论文阅读-基于深度强化学习的方法解决多智能体防御和攻击问题
论文原题目:A deep reinforcement learning-based method applied for solving multi-agent defense and attack problems
论文链接:https://www.sciencedirect.com/science/article/pii/S0957417421003377
论文信息:

目录
1 引言
2 问题制定与环境建模
2.1 多智能体防御与攻击
2.2 环境建模
2.2.1 状态空间
2.2.2 动作空间
2.2.3 奖励函数
3 智能体模型和学习过程
3.1 单智能体模型和学习过程
3.1.1 DDPG的网络结构
3.1.2 DDPG的学习过程
3.2 多智能体模型和学习过程
3.2.1 MADDPG的网络结构
3.2.2 MADDPG的学习过程
4 仿真结果与分析
4.1 环境模型设定
4.2 评价标准及参数设置
4.3 基线方法
4.4 基于规则的攻击代理的多代理防御与攻击
4.5 基于DRL的攻击代理的多代理防御与攻击
5 结论与未来工作
摘要:
智能体之间的协作学习一直是人工智能领域的重要研究课题。多智能体防御与攻击是多智能体协作中的重要问题之一,需要环境中的多个智能体学习有效的策略来实现目标。深度强化学习( Deep Reinforcement Learning,DRL )算法在处理连续控制问题尤其是动态交互情况下具有天然的优势,为那些长期研究的多智能体协作问题提供了新的解决方案。本文从深度确定性策略梯度( DDPG )算法出发,引入多智能体深度确定性策略梯度 ( MADDPG )算法来解决不同情况下的多智能体防御和攻击问题。我们重新构建所考虑的环境,重新定义连续状态空间,连续动作空间,相应的奖励函数,然后应用深度强化学习算法来获得有效的决策策略。为了验证基于DRL的方法的可行性和有效性,进行了多个考虑不同对抗场景的实验。实验结果表明,通过学习智能体可以做出更好的决策,并且使用MADDPG进行学习比使用其他基于DRL的模型取得了更优越的性能,这也说明了掌握其他智能体信息的重要性和必要性。
1 引言
本文的贡献:( 1 )基于开源的多智能体粒子环境重构多智能体防御和攻击环境;( 2 )引入深度强化学习算法,重新定义状态空间、动作空间和奖励函数;( 3 )使用几种不同的基于DRL的学习模型来训练攻击代理和防御代理;( 4 )通过实验和比较验证了所应用的DRL模型的有效性。
2 问题制定与环境建模
2.1 多智能体防御与攻击
本文考虑了防御和攻击问题的两个子问题,具体描述如下:
( 1 )基于规则攻击者的多Agent防御与攻击。本文采取基于规则攻击者对智能防御者。不考虑基于规则的防御者对抗智能攻击者的情形。
( 2 )基于DRL的多智能体防御与攻击。在这个子问题中,攻击者和防御者都通过深度强化学习模型采取行动,即智能攻击者和智能防御者。在这种情况下,攻击者为了实现自己的目标而合作,防御者也是如此。
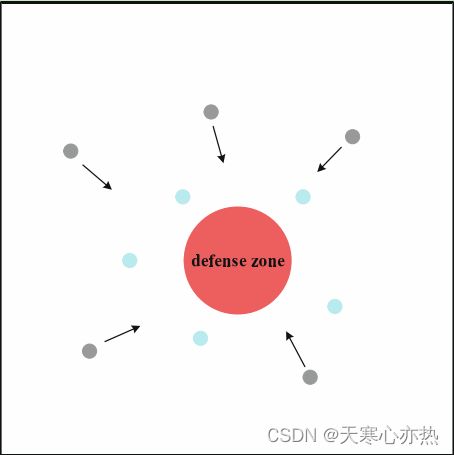 图1 防守与进攻的竞技场:红色圆形区域为防守区域,蓝色圆圈为防守方,黑色圆圈为进攻方。
图1 防守与进攻的竞技场:红色圆形区域为防守区域,蓝色圆圈为防守方,黑色圆圈为进攻方。
2.2 环境建模
在多智能体防御和攻击问题中,考虑的问题中有两类智能体,智能体类型k∈{ ATK,DFS },其中ATK表示攻击智能体,DFS表示防御智能体。所有的智能主体通过与环境的交互来学习自己的策略。我们将问题建模为马尔可夫决策过程( Markov Decision Processes,MDP ),我们的目标是最大化所有代理的累积折扣奖励。我们采用独立的五元组( ![]() 、
、![]() 、
、![]() 、
、![]() 、
、 )来表示每个类型为k的智能体i。
)来表示每个类型为k的智能体i。
2.2.1 状态空间
一般而言,防御Agent和攻击Agent的特征是相似的。对于给定的智能体,攻击者或防御者,状态向量中包含三种信息,分别是
( 1 )给定智能体自身的信息;
( 2 )相同类型智能体的相对位置和速度;
( 3 )与对手类型智能体之间的相对位置和速度。
![]()
![]()
2.2.2 动作空间
本文考虑智能体的连续动作空间,将动作表示为一个二维速度向量[ vx , vy],使得攻防智能体能够以任意速度和方向运动。
为了有效模拟实际智能体的运动行为,本文的智能体模型输出了智能体的二维加速度向量 ![]() ,而不是直接的速度向量。通过以下速度公式可以得到相应的速度,
,而不是直接的速度向量。通过以下速度公式可以得到相应的速度,

