一键了解获取网页requests方式
目录
一、爬虫原理:
二、安装:
测试:
三、文件的操作
方式一
方式二:
方式三
四、认识User-Agent
4.1、为什么用User-Agent:
步骤:
五、请求方式
5.1、get
5.2、post
六、爬出有中国关键字页面案例
一、爬虫原理:
代码发起请求 获取到请求的网页的源码,从源码里面筛选内容
二、安装:
第一步:在终端运行安装命令
pip install requests第二步:导入模块
import requests写好会报错说明没有安装
测试:
resp=requests.get("https://www.baidu.com")
print(resp)输出 响应码200,即代表请求成功

三、文件的操作
r 读取 w 写入 a 追加 b 二进制 + 又读又写
open打开文件夹
mode模式
encoding编码方式
方式一
file=open('a.html',mode='w+',encoding='utf-8')
# 放内容
file.write("")
# 关闭
file.close()方式二:
不用手动关闭,自动关闭
with open('a.html',mode='w+',encoding='utf-8') as f:
f.write("")方式三
# 百度的数据保存到网页中
file=pathlib.Path('a.html')
# 写入
file.write_text("hello world",encoding='utf-8')
# 如果文件不存在,就点touch
file.touch()四、认识User-Agent
4.1、为什么用User-Agent:
发现爬下来的百度不一样,而且访问不了----->反爬虫的策略
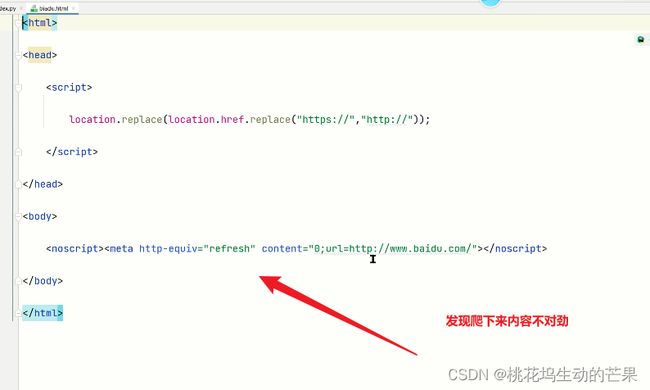


步骤:
找到浏览器的标识:右键----检查----网络----请求头----User-Agent(网页上的请求,都会带它)
把浏览器标识带上就会以为我们是正常标识,
注:可以发现标识在请求头中
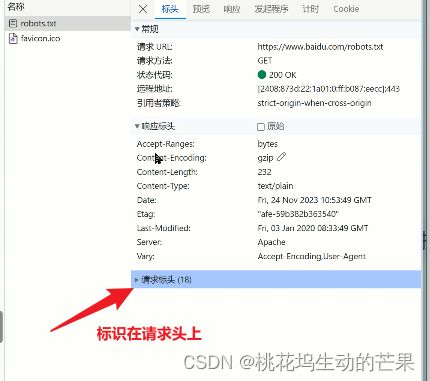
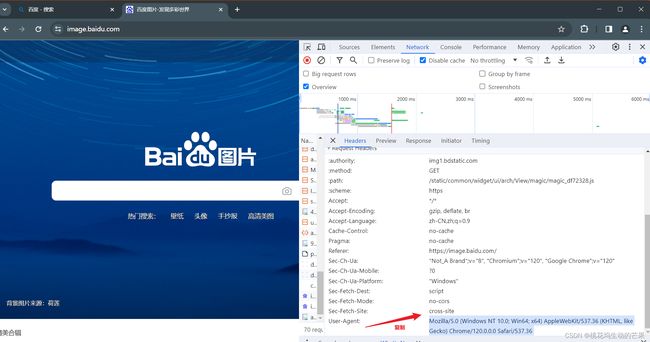
可以看见爬下来的效果


五、请求方式
5.1、get

requests.get(url)
url是请求的地址
params请求携带的参数
headers请求头
resp是响应对象
resp.text响应内容
resp.json响应内容,格式是json,把数据变成字典对象 resp.content是二进制内容(响应主题)
resp.status_code响应编码
应用场景:想知道访问是否失败了
例如:
if resp.status_code==200:
内容
案例:
resp = requests.get("https://www.baidu.com", headers={
# 把复杂的东西粘贴下来
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 '
'Safari/537.36 '
})
if resp.status_code == 200:
# 保存
file = pathlib.Path("baidu.html")
file.write_text(resp.text, encoding='utf-8')5.2、post

data要带的数据
resp响应的内容
import pathlib
import requests
resp = requests.post("http://www.baidu.com", data={
"key": 123
}, headers={
# 让它觉得我是浏览器
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 '
'Safari/537.36 '
})
if resp.status_code == 200:
# 保存
file = pathlib.Path("baidu2.html")
file.write_text(resp.text, encoding='utf-8')六、爬出有中国关键字页面案例
# https://www.baidu.com/s?ie=utf-8&wd=%E4%B8%AD%E5%9B%BD
# params用传参的方式
根据地址栏分析


resp = requests.get(url="https://www.baidu.com/s", params={
"wd": "中国"
}, headers={
#让它觉得我是浏览器
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
})
# 防止报错
resp.encoding = 'utf-8'
# 保存
# file文件
file = pathlib.Path("zg.html")
# 写入内容
file.write_text(resp.text, encoding='utf-8')