一些任务中,输入和输出都是Vector Sequence,但是输入的Vector Sequence的长度更长,输出的Vector Sequence的长度更短。比如说语音辨识任务,输入一句话(“好好好棒棒棒棒棒”),输出Character Sequence(“好棒”)。但存在一个问题是为什么识别出来的是“好棒”而不是“好棒棒”呢?

解决方案就是使用Connectionist temporal classification(CTC)。通过引入一个额外的符号 来表示NULL,输入“好棒”就输出“好棒”,输入“好棒棒”就输出“好棒棒”。
来表示NULL,输入“好棒”就输出“好棒”,输入“好棒棒”就输出“好棒棒”。
3.3 Many to many(No Limitation)
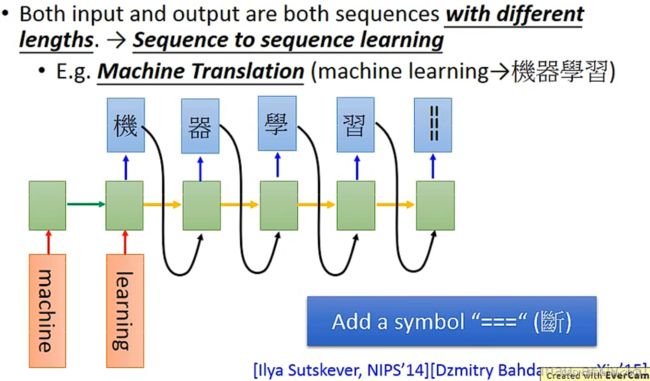
针对输入和输出都是Vector Sequence,但是不知道谁比较长的任务(Sequence to sequence learning),比如说机器翻译任务,输入和输出的Vector Sequence的长度都是不确定的。
3.4 Beyond Sequence
RNN模型的输出甚至可以超越Sequence。比如说句法分析任务(Syntactic Parsing),输入一个句子,输出的结果是这个句子的句法结构,而不是一个Vector Sequence。
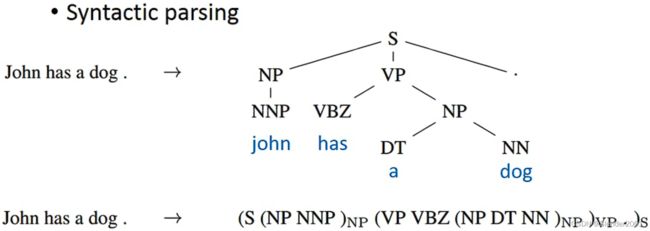
4 Sequence-to-sequence Auto-encoder-Text
当使用RNN做语句分析任务时,为了理解整个语句序列的意思,会忽略单词之间的顺序问题。下图中有两个单词完全一样的句子,只是句子之间的顺序不同,但顺序问题使得两个句子表达的意思也完全不同了。

想要将顺序问题加以考虑,需要使用编码器-解码器架构(Encoder-Decoder),即每一种顺序尽可能只对应一个编码。通常使用RNN作为编码器和解码器,将一个句子输入编码器后得到一个Encoded Vector,然后将Encoded Vector作为解码器的输入使得解码器尽可能得到和编码器输入一样单词顺序的语句。这个Encoded Vector就包含了这个句子中所有重要的信息。语句的编码还可以先编码一部分(逗号分隔的部分),再编码一个句子。实现这些编码效果往往需要大量的文本去训练。

5 Sequence-to-sequence Auto-encoder-Speech
语音数据也可以使用类似编码器-解码器的RNN架构,原理与文本类似,都是先将不等长的输入数据经过编码器整形成定长的编码向量,然后编码向量经过解码器能够还原成输入数据(还原度越高越好)。编码器和解码器的参数是同时训练的。