2.2.3 奖励函数
奖励函数表示在特定情境下被执行动作的表现。在本小节中,我们将重新定义攻击代理和防御代理的奖励函数,以使所使用的DRL算法在解决所考虑的问题时更具优势。为了避免奖励稀疏的问题,我们使用了基于距离的奖励函数。
对于攻击代理而言,其目标是到达防御区。显然,攻击代理越靠近防御区,其威胁越大。因此,攻击代理的奖励应该与自身和防御区的距离成反比。那么,攻击代理i在时刻t的奖励函数定义如下,

对于防御代理来说,他们的奖励也是基于距离。此外,防御代理的奖励函数需要考虑攻击者,定义防御代理j在时刻t的奖励函数为,

3 智能体模型和学习过程
在多智能体防御和攻击环境中,可以通过不同的模型训练多个不同的智能体。本文将问题分为两类,一类是单智能体模型和学习过程,另一类是多智能体模型和学习过程。在单智能体模型中,每个智能体只考虑自身的信息,而在多智能体模型中,需要同时考虑自身和其他智能体的信息。
3.1 单智能体模型和学习过程
我们采用传统的深度强化学习算法来处理单智能体模型。在所考虑的问题中,动作空间应该是连续的,因此我们采用深度确定性策略梯度( DDPG )算法来训练单智能体。由于攻击代理和防御代理在状态和动作上有相似之处,唯一不同的是奖励函数定义。因此,我们以攻击代理为例进一步说明应用模型和学习算法。对于防御代理,我们只需要替换奖励函数即可。
3.1.1 DDPG的网络结构
DDPG是基于行动者评论家( AC )的DRL模型。与DQN等基于值的DRL方法相比,模型中动作策略的生成和动作的评估是通过两个单独的组件完成的。而在DQN中,动作选择策略由每次预测的Q值最高的动作决定。因此,在AC架构中,有两个深度神经网络,一个负责生成策略(策略网络),另一个负责评估策略( Q网络)。
因此,对于任意的攻击代理![]() ,都有对应的策略网络
,都有对应的策略网络![]() 和Q网络
和Q网络![]() 。
。![]() 和
和![]() 的定义分别如式( 11 )和式( 12 )所示,
的定义分别如式( 11 )和式( 12 )所示,

