Transformer论文--Attention Is All You Need
原文链接:Attention is All you Need
文章概述
目前主要的序列传导模型基于复杂的循环或卷积神经网络,包括encoder and a decoder。作者提出了仅依赖于注意力机制的的一种新的简单网络结构(Transformer),在机器翻译任务中与其他模型相比,该模型展现了更高的并行计算量同时大大减少了训练时间。并在WMT 2014 English-to-German比赛中BLEU值达到了28.4,比其他模型(包括集成模型)高出2个BLEU值。在WMT 2014 English-to-French比赛中达到了单一模型的最高记录(BLEU为41)。
介绍
对于循环模型,通常是沿输入到输出的方向来考虑,当前位置的输出不仅要依赖于当前层的的输入函数,还需要考虑先前位置的输出状态。这种序列化严重限制了计算的并行性,虽然目前能通过因式分解和条件计算来提高序列模型的效率,但序列模型最根本的限制仍然存在(即模型间固有的输入输出顺序限制了样例的并行),这篇文章提出的Transformer避免了递归的架构,依赖于注意力机制来得到输入和输出间全局依赖关系,显著提升了并行程度。
方法
该模型结构如下图所示,基于self-attention机制和点积,对encoder和decoder进行全连接。
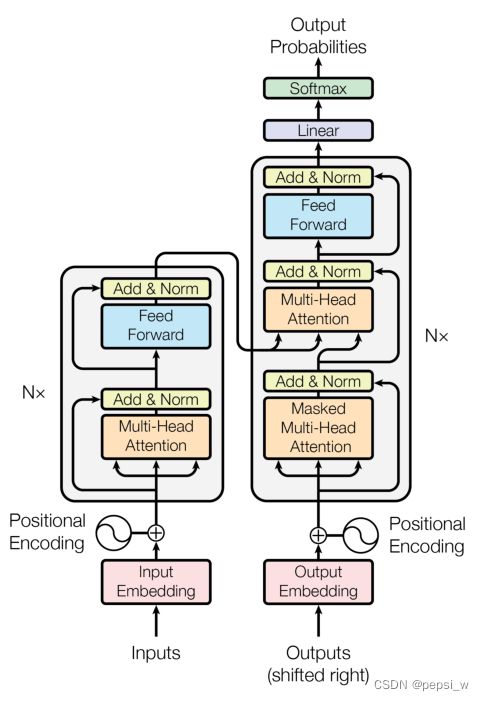
图1 transformer模型架构
encoder-decoder 架构
encoder:由N=6个相同层组成,每个层中包含两个子层(如图1中的左部分)。第一层是Multi-Head Attention,第二层是一个位置全连接层网络。作者使用残差连接两子层,并加入了layer normalization,每子层的输出为:LayerNorm(x + Sublayer(x)),其中Sublayer(x) 是子层本身的函数。
decoder:同encoder一样,由N=6个相同层组成,除了encoder中的两个子层,另外还有一个子层使用Multi-Head Attention来对encoder的输出进行关注(如图1中的右部分)。跟encoder相似,在每个子层中使用残差连接,并加入layer normalization。但这里引入了Mask来对后续序列进行保护,保证对位置i的预测仅依赖于i前面的输出。
注意力机制
注意函数是将查询键和一组键值对映射到输出的一个函数,其中查询Q、键K、值V 和输出都是向量。其中输出是V的一个加权和,其权重等价于查询Q与键K之间的相似度,如图2左部分所示。虽然K和V保持不变,但查询Q改变时,分配到V的权重就会发生改变,导致输出也会改变。

图2 点乘注意力机制和多头注意力
注意力机制常用两种机制:加法和点乘,虽然在理论上这两种函数复杂度都是差不多的,但在实际中点乘运算速度更快并且更节省空间。作者提出在dk(查询Q和键K的维度)值较小的时候这两种函数表现差不多,但dk值较大时加法注意力要优于点乘注意力,作者认为这是因为dk越大点积就越大,梯度就会越小,可能会导致softmax的梯度消失。本文中为了抵消这种影响将点乘*1/√dk 在一定程度上控制了点积的大小。输出矩阵的计算为:

如图2右部分所示,Multi-Head Attention将V、Q、K通过一个线性层投影到低维,然后做h次scaled dot product ,最后把每个函数的输出拼接到一起再次投影,得到输出。多头注意使得模型能够在不同位置共同关注来自不同表示子空间的信息(有点类似CNN的多个输出通道),具体公式如下:

在本文中,一共在三个地方使用了多头注意力机制。第一个是“encoder-decoder attention” 层中,查询Q是来自 前面masked multi-head attention 的输出,键K和值V来自 encoder 的输出,这里是允许解码层中的每个位置都能去注意输入序列的所有位置。第二个是在编码层中的self-attention层,允许编码层中的每个位置能注意上一层中的所有位置。第三个是在解码层中的self-attention,允许解码器中的每个位置关注到解码器中之前的所有位置(这里是因为masked的作用)。
前馈网络
除了注意力子层,在每个编码器和解码器前面都有两个线性层和一个ReLU变换:

Embeddings和softmax
与其他序列转换模型类似,Transformer使用Embedding将输入和输出的token转换为向量,并使用线性变换和softmax将解码器的输出转换为预测的下一个概率。在Transformer的两个嵌入层之间共享相同的权矩阵和softmax线性变换。在嵌入层中,作者将这些权重乘以√dmodel
位置编码
输出output是值V的加权和(权重是查询Q和键K之间的距离,和序列信息无关),为了保证有序性使用位置编码,作者考虑了两种方法,一种是正弦余弦波,一种是position embedding。 在本文中选择了前者来作为位置编码,因为其能够推断出比训练遇到的额序列更长的序列。计算公式如下,(其中位置为pos,维度为i)
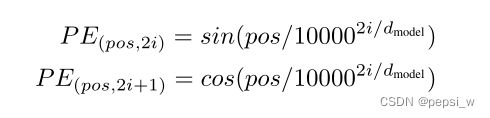
实验
这里使用了Adam训练器,学习率也根据以下公式进行调整:即在第一个warmup_steps训练步骤中线性增加学习率,此后按步骤数的反平方根比例减少。这里warmup_steps = 4000。
分别在WMT 2014 English-German和WMT2014 English-French数据集上进行训练,结果如下表所示:

可以看出作者提出的Transformer模型在EN-DE数据集上优于之前所有的模型,big版达到了目前最好的结果28.4,比之前的结果高出2个点。在EN-FR数据集上超越了之前的单一模型,并且训练成本也远低于它们。
本文中作者还对该模型的一些变形进行了实验,具体结果如下所示:

结论
本文提出了第一个完全基于注意力机制的序列模型,用Multi-Head Attention取代了encoder-decoder架构中最常用的递归层。并在在翻译任务上表现出很好的效果。作者提到未来会将该注意力模型运用于其他方面,如图像、音频的处理。