4.4 媒资管理模块 - 分布式任务处理介绍、视频处理技术方案
媒资管理模块 - 视频处理
文章目录
- 媒资管理模块 - 视频处理
- 一、视频转码
-
- 1.1 视频转码介绍
- 1.2 FFmpeg 基本使用
-
- 1.2.1 下载安装配置
- 1.2.2 转码测试
- 1.3 工具类
-
- 1.3.1 VideoUtil
- 1.3.2 Mp4VideoUtil
- 1.3.3 测试工具类
- 二、分布式任务处理
-
- 2.1 分布式任务调度
- 2.2 XXL-JOB 配置执行器 中间件
- 2.3 搭建XXL-JOB
-
- 2.3.1 调度中心
- 2.3.2 执行器
- 2.3.3 执行任务
- 2.4 XXL-JOB 高级配置参数
- 2.5 分片广播
-
- 2.5.1 分片广播事例
- 三、视频处理
-
- 3.1 技术方案
-
- 3.1.1 作业分片方案
- 3.1.2 保证任务不重复执行
- 3.1.3 视频处理方案
一、视频转码
1.1 视频转码介绍
视频转码是指的对视频文件的编码格式进行转换
视频上传成功需要对视频的格式进行转码处理,比如:avi转成mp4
一般做文件存储的服务都需要对文件进行处理,例如对视频进行转码处理,可能由于文件量较大需要使用多线程等技术进行高效处理

文件格式:是指.mp4、.avi、.rmvb等 这些不同扩展名的视频文件的文件格式
视频文件的内容主要包括视频和音频,其文件格式是按照一 定的编码格式去编码,并且按照该文件所规定的封装格式将视频、音频、字幕等信息封装在一起,播放器会根据它们的封装格式去提取出编码,然后由播放器解码,最终播放音视频
音视频编码格式:通过音视频的压缩技术,将视频格式转换成另一种视频格式,通过视频编码实现流媒体的传输
目前最常用的编码标准是视频H.264,音频AAC
比如:
一个.avi的视频文件原来的编码是a,通过编码后编码格式变为b,
音频原来为c,通过编码后变为d
1.2 FFmpeg 基本使用
1.2.1 下载安装配置
我们Java程序员只需要调用流媒体程序员写的工具类即可完成对视频的操作,这个工具可能是c或c++写的
流媒体程序员:专门做视频处理类的东西
FFmpeg开源工具被许多开源项目采用,QQ影音、暴风影音、VLC等
下载链接:https://www.ffmpeg.org/download.html#build-windows