其中,策略网络![]() 根据状态
根据状态![]() 生成动作
生成动作 ![]() 。
。![]() 是策略网络需要学习的参数。注意,
是策略网络需要学习的参数。注意,![]() 是一个连续的行动,我们需要通过策略整合将其转化为实际行动,而不是对行动进行抽样。
是一个连续的行动,我们需要通过策略整合将其转化为实际行动,而不是对行动进行抽样。
需要注意的是,在DDPG中,不同智能体的策略和评价是独立的,即每个智能体的策略和评价仅由其自身的状态和行动决定。
本文采用多层感知( MLP )构建策略网络和Q网络,架构如图2所示。该策略网络具有1个输入层、2个隐含层和1个输出层。输入层和输出层均为全连接( FC )网络,定义如式( 13 )所示。在每个隐藏层中,有64个以ReLu为激活函数的神经元,ReLu的定义见式( 14 )。输出层有5个神经元,表示5个基本动作,采用Softmax激活函数保证动作系数之和为1。Softmax的定义如式( 15 )所示。
![]()
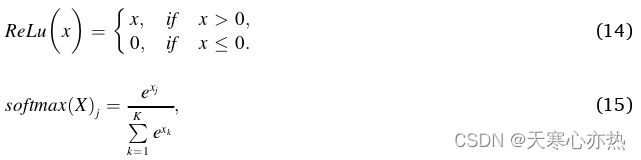
 图2 策略网络P和Q网络Q的架构
图2 策略网络P和Q网络Q的架构
Q网络的架构与策略网络类似,但输入和输出略有不同。在Q网络中,输入是策略网络生成的状态和动作的连接向量。我们不使用神经元来表示输出( None ),以确保评估值的范围是实数域。
3.1.2 DDPG的学习过程
由于DDPG有两个独立的网络,我们将分别说明这两个网络的学习过程。
Q网络的学习过程基于Bellman函数描述当前状态-动作对的评价值与下一个状态-动作对的评价值之间的关系。Q值可以形式化定义如下,

Q网络的目标是最小化TD误差,TD误差越小,估计的状态-动作对的评价越准确。通过( 16 )式,我们可以得到TD误差,即
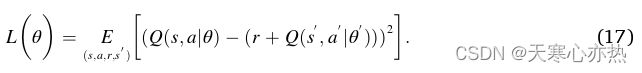
因此,可以通过梯度下降更新相应的参数θ,如下式所示,

式中:η为学习速率。
另一方面,策略网络的学习是基于策略梯度的,目标是最大化对策略网络生成的策略中行动的整体评价,如下式所示,

在DDPG中,策略是确定的,式( 19 )中的梯度可以表示为:
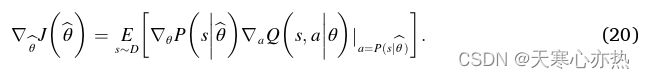
然后,通过( 21 )式中的梯度提升可以更新策略网络中的参数 θ

