如何正确地理解应用架构并开发

许多同学或多或少都经历过这样的流程:
新同学刚来公司,学习了解团队的一些工程代码,并了解其中的代码风格
团队新接手了一些其他团队的项目,需要了解工程结构以及概念
如何定义工程项目的工程结构,包目录结构并达成团队共识
如果你有上述经历,并对工程应用之中的Module划分及其背后的意义理解上存在一些困扰, 那本文对你或许会有一些帮助。
理解代码从理解应用架构开始

应用架构
▐ 混乱的应用架构
最近看了一些业务工程的代码,发现业务系统非常混乱,混乱主要体现在:
应用的层次结构混乱:不知道应用应该如何分层、应该包含哪些组件、组件之间的关系是什么;
缺少规范的指导和约束:新加一段业务逻辑不知道放在什么地方(哪个类,哪个包)、应该起什么名字比较合适?
每个工程的Module数量不一样,Module的命名和定义不一样,不同的Module之间的依赖关系混乱(延伸下就是:Module和Package的作用不清晰,不能很好的区分两者之间的区别)
但有一个共同点就是都很复杂。导致复杂性的原因有很多,如果从架构的层面看,主要有两点:
架构设计过于复杂,层次太多能把人绕晕。
架构简单,ServiceImpl作为上帝类包揽一切,一杆捅到DAO(就简单场景而言,这种Transaction Script也还凑合,至少实现上手都快。
这种人为的复杂性导致系统越来越臃肿,越来越难维护,新来的同学,往往要捂着鼻子抠几天甚至几个月,才能理清系统和业务脉络,然后又一头扎进各种bug fix,业务修补的恶性循环中,暗无天日!
(Transaction Script地址:https://martinfowler.com/eaaCatalog/transactionScript.html)
▐ 有序的应用架构
一个没有架构的应用系统,就像一堆随意堆放、杂乱无章的玩具,只有熵值,没有熵减。而一个有良好架构的应用系统,有章法、有结构,一切都显得井井有条。

好的组织架构会遵循一定的架构模式,大部分的组织都会按职能和业务来设计自己的架构。如果你反其道而行之,硬要把销售、财务和技术人员放在一个部门,就会显得很奇怪。
对于应用架构而言,代码是其核心组成要素,结构就是这些代码该如何被组织,也就是要如何处理模块(Module)、包(Package)和类(Class)之间的关系。简而言之,应用架构就是要解决代码要如何被组织的问题。
▐ 包和模块之间的区别
包和模块这两个概念是比较容易发生混淆的。比如在《实现领域驱动设计》中,作者就说:
If you are using Java or C#, you are already familiar with Modules, though you know them by another name. Java calls them packages. C# calls them namespaces.
他认为Module是Package,这个定义容易造成混淆。特别是在使用Maven的时候,在Maven中,Module是一个Artifact,通常是一个Jar而不是Package。比如NBF-Falcon Framework基础类型的工程就包括如下3个Module:
{应用Code}-api
{应用Code}-service
{应用Code}-start
的确,Module和Component这两个概念很相近,很容易造成混淆。比如,在StackOverflow上有一个提问,就是问Module和Component之间区别的。获得最高赞的答案是通过Scope来区分的。
The terms are similar. I generally think of a "module" as being larger than a "component". A component is a single part, usually relatively small in scope.
「这两个概念类似,我通常认为“模块”比“组件”更大。组件是一个单独的部分,通常范围相对较小。」
(StackOverflow地址:https://softwareengineering.stackexchange.com/questions/178927/is-there-a-difference-between-a-component-and-a-module?spm=ata.21736010.0.0.48807536xgth68)
这个回答和我的直觉反应是一致的,即Module比Package要大。根据以上信息,我在此对Module和Package进行一下定义说明,在本文中,都会遵照如下的定义。- 模块(Module):和Maven中Module定义保持一致,简单理解就是Jar。- 包(Package):和UML中的定义类似,简单理解就是一个文件夹。
一个Moudle通常是由多个Package组成的,其关系如下图所示:

▐ 典型的业务系统
典型的业务系统都需要:
接收request,响应response;
做业务逻辑处理,像校验参数,状态流转,业务计算等等;
和外部系统有联动,像数据库,微服务,搜索引擎等;
如何正确的组织这些业务代码,让他们处于自身该存在的位置,就是我们今天要聊的话题。

常见的工程结构(理论部分)
同样,好的应用架构,不管是六边形架构、洋葱圈架构、整洁架构等,都提倡以业务为核心,解耦外部依赖,分离业务复杂度和技术复杂度。
简单理解下业务复杂度和技术复杂度的概念:
对于一个最简单的钱包扣钱的user case来说
业务复杂度:钱包扣钱时的规则(eg:不能扣成负值)就是业务复杂度
技术复杂度:钱包最终是如何存储的,是用mysql还是lindorm
应用架构的本质(核心),就是要从繁杂的业务系统中提炼出共性,找到解决业务问题的最佳共同模式,为开发人员提供统一的认知,治理混乱。帮助应用系统“从混乱到有序”,物流技术部的工程脚手架就是为此而生,其核心职责就是定义良好的应用结构,提供最佳实践。
▐ 分层模式
分层是一种常见的根据系统中的角色(职责拆分)和组织代码单元的常规实践。常见的分层结构如下图所示:

▐ CQRS模式(命令和查询责任分离)
CQRS(Command Query Rsponsibility Segregation,命令查询分离)
其基本思想在于,任何一个对象的方法可以分为两大类:* 命令(Command):不返回任何结果(void),但会改变对象的状态。* 查询(Query):返回结果,但是不会改变对象的状态,对系统没有副作用。

▐ 六边形架构
六边形架构是Alistair Cockburn在2005年提出,解决了传统的分层结构所带来的问题,实际上它也是一种分层架构,只不过不是上下,而是变成了内部和外部(如下图所示)。

六边形架构又称为端口-适配器架构,这个名字更容器理解。六边形架构将系统分为内部(内部六边形)和外部,内部代表了应用的业务逻辑,外部代表应用的驱动逻辑、基础设施或其他应用。
适配器分为两种类型(如下图所示),左侧代表 UI 的适配器被称为主动适配器(Driving Adapters),因为是它们发起了对应用的一些操作。而右侧表示和后端工具链接的适配器,被称为被动适配器(Driven Adapters),因为它们只会对主适配器的操作作出响应。

▐ 洋葱圈架构
洋葱架构与六边形架构有着相同的思路,它们都通过编写适配器代码将应用核心从对基础设施的关注中解放出来,避免基础设施代码渗透到应用核心之中。这样应用使用的工具和传达机制都可以轻松地替换,可以一定程度地避免技术、工具或者供应商锁定。
不同的是洋葱架构还告诉我们,企业应用中存在着不止两个层次,它在业务逻辑中加入了一些在领域驱动设计的过程中被识别出来的层次(Application,Domain Service,Domain model,Infrastructure等)
另外,它还有着脱离真实基础设施和传达机制应用仍然可以运行的便利,这样可以使用 mock 代替它们方便测试。

在洋葱架构中,明确规定了依赖的方向:
外层依赖内层;
内层对外层无感知。

应用架构的核心
纵观上面介绍的所有应用架构,我们可以发现一个共同点,就是“核心业务逻辑和技术细节分离”。

是的,六边形架构、洋葱圈架构的核心职责就是要做核心业务逻辑和技术细节的分离和解耦。
试想一下,业务逻辑和技术细节糅杂在一起的情况,所有的代码都写在ServiceImpl里面,前几行代码是做validation的事,接下来几行是做convert的事,然后是几行业务处理逻辑的代码,穿插着,我们需要通过RPC或者DAO获取更多的数据,拿到数据后,又是几行convert的代码,在接上一段业务逻辑代码,然后还要落库,发消息.....等等。
再简单的业务,按照上面这种写代码的方式,都会变得复杂,难维护。
因此,我认为应用架构的核心使命就是要分离业务逻辑和技术细节。让核心业务逻辑可以反映领域模型和领域应用,可以复用,可以很容易被看懂。让技术细节在辅助实现业务功能的同时,可以被替换。