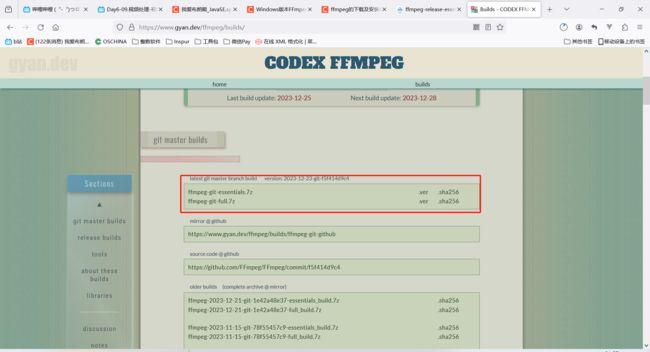
最终下载之后三个exe文件

查看是否安装成功
ffmpeg -v

也可以把ffmpeg.exe文件配置在path环境变量中

现在我们就可以在任意一个位置执行命令了

1.2.2 转码测试
将avi文件转换成mp4文件
ffmpeg.exe -i avi测试视频.avi 1.mp4


转成mp3
ffmpeg -i xxx.avi xxx1.mp3
转成gif
ffmpeg -i xxx.avi xxx1.gif
1.3 工具类
在xuecheng-plus-base工程添加此工具类
这份工具类其实就是流媒体程序员进行提供的
其实我们需要的是怎么调用ffmpeg.exe文件
1.3.1 VideoUtil
/**
* 此文件作为视频文件处理父类,提供:
* 1、查看视频时长
* 2、校验两个视频的时长是否相等
*
*/
public class VideoUtil {
String ffmpeg_path = "D:\\Program Files\\ffmpeg-20180227-fa0c9d6-win64-static\\bin\\ffmpeg.exe";//ffmpeg的安装位置
public VideoUtil(String ffmpeg_path){
this.ffmpeg_path = ffmpeg_path;
}
//检查视频时间是否一致
public Boolean check_video_time(String source,String target) {
String source_time = get_video_time(source);
//取出时分秒
source_time = source_time.substring(0,source_time.lastIndexOf("."));
String target_time = get_video_time(target);
//取出时分秒
target_time = target_time.substring(0,target_time.lastIndexOf("."));
if(source_time == null || target_time == null){
return false;
}
if(source_time.equals(target_time)){
return true;
}
return false;
}
//获取视频时间(时:分:秒:毫秒)
public String get_video_time(String video_path) {
/*
ffmpeg -i lucene.mp4
*/
List<String> commend = new ArrayList<String>();
commend.add(ffmpeg_path);
commend.add("-i");
commend.add(video_path);
try {
ProcessBuilder builder = new ProcessBuilder();
builder.command(commend);
//将标准输入流和错误输入流合并,通过标准输入流程读取信息
builder.redirectErrorStream(true);
Process p = builder.start();
String outstring = waitFor(p);
System.out.println(outstring);
int start = outstring.trim().indexOf("Duration: ");
if(start>=0){
int end = outstring.trim().indexOf(", start:");
if(end>=0){
String time = outstring.substring(start+10,end);
if(time!=null && !time.equals("")){
return time.trim();
}
}
}
} catch (Exception ex) {
ex.printStackTrace();
}
return null;
}
public String waitFor(Process p) {
InputStream in = null;
InputStream error = null;
String result = "error";
int exitValue = -1;
StringBuffer outputString = new StringBuffer();
try {
in = p.getInputStream();
error = p.getErrorStream();
boolean finished = false;
int maxRetry = 600;//每次休眠1秒,最长执行时间10分种
int retry = 0;
while (!finished) {
if (retry > maxRetry) {
return "error";
}
try {
while (in.available() > 0) {
Character c = new Character((char) in.read());
outputString.append(c);
System.out.print(c);
}
while (error.available() > 0) {
Character c = new Character((char) in.read());
outputString.append(c);
System.out.print(c);
}
//进程未结束时调用exitValue将抛出异常
exitValue = p.exitValue();
finished = true;
} catch (IllegalThreadStateException e) {
Thread.currentThread().sleep(1000);//休眠1秒
retry++;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
System.out.println(e.getMessage());
}
}
}
return outputString.toString();
}
public static void main(String[] args) throws IOException {
String ffmpeg_path = "D:\\Program Files\\ffmpeg-20180227-fa0c9d6-win64-static\\bin\\ffmpeg.exe";//ffmpeg的安装位置
VideoUtil videoUtil = new VideoUtil(ffmpeg_path);
String video_time = videoUtil.get_video_time("E:\\ffmpeg_test\\1.avi");
System.out.println(video_time);
}
}
1.3.2 Mp4VideoUtil
public class Mp4VideoUtil extends VideoUtil {
String ffmpeg_path = "D:\\Program Files\\ffmpeg-20180227-fa0c9d6-win64-static\\bin\\ffmpeg.exe";//ffmpeg的安装位置
String video_path = "D:\\BaiduNetdiskDownload\\test1.avi";
String mp4_name = "test1.mp4";
String mp4folder_path = "D:/BaiduNetdiskDownload/Movies/test1/";
public Mp4VideoUtil(String ffmpeg_path, String video_path, String mp4_name, String mp4folder_path){
super(ffmpeg_path);
this.ffmpeg_path = ffmpeg_path;
this.video_path = video_path;
this.mp4_name = mp4_name;
this.mp4folder_path = mp4folder_path;
}
//清除已生成的mp4
private void clear_mp4(String mp4_path){
//删除原来已经生成的m3u8及ts文件
File mp4File = new File(mp4_path);
if(mp4File.exists() && mp4File.isFile()){
mp4File.delete();
}
}
/**
* 视频编码,生成mp4文件
* @return 成功返回success,失败返回控制台日志
*/
public String generateMp4(){
//清除已生成的mp4
// clear_mp4(mp4folder_path+mp4_name);
clear_mp4(mp4folder_path);
/*
ffmpeg.exe -i lucene.avi -c:v libx264 -s 1280x720 -pix_fmt yuv420p -b:a 63k -b:v 753k -r 18 .\lucene.mp4
*/
List<String> commend = new ArrayList<String>();
//commend.add("D:\\Program Files\\ffmpeg-20180227-fa0c9d6-win64-static\\bin\\ffmpeg.exe");
commend.add(ffmpeg_path);
commend.add("-i");
// commend.add("D:\\BaiduNetdiskDownload\\test1.avi");
commend.add(video_path);
commend.add("-c:v");
commend.add("libx264");
commend.add("-y");//覆盖输出文件
commend.add("-s");
commend.add("1280x720");
commend.add("-pix_fmt");
commend.add("yuv420p");
commend.add("-b:a");
commend.add("63k");
commend.add("-b:v");
commend.add("753k");
commend.add("-r");
commend.add("18");
// commend.add(mp4folder_path + mp4_name );
commend.add(mp4folder_path );
String outstring = null;
try {
ProcessBuilder builder = new ProcessBuilder();
builder.command(commend);
//将标准输入流和错误输入流合并,通过标准输入流程读取信息
builder.redirectErrorStream(true);
Process p = builder.start();
outstring = waitFor(p);
} catch (Exception ex) {
ex.printStackTrace();
}
// Boolean check_video_time = this.check_video_time(video_path, mp4folder_path + mp4_name);
Boolean check_video_time = this.check_video_time(video_path, mp4folder_path);
if(!check_video_time){
return outstring;
}else{
return "success";
}
}
}
上面的代码中大多数是参数封装,真正调用FFmpeg的是下面几行
ProcessBuilder builder = new ProcessBuilder();
builder.command(commend);
//将标准输入流和错误输入流合并,通过标准输入流程读取信息
builder.redirectErrorStream(true);
Process p = builder.start();
1.3.3 测试工具类
我们可以测试一下,比如打开一下“咪咕视频”
public static void main(String[] args) throws IOException {
ProcessBuilder builder = new ProcessBuilder();
//启动一下我本地的咪咕视频(路径中尽量不要含有中文)
builder.command("D:\\soft\\MiguVideo\\MiGuApp.exe");
//将标准输入流和错误输入流合并,通过标准输入流程读取信息
builder.redirectErrorStream(true);
Process p = builder.start();
}

