ConcurrentHashMap分段锁
1.分段锁的设计目的
ConcurrentHashMap 是支持高并发的线程安全的 HashMap。相较于 HashTable 使用 synchronized 方法来保证线程安全,ConcurrentHashMap 采用分段锁的方式,在线程竞争激烈的情况下 ConcurrentHashMap 的效率高很多。
ConcurrentHashMap 中的分段锁称为 Segment,它的内部结构是维护一个 HashEntry 数组,同时 Segment 还继承了 ReentrantLock。
当需要 put 元素的时候,并不是对整个 ConcurrentHashMap 进行加锁,而是先通过 hashcode 来判断它放在哪一个分段中,然后对该分段进行加锁。所以当多线程 put 的时候,只要不是放在同一个分段中,就可以实现并行的插入。分段锁的设计目的就是为了细化锁的粒度,从而提高并发能力。
2.分段锁的实现
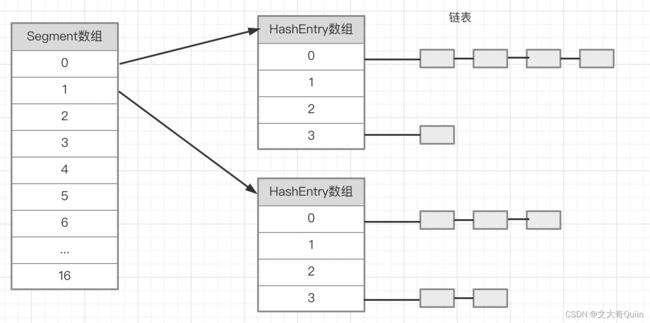
ConcurrentHashMap 数据结构模型
ConcurrentHashMap 中维护着一个 Segment 数组,Segment 中有维护着一个 HashEntry 的数组,所以 ConcurrentHashMap 的底层数据结构可以理解为:数组 + 数组 + 链表
public class ConcurrentHashMap extends AbstractMap
implements ConcurrentMap, Serializable {
private static final long serialVersionUID = 7249069246763182397L;
// 分段数组,每一段都是一个 hash 表
final Segment[] segments;
} static final class Segment extends ReentrantLock implements Serializable {
// 每段中的表
transient volatile HashEntry[] table;
} 
ConcurrentHashMap 分段锁的实现
ConcurrentHashMap 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程操作不同的分段,就不会存在锁竞争,提高并发访问率。
Segment 本身就继承了 ReentrantLock 具备了锁的功能,在每次 put 前都会先尝试 tryLock() 加锁,如果成功则进行元素存储;如果失败,就会调用 Segment 的 scanAndLockForPut() 尝试循环加锁并扫描指定的 key。
下面从 put 的源码中看分段锁的具体实现:
public class ConcurrentHashMap extends AbstractMap
implements ConcurrentMap, Serializable {
public V put(K key, V value) {
Segment s;
// 判断 value 是否为 null ,为 null 则直接抛出空指针异常
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// 获取分段锁的下标
int j = (hash >>> segmentShift) & segmentMask;
// 从 Segment 数组中获取该下标的分段对象
if ((s = (Segment)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
// 如果分段不存在则创建一个新的分段
s = ensureSegment(j);
// 调用 Segement 的 put 方法
return s.put(key, hash, value, false);
}
} static final class Segment extends ReentrantLock implements Serializable {
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 获取锁,如果获取成功则创建一个临时节点 node = null,如果获取失败,则调用 scanAndLockForPut 循环获取
HashEntry node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry[] tab = table;
// 获取在分段中的索引
int index = (tab.length - 1) & hash;
// 根据索引获取链表的首节点
HashEntry first = entryAt(tab, index);
// 遍历链表
for (HashEntry e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
// 遍历完未找到相同的 key
else {
// 将新节点设置为链表头
if (node != null)
node.setNext(first);
else
node = new HashEntry(hash, key, value, first);
int c = count + 1;
// 判断是否需要扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
// 扩容
rehash(node);
else
// 更新数组
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// 释放锁
unlock();
}
// 如果 key 存在,更新 value,返回旧 value
return oldValue;
}
private HashEntry scanAndLockForPut(K key, int hash, V value) {
HashEntry first = entryForHash(this, hash);
HashEntry e = first;
HashEntry node = null;
int retries = -1;
// 如果第一次获取锁就成功,则直接返回一个 node = null
while (!tryLock()) {
HashEntry f;
// 遍历一次链表,后面检查到链表被其他线程修改,会重新遍历
if (retries < 0) {
if (e == null) {
if (node == null)
node = new HashEntry(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
// 尝试获取的次数大于 64,则加互排锁,并结束循环
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
// 尝试的次数为偶数时判断一下,是否链表被其他线程改变,如果修改了,则重新遍历
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f;
retries = -1;
}
}
return node;
}
private void scanAndLock(Object key, int hash) {
// similar to but simpler than scanAndLockForPut
HashEntry first = entryForHash(this, hash);
HashEntry e = first;
int retries = -1;
while (!tryLock()) {
HashEntry f;
if (retries < 0) {
if (e == null || key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f;
retries = -1;
}
}
}
} put的完整流程

3.JDK1.8中的ConcurrentHashMap
jdk1.8 中的 ConcurrentHashMap 中废弃了 Segment 锁,直接使用了数组元素,数组中的每个元素都可以作为一个锁。在元素中没有值的情况下,可以直接通过 CAS 操作来设值,同时保证并发安全;如果元素里面已经存在值的话,那么就使用 synchronized 关键字对元素加锁,再进行之后的 hash 冲突处理。
jdk1.8 的 ConcurrentHashMap 加锁粒度比 jdk1.7 里的 Segment 来加锁粒度更细,并发性能更好。