如何正确的进行工程划分?
这些应用架构思想虽然很好,但我们很多同学还是“不讲Co德,明白了很多道理,可还是过不好这一生”。
所以我们接下来聊聊这个偏工程实践的话题。
▐ 业务工程中最基本的Module划分
上文提到了Moudle和包之间的关系,我们有个基本共识,Module比Package(包)要大一些。那我们基本的分层结构又应该是怎么样的呢,这里列两种业务工程中最常见的Module之间的依赖关系:
非依赖倒置下的Module分层

依赖倒置(DIP)下的Module分层(推荐)

依赖倒置(DIP):
简单说依赖倒置就是你不要直接依赖我,你和我都同时依赖一个接口(所以有时候也叫面向接口的编程),这样我们之间就解耦了,依赖和被依赖方都可以自由改动了。
依赖倒置下的Module分层的好处
Domain层会变得更加纯粹,完全摆脱了对技术细节(以及技术细节带来的复杂度)的依赖,只需要安心处理业务逻辑就好(我们经常说的核心业务逻辑稳定其实就是Domain层的稳定,上文中的Domain层完全依赖于接口和内部的模型,屏蔽了技术细节,如果我们更换技术组件,也只需要更换技术细节的实现即可)
并行开发:只要在Domain和Infrastructure约定好接口,可以有两个同学并行编写Domain和Infrastructure的代码
可测试性:没有任何依赖的Domain里面都是POJO的类,单元测试将会变得非常方便,也非常适合TDD的开发。
分层职责
1.适配层(Adapter Layer):负责对前端展示(web,wireless,wap)的路由和适配,对于传统B/S系统而言,adapter就相当于MVC中的controller;
○用户展现信息以及解释用户命令
○大部分工程为start模块
2.应用层/应用服务层(Application Layer):主要负责获取输入,组装上下文,参数校验,调用领域层做业务处理,如果需要的话,发送消息通知等。层次是开放的
○应用层也可以绕过领域层,直接访问基础实施层(CQRS模式中对于查询的说法就是可以绕过DomainModel之间查询数据);
○很薄的一层,用来协调应用的活动。它不包含业务逻辑
○同样的一个Service应可被不同的Adapter(Web、远程调用、异步消息)复用)。
○适合处理事务、高层次日志(oplog)、安全(权限)
3.领域层(Domain Layer):主要是封装了核心业务逻辑,并通过领域服务(Domain Service)和领域对象(Domain Entity)的方法对App层提供业务实体和业务逻辑计算。
○领域是应用的核心,不依赖任何其他层次
○通常每一个聚合(aggregate)一个package。聚合包含实体(entity),值对象(value object),领域事件(domain event),资源库(repository,仅接口)接口和一些工厂(Factory)。
4.基础实施层(Infrastructure Layer):主要负责技术细节问题的处理,比如数据库的CRUD、搜索引擎、文件系统、分布式服务的RPC等。此外,领域防腐的重任也落在这里,外部依赖需要通过防腐层(Anti-Corruption) 实现的转义处理,才能被上面的App层和Domain层使用。
▐ 如果我要提供一个SDK对外提供服务怎么办?

Module的定义应该遵循自身业务需求(如无必要勿增实体)
上文中如果需要一个api包则增加一个API Module包即可
这里的client包不要依赖Domain,这会引入大量无关依赖,对包的使用者造成困扰
▐ 包结构的划分
分层是属于大粒度的职责划分,太粗,我们有必要往下再down一层,细化到包结构的粒度,才能更好的指导我们的工作。
还是拿一堆玩具举例子,分层类似于拿来了一个架子,分包类似于在每一层架子上又放置了多个收纳盒。所谓的内聚,就是把功能类似的玩具放在一个盒子里,这样可以让应用结构清晰,极大的降低系统的认知成本和维护成本。