可以在此类中执行main函数调用一下此工具类是否能完成视频转码
public static void main(String[] args) throws IOException {
//ffmpeg的路径
String ffmpeg_path = "";//ffmpeg的安装位置
//源avi视频的路径
String video_path = "";
//转换后mp4文件的名称
String mp4_name = "";
//转换后mp4文件的路径
String mp4_path = "";
//创建工具类对象
Mp4VideoUtil videoUtil = new Mp4VideoUtil(ffmpeg_path,video_path,mp4_name,mp4_path);
//开始视频转换,成功将返回success
String s = videoUtil.generateMp4();
System.out.println(s);
}
二、分布式任务处理
2.1 分布式任务调度
什么是任务调度?
下面的场景就是一个调度方案
-
每隔24小时执行数据备份任务。
-
12306网站会根据车次不同,设置几个时间点分批次放票。
-
某财务系统需要在每天上午10点前结算前一天的账单数据,统计汇总。
-
商品成功发货后,需要向客户发送短信提醒。
任务调度:对任务的调度,它是指系统为了完成特定业务,基于给定时间点,给定时间间隔或者给定执行次数自动执行任务
我们可以将一个视频的转码理解为一个任务的执行,如果视频的数量比较多,如何去高效处理一批任务呢?
- 多线程
多线程是充分利用单机的资源。
- 分布式加多线程
充分利用多台计算机,每台计算机使用多线程处理。每台计算机都在同时运行指定任务处理
方案2可扩展性更强,并且是一种分布式任务调度的处理方案。
什么是分布式任务调度?
通常任务调度的程序是集成在应用中的,
比如:优惠卷服务中包括了定时发放优惠卷的的调度程序,
结算服务中包括了定期生成报表的任务调度程序
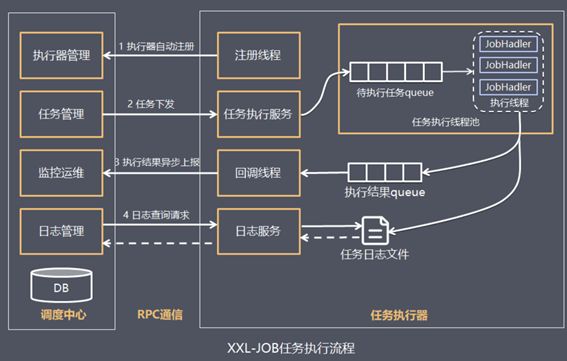
由于采用分布式架构,一个服务往往会部署多个冗余实例来运行我们的业务,在这种分布式系统环境下运行任务调度,我们称之为分布式任务调度,如下图:

分布式调度要实现的目标:
不管是任务调度程序集成在应用程序中,还是单独构建的任务调度系统,如果采用分布式调度任务的方式就相当于将任务调度程序分布式构建,这样就可以具有分布式系统的特点,并且提高任务的调度处理能力:
1、并行任务调度
并行任务调度实现靠多线程,如果有大量任务需要调度,此时光靠多线程就会有瓶颈了,因为一台计算机CPU的处理能力是有限的。
如果将任务调度程序分布式部署,每个结点还可以部署为集群,这样就可以让多台计算机共同去完成任务调度,我们可以将任务分割为若干个分片,由不同的实例并行执行,来提高任务调度的处理效率。
2、高可用
若某一个实例宕机,不影响其他实例来执行任务。
3、弹性扩容
当集群中增加实例就可以提高并执行任务的处理效率。
4、任务管理与监测
对系统中存在的所有定时任务进行统一的管理及监测。让开发人员及运维人员能够时刻了解任务执行情况,从而做出快速的应急处理响应。
5、避免任务重复执行
当任务调度以集群方式部署,同一个任务调度可能会执行多次
比如在上面提到的电商系统中到点发优惠券的例子,就会发放多次优惠券,对公司造成很多损失,所以我们需要控制相同的任务在多个运行实例上只执行一次
2.2 XXL-JOB 配置执行器 中间件
我们只需要编写任务的执行逻辑即可,其他的部分都在中间件中
XXL-JOB是一个轻量级分布式任务调度平台
其核心设计目标是开发迅速、学习简单、轻量级、易扩展。
现已开放源代码并接入多家公司线上产品线,开箱即用。
官网:https://www.xuxueli.com/xxl-job/
文档:https://www.xuxueli.com/xxl-job/#%E3%80%8A%E5%88%86%E5%B8%83%E5%BC%8F%E4%BB%BB%E5%8A%A1%E8%B0%83%E5%BA%A6%E5%B9%B3%E5%8F%B0XXL-JOB%E3%80%8B
XXL-JOB主要有调度中心、执行器、任务:
调度中心:
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码;
主要职责为执行器管理、任务管理、监控运维、日志管理等
调度中心其实就是一个管理者
任务执行器:
负责接收调度请求并执行任务逻辑;
只要职责是注册服务、任务执行服务(接收到任务后会放入线程池中的任务队列)、执行结果上报、日志服务等
任务执行器相当于分布式部署,两个执行器相当于两个人执行
**任务:**负责执行具体的业务处理。

执行流程:
- 任务执行器根据配置的调度中心的地址,自动注册到调度中心
调度中心要知道自己下面有多少个任务执行器
- 达到任务触发条件,调度中心下发任务
调度中心会根据任务的调度策略来下发任务
- 执行器基于线程池执行任务,并把执行结果放入内存队列中、把执行日志写入日志文件中
任务执行器可能会执行多个任务,所以要先将任务放入线程池中
- 执行器消费内存队列中的执行结果,主动上报给调度中心
任务执行器将执行结果异步上报给调度中心
也就是能够在调度中心里面必须能够拿到几点几分几秒,哪个执行器执行任务是成功还是失败的
- 当用户在调度中心查看任务日志,调度中心请求任务执行器,任务执行器读取任务日志文件并返回日志详情
其实就是调度中心主动查询任务执行器执行的任务是成功还是失败
2.3 搭建XXL-JOB
调度中心负责给执行器下发任务,执行器负责执行任务
2.3.1 调度中心
首先下载XXL-JOB
GitHub:https://github.com/xuxueli/xxl-job
码云:https://gitee.com/xuxueli0323/xxl-job
项目使用2.3.1版本: https://github.com/xuxueli/xxl-job/releases/tag/2.3.1

