2024.1.7周报
目录
摘要
ABSTRACT
一、文献阅读
1、题目
2、摘要
3、模型架构
4、文献解读
一、Introduction
二、创新点
三、实验过程
四、结论
二、深度学习知识
一、从Encoder-Decoder框架中理解为什么要有Attention机制
二、Attention思想
三、Seq2Seq + Attention代码逐行实现
总结
摘要
本周,我阅读了一篇名为Named Entity Recognition with Bidirectional LSTM-CNNs的论文,其中提出了一种创新的神经网络架构。该架构采用了双向LSTM和CNN的混合模型,能够自动提取单词级和字符级的特征,从而避免了繁琐的特征工程。这一方法为实现命名实体识别提供了一种高效而精确的途径。此外,在深度学习方面,我继续学习了Attention机制。将Attention与Seq2Seq相结合,深化了对Attention思想的理解。这种结合不仅为模型提供了更全面的信息获取能力,还加强了对序列到序列学习的认识。
ABSTRACT
This week, I read a paper titled "Named Entity Recognition with Bidirectional LSTM-CNNs," which introduces an innovative neural network architecture. The architecture employs a hybrid model of bidirectional LSTM and CNN, enabling the automatic extraction of features at both the word and character levels, thereby eliminating the need for cumbersome feature engineering. This approach presents an efficient and precise method for implementing named entity recognition.
Furthermore, in the realm of deep learning, I continued to delve into the concept of Attention. Combining Attention with Seq2Seq, I deepened my understanding of the Attention mechanism. This integration not only provides the model with a more comprehensive ability to gather information but also enhances my comprehension of sequence-to-sequence learning.
一、文献阅读
1、题目
题目:Named Entity Recognition with Bidirectional LSTM-CNNs
链接:https://arxiv.org/abs/1511.08308
期刊:Computation and Language
2、摘要
文章提出了一种新的神经网络架构,这个架构可以通过使用双向LSTM和CNN的混合模型自动提取单词级和字符级的特征,避免了大量特征工程的工作。命名实体识别任务通常需要大量的外部知识,如很好的特征提取、字典等等。并且提出了词汇表部分匹配算法,通过BIOES Annotation 去对词汇表中的单词前缀后缀进行匹配。通过引入使用公共资源构建的词汇表,本文的模型在CONLL-2003数据集上取得91.62的F1值,在OneNotes数据集上取得86.28的F1值。
The paper proposes a new neural network architecture that can automatically extract word-level and character-level features using a hybrid model of bidirectional LSTM and CNN, avoiding extensive feature engineering. Named entity recognition tasks usually require a lot of external knowledge, such as good feature extraction, dictionaries, etc. It also proposes a vocabulary partial matching algorithm by matching the prefixes and suffixes of words in the vocabulary through BIOES Annotation. By introducing a vocabulary built with public resources, the model in this paper achieves an F1 score of 91.62 on the CONLL-2003 dataset and 86.28 on the OneNotes dataset.