3.2 多智能体模型和学习过程
单智能体强化学习无法有效利用其他智能体的全局状态和动作信息,即DDPG中的Q网络只能根据单个智能体的状态和动作做出反应,导致Q网络给出的评价不准确。为了解决这个问题,MADDPG ( Lowe等, 2017)算法被提出。
MADDPG是DDPG在多智能体环境下的扩展。MADDPG和DDPG的策略网络相同,都考虑了单个Agent的状态信息。两者的区别在于MADDPG中的Q网络考虑了其他智能体的动作和状态,区别仅体现在训练阶段。在测试阶段,由于不再需要Q网络,它们的策略网络的执行过程完全相同。MADDPG与DDPG在网络结构上的比较如图3所示。从图3可以看出MADDPG与DDPG的区别。在接下来的小节中,我们也将以攻击代理为例,简要介绍MADDPG的网络结构和学习过程。
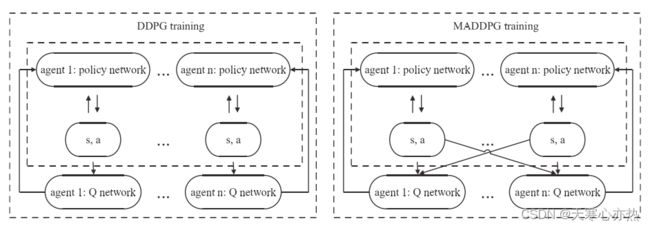 图3 MADDPG训练与DDPG训练的差异
图3 MADDPG训练与DDPG训练的差异
3.2.1 MADDPG的网络结构
在MADDPG中,攻击代理![]() 存在策略网络和Q网络。策略网络的定义与DDPG的定义一致,如式( 11 )所示。然而,Q网络更新为:
存在策略网络和Q网络。策略网络的定义与DDPG的定义一致,如式( 11 )所示。然而,Q网络更新为:
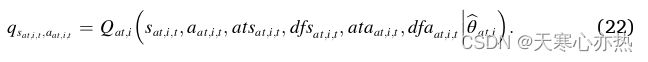
MADDPG中的Q网络和策略网络也使用了MLP,如图4所示。
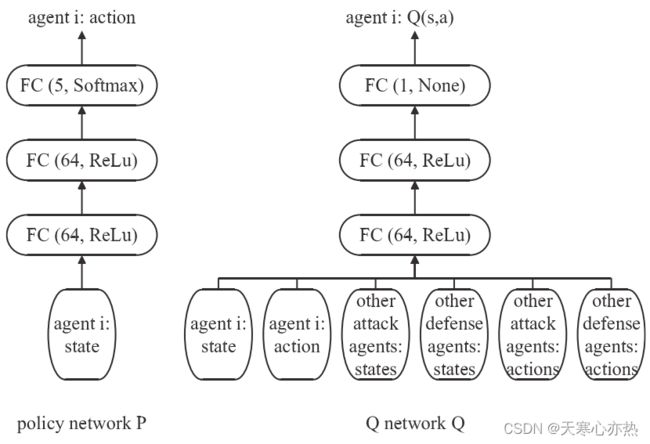 图4 MADDPG中策略网络和Q网络的架构
图4 MADDPG中策略网络和Q网络的架构
3.2.2 MADDPG的学习过程
MADDPG的学习过程与DDPG类似。对于Q网络,对应的目标函数为:
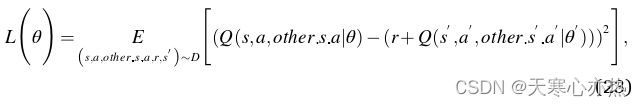
其中,![]() 是其他攻击者和防御者的状态和动作。对于下一时刻
是其他攻击者和防御者的状态和动作。对于下一时刻![]() 的状态和动作,
的状态和动作,![]() 的状态来自重放缓冲区,
的状态来自重放缓冲区,![]() 的相关动作通过延迟策略网络获得。梯度的更新如式( 18 )所示。
的相关动作通过延迟策略网络获得。梯度的更新如式( 18 )所示。
对于策略网络,对应的目标函数为:
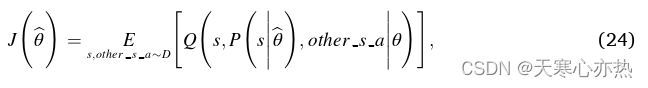
并且梯度可以计算如下:
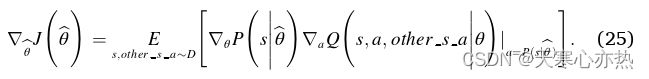
然后,梯度的最终更新也可以通过式( 21 )计算得到:
4 仿真结果与分析
在这一部分,我们进行了一系列的仿真来分析所应用的DRL算法在多智能体防御和攻击问题中的效果。我们还给出了所考虑问题的环境模型设定、评价标准、参数设置、统计分析和结果。
4.1 环境模型设定
仿真环境为一个包含N个攻击者、M个防御者和一个防御区域的二维环境。
防御者的最大速度高于攻击者的最大速度,原因在于我们的情况下攻击者比防御者多,如果没有速度优势,防御者几乎不可能连续拦截所有攻击者。此外,如果攻击者成功攻击防御区域或被被告捕获,则攻击者将停止攻击,无法再次被其他防御者捕获。最后,当没有更多的攻击者或者达到最大交互次数时,交互终止。
对于防御者,我们采用DRL模型对其进行训练,而对于攻击者,他们可以利用DRL模型进行学习或者只是按照给定的规则进行行为。对于DRL模型控制的智能体,其运动是可变的,智能体的加速度由学习模型给出,但不能超过智能体的最大速度。对于基于规则的攻击者,本文采用了以下简单但有效的规则:1 )每个智能体的速度方向直接指向防御区,保证其沿着最短路径朝着目标移动;2 )攻击者以匀速运动,其速度为最大允许速度。
4.2 评价标准及参数设置
在我们的仿真中,使用三种不同的评价标准来展示模型的性能,分别是平均攻击命中率、平均攻击成功率和平均代理累积奖励。
平均攻击命中率衡量了攻击的质量,它表示在一次对抗中能够平均命中防御区的N个攻击者的百分比。显然,对于攻击者来说,平均命中率越高越好。平均攻击命中率的具体计算如下所示,

