第二、三周周报12.17.2022-12.25.2022
这两周:
爬了一些图片练练手
作为NLP入门,跟着看了李宏毅老师的一些NLP基础内容。
学习了RNN模型的数学基础,原理,用pytorch跑了一下RNN,对于如何使用RNN模型有了一定的了解
目录
图片爬虫:
acjson
selenium
NLP
语音辨识
TOKEN
获取声学特征
一些数据集尺度
语音辨识常见模型
seq2seq
HMM
RNN
输入输出张量shape
激活函数:
RNN:tanh函数
IRNN:RELU函数
损失函数:
多层RNN
嵌入层embedding
one-hot编码缺点
Embedding的作用
实际操作
线性层linear
双向循环
图片爬虫:
百度图片有反爬机制,这个把headers多填充一下就好了。
比如搜索一下BERT相关的图片,百度图片会给出如下非常长的一个url,其实GET方式传请求的话,留word这一项就可以了,bert传入后即可
https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8864303546197470980&ipn=rj&ct=201326592&is=&fp=result&fr=&word=bert&queryWord=bert&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn=90&rn=30&gsm=5a&1672118989250= https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8864303546197470980&ipn=rj&ct=201326592&is=&fp=result&fr=&word=bert&queryWord=bert&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn=90&rn=30&gsm=5a&1672118989250=然后比较折磨的一点就是,一开始不知道,百度图片的网页实际是动态网页,然后它request返回的不是正常的html,会出错,图片甚至会把base64编码返回,实际处理不是很方便。所以这里就不继续用beautifulsoup4来进行图片爬取了。
https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8864303546197470980&ipn=rj&ct=201326592&is=&fp=result&fr=&word=bert&queryWord=bert&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn=90&rn=30&gsm=5a&1672118989250=然后比较折磨的一点就是,一开始不知道,百度图片的网页实际是动态网页,然后它request返回的不是正常的html,会出错,图片甚至会把base64编码返回,实际处理不是很方便。所以这里就不继续用beautifulsoup4来进行图片爬取了。
具体的方法话,有两种方法,
- 一种是selenium,就可以实现动态网页的爬取了
- 一种分析网页返回会发现acjson包,看了一下会发现,里面key:thumburl后面对应的value就是我们需求图片的静态资源url,然后爬取这个url实际就可以了
第二种相对简单一点,所以在这里简单地尝试了一下,唯一不方便就是它不是html没法解析,然后也不是没有办法,自己编写一个正则表达式,取出来就可以了。
img_re = re.compile('"thumbURL":"(.*?)"')就是取thumbURL后的url。
具体流程,简单来讲就是,request->正则表达式取url->request img url->保存到本地。
因为百度正好一页是30张图,所以这里爬了一页。
还有值得一提的一点:request 图片url后,返回的直接用r.content就好了,content和text的区别在于content返回的是byte型数据,而text返回的是Unicode数据,也就是说text对原始数据进行的特殊的编码,而这个编码方式是基于对原始数据的猜测(响应头),
- text一般用于返回的文本
- content的一般用于对返回的其他数据类型
acjson
import requests
import re
headers = {"User-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36', # 随机生成一个代理请求
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Connection": "keep-alive"}
img_re = re.compile('"thumbURL":"(.*?)"')
count=0
def file_op(img):
global count
count+=1
tmp_file_name = 'C:/Users/源/image/%s.jpeg' % count
with open(file=tmp_file_name, mode="wb") as file:
try:
file.write(img)
except:
pass
def url(page_url, start_num=0, page=5):
end_num = page*30
for page_num in range(start_num, end_num, 30):
resp = requests.get(url=page_url+str(page_num), headers=headers)
if resp.status_code == 200:
img_url_list = img_re.findall(resp.text) # 这是个列表形式
print(img_url_list)
for img_url in img_url_list:
img_rsp = requests.get(url=img_url, headers=headers)
file_op(img=img_rsp.content)
else:
break
print("内容已经全部爬取")
if __name__ == "__main__":
org_url = "https://image.baidu.com/search/acjson?tn=resultjson_com&word=bert"
url(page_url=org_url, start_num=int(input("开始页:")), page=int(input("所需爬取页数:")))
爬下来的结果30张