3、模型架构

1、整个模型可以分为三个部分:特征抽取层、双向LSTM层、输出层
2、在特征抽取层中,由三个部分组成。Word Embedding是提取单词级特征,Additional Word Features是提取额外的单词特征,Char Features是使用CNN提取出来的字符级特征。最后再将这三部分concat起来。
3、在双向LSTM层中,将嵌入层得到的结果输入到双向LSTM中,分别传入输出层中。
4、在输出层中,会分别将前向LSTM和反向LSTM输入到线性层中,再分别通过softmax,最后再进行相加得到最终结果。

卷积神经网络从每个单词中提取字符特征。通过查找表计算字符嵌入和(可选的)字符类型特征向量。然后,它们被连接起来并传递给CNN。
首先通过Character Embedding提取字符级特征,再提取额外的字符特征,最后再将两者concat起来。
然后将第一步提取到的特征进行输入到卷积层中,再通过最大池化层,得到最终的CNN提取的字符级特征。
4、文献解读
一、Introduction
传统的模型,如CRF、SVM、感知机模型等,需要大量的特征工程的工作。Collobert等人在2011年提出的神经网络模型虽然解决了传统模型需要大量特征工程的缺陷,但是依然存在两个比较大的缺陷:(1)、模型使用的是简单的前馈神经网络,上下文的使用仅仅是围绕一个单词的窗口大小。(无法提取长距离单词之间的关系)(2)、模型仅仅使用了word embeddings,无法提取出更深层次的字符级特征(例如前缀、后缀,在分析不常见词的时候有用)为了处理变长序列,我们可以使用RNN模型,但是为了改变RNN无法提取长距离的依赖,衍生出了LSTM模型。一个双向的LSTM模型能够考虑单词两边的所有有用的信息。卷积神经网络已经被证实可以很好地提取字符级别的特征。本文提出了双向LSTM和CNN的混合模型用于提取单词级和字符级的特征,并且提出了字典部分匹配算法。
二、创新点
1、Capitalization Feature
由于在单词嵌入查找过程中大写信息被删除,评估Collobert 使用单独的查找表的方法,使用以下操作添加大写特征:allCaps, upperInitial, lowercase,mixedCaps, noinfo。
2、Lexicons
作者将每个 n-gram(最长的词典条目的长度)与词典中的条目进行匹配。如果 n-gram与条目的前缀或后缀匹配,且至少是条目长度的一半,则匹配成功。由于虚假匹配的可能性很大,对于除 Person 以外的所有类别,我们丢弃长度小于2个词向量的部分匹配。当同一个类别中有多个重叠的匹配时,我们更喜欢精确匹配而不是部分匹配,然后是较长的匹配而不是较短的匹配,最后是句子中较早的匹配而不是较晚的匹配。所有匹配项不区分大小写。
三、实验过程
1、数据集
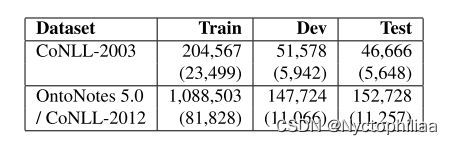
CoNLL 2003:CoNLL-2003 数据集由来自Reuters RCV1 语料库的新闻通讯社组成,语料库标记了四种类型的命名实体:位置、组织、个人和其他。由于数据集比 OntoNotes 小,我们对开发集进行超参数优化后,在训练集和开发集上对模型进行训练。
OntoNotes 5.0数据集:Pradhan 等人为 CoNLL-2012 共享任务编译了OntoNotes 5.0 数据集的核心部分,并描述了一个标准的训练/开发/测试分割,我们使用它来进行评估。继Durrett 和Klein(2014)之后,我们将我们的模型应用于具有黄金标准命名实体注释的数据集的部分;新约部分被排除在外,因为缺乏金标准的注解。这个数据集比CoNLL-2003 大得多,由各种来源的文本组成,例如广播会话、广播新闻、新闻专线、杂志、电话会话和Web文本。
2、超参数的设定
CoNLL-2003:convolution width:3,CNN output size:53,LSTM state size:275,LSTM layers:1,learning rate:0.0105,Epochs:80,Dropout:0.68,Mini-batch size:9
OntoNotes 5.0:convolution width:3,CNN output size:20,LSTM state size:200,LSTM layers:2,learning rate:0.008,Epochs:18,Dropout:0.63,Mini-batch size:9
3、评估指标
BLSTM-CNN+emb+lex模型在CONLL-2003和OntoNotes5.0数据集上的得分。
4、实验结果
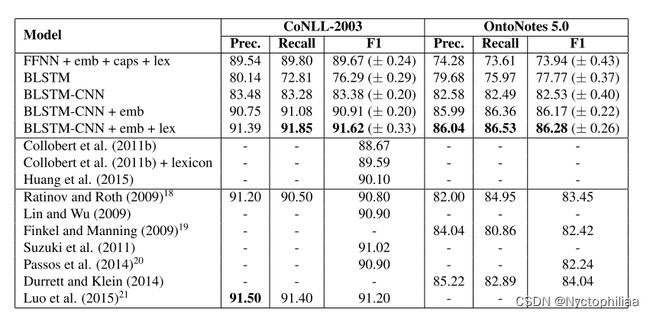
上图显示了所有数据集的结果。BLSTM-CNN+emb+lex已经超过了CoNLL-2003 和OntoNotes 先前报道的最高 F1 得分。特别是,在没有外部知识的情况下,我们的模型在CoNLL- 2003数据集上具有竞争力,并为OntoNotes 建立了一个新的技术水平,表明在给定足够的数据的情况下,神经网络可以自动学习 NER的相关特征,而无需特征工程。
四、结论