如果想本地运行的话,我们需要修改一些参数才可以运行

包结构
xxl-job-admin:调度中心
xxl-job-core:公共依赖
xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用)
:xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;
:xxl-job-executor-sample-frameless:无框架版本;

进入xxl-job
http://192.168.101.65:8088/xxl-job-admin/toLogin
账号:admin
密码:123456


2.3.2 执行器
在调度中心创建一个执行器
配置执行器,执行器负责与调度中心通信接收调度中心发起的任务调度请求
创建“执行器管理”,如下图所示

此时没有一个java程序在执行任务,知识创建了一个执行器而已

因为我们要在media工程的media-service工程中使用xxl-job,所以在media-service的pom文件中增加下面这个坐标
我们的执行器就是在media-service工程中编写
我们现在的目的是让执行器注册到调度中心,我们添加之后就注册到调度中心了
<dependency>
<groupId>com.xuxueligroupId>
<artifactId>xxl-job-coreartifactId>
dependency>
在nacos下的media-service-dev.yaml下配置xxl-job
我们配置上坐标后还不能说是完整的注册到调度中心了,我们还需要告诉它调度中心在哪里,所以就需要下面调度中心的配置了
注意配置中的appname这是执行器的应用名
调度中心要给执行器下发任务,那执行器肯定得启动一个服务
port是执行器启动的端口,如果本地启动多个执行器注意端口不能重复。执行器启动起来后,调度中心会调用它
xxl:
job:
admin:
addresses: http://192.168.101.65:8088/xxl-job-admin
executor:
appname: testHandler
address:
ip:
port: 9999
logpath: /data/applogs/xxl-job/jobhandler
logretentiondays: 30
accessToken: default_token
将下面的配置复制到media-service工程
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
*
* org.springframework.cloud
* spring-cloud-commons
* ${version}
*
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}
最终结果如下图所示

2.3.3 执行任务
为什么要配置执行器呢?
我们要让执行器执行任务
那我们怎么告诉执行器来执行什么样的任务呢?
如下图所示的地方有个事例,拷贝到我们自己的工程中

第一步:定义任务类
/**
* XxlJob开发示例(Bean模式)
*
* 开发步骤:
* 1、任务开发:在Spring Bean实例中,开发Job方法;
* 2、注解配置:为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。
* 3、执行日志:需要通过 "XxlJobHelper.log" 打印执行日志;
* 4、任务结果:默认任务结果为 "成功" 状态,不需要主动设置;如有诉求,比如设置任务结果为失败,可以通过 "XxlJobHelper.handleFail/handleSuccess" 自主设置任务结果;
*
* @author xuxueli 2019-12-11 21:52:51
*/
/**
* 任务类
*/
@Component
public class SampleXxlJob {
private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);
/**
* 执行器拿到任务后就会执行这个方法
* 具体的任务方法
*/
@XxlJob("demoJobHandler") //任务名称是demoJobHandler
public void demoJobHandler() throws Exception {
System.out.println("处理视频.....");
//任务执行逻辑...
}
/**
* 执行器拿到任务后就会执行这个方法
* 具体的任务方法
*/
@XxlJob("demoJobHandler2")
public void demoJobHandler2() throws Exception {
System.out.println("处理文档.....");
//任务执行逻辑....
}
}
第二步:调度中心中注册任务
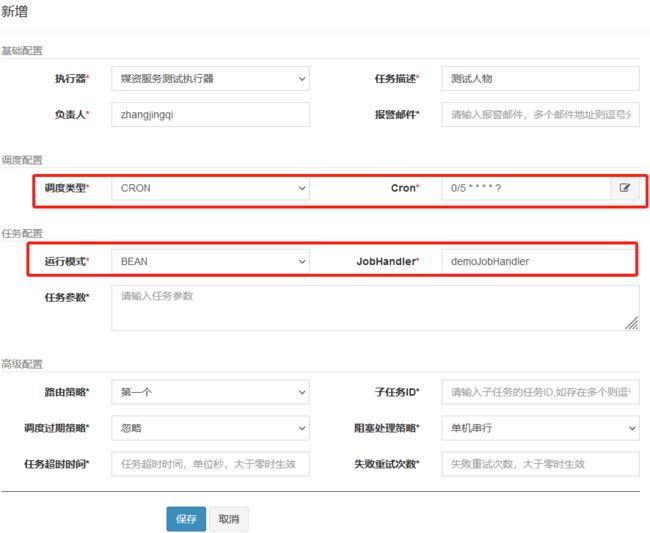
调度类型:
- 固定速度:每隔多长时间进行调度
CRON:不仅可以配置每隔多长时间,还可以配置年月日时分秒