平均攻击成功率也是对攻击质量的评价,它表示在一次对抗中能够平均击中防御区域的攻击者数量。对于该准则,只要攻击命中率大于0,则认为攻击成功。同样,对于攻击者来说,平均攻击成功率越高越好。此外,平均攻击成功率往往高于平均攻击命中率,我们定义如下,

虽然平均攻击命中率和平均攻击成功率可以直接反映对抗的结果,但不能反映模型是否真正优化。由于强化学习的目标是最大化累积奖赏,为了清晰地展示模型的优化过程,需要平均考虑对抗中的累积奖赏。平均累积奖赏的定义如下所示,

4.3 基线方法
为了进一步研究不同的DRL算法对于解决多智能体防御和攻击问题的效果,我们将基于DDPG和MADDPG的模型与以下基准算法进行比较。
独立Q学习( Independent Q-learning,IQL ) ( Tampuu等, 2017)将多智能体学习问题转化为同时存在的单智能体学习问题的集合,每个智能体通过深度Q学习独立学习一个个体动作值函数。
价值分解网络( Value Decomposition Networks,VDN ) ( Sunehag等, 2018)基于个体观测和行动,通过价值分解网络将一个中心状态-行动价值函数分解为个体状态-行动价值函数之和。
Actor Critic ( AC ) ( Mnih等, 2016)结合了仅Actor和仅Critic方法的长处。Actor网络通过近似学习一个价值函数,然后利用该价值函数向绩效改进的方向更新Actor网络。
4.4 基于规则的攻击代理的多代理防御与攻击
在基于规则的多智能体防御与攻击问题中,防御方根据学习模型进行决策,攻击者的行动通过规则给出。我们考虑四种不同的对抗环境,分别是2个防御者对2个攻击者,2个防御者对3个攻击者,3个防御者对5个攻击者,4个防御者对6个攻击者。在每种环境下,我们比较了防御方在AC、VDN、IQL、DDPG和MADDPG训练模型下的表现。
为了更直观地观察对抗过程,我们首先给出了5个基于规则的攻击者与3个基于MADDPG的防御者的对抗示例,如图5所示。
 图5 5个基于规则的攻击者和3个基于MADDPG的防御者下的对抗过程
图5 5个基于规则的攻击者和3个基于MADDPG的防御者下的对抗过程
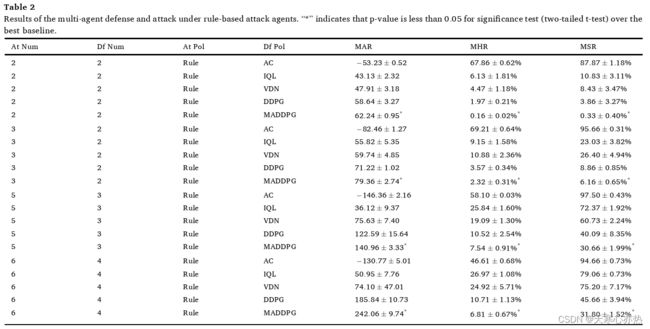
从表2可以得到以下结论。( 1 ) MADDPG在不同场景下的表现均优于其他方法,验证了MADDPG的优越性。此外,t-检验的结果表明MADDPG获得的改善是显著的。( 2 ) AC比其他方法更敏感,因为它的动作选择过程是随机的,而不是DDPG或MADDPG中的确定性动作选择。因此,AC的最终结果很差。( 3 ) VDN在学习的早期阶段可以取得较好的效果。然而,随着训练步数的增加,MADDPG和DDPG优于VDN。( 4 ) MADDPG总体上优于DDPG,表明在神经网络结构或学习算法中显式考虑其他智能体的信息可以进一步提高性能。( 5 )在我们的环境中,攻击者数量多的场景比攻击者数量少的场景更加复杂。