这种就是完全爬静态了,还有就是selenium,直接模拟鼠标滑动网页,读取动态网页数据来爬取,比较高级一点,下周有时间再做。
selenium
。。。。
NLP
The field of study that focuses on the interactions between human language and computers is called Natural Language Processing or NLP for short. It sits at the intersection of computer science, artificial intelligence, and computational linguistics. -----Wikipedia
即专注于人类语言和计算机之间互动的研究领域。
NLP大致分为两种,一种是传统NLP,例如隐马尔可夫模型和条件随机场模型,一种是现代利用深度学习来实现的NLP。
应用方面大致有如下六种:语音转文本,文本转语音,语音改变,翻译,问答,回复。

语音辨识
语料预处理的 6 个步骤
- 分词 – Tokenization
- 词干提取 – Stemming
- 词形还原 – Lemmatization
- 词性标注 – Parts of Speech
- 命名实体识别 – NER
- 分块 – Chunking
TOKEN
早期没有深度学习,NLP的操作是phoneme,利用字符与音符的对照leixicon,例如cat->K AE T,这样,通过大量的专家标注来实现语音辨识。
还有grapheme,英文单词之间用_间隔,中文则不需要间隔。
phoneme和graphme区别就类似于phoneme是一个个单词整体的语音和单词转化,而graphme倾向于离散的,将所有字母分隔地取对照,而因此,graphme会面临辨识错误等风险,例如k的读音可能同时对照英语k和c。
morpheme 将一个单词最小可表示含义的部分提取出来识别。
获取声学特征
输入音频后,对其采样,按时间例如25ms一个区间截取采样片段,再以10ms逐步推进。在一个时长为25ms的区间内,
最简单的就是,取所有采样点,例如一个采样频率16khz,25ms的片段,那么就有400个特征。除此以外,还有MFCC输出维度为39维左右。类似的还有filterbank output,大约是80维。
一些数据集尺度

语音辨识常见模型
seq2seq
。。。
HMM
。。。
RNN
RNN本质是一种线性层。

将序列中的每一项都送入RNN cell当中,并且融合每一个x1,x2等等

h0作为先验知识,进行一个输入,如果没有实际h0的值,那么就直接取维度与hi相等的零向量输入,例如hi为5维,h0=[0 0 0 0 0]'
RNN cell实际在这一运算过程中,是同一个线性层,也即同一个RNN cell在未进行反向传播之前,里面的参数是相同的,改变的只有输入的不同时刻的输入序列值以及上一时刻输出的隐藏层数值,这也是为什么RNN被称为循环神经网络的原因。
大致原理可用如下代码表示:
for x in X:
h=linear(x,h)pytorch创建RNNcell:
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)直接调RNN:
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers)
out, hidden = cell(inputs, hidden)输入输出张量shape
网络输入的 shape 为 [seq_len, batch, feature_len]。其中 seq_len 代表特征的个数,batch 代表有多少个句子,feature_len 代表每个特征的向量表示,hidden_len 代表 RNN 单元的隐含层神经元个数。
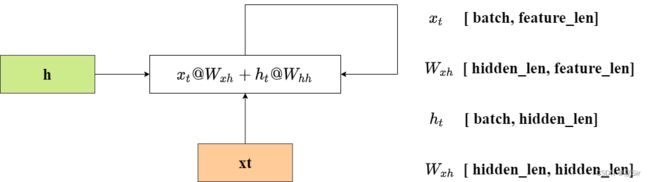
本质上,每次迭代就是xt与h进行运算,同时输出的h参与到下一次迭代的运算当中。
RNN 层的公式: ![]()
shape 变化为:![]()
激活函数:
RNN:tanh函数
RNN采取tanh,主要原因是防止梯度爆炸,RNN与CNN不一样,RNN中,在每个阶段都共享一个参数 W,使用relu函数的话,就会造成激活函数对输入值的求导结果始终为1,某一条路径上的导数中W连乘将会是一个非常大的数值。
IRNN:RELU函数
不过在IRNN当中,通过对W和b设置特殊的初值,避免了W连乘数值过大这一结果,也可使用RELU。
损失函数:
RNN损失函数主要是one-hot编码、softmax构成的交叉熵函数来计算损失函数的。

