深入理解 Hadoop (四)HDFS源码剖析
HDFS 集群启动脚本 start-dfs.sh 分析
启动 HDFS 集群总共会涉及到的角色会有 namenode, datanode, zkfc, journalnode, secondaryName 共五种角色。

JournalNode 核心工作和启动流程源码剖析
// 启动 JournalNode 的核心业务方法
public void start() throws IOException {
// 第一件事:创建 JournalNode 的本地工作目录
// /home/bigdata/data/journaldata/hadoop330ha
for (File journalDir : localDir) {
validateAndCreateJournalDir(journalDir);
}
// 第二件事: 创建和启动 JournalNode 的 Http 服务,绑定端口 8480
httpServer = new JournalNodeHttpServer(conf, this, getHttpServerBindAddress(conf));
httpServer.start();
// 第三件事: 创建和启动 JournalNode 的 RPC 服务 JournalNodeRpcServer,绑定端口 8485
rpcServer = new JournalNodeRpcServer(conf, this);
rpcServer.start();
}
最重要的需要关注 JournalNodeRpcServer,将来 NameNode 在进行一个事务操作,需要记录日志的时候,会把日志记录到 NameNode 的本地,并发送日志到所
有的 JournalNode,当 NameNode 本地记录成功,并且 JournalNode 中的成功过半,才认为这条事务的日志记录是成功的。
// 1、JournalNodeRpcServer 实现了两个协议:QJournalProtocol 和 InterQJournalProtocol
// 2、QJournalProtocol 是 NameNode 和 JournalNode 之间的通信协议
// 3、InterQJournalProtocol 是 JournalNode 之间进行沟通的协议
public class JournalNodeRpcServer implements QJournalProtocol, InterQJournalProtocol {
// NameNode 发送命令让 JournalNode 开启一个新的日志段 LogSegment
public void startLogSegment(RequestInfo reqInfo, long txid, int layoutVersion){
jn.getOrCreateJournal(....).startLogSegment(reqInfo, txid, layoutVersion);
}
// NameNode 发送 LogEdit 给 JournalNode
public void journal(RequestInfo reqInfo, long segmentTxId, long firstTxnId, int numTxns, byte[] records){
jn.getOrCreateJournal(....).journal(reqInfo, segmentTxId, firstTxnId, numTxns, records);
}
}
ZKFC 核心工作原理和启动源码剖析
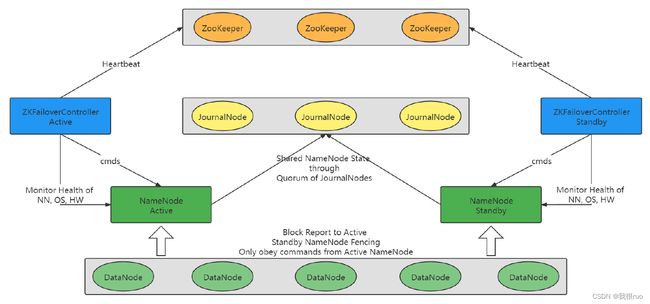
关于 ZKFC 的工作流程:
- 建立和 ZK 的链接,创建锁节点的父节点。
- 启动一个监控 NameNode 健康状态的线程。
- 启动 RPCServer,将来可能会出现集群中有两个 standby 但是没有 active,集群重启,手动切换其中一个 namenode 为 active。
hdfs haadmin --transitionToActive nn2
- ZKFC 尝试创建锁节点,参与 active 选举,方式就是通过 基于 zk 的分布式独占锁来执行选举。
- 当选举成功,自己先更新状态,然后通过 RPC 告知 namenode 切换状态。
- 选举不成功,则注册监听,监听 active namenode 的状态。
HDFS NameNode 启动全流程源码剖析
创建和启动 HttpServer
加载磁盘元数据构建 FSNamesystem
FSNamesystem 是 NameNode 的内部最重要的三大组件之一 (第一个是 HttpServer2,第二个是 RpcServer,第三个就是 FSNameSystem 了)。FSNamesystem 负责 NameNode 里面的一切元数据相关的相关工作。在 NameNode 启动的过程中,需要恢复磁盘元数据到内存中:
1、构建 FSImage。
2、构建 FSNamesystem,FSImage 作为 FSNamesystem 内部非常重要的组件来完成磁盘元数据维护, 在内部会构建 FSDirectory。
3、通过 FSNamesystem 去恢复元数据。
创建 NameNode RPC 服务