随着环境变得越来越复杂,基于规则的攻击者对基于DRL的防御者的攻击成功率和命中率不断提高,所有比较的方法都面临这个问题。这一缺陷主要源于两个原因。( a )环境本身的复杂性。显然,随着攻击者的增多,防御者要想成功防御所有攻击者变得更加困难。然而,我们的基于学习模型的防御者仍然能够将单个攻击者的命中率限制在相对较低的水平。( b )深度强化学习模型的代理可扩展性问题。随着Agent数量的增加,执行的策略应该与更多的Agent协作,模型的状态空间呈指数增长,这也是大多数DRL模型( Li et al . , 2019 ; Wang et al . , 2020 ; Liu et al , 2020)面临的问题。
4.5 基于DRL的攻击代理的多代理防御与攻击
在多智能体防御和基于DRL的攻击智能体攻击问题中,攻击者和防御者的行动都是通过DRL算法给出的。在本小节中,我们还研究了4种场景,分别是2个防御者对2个攻击者,2个防御者对3个攻击者,3个防御者对5个攻击者,4个防御者对6个攻击者。在每个场景中,我们同时考虑使用DDPG或MADDPG训练的智能体。图9给出了经过MADDPG训练的5名攻击者和3名防御者的对抗过程示例。
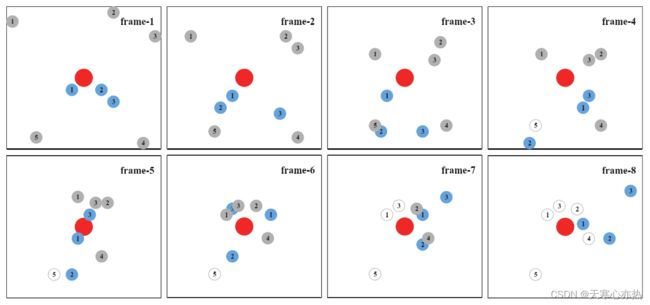 图9 5个基于MADDPG的攻击者和3个基于MADDPG的防御者的对抗过程
图9 5个基于MADDPG的攻击者和3个基于MADDPG的防御者的对抗过程
5 结论与未来工作
在本文中,我们使用深度强化学习算法处理多智能体防御和攻击问题。根据攻击代理的类型将防御和攻击问题分为两类,即基于规则的多代理防御和攻击和基于DRL的多代理防御和攻击。在这两种情况下,防御者的行为都是通过深度强化学习模型给出的。我们对DDPG和MADDPG算法中的连续状态空间、连续动作空间和奖励函数进行了改进,以更好地解决所考虑的问题。详细介绍了训练过程中DDPG和MADDPG的网络结构和学习方法。为了证明DRL训练的有效性,本文还进行了一系列的实验和比较,MADDPG的性能优于其他使用的DRL模型。
然而,本文主要针对的是少量的攻击代理和防御代理。此外,在仿真环境中只考虑攻击代理、防御代理和防御区域。在未来的工作中,我们将关注更多包含静态和动态障碍物的实际环境,以及智能体数量动态变化的情况(可扩展性)。