6 相关代码
实现功能:北京PM2.5预测
数据集:Beijing PM2.5 Data
模型:LSTM模型(训练集样本33824,测试集样本10000)
代码:
import torch
import torch.nn as nn
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
# # 打印出Seaborn库中内置的所有数据集列表
# datasets_name = sns.get_dataset_names()
# print("ALL DATASET:", datasets_name)
#
# # 加载航班数据集
# flight_data = sns.load_dataset("flights")
# flight_data.head()
data = pd.read_excel('../DataSet/PRSA_data_2010.1.1-2014.12.31(Updated_data).xlsx')
# print(data, type(data))
# 将 PM2.5 列的数据改为浮点型存入 all_data 中
all_data = data['PM2.5'].values.astype(float)
# 将列 TIME-HOUR 转换为日期格式
data['TIME-HOUR'] = pd.to_datetime(data['TIME-HOUR'])
# data 的列类型是对象
# print(data.head(), data.shape, data.columns)
# data 是一个 numpy 二维数组
# print(data)
# 划分33824个训练集和10000测试集
test_data_size = 10000
train_data = all_data[:-test_data_size]
test_data = all_data[-test_data_size:]
# print(len(train_data))
# print(len(test_data))
# 归一化,注意 fit_transform 方法的输入必须是一个二维的数组
# 训练集和测试集不要一起归一化,就是说不要先归一化再划分数据集,先将数据集划分后再分别进行归一化
scaler = MinMaxScaler(feature_range=(-1, 1))
train_data_normalized = scaler.fit_transform(train_data.reshape(-1, 1))
test_data_normalized = scaler.fit_transform(test_data.reshape(-1, 1))
# 印出归一化训练数据的前5条和后5条记录
# print(train_data_normalized[:5])
# print(train_data_normalized[-5:])
# 将数据集转换为张量
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)
test_data_normalized = torch.FloatTensor(test_data_normalized).view(-1)
# print(train_data_normalized)
# 将训练数据转换为序列和相应的标签
# 可以使用任何序列长度,取决于领域知识,比如说数据是按月份收集的就将序列长度设为12(一年12个月),如果数据是按天数收集的就将序列长度设为365(一年365天)
# 本数据集是按小时收集的,所以设定序列长度为 30 * 24 (按月来设定窗口)
train_window = 30 * 24
# 定义一个名为create_inout_sequences的函数
# 该函数将接受原始输入数据,并返回一个元组列表
# 在每个元组中,第一个元素将包含 30 * 24 个项目的列表,对应于前1个月内每个小时的 PM2.5 的排放量,第二个元素将包含一个项目的列表即第2个月的第一个小时的 PM2.5 的排放量
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L-tw):
train_seq = input_data[i:i+tw]
train_label = input_data[i+tw:i+tw+1]
inout_seq.append((train_seq, train_label))
return inout_seq
# 创建训练序列
train_input_seq = create_inout_sequences(train_data_normalized, train_window)
# print(train_inout_seq[:5])
class LSTM(nn.Module):
# input_size:对应于输入中特征的数量,数据集中只有 PM2.5 这一个特征
# hidden_layer_size:指定隐藏层的数量以及每层神经元的数量
# output_size:输出中项目的数量,本项目中只预测未来一个小时内的 PM2.5 的量,因此输出大小将为1
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