文章提出的神经网络模型包含了双向 LSTM和字符级CNN,并受益于通过 dropout 的强健的训练,实现了最先进的命名实体识别,很少的特征工程。我们的模型改进了之前在 NER的两个主要数据集上最好的报告结果,表明该模型能够从大量数据中学习复杂的关系。对部分匹配词典算法的初步评估表明,通过更灵活地应用现有的词典,可以进一步提高性能。对现有单词嵌入的评估表明,训练数据的领域与训练算法同样重要。更有效地构建和应用词汇和词汇嵌入是需要更多研究的领域。
二、深度学习知识
深度学习中的注意力和人类的注意力机制有关,比如说,面对食物的时候,我们会先辨认它的形状、颜色,随后可能会闻一闻气味,再尝一尝味道,然后确认这是一盘小酥肉。那么在认出小酥肉的这个过程中,每个阶段我们关注的内容都有所不同。在令Attention崛起的机器翻译场景中亦是如此,比如翻译“我爱你中国时”,我们会格外注意其中的一部分汉子,比如“China”。我们希望机器也能学会这种处理信息的方式,于是就有了注意力机制Attention,可以形象的理解为,注意力可以从纷繁复杂的输入信息中,找出对当前输出最重要的部分。
注意力的核心目标就是从众多信息中选择出对当前任务目标更关键的信息,将注意力放在上面。本质思想就是【从大量信息中】【有选择的筛选出】【少量重要信息】并【聚焦到这些重要信息上】,【忽略大多不重要的信息】。聚焦的过程体现在【权重系数】的计算上,权重越大越聚焦于其对应的value值上。即权重代表了信息 的重要性,而value是其对应的信息。
一、从Encoder-Decoder框架中理解为什么要有Attention机制

上图中的框架并没有体现出注意力机制,所以可以把它看做分心模型,为什么说它注意力不集中分心呢?请看Decoder部分每个单词的生成过程:

其中f是解码器的非线性变换函数,从这里我们可以看出,在生成目标句子的单词时,无论生成那个单词,他们使用的输入句子的语义编码c都是一样的,没有任何区别。
而语义编码c是由句子的每个单词经过Encoder编码产生的,这意味着不论是生成哪个单词,句子中任意单词对某个目标单词y的影响力都是相同的,就像人类的眼中没有注意力焦点是一样的 。
比如在机器翻译场景中,输入的英文句子为:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:”汤姆“、”追逐“、”杰瑞“。在翻译”杰瑞“这个单词的时候,分心模型里面每个英文单词对于翻译目标单词”杰瑞“的贡献程度是相同的,这很显然是不合道理的。显然”Jerry“对于翻译成”杰瑞“更为重要。
那么它会存在什么问题呢?类似RNN无法捕捉长序列的道理,没有引入Attention机制在输入句子较短时影响不大,但是如果输入句子比较长,此时所有语义通过一个中间语义向量表示,单词自身的信息避免不了会消失,也就是会丢失很多细节信息,这也是为何引入Attention机制的原因。
例如上面的例子,如果引入Attention的话,在翻译”杰瑞“的时候,会体现出英文单词对于翻译当前中文单词的不同程度影响,比如给出类似下面的概率分布:
每个英文单词的概率代表了翻译当前单词”杰瑞“时,注意力分配给不同英文单词的权重大小,这对于正确翻译目标单词是有着积极作用的。
目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词yi的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的Ci。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了注意力模型的Encoder-Decoder框架理解起来如下图所示:
即生成目标句子单词的过程成了下面的形式:
 而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:

其中,f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入xi后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式:

其中,Lx代表输入句子Source的长度,aij代表在Target输出第i个单词时Source输入句子中第j个单词的注意力分配系数,而hj则是Source输入句子中第j个单词的语义编码。假设下标i就是上面例子所说的“ 汤姆” ,那么Lx就是3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是0.6,0.2,0.2,所以g函数本质上就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,公式对应的中间语义表示Ci的形成过程类似下图。

二、Attention思想

- Q是query,是输入的信息;key和value成组出现,通常是原始文本等已有的信息;
- 通过计算Q与K之间的相关性a,得出不同的K对输出的重要程度;
- 再与对应的v进行相乘求和,就得到了Q的输出;
详细来说:


三、Seq2Seq + Attention代码逐行实现
一、导入依赖包
import torch
import torch.nn as nn
import torch.nn.functional as F二、seq2seq编码器
1.将输入序列input_ids通过Embedding层映射为词向量序列。
2. 将词向量序列输入到LSTM层,得到该序列在每个时刻的输出状态输出output_states。
