2023/11/5周报
文章目录
- 摘要
- Abstract
- 文献阅读
-
- 题目
- 创新点
- 方法框架
- 数据收集和实验设置
- 实验结果
- Conclusion
- 深度学习
-
- Self-attention
-
- Self-attention的优势
- Self-attention的原理
- Transformer
- 模型训练
- 总结
摘要
本周阅读了一篇基于多输出学习的深度神经网络空气污染时间序列预测的文章,文中使用多输入多输出的学习方法,使用MConvLSTM模型,减少了训练周期和参数的数量。此外还对self-attention和transformer模型进行了复习。
Abstract
This week, an article on the prediction of air pollution time series based on deep neural network with multi-output learning is readed. In this paper, the multi-input multi-output learning method and the MConvLSTM model are used to reduce the training period and the number of parameters. In addition, the self-attention and transformer models are reviewed.
文献阅读
题目
Time Series Forecasting of Air Pollution using Deep Neural Network with Multi-output Learning
创新点
传统的空气污染预测方法为给定的多个输入提供单一输出。现有的污染预测方法,包括统计学和机器学习技术。这些技术遵循多输入和单输出的方法,这种方法在一次运行中提供多输出结果的同时无法提供模型稳定性。此外,这些模型需要为每个变量单独训练才能提供多个输出,这需要更多的训练时间,最终会严重影响预测性能。因此,本研究开发了一种多输入多输出学习方法的神经网络模型,该模型可以识别长期内特征之间的相关性,以提高精度。由于该模型不需要对每个变量进行多次训练,最终减少了训练周期和成本。
方法框架
该方法框架采用多输入、多输出学习方法,多输出卷积LSTM(MConvLSTM)网络模型如下图所示。

ConvLSTM能够识别空气质量特征之间的时间相关性,并基于历史信息对数据进行时态建模,已被广泛应用于时间序列预测。卷积部分旨在更好地进行特征学习,而LSTM部分用于时间序列预测。ConvLSTM具有与LSTM类似的架构,这是RNN结构的另一种变体。
LSTM在每个门中都有一个点积,它被ConvLSTM中的卷积运算所取代。ConvLSTM操作可以计算为:

其中 ![]() 是输入变量,
是输入变量, ![]() 是神经元的隐藏状态。输入变量和隐藏状态都被卷积,其中作为
是神经元的隐藏状态。输入变量和隐藏状态都被卷积,其中作为 ![]() ,神经元状态不被卷积,而只是点积。输入门
,神经元状态不被卷积,而只是点积。输入门 ![]() 、单元状态更新门
、单元状态更新门 ![]() 、遗忘门
、遗忘门 ![]() 和输出门
和输出门 ![]() 都经历类似的卷积。2D卷积层取代卷积操作。
都经历类似的卷积。2D卷积层取代卷积操作。
数据收集和实验设置
实验空气污染数据集包括2013年至2017年期间的空气污染物和气象参数。
注:
由于传感器生成的污染物数据集包含缺失值和损坏的数据。因此,使用线性插值来确定其缺失值的属性。一旦缺失值被插补,则采用Z分数技术进行数据归一化。
本文使用RMSProp优化器及MAE损失函数来训练各模型。对于多步预测结果,预测范围设置为91。每个深度学习模型都使用了Relu激活函数。遵循drop机制,以避免模型过拟合。对于每个深度学习模型,dropout值设置为0.02,epoch设置为1000。
实验结果
在评估建议和基线模型的预测性能时,对均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE)进行了评估。单输出基线模型,如CNN,LSTM,GRU,Bidirectional LSTM(BILSTM),Bidirectional GRU(BIGRU)被用作基线模型,以评估所提出的M-ConvLSTM模型在91天预测期内的污染预测性能。

为了进一步评估MCvLSTM模型的预测结果,还绘制了古城站点污染物预测值与实际观测值之间的散点图,表明与其他比较的单输出模型相比,所提出的模型的预测值和观测值之间的差异最小,下面以pm2.5为例:


Conclusion
本文采用多输出学习技术,以提高长期空气质量预测模型的稳定性。所提出的M-ConvLSTM模型可以同时预测多个污染物,比单输出模型降低了度量值。
深度学习
Self-attention
有时候我们期望网络能够看到全局,但是又要聚焦到重点信息上。比如在做自然语言处理时,句子中的一个词往往不是独立的,和它上下文相关,但和上下文中不同的词的相关性又是不同的,所以我们在处理这个词时,在看到它的上下文的同时也要更加聚焦与它相关性更高的词,这就需要用到自注意力机制。
自注意力机制在序列模型中取得了很大的进步。上下文信息对于很多视觉任务都很关键,如语义分割、目标检测。自注意力机制通过(key、query、value)的三元组提供了一种有效的捕捉全局上下文信息的建模方式。
Self-attention的优势
在之前,NLP领域通常使用LSTM(RNN)来处理序列数据。例如在执行翻译任务时,需要考虑源句内部的关系、目标句内部的关系、原句与目标句之间的关系。然而RNNseq2seq模型只捕捉了原句与目标句之间的关系,因此RNN/LSTM产生了如下两个缺点:
A: 需要考虑前序信息,不能并行运算,导致训练所需时间较长。
B: 当序列长度过长的时候,由于模型深度增加,序列开始的部分对末端部分的影响几乎消失,虽然通过记忆网络、attention机制的加入可以降低一部分影响,但这种问题依旧存在。由于对于长距离的信息不能有效的提取和记忆,会导致信息的大量丢失。
Self-attention可以很好的处理上面两个问题,首先,self-attention通过位置编码保证序列
关系,计算上不依赖序列关系,所以可以实现完全的并行,其次,在计算相关性时候,任何
一个点都会与整个序列中的所有输入做相关性计算,避免了长距依赖的问题。
Self-attention的原理
首先以两个词的输入为例来解释self-attention的大致过程:


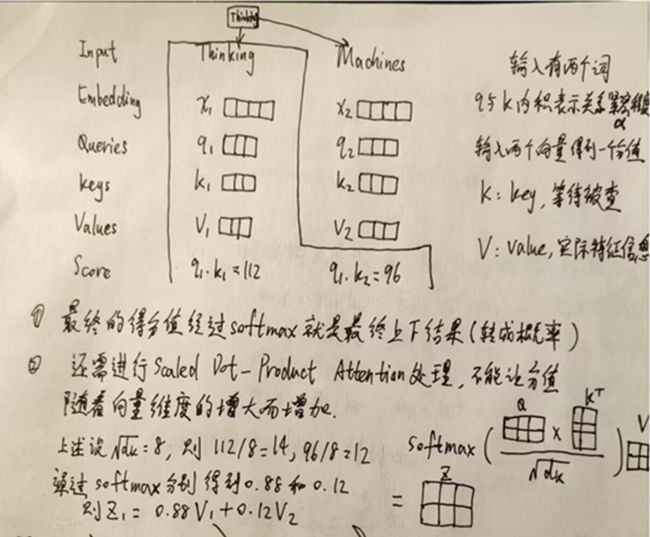
此时每个词看的是整个输入序列,不再只看之前的序列,并且是并行计算,同时计算出所有的输出结果。
再以四输入四输出为例进行补充说明:
由此可知,只有Wq、Wk、Wv是机器需要学习的参数。其它参数不需要学习。
Transformer
在自然语言处理任务中,往往需要对句子进行编码表示,以便后续任务使用。传统的序列模型,例如RNN和LSTM,能够在某种程度上解决这个问题,但是由于序列模型的特殊结构,使得其难以并行计算,并且在处理长文本时,性能下降明显。因此,Google提出了一种全新的模型——Transformer。

基于self-attention的机制,包括encoder编码器和decoder解码器两部分。上周周报已推导self-attention的计算公式如下:
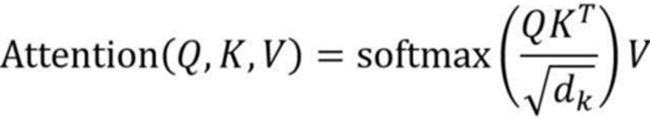
dk是Q,K矩阵的列数,即向量维度。
Encoder
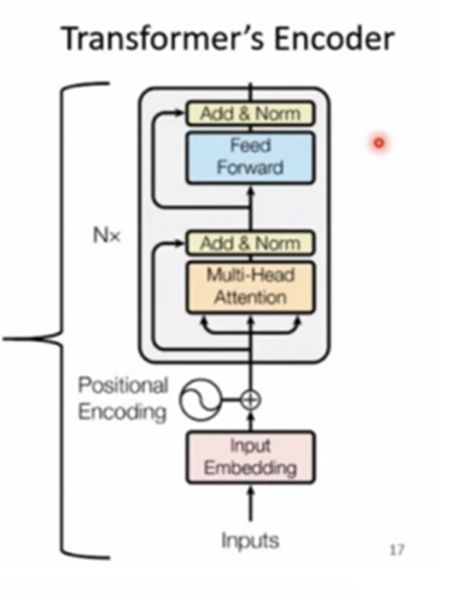
在encoder编码器中,每一层包括两个子层:Multi-Head Attention和全连接层。Multi-Head Attention层将输入序列中的每个位置都作为查询(Q)、键(K)和值(V),计算出每个位置和所有位置之间的注意力分布,得到一个加权和表示该位置的上下文信息。全连接层则对该上下文信息进行前向传播,得到该层的输出。
Decoder
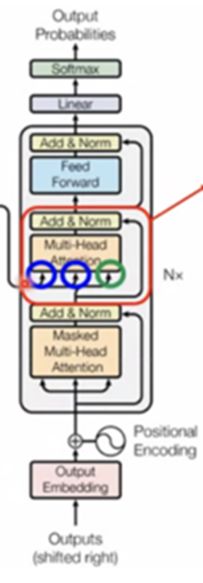
在解码器中,除了编码器中的Multi-Head Attention和全连接层,还增加了一个Masked Multi-Head Attention层。该层和编码器中的Multi-Head Attention类似,但是在计算注意力分布时,只考虑该位置之前的位置,从而避免了解码器中使用未来信息的问题。
模型训练
Transformer模型的训练过程通常使用最大似然估计(MLE)来完成。即对于给定的输入序列,模型预测输出序列的概率,并最大化其概率值。同时,为了避免过拟合,通常还会加入正则化项,例如L2正则化等。
总结
本周学习了一篇基于多输出学习的深度神经网络空气污染时间序列预测的文章,对时序序列模型进行初步接触,并对self-attention进行了复习,下周继续学习时序模型和流体力学内容。