NameNodeRpcServer 的内部启动的 RPCServer 事实上有三个:
- serviceRpcServer:接受来自于 DataNode 的 RPC 请求进行处理。
- lifelineRpcServer:默认没有配置,不启动。
- clientRpcServer:接受来自于 Client 的 RPC 请求进行处理。
启动 RPCServer 和工作线程
HDFS 的元数据管理
HDFS 元数据管理全貌

关于上图中的几种角色关于 元数据处理 相关的工作:
- 客户端:发送请求:会涉及更新系统状态的请求,事务请求。都会记录日志,所以 NameNode 接收到该请求,就会执行一个事务:更新内存 + 记录磁盘日志
- NameNode:执行事务,事务成功,必须是以下三件事都成功:
- 更新元数据到内存数据结构 FSDirectory 中 + 写日志到磁盘中
- 写日志到 Active NameNode 本地磁盘文件中 edits_inprogress_txid 文件中
- 写日志到 Journal 系统: 发送 RPC 请求将日志发送给所有的 JournalNode 等待过半的 JournalNode 写成功
- JournalNode:在启动的时候,其实它内部启动了一个 JouranlNodeRpcServer,接收来自于 active NameNode 的 journal RPC 请求记录日志到本地
- Standby NameNode 做两件事:
- EditLogTailer:每隔一段时间,从 journal 系统中拉取日志数据,然后合并到 standby namenode 的内存中,其实 standby namenode 的内存中也有一份几乎最新状态的元数据存在。
- StandbyCheckpointer 线程:每隔一段时间,做一次判断,检查是否要执行 checkpoint。
- checkpoint 条件:常规的条件一般有三种:
- 日志条数 : 100W(HDFS 条件之一)
- 时间:1个小时(HDFS 条件之一)
- 日志文件大小: 1G
- 执行过程
- 发送 RPC 请求个 Active NameNode,通知要进行一次 元数据checkpoint:做一件事:rollLog(edits_inprogress_txid 变成 edits_starttxid_endtxid)
- StandbyNameNode 去到 Active NameNode 中下载 fsiamge 文件和 edits 文件
- 在 StandbyNameNode 的内存中,进行 fsimage 和 edits 文件的合并,生成一个最新的 fsimage
- StandbyNameNode 上传该 fsimage 文件给 active NameNode
- 补充说明:下载和上传 fsiamge 或者 edits 都是通过 Http 方式
- checkpoint 条件:常规的条件一般有三种:
HDFS 完成创建文件夹全流程源码分析
重点:DistributedFileSystem
HDFS 更新内存元数据完整剖析
重点:FSDirectory
FSEditlog 双写缓冲机制
重点:FSEditLog —— 双写缓冲 + 分段加锁
FSEditlogAsync 异步写机制
重点:FSEditLogAsync —— react 模式
NameNode 启动元数据恢复源码深度剖析
核心:加载磁盘元数据,恢复到内存中。
- 加载 fsimage 文件到内存
- 加载 edits 文件到内存
HDFS 元数据 Checkpoint 工作流程和源码分析

先下载 editLog,然后校验 txId 是否连续,连续则使用本地的 fsImage,否则去 active NameNode 下载最新的 fsImage。
HDFS DataNode 启动和上传数据全流程
HDFS DataNode 启动全流程分析
- 主类 DataNode
- 通过 instantiateDataNode() 方法创建 DataNode
- 通过 runDatanodeDaemon() 方法启动 DataNode
创建 DataNode 实例
在启动 DataNode 的过程中,大致的工作:
- 构建 DataNode 实例对象
- 启动 DataNode
- 创建 DataNode 内部的 DataXceiverServer
- 创建 DataNode 内部的 HttpServer
- 创建 DataNode 内部的 RPCServer
- 创建 ErasureCodingWorker 和 BlockRecoveryWorker
- 创建 BlockPoolManager 来完成 DataNode 向 NameNode 注册、心跳和数据块汇报

DataNode 实例启动
其实启动的时候,就是启动:
- BlockPoolManager 启动:向 NameNode 注册,并且维持心跳
- DataXceiveServer 服务启动:用来接收 文件上传过程中 Client 发送过来的数据
- RPCServer 启动
BPServiceActor 的 run() 方法中有两个重要方法:
- 第一个方法 connectToNNAndHandshake():DataNode 完成和 NameNode 的链接,然后向 NameNode 执行注册