cron = “0/30 * * * * ?”
- 从第0秒开始,每间隔30秒执行1次
- 秒 分 时 日 月 周
- 以秒为例
- *:每秒都执行
- 1-3:从第1秒开始执行,到第3秒结束执行
- 0/3:从第0秒开始,每隔3秒执行1次
- 1,2,3:在指定的第1、2、3秒执行
- ?:不指定
- 日和周不能同时制定,指定其中之一,则另一个设置为?
30 10 1 * * ? 每天1点10分30秒触发
0/30 * * * * ? 每30秒触发一次
* 0/10 * * * ? 每10分钟触发一次
第三步:启动任务

第四步:观察控制台

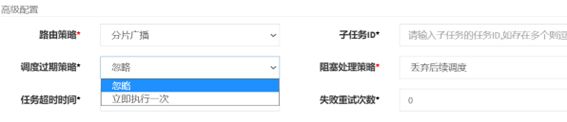
2.4 XXL-JOB 高级配置参数
XXL-JOB分布式调度平台包括调度中心和执行器,我们刚刚已经在media-service工程中创建了一个执行器,但是分布式任务调度要有多个执行器来执行任务,所以我们需要把执行器至少部署两个节点
怎么部署至少两个节点呢?
将media-api工程运行两个即可
怎么让XXL-JOB调度多个集群(即多个执行器)进行执行任务呢?
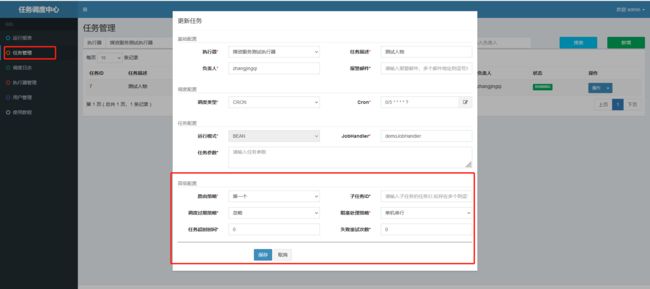
其实就是刚刚任务管理中的这些配置
-
路由策略:
我们有一个调度中心,三个任务执行器
当我们规定的任务调度时间到了后调度中心就会下发任务,但是现在面临一个问题,这个任务分发给哪个任务执行器?
这就需要我们配置路由策略了
第一个:每次都会下发给第一个任务执行器
最后一个:每次都会下发给第最后一个任务执行器
轮训:每个人轮着来
一致性HASH:我们的任务有一个id,会求此id的hash值,并且此hash值一定会是执行器中的其中一个
最不经常使用:最不经常执行任务的执行器
最近最久未使用:最近最不经常执行任务的执行器
故障转移:任务路由策略选择"故障转移"情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
忙碌转移:某个执行器任务挺多或者正在忙,就会发送给其他执行器
分片广播:执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务;
除了分片广播之外,都是一个任务由一个执行器进行执行,不能将执行能力发挥到最大
分片广播可以实现将任务同时发送给多个任务执行器