那么,对于一个后端应用来说,应该需要哪些收纳盒。

各个包结构的简要功能描述,如下表所示:
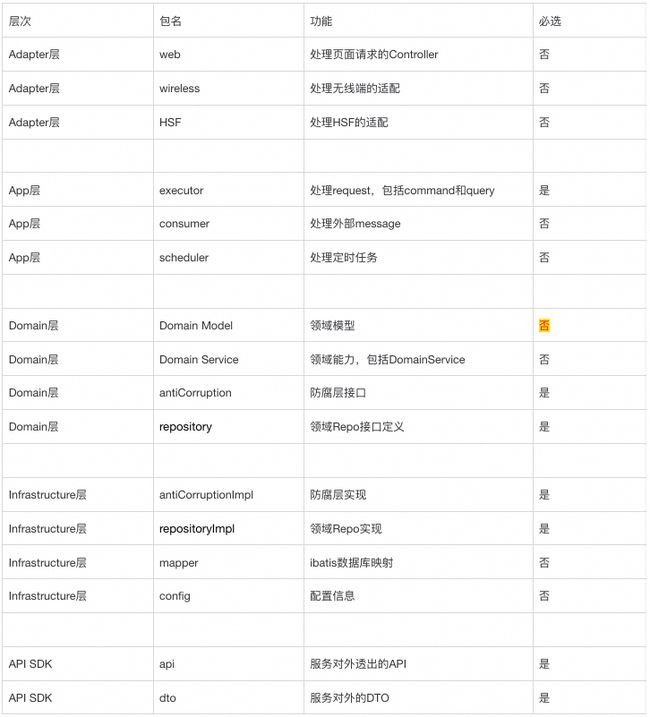
你可能会有疑问,为什么Domain的model是可选的?
因为是应用架构,不是DDD架构。对于应用架构来说:无有必要勿增实体。领域模型对设计能力要求很高,没把握用好,一个错误的抽象还不如不抽象,宁可不要用,也不要滥用,不要为了DDD而DDD。
问题的关键是要看,新增的模型没有给你带来收益。比如有没有帮助系统解耦,有没有提升业务语义表达能力的提升,有没有提升系统的可维护性和可测性等等。
模型虽然可选,但DDD的思想是一定要去学习和贯彻的,特别是统一语言、边界上下文、防腐层的思想,值得深入学习,仔细体会。实际上,应用架构里面的很多设计思想都来自于DDD。其中就包括领域包的设计。
前面的包定义,都是功能维度的定义。为了兼顾领域维度的内聚性,我们有必要对包结构进行一下微调,即顶层包结构应该是按照领域划分,让领域内聚。
也就是说,我们要综合考虑功能和领域两个维度包结构定义。按照领域和功能两个维度分包策略,最后呈现出来的,是如下图所示的顶层包节点是领域名称,领域之下,再按功能划分包

下图是一个例子,按照分包策略,我们在每一个Module下面首先按照领域做一个顶层划分,然后在领域内,再按照功能进行分包。


如何解决应用架构中的问题
▐ 应用架构中如何处理解耦问题
“高内聚,低耦合”这句话,你工作的越久,就越会觉得其有道理。
所谓耦合就是联系的紧密程度,只要有依赖就会有耦合,不管是进程内的依赖,还是跨进程的RPC依赖,都会产生耦合。依赖不可消除,同样,耦合也不可避免。我们所能做的不是消除耦合,而是把耦合降低到可以接受的程度。在软件设计中,有大量的设计模式,设计原则都是为了解耦这一目的。
在DDD中有一个很棒的解耦设计思想——防腐层(Anti-Corruption),简单说,就是应用不要直接依赖外域的信息,要把外域的信息转换成自己领域上下文(Context)的实体再去使用,从而实现本域和外部依赖的解耦。
防腐层设计在应用架构中的应用
我们把防腐层(Anti-Corruption)这个概念进行泛化,将数据库、搜索引擎等数据存储都列为外部依赖的范畴。利用依赖倒置,统一使用防腐层(Anti-Corruption)/Repository等接口来实现业务领域和外部依赖的解耦。
其实现方式如下图所示,主要是在Domain层定义防腐层(Anti-Corruption)/Repository等接口,然后在Infrastructure提供防腐层(Anti-Corruption) 接口的实现。