- 第二个方法 offerService():启动 BPOfferServer 和 BPServiceActor 来让 DataNode 可以不停的向 NameNode 进行心跳和数据块汇报
DataXceiver 初始化和启动
数据传输过程中:每个 datanode 中都有一个 DataXceiverServer 的这样一个组件:启动起来,等待客户端的链接请求,如果接收到连接器请求,完成链接建立,然后构建一个新的线程,专门对这个客户端提供服务。—— 实为 BIO 服务,等待客户端连接。
DataNode 向 NameNode 注册
DataNode 向 NameNode 执行注册的实现在 BPServiceActor.connectToNNAndHandshake() 方法中完成。
心跳机制
HeartBeatManager 内部启动了一个 HeartBeatManager.Monitor 的线程来每隔 5s 钟执行一次判断,如果发现某个 datanode 的上一次心跳时间距离现在超过 30s 了,则启动检查机制,每隔5min 检查一次。最多检查两次。当 两次检查时间 + 10次心跳时间,都没有发现 datanode 复活,就认为这个 datanode 死掉了
最终的答案: 630s
DataNode 向 NameNode 心跳
DataNode 执行向 NameNode 的心跳和块汇报,一个 BPServiceActor 负责和一个 NameNode 进行通信。
DataNode 会每隔 3s 钟向 NameNode 发送心跳信息,得到的反馈是 NameNode 下发给 DataNode 需要执行的命令。
DataNode 向 NameNode 数据块汇报
全量汇报同样会返回 NameNode 下发给 DataNode 需要执行的命令。
全量汇报默认每 6 小时执行一次。
HDFS 上传数据全流程源码分析
概述

整个文件上传的过程的精髓,就在三句代码:
- 初始化得到本地输入流,读取本地文件数据
InputStream in = srcFS.open(src);
- 初始化得到目标文件系统输出流,用于完成数据输出
OutputStream out = dstFS.create(dst, overwrite);
(1)发送 RPC 请求到 NameNode 创建 INodeFile 文件节点。
(2)创建输出流,其实内部最重要的事情,就是初始化 DataStreamer。
(3)启动 输出流内部的 DataStreamer 线程。
(4)如果 DataStreamer 消费到 dataQueue 中的一个 packet,其实会做一个判断,检查是否 SETUP_STAGE,是则要创建 pipline。
精髓:DFSOutputStream 的内部藏着 DataStreamer 线程,它负责消费 dataQueue 队列,当执行数据传输的时候,通过本地输入流读取本地文件数据,构造 Packet 数据包加入到 dataQueue 队列的时候,DataStreamer 就负责发送 Packet 到多个 DataNode 建立的 pipline 数据管道之上完成数据传输。
3. 完成数据输出
IOUtils.copyBytes(in, out, conf, true);
(1)执行本地输入流数据读取,构造 Packet 加入到 dataQueue 中,其中需要注意的是:Packet 是由很多 Chunk 组成的。
(2)发送 RPC 请求给 NameNode 申请一个 Block,NameNode 会调用 BlockPlacementPolicy 副本存放策略选取 DataNode 列表返回给客户端。
(3)客户端根据上一步拿到的该 Block 的 DataNode 列表建立数据传输管道。
Client ==> DataNode01 ==> DataNode02 ==> DataNode03
(4)客户端启动 ResponseProcessor 线程用来处理 DataNode 反馈回来的 Packet 的 ACK
(5)从 dataQueue 弹出 Packet, 加入到 ackQueue,执行 Packet 发送
(6)如果一个 Block 的最后一个数据块发送完了,则等待该 Block 的 ACK
(7)结束一个数据块
(8)如果结束了上一个数据块,并且当前文件没有上传完毕,意味着继续接收到了新的 Packet,再次申请 BLock 建立数据管道,完成数据传输。

HDFS 创建文件元数据
NameNode 中负责完成内存元数据管理的就是 FSNameSystem 中的 FSDirectory ,具体实现,就是构建一个 INodeFile 包含要上传的文件的各种信息,然后添加到目录树中的指定文件夹下,并且加入 INodeMap 进行管理维护,方便以后根据 path 来索引。同时也记录了操作日志到磁盘元数据中。
最后构建了一个 HdfsFileStatus 返回给客户端,包含了该文件的各种必要信息,比如 文件路径,文件大小,副本个数,数据块大小,权限等。
启动 DataStramer 线程
DFSOutputStream 类继承结构。

