《游戏引擎架构》知识点合集-3.游戏软件工程基础
跳过第二章直接梳理第三章的原因是第二章主要讲的是工具向内容,一方面详细地介绍了版本控制软件Subversion/TortoiseSVN和IDE:Visual Studio的使用技巧,另一方面简单介绍了函数时间占用相关剖析器,内存泄漏、内存损坏的原理和相应的检测工具。此方面工具向内容不做过多搬运,感兴趣的小伙伴可自行查阅第二章内容。
面向对象编程
类/对象
类是属性和行为的集合(class includes variables and functions)。描述类的各别实例即是对象。比如一条叫阿旺的狗是“dog”类的一个实例。类和实例之间存在一对多的关系。
封装
对象向外提供有限接口,隐藏内部状态和实现细节。
继承
延申现有的类用来定义新类。新类可延申/修改现有类的数据/接口/行为。延伸类和现有类是“is-a”关系。比如圆形是一个形状,狗是一个动物。
书中将这一概念简单延申至“多重继承”的概念。多重继承指新类继承至一个或以上的父类。这种设计会造成代码混淆且复杂(继承结构由树状变成图状),其中一个原因则是如果A继承自B和C,而B和C继承自同一个类D,则会出现菱形继承的问题,导致实例化A时会实例化两个D。多重继承同样会使类型转换变得复杂。因此尽量避免使用多继承,或者只允许多重继承一些简单且无父类的类。
多态
多态指用单一共同接口操作不同类型的对象。比如调用Shape.Draw()来操作继承自Shape的Circle、Rectangle,它们即便不是相同的绘制方法,却可以通过调用同一个接口来实现。
合成与聚合
合成/聚合:has-a/use-a关系。比如太空船有一台引擎,汽车有一台发动机。善用合成/聚合,避免滥用继承。
设计模式
同一类型问题有相似的方案去解决。游戏工业有自己的一套设计模式,比如渲染、碰撞、动画、音频等等。
编码标准
本书笔者认为其存在的主因:
1.使代码易读、易理解、易维护。
2.预防程序员自找麻烦。比如上方说的多重继承这种,明明可以换个其他方案来避免的。
本书笔者最起码的编码标准:
1.保持接口(.h)文件清晰明了易懂。
2.命名方法统一易懂,坚持使用能直接反映类、函数、变量用途的直观名字。
3.善用命名空间,有一定的命名空间规范,宏命名时更需小心,因为它仅仅是文本替换。
4.通过书籍找到最好的编程语言实践技巧。
5.坚持遵守编码规定。
6.坚持写最简洁的代码,即能很容易地暴露出常见的编程错误的代码。
C/C++的数据、代码及内存
这期间讲了很多C++11本身的特性,因这些知识太局限于c++而非程序员大众都需了解的知识,在此略过。
基本数据类型
char:8位。
int:有符号数值。32位CPU架构上被定义为32位,64位CPU架构上被定义为64位。
short:多数情况下是16位。比int短。
long:多数情况下是32位或64位,取决于CPU架构、编译选项、目标操作系统。比int长。
float:32位。
double:64位。
bool:从不会实现为1位。有些编译器定义为8位,有些定义为32位。
流水线、缓存及优化
与游戏性能优化有关的硬件知识。
并行泛型转移
早期计算机中,CPU相对较慢,程序员集中优化于降低任务所花费的CPU周期数目。而时至今日,CPU性能的提升速度高于内存访问的提升速度,致使现在普遍的优化方式是在CPU上做更多工作,避免访问内存。