高内聚低耦合在包划分中的体现
刚刚我们提到了在包划分的过程中,推荐先按照领域分包,这其实就是一种高内聚低耦合,这样做的好处有以下几方面:
明确这个包下面提供的类和功能应该放在一起考虑
通过包的可见性现在自身领域服务(功能)对外的可见性(重点)
a.写java的同学经常会给领域模型DomainModel上直接加上Setter方法,这样会比较方便构造领域对象,但是这样的做法其实违反了开闭原则,意味着你的领域对象中的所有属性对外都是暴露的,可以直接通过set的方式而不是通过领域对象提供的方法来进行变更,这对领域对象的稳定性来说很不友好
b.通过包的可见性来暴露自身想暴露的能力
这里推荐一种比较好的做法:
对于setter方法以及内部调用的方法设置为包可见(package private)
通过构造函数/Factory(复杂的聚合根)创建领域对象
▐ 如何对齐文中的概念和实际业务中的Module?
由于各个团队之间自身规范的问题以及建项目的同学自身对应用架构的理解不同,你可能会发现如下几种情况:
业务系统中的Module层数和文中描述的不同
业务复杂度决定了包的层级,对于简单的web系统,单module其实更能降低架构复杂度
拆分粒度不同,有些工程可能会拆分出类似Infrastruct-client(对应上文中的防腐层(Anti-Corruption)Interface)这样的Module
业务诉求不同:有些业务系统并不需要提供API,而是通过DTS/Controller驱动业务,自然也就不需要API Module
业务系统中的Module命名和文中描述不同
每个人对module的命名问题,实际还是要看这个module承载的业务职责
模块的职责不同,比方说对外提供的富客户端一般以Client命名,接口包一般就叫API了
业务系统中Module的依赖关系和文中不同
有没有可能是分层太多倒置后来的同学也搞不清楚该怎么依赖了,导致的错误依赖
文中也提供了好几种依赖,就像地心说和日心说一样,对于应用结构的认识是有一个过程的
业务系统中的包划分和文中不同
很多业务系统直接按照功能分包了,比如repository放一起(我认为对于实现来说是ok的,对于领域模型来说还是要有领域的概念)
那么如何找到这个工程目前的工程规范呢?
如果有工程结构的文档,优先阅读(省时间)
找一个Use Case,从入口侧去看文中的业务开发中涉及到的业务逻辑写在了哪个包中
注:Use Case是《架构整洁之道》里面的术语,简单理解就是响应一个Request的处理过程
▐ 如果业务代码中的应用架构不合理,你有自己的想法怎么办?
工程刚开始搭建阶段:大家团队内进行讨论,并产出应用架构图,统一领域语言:module分布、包命名规范、类命名规范等,再进行开发
工程不复杂,且大家都认可新的应用架构:拉分支修改,改造后进行功能的回归测试,组内review完没问题将变更合并入主干分支
工程比较复杂或者你只是想让你这部分代码符合你的规范:并不建议这样做,对于一个应用工程来说,不同代码风格往往比合理的工程架构更致命,会导致工程结构混乱,大家理解困难,一个统一的工程规范远比合理更重要

如何编写业务代码?
▐ DDD下业务代码的组织方式
“写操作”在DDD中的实现3种场景,分别是
通过聚合根完成业务请求,这是DDD完成业务请求的典型方式
通过Factory完成聚合根的创建
通过DomainService完成业务请求

读操作,同样给出了3种方式
基于领域模型的读操作(读写操作糅合在了一起,不推荐)
基于数据模型的读操作(绕过聚合根和资源库,直接返回数据,推荐)
CQRS(读写操作分别使用不同的数据库,比较重)
(图中的ReadModel可以理解为DTO)