-
子任务ID
不经常使用
当执行完一个任务又想执行第二个任务,此时第二个任务就是第一个任务的子任务

-
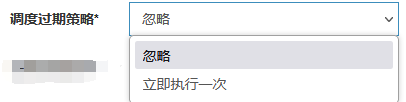
调度过期策略
到了改调度的时候不知道什么原因没有调度
-
堵塞处理策略
当前执行器在执行任务,但是任务调度中心又让此执行器进行执行任务2,此时任务2就被堵塞了
单击串行:队列的形式,任务进行排队,执行器按次序执行任务
丢弃后续调度:执行器正在执行任务但是新派了任务,不会干新派的任务
覆盖之前调度:执行器正在执行任务但是新派了任务,会把当前的活终止,去做新的活

-
任务超时时间
假如我们任务订的10秒,但是15秒还没有执行完,那超时了就不执行了

- 失败重试次数
![]()
2.5 分片广播
分片广播:执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务
那这样处理同一批视频的话,会不会重复处理同一个视频?
不会
分片广播在给执行器分配任务的时候会给执行器分发序号
调度中心去广播的时候,会通知三个执行器执行任务
比如通知第0号执行器:把第零部分执行一下
比如通知第1号执行器:把第1部分执行一下
比如通知第2号执行器:把第2部分执行一下
…
此时各个执行器就能执行各个的任务

作业分片适用哪些场景呢?
• 分片任务场景:10个执行器的集群来处理10w条数据,每台机器只需要处理1w条数据,耗时降低10倍;
• 广播任务场景:广播执行器同时运行shell脚本、广播集群节点进行缓存更新等。
所以,广播分片方式不仅可以充分发挥每个执行器的能力,并且根据分片参数可以控制任务是否执行,最终灵活控制了执行器集群分布式处理任务。
2.5.1 分片广播事例
如下所示的代码有一个示例,我们可以看一下

可以把这个复制到我们的工程中
下面的代码需要做的就是告诉执行器编号,给每个执行器进行编号
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();//执行器的序号,从0开始
int shardTotal = XxlJobHelper.getShardTotal();//执行器总数
//只要有了上面两个参数,我们就可以人为确定我们执行器执行哪一部分
System.out.println("shardIndex:"+shardIndex);
System.out.println("shardTotal:"+shardTotal);
}
我们需要两个执行器,那只能启动两个MediaApplication项目
其中对于media-service-dev工程一定要在nacos配置本地优先策略
spring:
cloud:
config:
override-none: true
-Dserver.port=63051 配置一下启动端口
-Dxxl.job.executor.port=9998 配置执行器的端口

启动两个执行器,如下图所示:

然后查看一下调度中心,是否有两个执行器
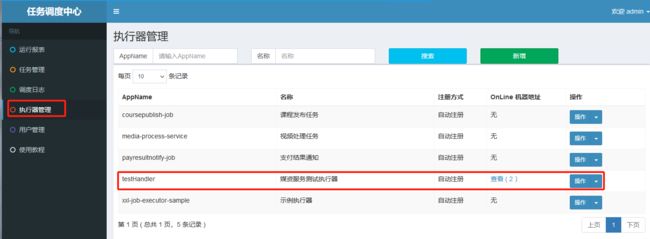
要想让执行器执行任务,还需要在调度中心的任务管理注册任务

执行任务
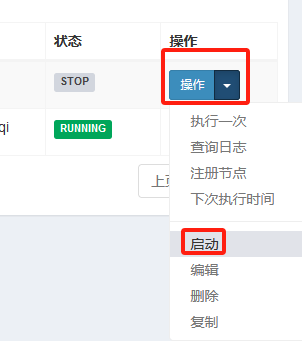
观察控制台情况
分别是0号执行器和1号执行器,总共两个执行器


三、视频处理
3.1 技术方案
3.1.1 作业分片方案
此时如何保证多个执行器不会查询到重复的任务呢?
将待处理的文件进行编号
两个执行器实例那么分片总数为2,序号为0、1
从任务1开始,如下:
1 % 2 = 1 执行器2执行
2 % 2 = 0 执行器1执行
3 % 2 = 1 执行器2执行
以此类推.