# self.hidden_cell:这是 LSTM 层的隐藏状态
# LSTM 层是一种循环神经网络(RNN),它在处理序列数据时会维护一个隐藏状态,用于捕获序列中的时间相关性
# input_seq:这是输入到 LSTM 层的数据序列
# 在这里,input_seq 被视为一个三维张量,其形状为 (sequence_length, batch_size, input_size)
# 其中 sequence_length 表示序列的长度,batch_size 表示批次大小,input_size 表示输入特征的数量
# view(len(input_seq), 1, -1):这是一个 PyTorch 的操作,用于重新排列输入张量的维度
# 具体来说,它将输入张量的维度从 (sequence_length, input_size) 重新排列为 (sequence_length, 1, input_size)
# 这是因为 LSTM 层期望输入数据具有这种形状,其中第二个维度通常用于批次大小,这里 1 表示批次大小为 1
# lstm_out 的形状为 (sequence_length, batch_size, hidden_size)
# 预测出来的 PM2.5 的量存储在 predictions 列表中最后一个项目中,并返回给调用函数
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)
# print(lstm_out.shape)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]
# 创建 LSTM() 类对象、定义损失函数和优化器
# 损失函数:交叉熵损失
# 优化器:Adam
model = LSTM()
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# print(model)
# 模型训练
epochs = 1
for i in range(epochs):
for seq, labels in train_input_seq:
optimizer.zero_grad()
# 初始化LSTM模型的隐藏状态和细胞状态
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
y_pred = model(seq)
single_loss = loss_function(y_pred, labels)
single_loss.backward()
optimizer.step()
# {i:3} 是一个占位符,它表示要在这个位置插入一个整数 i,并且将其格式化为占据3个字符的宽度
# 这意味着无论 i 是多少,都会占据3个字符的位置,不足的部分用空格填充
# {single_loss.item():10.8f} 是另一个占位符,它表示要在这个位置插入一个浮点数 single_loss.item(),并将其格式化为占据10个字符的宽度
# 其中包括小数点和8位小数,这会以固定的宽度显示损失值
print(f'epoch: {i:3} loss: {single_loss.item():10.10f}')
# 模型泛化
test_input_seq = create_inout_sequences(test_data_normalized, train_window)
predictions = []
for seq, labels in test_input_seq:
with torch.no_grad():
model.hidden = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
prediction = model(seq)
predictions.append(scaler.inverse_transform(np.array(prediction).reshape(-1, 1)))
print(len(predictions), type(predictions))
print(len(test_data[train_window:]), type(test_data[train_window:]))
print("------------------------------------------------------")
# 创建x轴的值(可以是范围或自定义值)
x_values = np.arange(len(predictions))
# 匹配 prediction 与 test_data[train_window:] 的维度
predictions = np.array(predictions)
print(predictions.shape)
print(test_data[train_window:].shape)
print("------------------------------------------------------")
print(predictions.reshape(-1))
print(test_data[train_window:])
# 绘制预测值的图形
plt.plot(x_values, predictions.reshape(-1), label='Forecast values', linestyle='-', color='red', marker='')
# 绘制真实值的图形
plt.plot(x_values, test_data[train_window:], label='True Values', linestyle='-', color='blue', marker='')
# 添加图例
plt.legend()
# 设置图形标题和轴标签
plt.title('True vs. predicted values')
plt.xlabel('Time')
plt.ylabel('PM2.5')
# 显示图形
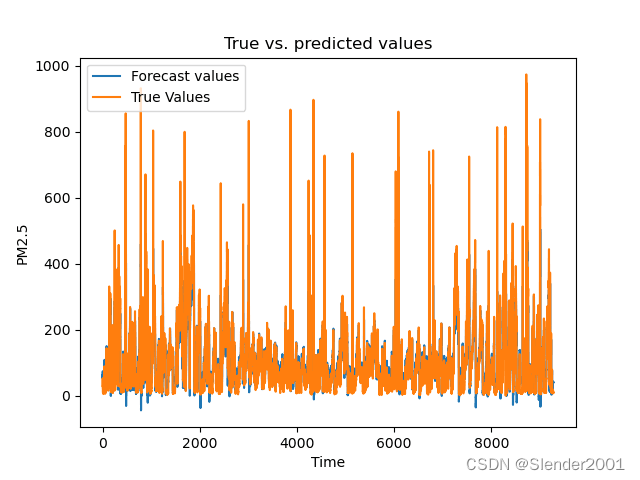
plt.show()原始数据图像:

测试集预测数据图像:(受限于设备性能,epoch次数很少,导致测试结果很差)
总结
RNN作为自编码器除了运用于语音和文本数据,还可以用于处理时间序列数据,在上一周阅读的文献中就使用了LSTM作为自编码器结合自注意力机制提高时间序列预测的精度。下一周我将开始学习GNN。