3. 返回最后一个时刻的隐藏状态final_h,以及所有时刻的输出状态output_states。
class Seq2SeqEncoder(nn.Module):
#实现基于LSTM的编码器,也可以是RNN、GRU
def __init__(self,embedding_dim,hidden_size,source_vocab_size):
super(Seq2SeqEncoder,self).__init__()
#lstm层输入大小为embedding_dim,隐层大小为hidden_size,然后把batch_size放在首个维度
self.lstm_layer=nn.LSTM(input_size=embedding_dim,hidden_size=hidden_size,batch_first=True)
#Embedding层将输入序列input_ids映射到embedding_dim维的表示空间
self.embedding_table=nn.Embedding(source_vocab_size,embedding_dim)
def forward(self,input_ids):
#利用embedding层得到输入序列的向量表示
input_sequence = self.embedding_table(input_ids)
#输入input_sequence到LSTM层,得到所有时刻的输出状态输出output_states
output_states,(final_h,final_c) = self.lstm_layer(input_sequence)
#返回最后时刻的隐藏状态final_h,以及输出状态
return output_states,final_h三、注意力机制
1. 接收解码器当前状态decoder_state_t和编码器状态序列encoder_states作为输入。
2. 计算解码器状态与每个编码器状态的点积,得到相关性得分score。
3. 对score做softmax,得到normalize后的权重attn_prob。
4. 利用attn_prob对编码器状态加权求和,得到上下文向量context。5. 返回注意力权重attn_prob和上下文向量context。
class Seq2SeqAttentionMechanism(nn.Module):
#实现dot-product的Attention
def __init__(self):
super(Seq2SeqAttentionMechanism,self).__init__()
#接收两个参数:
#decoder_state_t: 解码器当前时刻的状态,形状为[batch_size, hidden_size]
#encoder_states: 编码器输出的状态序列,形状为[batch_size, source_length, hidden_size]
def forward(self,decoder_state_t,encoder_states):
#从encoder_states得到输入序列相关的形状信息
bs,source_length,hidden_size = encoder_states.shape
#size:[batch_size, 1, hidden_size]。
decoder_state_t=decoder_state_t.unsqueeze(1)
#size:[batch_size,source_length,hidden_size]
decoder_state_t=torch.tile(decoder_state_t,dims=(1,source_length,1))
#点乘注意力,计算解码器状态与编码器状态的点积,得到相关性得分score。计算结果为[bs,source_length]
score = torch.sum(decoder_state_t*encoder_states,dim=-1)
#softmax,对score进行softmax,得到normalize后的概率attn_prob作为注意力权重
attn_prob = F.softmax(score,dim=-1)
#利用attn_prob对编码器状态加权求和,得到上下文向量context
context = torch.sum(attn_prob.unsqueeze(-1)*encoder_states,1)
return attn_prob,context四、seq2seq解码器
1. 在__init__中定义了词向量层、LSTM计算单元、投影层、注意力层等组件。
2. forward函数实现训练模式下的解码计算。 - 将目标序列通过词向量层映射为词向量序列。
- 利用LSTM逐步解码每个时刻。
- 计算注意力权重和上下文向量。
- 将上下文向量与LSTM隐状态拼接后通过投影层计算当前时刻的logits。
- 存储每个时刻的logits和注意力权重矩阵。3. inference函数实现测试模式下的自回归解码。 - 利用start token初始化,循环调用LSTM生成隐状态。
- 计算注意力和上下文向量。
- 通过投影层计算logits,选择概率最高的词作为当前预测。
- 将预测词不断累加到结果中,直到生成结束词end_id。
class Seq2SeqDecoder(nn.Module):