精髓:DFSClient 在创建文件的输入输出流 DFSOutputStream 的时候,其实是在内部构造了一个 DataStreamer 线程,内部维护了一个 dataQueue 数据 Packet 队列。当真正执行数据传输的时候,其实就是本地输入流读取本地文件数据构造数据包 Packet 加进 dataQueue 队列,这样的话,DataStreamer 就可以从dataQueue 队列中获取 Packet 执行数据发送了。注意区分:
- 如果 BlockConstructionStage 为 PIPELINE_SETUP_CREATE 的时候(DataStreamer 刚创建,和上一个 Block 刚完成传输)则需要向 NameNode 申请 Block,并且构建 Client 到 DataNode1 到 DataNode2 到 DataNode3 的数据传输管道。并且 启动 ResponseProcessor 线程用来处理 Packet ACK 消息。
- 如果数据管道存在,则获取到的 Packet 执行正常发送即可。
- pepline 建立应用到了状态模式
至此,本地输入流和 HDFS 输出流创建完成。可以认为把文件上传相关准备工作都做到位了,接下来开始进行真正数据传输。
创建 Packet
HDFS 的客户端在进行文件上传的时候,会创建本地文件输入流,创建 HDFS 文件输出流。然后对接起来完成数据传输,具体实现通过 FIleUtils 的 copy 方法来实现的。
- 最终创建的输出流是: HdfsDataOutputStream,是 FSDataOutputStream 的子类,继承关系如图所示:

- 在创建 FSDataOutputStream 的时候,会调用父类构造,传入 PositionCache 输出流给父类,保存在父类 FilterOutputStream 的成员变量 OutputStream 的 out 上。
- 当开始进行数据传输调用 HdfsDataOutputStream 的 write() 方法,HdfsDataOutputStream 类中并没有定义 write 方法,所以其实最终调用的就是 DataOutputStream 的 write(byte b[], int off, int len) 方法来实现的,而该方法的内部实现,都是调用成员变量 OutputStream out 来实现的。
- 由第二步知道:out 就是 PositionCache。所以最后的结论:
- 当调用 HdfsDataOutputStream.write(byte b[], int off, int len) 就是调用 PositionCache.write(byte b[], int off, int len) 方法。
- 另外补充一点:PositionCache 内部包装了 DFSOutputStream,所以中还是通过 DFSOutputStream 来完成数据输出。而 DFSOutputStream 是 FSOutputSummer 的子类。终于找到了 write 方法的具体实现。
关于如何写一个 Packet 是通过 DFSOutputStream 的 writeChunk() 方法不断写 Chunk 构建出来的,最后添加到 DataStreamer 中的 dataQueue 队列中,由 DataStreamer 线程完成 Packet 数据包发送。
DFSClient 申请 Block
当 DFSOutputStream 构建一个 Packet 提交到 DataStreamer 内的 dataQueue 队列时,会唤醒阻塞在 dataQueue 的 DataStreamer 线程。DataStreamer 线程从 dataQueue 获取出来一个数据 Packet 执行发送,这时候需要判断,这个 Packet 执行发送的时候,BlockConstructionStage 的值是什么。如果是 PIPELINE_SETUP_CREATE,意味着是这个 Packet 是新的 Block 的第一个 Packet,则需要申请 Block 获取 DataNode 存储列表,然后建立数据管道进行数据传输。
总体来说,就是 DFSClient 发送 RPC 请求给 NameNode 申请一个该 File 的一个 Block,在 NameNode 内部主要做两件事:
- 首先根据默认副本存放策略实现 BlockPlacementPolicyDefault 选举副本个数 DataNode。
- 构建一个 BlockInfo 对象加入到 FIle 的 blocks 数组中,同时编号并记录 offset,然后将必要的信息封装成 LocatedBlock 返回给 DFSClient(必要的信息包含上一步获取的 DataNode)。
建立数据管道
DFSClient 向 NameNode 申请到一个 Block,NameNode 给 DFSClient 返回了该 Block 的 DataNode 存储列表,然后 DFSClient 就着手建立 Client 和 多个 DataNode 之间的数据传输管道了。
DFSClient 中,构建了 Socket 客户端,并且发起链接给 DataNode 启动的 DataXceiver 服务端,建立连接,然后构建输入输出流用于传输数据。最后 DFSClient 端构建了一个 Sender 线程用来完成向 DataNode 发送数据。最后构建 Sender 线程,通过 writeBlock() 发送请求相关数据。