内存缓存Cache
缓存不过是另一组内存,但CPU读写缓存比主存要快得多。原因:1.采用如今最快及最贵的技术。2.物理上缓存置于离CPU核心最近的地方。
通过cache提升内存访问性能的方法是,将程序最常使用的数据块保存至cache的局部拷贝。若CPU请求的数据已存在于缓存中,缓存就能非常快速地完成请求(缓存命中);否则就必须从主内存读入缓存(缓存命中失败)而带来非常高的开销。
缓存的内存地址和主内存的地址为简单的一对多关系。比如主内存是一个小区,每一户人家作为一个单元,那么缓存就是记载着某几幢的单元信息本。这个小区一共有40幢,而信息本最多情况只能记载5幢的信息,当我们想查找第10幢第4户单元的家庭信息,发现本子上没有,就要把本子上某一幢的所有信息替换成第十幢,然后再找第4户单元的具体信息。从这里可以发现,缓存的某一块位置,可能会对应主内存的多块位置。
缓存有个缓存线的概念,而且缓存只能处理与缓存线大小倍数对齐的内存地址,类比于上方描述的(某一幢的所有信息)。也就是说缓存是以缓存线而非字节作为索引单元(要写缓存,就得把这一幢楼里所有信息都写进去),这样做能有效提高缓存命中(程序常见情况就是顺序访问内存,就好比上方例子中我知道了第10幢第4户单元的家庭信息后就想要知道第10幢第8户单元的信息了)。

数据和代码都可能会被置于缓存内,一个被称为指令缓存(预载即将执行的机器码),另一个被称为数据缓存(加速从主内存读/写数据)。大多数处理器会在物理上独立分开这两种缓存。
前面描述的缓存例子为简单的映射,即直接映射缓存(每个地址仅映射单条缓存线)。存在的问题是如果有新的数据请求A没有在缓存中出现,就要覆写数据B;但下一次又要请求B,此时覆写A之后又请求A。。。可能就会导致两个不相关的内存块可能不断来回相互逐出。有一个方式就是组关联,比如2路组关联,一个内存映射至2个缓存线(也就是保证一个缓存中有两份一样的主内存数据)。

替换策略:如果有多路“缓存路”,当缓存命中失败发生时,根据CPU替换策略来挑选某一路进行缓存覆写操作。常见操作即是逐出最“老”(距离上次调用时间最长)的数据。
写入策略:有两种主流,一种是写入缓存时立即写入内存;另一种是先写入缓存,当这个缓存线即将被清理/覆写的时候再写回内存。
有多级缓存的概念来提高命中率,游戏过程中若在一级缓存中没有获得想要的数据则找二级缓存,依此类推。
我们需要做的就是尽可能提高缓存命中率,其中最佳办法就是把数据编排进连续的内存块中,尺寸越小越好,并且要顺序访问这些数据。
指令流水线和超纯量CPU
这两者能增强CPU内的并行性。
流水线指的是CPU的一个指令周期,通常情况下CPU完成一条指令会分为n个步骤,独自完成其中m个步骤时其实可以继续下一个指令的步骤而非傻等。
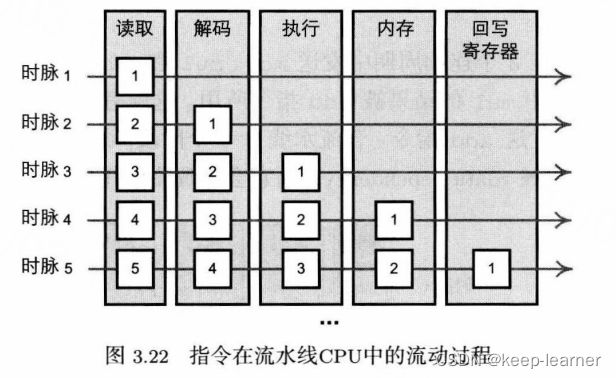
超纯量指的是多组冗余电路,可以使CPU并行处理多个指令,比如多个证书算术逻辑单元,CPU可同时执行2个整数指令。
“数据依赖”可能会令流水线产生一个“气泡”,降低吞吐量,即流水线停顿。原因是这一条数据会用到上一条数据的结果,导致不能并行运算。比如书中一个例子:第三条指令add r1,7,r2用到了第二条指令的结果r1,所以要等待第二条指令全部完成了才能开始第三条指令的第一个读取步骤。