def __init__(self,embedding_dim,hidden_size,num_classes,target_vocab_size,start_id,end_id):
super(Seq2SeqDecoder,self).__init__()
#LSTM的计算单元,lstm层输入大小为embedding_dim,隐层大小为hidden_size
self.lstm_cell = torch.nn.LSTMCell(embedding_dim,hidden_size)
#全连接层,将两份隐状态映射到词典大小的 logits,num_classes就是target_vocab_size
self.proj_layer = nn.Linear(hidden_size*2,num_classes)
#注意力机制
self.attention_mechanism = Seq2SeqAttentionMechanism()
#最后的分类层,词典大小,等于目标语言的词汇量target_vocab_size
self.num_classes = num_classes
#Embedding层,将输入token ID映射为embedding向量
self.embedding_table = torch.nn.Embedding(target_vocab_size,embedding_dim)
#推理时,从start id开始,一直到start end结束,两个token
self.start_id = start_id
self.end_id=end_id
def forward(self,shifted_target_ids,encoder_states):
#输入target序列id先通过Embedding层,得到对应的词向量表示shifted_target。
shifted_target = self.embedding_table(shifted_target_ids)
bs,target_length,embedding_dim = shifted_target.shape
bs,source_length,hidden_size = encoder_states.shape
#初始化存储变量,存储每个时间步的logits,用于计算损失
logits = torch.zeros(bs,target_length,self.num_classes)
#存储每个时间步的attention权重,用于可视化
probs = torch.zeros(bs,target_length,source_length)
for t in range(target_length):
decoder_input_t = shifted_target[:,t,:]
if t==0:
h_t,c_t = self.lstm_cell(decoder_input_t)
else:
h_t,c_t = self.lstm_cell(decoder_input_t,(h_t,c_t))
attn_prob,context = self.attention_mechanism(h_t,encoder_states)
decoder_output=torch.cat((context,h_t),-1)
# logits存储了每个时间步的logits输出
logits[:,t,:] = self.proj_layer(decoder_output)
# probs存储了每个时间步的attention权重矩阵
probs[:,t,:] = attn_prob
return probs,logits
def inference(self,encoder_states):
target_id = self.start_id
h_t = None
result = []
"""
- 将当前target_id通过Embedding层得到输入向量。
- 如果是第一个时间步,调用LSTM计算初始隐状态。
- 否则使用上一步的隐状态进行递归计算当前隐状态。
- 计算attention权重和上下文向量。
- 将上下文向量与隐状态拼接后通过投影层计算logits。
- 根据logits选取概率最大的词id作为当前预测目标,存储到结果列表中。
- 如果预测到end_id,终止循环。
"""
while True:
decoder_input_t = self.embedding_table(target_id)
if h_t is None:
h_t,c_t = self.lstm_cell(decoder_input_t)
else:
h_t,c_t = self.lstm_cell(decoder_input_t,(h_t,c_t))
attn_prob,context = self.attention_mechanism(h_t,encoder_states)
decoder_output = torch.cat((context,h_t),-1)
logits = self.proj_layer(decoder_output)
target_id = torch.argmax(logits,-1)
result.append(target_id)
if torch.any(target_id ==self.end_id):
print("stop decoding!")