注意:Sender 实现了 DataTransferProtocol,但是 DataTransferProtocol 并不是标准的 Hadoop RPC 通信协议,而是单独实现的一套用来传输数据的协议。
Sender 作为客户端发送 writeBlock RPC 请求,DataXceiver 作为服务端处理 RPC 请求。
- 当 DataNode 启动的时候,创建和启动了一个用于做数据传输的一个 服务端: DataXceiverServer
- 当 Client 申请到一个 Block 拿到了 3 个datanode 列表,需要去建立数据传输管道
- client 生成一个 socket 客户端,发起链接请求给 第一个datanode: 建立连接之后, 会接收到上游发送下来的操作代号: OP_WRITE。处理逻辑其实就是构建一个 BlockReceiver用来专门接收数据
- 生成一个 block 文件
- 构建这个 block 的文件输出流
- 如果 targets 长度不为 0,则表示下游依然有 DataNode,则起一个 Sender 继续向下游发送数据。生成一个socket ,发起链接请求给 下一个 datanode, 那么 datnaode 中的 DataXceiverServer 也是构建一个 DataXceiver 来完成相关工作
- 否则数据管道即构建成功。
DataNode 接收数据和发送 ACK
DataNode 中的 BlockReceiver 的职责就是负责接收数据块,并且发送数据 Packet 给下游 DataNode 然后给上游 DataNode 返回 ACK。大概的工作机制:
- 读取上游发送过来的数据。
- 如果存在下游 DataNode 的话,则把读取到的 Packet 发送给下游 DataNode。
- 执行数据 write to disk 的操作。
- 给上游返回 SUCCESS 标识。
PacketResponder 线程
PacketResponder 就是 DataNode 负责处理 ACK 的,从下游 DataNode 接收 ACK 发给上游 DataNode。
ResponseProcessor线程
从下游 DataNode 上读取 ACK 消息进行处理,如果 Packet 成功,则从 ackQueue 中进行移除。
HDFS 契约机制
当一个客户端想要去操作某个 HDFS 文件的时候,首先要获取该文件的 契约,然后能写入数据。而且同一时间,只能有一个客户端获取契约。如果其他客户端没有获取到契约,就只能等着别人释放。
具体的工作机制:
客户端在写文件过程中,会开启一个线程,不停的发送请求给 NameNode 进行文件续约。
NameNode 端也有一个专门的检测线程,负责监控各个契约的续约时间。如果某个契约长时间没有续约,则删除,从而让别的客户端有机会能写该 文件。
关于契约机制的源码解析:
- 第一步:NameNode 在启动的时候,会创建和启动 LeaseManager 进行工作。
- 第二步:当客户端发送 RPC 请求给 NameNode 创建一个文件的时候,NameNode 会给该客户端生成一个 Lease 加入到 NameNode 中启动的 LeaseManager 中进行管理。
- 第三步:当 DFSClient 客户端获取到了 HDFS 某个文件的输出流之后,就开启一个线程,用来不停的去申请续约。
综上所述,这个功能就是为了让操作该文件的 客户端保持独占,类似于一把锁的作用。
HDFS 文件上传的容错机制
关于异常处理,有两种方式:
- 如果宕机的 datanode 大于一半,则丢弃刚才的 block,重新申请 block 和 datanode 列表,完全推倒重来。
- 如果宕机的 datanode 不足一半,则直接忽略,用剩下的 datanode 列表来构建 pipline。
HDFS 文件下载全流程分析
HDFS 文件下载入口代码
其实 HDFS 文件上传和下载的入口是一样的,关键就看输入流,输出流的不同了。
最终还是通过 FileUtil 来完成 输入流 到 输出流 上的数据传输的,最后依然进入到 FileUtils 的 copy() 方法。
依然是三个重点:
- 创建 HDFS 文件输入流
- 创建本地文件系统输出流
- 执行数据传输
数据读取客户端操作
当真正要读取数据的时候,是通过 in.read(buf); 驱动的,这个 in 的 read() 功能最终就是 DFSInputStream 完成的。
数据读取服务端操作
当服务端收到 客户端的读取数据的请求,最终还是由 DataXceiver 来完成的。
最大的特色就是,会通过操作系统预读来加速数据读取(内部涉及到零拷贝支持),从而提高吞吐。
源码阅读总结
设计模式
命令模式
- DataNode 心跳、块汇报给 NameNode,NameNode 会将待执行命令发送给 DataNode。
- RPC 通信中封装的 Call 对象也可以看做是命令模式。
装饰者模式
- HDFSDataInputStream、FSDataInputStream (DFSInputStream) 对输入、输出的调用。
组合模式
- HDFS 的文件系统功能实现。
- NameNode 的功能实现。
- ResourceManager 的功能实现。
迭代器模式
- BatchedRemoteIterator
状态模式
- pepline 建立。