多层RNN

嵌入层embedding
one-hot编码缺点
维度高、稀疏、硬编码
因此编码希望维度低、稠密、通过数据学习来编码
把one-hot进行降维,或者升维,因为在实际的应用当中,往往单一的降维可能无法发现特征的特性,升维往往也是一种选择。
具体的计算实现大致为特征矩阵 原始矩阵*升降维矩阵=新的embedded矩阵,其实类似于卷积,利用矩阵进行升降维。
Embedding的作用
简单来说,个人理解下EMBEDDING。作用实际上是,利用矩阵乘法进行升降维操作,不过在这个升降维的过程当中,EMBEDDING同时在各特征的具体数值上,建立了输入数据当中一定的联系,使得在深度学习当中,可以发现这些关系,提升效率。
实际操作
根据数据首先转换为one-hot编码的tensor就不多说了,转换完成后,由于现实情况下,tensor中的seq_len可能不一致,由此,需要进行填充,具体的操作为:首先构建一个shape与当前一样的tensor再将现在的数据从原来的tensor上拷贝过来,替换对应位置的数据实现padding。
其次,在输入之前,需要进行由高到低的seq_len排序。

完成seq_len降序排序后,即可进行embedding。这里embedding后,会发现tensor直接shape加1了,这里的原因实际上就是,取图中78这个数字,实际就是onehot编码后,[0,0,0,...1,0,0...,0],也即78位置处为1的一个编码,然后它的维度为hiddensize原因是,embedding后就要输入RNNcell当中去进行运算,根据输入输出张量shape这部分,得知在seq—len循环当中xt实际为batch*featurelen长度,不过这里选取hiddensize为nn.embedding中设置的dim为hiddensize。
总之,最后按照非0的这些,全部叠到一块儿,构成一个shape为2的tensor就可以进行后续的操作。然后,神经网络自己取数据的时候,就根据这个seq_length列表,一条条地取,首先是x1有10个,x2有8个,这样运算。
self.embedding = torch.nn.Embedding(input_size, hidden_size)
embedding = self.embedding(input)更具体一点,nn.embedding的大致逻辑是如下代码。
def make_tensors(names, countries):
sequences_and_lengths = [name2list(name) ofor name n in names]
name_sequences = [sl[0] ofor sl n in sequences_and_lengths]
seq_lengths = torch.LongTensor([sl[1] ofor sl n in sequences_and_lengths])
countries = countries.long()
# make tensor of name, BatchSize x SeqLen
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
ofor idx, (seq, seq_len) n in enumerate(zip(name_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
# sort by length to use pack_padded_sequence
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=reTrue)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx]
eun return create_tensor(seq_tensor), \
create_tensor(seq_lengths),\
create_tensor(countries)就是四步走,seq长短不一填充->按seq长短降序排列->根据设置的输出维度输出->按batch排入一列输入hidden层。
线性层linear
因为在实际设置hidden_size当中,输出并不一定与分类的结果数量,也就是最终输入到交叉熵函数当中的特征个数相同,所以最后一步输出,可以借助线性层将结果输出为于特征个数相同的维度。

#定义线性层
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)
#分类结果输出
fc_output = self.fc(hidden_cat)
return fc_output双向循环
实际在自然语言处理当中,对于语言的理解,往往不仅需要根据一个序列从前向后考虑,从后向前,例如我们在一个地点名词前面,往往要加一个动词这样。由此,产生了双向循环神经网络。

比如双向GRU当中
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers,
bidirectional=bidirectional)
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)fc是我们定义的线性层,如果是bidirectional的话,那么最终输出,就不仅仅是一个hn,而是双向
拼接成的,[h_n_f,h_n_B],分别代表前向和反向的rnn结果。