break
predicted_ids = torch.stack(result,dim=0)
return predicted_ids五、Model
1. 在__init__中定义编码器模块encoder和解码器模块decoder。
2. forward函数定义模型的训练模式前向计算过程: - 输入源语言序列input_sequence_ids和目标语言序列shifted_target_ids。
- 通过编码器模块获得编码器状态encoder_states。
- 将编码器状态传入解码器模块。
- 解码器模块输出注意力权重probs和预测的logits。
- 返回probs和logits。3. infer函数预留了模型的推理模式下前向计算的接口。
class Model(nn.Module):
def __init__(self,embedding_dim,hidden_size,num_classes,source_vocab_size,target_vocab_size,start_id,end_id):
super(Model,self).__init__()
self.encoder=Seq2SeqEncoder(embedding_dim,hidden_size,source_vocab_size)
self.decoder=Seq2SeqDecoder(embedding_dim,hidden_size,num_classes,target_vocab_size,start_id,end_id)
"""
def forward():
- 定义模型的前向计算过程。
- input_sequence_ids:源语言序列。
- shifted_target_ids:目标语言序列(向后偏移一位)。
- 通过编码器模块获得编码器状态。
- 通过解码器模块获得attention权重和预测logits。
- 返回attention权重probs和预测logits。
"""
def forward(self,input_squence_ids,shifted_target_ids):
encoder_states,final_h=self.encoder(input_sequence_ids)
probs,logits = self.decoder(shifted_target_ids,encoder_states)
return probs,logits
def infer(self):
pass六、 验证
通过定义模型和输入,示例代码实现了一次Seq2Seq模型的前向传播过程,并打印出attention概率矩阵和预测logit矩阵的大小,验证了Seq2Seq模型的训练模式下的前向计算流程。
input_sequence_ids: shape=(2, 3),源语言序列
target_ids: shape=(2, 4),目标语言序列shifted_target_ids: 在target_ids前面添加start_id,shape=(2, 5)
正向传播计算probs和logits:
encoder编码input_sequence_ids得到编码器状态
decoder解码shifted_target_ids,在编码器状态条件下生成目标序列
probs表示attention概率矩阵,shape=(2, 5, 3)logits表示预测的logits,shape=(2, 5, 10)5. 打印输出大小:
probs size: torch.Size([2, 5, 3])
logits size: torch.Size([2, 5, 10])
if __name__ == '__main__':
source_length=3
target_length=4
embedding_dim=8
hidden_size=16
num_classes=10
bs = 2
start_id=end_id=0
source_vocab_size=100
target_vocab_size=100
#源序列的ids
input_sequence_ids = torch.randint(source_vocab_size,size=(bs,source_length)).to(torch.int32)
target_ids = torch.randint(target_vocab_size,size = (bs,target_length))
target_ids = torch.cat((target_ids,end_id*torch.ones(bs,1)),dim=1).to(torch.int32)
shifted_target_ids = torch.cat((start_id*torch.ones(bs,1),target_ids[:,1:]),dim=1).to(torch.int32)
model = Model(embedding_dim, hidden_size, num_classes, source_vocab_size, target_vocab_size, start_id, end_id)
probs, logits = model(input_sequence_ids, shifted_target_ids)
print(probs.shape)
print(logits.shape) 说明我们的计算过程是正确的。
说明我们的计算过程是正确的。
总结
通过定义模型和输入,示例代码实现了一次Seq2Seq模型的前向传播过程,并打印出attention概率矩阵和预测logit矩阵的大小,验证了Seq2Seq模型的训练模式下的前向计算流程。通过对seq2seq+attention的逐行代码实现,让我对seq2seq+attention的理解更深。