3.1.2 保证任务不重复执行
多个执行器在并行执行,怎么保证任务不重复执行呢?
比如说0号执行器有1号任务和3号任务,但是此时调度中心又来进行调度,那1号任务和3号任务可能又执行了一遍
如果一个执行器在处理一个视频还没有完成,此时调度中心又一次请求调度,为了不重复处理同一个视频该怎么办
- 配置调度过期策略
调度过期策略:调度中心错过调度时间的补偿处理策略,包括:忽略、立即补偿触发一次等;
- 忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间;
- 立即执行一次:调度过期后,立即执行一次,并从当前时间开始重新计算下次触发时间;
这里我们选择忽略,如果立即执行一次就可能重复执行相同的任务
-
配置阻塞处理策略
阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
阻塞处理策略就是当前执行器正在执行任务还没有结束时调度中心进行任务调度,此时该如何处理
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
这里如果选择覆盖之前调度则可能重复执行任务,这里选择 丢弃后续调度来避免任务重复执行

- 保证任务处理的幂等性
任务的幂等性是指:对于数据的操作不论多少次,操作的结果始终是一致的
某一个视频不管是调度多少次,只会转码一次
某个视频转码成功后再来调度就不会进行了,因为已经转码成功了
什么是幂等性?它描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果
幂等性是为了解决重复提交问题,比如:恶意刷单,重复支付等
解决幂等性常用的方案
1)数据库约束,比如:唯一索引,主键。
2)乐观锁,常用于数据库,更新数据时根据乐观锁状态去更新。
3)唯一序列号,操作传递一个唯一序列号,操作时判断与该序列号相等则执行。
基于以上分析,在执行器接收调度请求去执行视频处理任务时要实现视频处理的幂等性,要有办法去判断该视频是否处理完成,如果正在处理中或处理完则不再处理。这里我们在数据库视频处理表中添加处理状态字段,视频处理完成更新状态为完成,执行视频处理前判断状态是否完成,如果完成则不再处理。
3.1.3 视频处理方案
边梳理整个视频上传及处理的业务流程
上传视频成功向视频处理待处理表添加记录
我们上传视频的代码已经做了,但是没有做向任务表插入一条待处理视频的任务
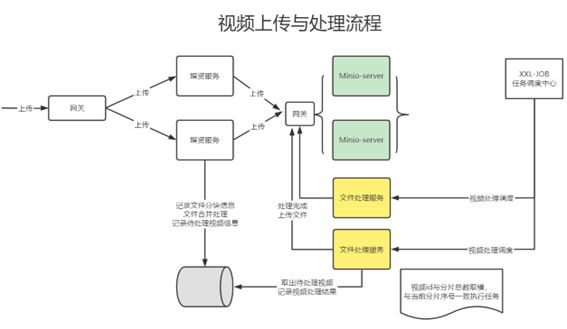
视频处理的详细流程如下:

1、任务调度中心广播作业分片。
2、执行器收到广播作业分片,从数据库读取待处理任务,读取未处理及处理失败的任务。
3、执行器更新任务为处理中,根据任务内容从MinIO下载要处理的文件。
4、执行器启动多线程去处理任务。
5、任务处理完成,上传处理后的视频到MinIO。
6、将更新任务处理结果,如果视频处理完成除了更新任务处理结果以外还要将文件的访问地址更新至任务处理表及文件表中,最后将任务完成记录写入历史表。
行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
这里如果选择覆盖之前调度则可能重复执行任务,这里选择 丢弃后续调度来避免任务重复执行
[外链图片转存中…(img-Bdh0beJE-1704806448805)]
- 保证任务处理的幂等性
任务的幂等性是指:对于数据的操作不论多少次,操作的结果始终是一致的
某一个视频不管是调度多少次,只会转码一次
某个视频转码成功后再来调度就不会进行了,因为已经转码成功了
什么是幂等性?它描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果
幂等性是为了解决重复提交问题,比如:恶意刷单,重复支付等
解决幂等性常用的方案
1)数据库约束,比如:唯一索引,主键。
2)乐观锁,常用于数据库,更新数据时根据乐观锁状态去更新。
3)唯一序列号,操作传递一个唯一序列号,操作时判断与该序列号相等则执行。
基于以上分析,在执行器接收调度请求去执行视频处理任务时要实现视频处理的幂等性,要有办法去判断该视频是否处理完成,如果正在处理中或处理完则不再处理。这里我们在数据库视频处理表中添加处理状态字段,视频处理完成更新状态为完成,执行视频处理前判断状态是否完成,如果完成则不再处理。