对于业务代码来说,怎么提炼出业务逻辑和技术细节?
对Use Case进行过程分解
对象模型建设

举个例子,在上架过程中,有一个校验是检查库存的,其中对于组合品(CombineBackOffer)其库存的处理会和普通品不一样。原来的代码是这么写的:
boolean isCombineProduct = supplierItem.getSign().isCombProductQuote();
// supplier.usc warehouse needn't check
if (WarehouseTypeEnum.isAliWarehouse(supplierItem.getWarehouseType())) {
// quote warehosue check
if (CollectionUtil.isEmpty(supplierItem.getWarehouseIdList()) && !isCombineProduct) {
throw ExceptionFactory.makeFault(ServiceExceptionCode.SYSTEM_ERROR, "亲,不能发布Offer,请联系仓配运营人员,建立品仓关系!");
}
// inventory amount check
Long sellableAmount = 0L;
if (!isCombineProduct) {
sellableAmount = normalBiz.acquireSellableAmount(supplierItem.getBackOfferId(), supplierItem.getWarehouseIdList());
} else {
//组套商品
OfferModel backOffer = backOfferQueryService.getBackOffer(supplierItem.getBackOfferId());
if (backOffer != null) {
sellableAmount = backOffer.getOffer().getTradeModel().getTradeCondition().getAmountOnSale();
}
}
if (sellableAmount < 1) {
throw ExceptionFactory.makeFault(ServiceExceptionCode.SYSTEM_ERROR, "亲,实仓库存必须大于0才能发布,请确认已补货.\r[id:" + supplierItem.getId() + "]");
}
}然而,如果我们在系统中引入领域模型之后,其代码会简化为如下:
if(backOffer.isCloudWarehouse()){
return;
}
if (backOffer.isNonInWarehouse()){
throw new BizException("亲,不能发布Offer,请联系仓配运营人员,建立品仓关系!");
}
if (backOffer.getStockAmount() < 1){
throw new BizException("亲,实仓库存必须大于0才能发布,请确认已补货.\r[id:" + backOffer.getSupplierItem().getCspuCode() + "]");
}有没有发现,使用模型的表达要清晰易懂很多,而且也不需要做关于组合品的判断了,因为我们在系统中引入了更加贴近现实的对象模型(CombineBackOffer继承BackOffer),通过对象的多态可以消除我们代码中的大部分的if-else

常见问题
▐ API层
API包一般放什么内容?
对外暴露接口:直接代理外界需要访问的领域服务。
Facade模式:对Domain层的能力,基于易用性的目的,进行一定的重组;比如多个领域服务合一个API、一个领域服务拆多个API
对于一些通用的判断方法可以放在里面
通用的异常类型
通用的枚举
▐ Application层
Application层即API的设计要划分领域吗?
需要划分领域,细节可能和Domain层存在一些差异,由于属于顶层服务
API和Domain Service都是接口,它们的区别是什么?
API是暴露给外部系统,希望外部系统感知的能力;领域服务的能力仅暴露在系统内部。
API暴露的能力一般比领域服务少,因为领域服务还要给JobProcessor、MessageListener或其它领域服务提供服务。
分层原则(也是任何分层分域的一般准则)
架构解决的是变化的问题。根据子系统变化的快慢,对子系统进行分层,从而隔离变化。例如上面的基础域变化慢,业务域变化快,分开。
▐ Domain
为什么Domain层和Infrastructure层要依赖倒置?
通过依赖倒置,消除Domain层的外部依赖,完全隔离外部变化,实现自洽。
Repository和防腐层(Anti-Corruption)是什么?
Repository就是DDD里的领域仓库,负责领域实体的生命周期管理(可以简单理解为增删改查)
防腐层(Anti-Corruption)是为了隔离变化而抽象出来的概念,负责和外部系统打交道。
Repository和防腐层(Anti-Corruption)的区别是什么?
从代码结构上来看是一样的。如果按设计模式来解读,本质上都是Adaptor。其中,本领域充当Adaptor中的client角色。即Repository和防腐层(Anti-Corruption)的接口签名是基于本领域的需求而设计(而不是基于外部系统的签名来设计)。这也是为什么Repository和防腐层(Anti-Corruption)要按域来组织,而不是按外部系统来组织。
从语义上来讲,Repository偏数据,防腐层(Anti-Corruption)偏功能。这种语义区分能提升系统可维护性。
▐ Infrastructure
什么决定了是放Domain层还是Infrastructure层?
约定:访问中间件/外部系统的,放基础设施层。领域层只放领域逻辑,从而隔离变化。
基础设施从字面上看偏基础,为什么把中间件、外部系统放这里?
按照洋葱圈架构的说法,这些其实都是适配器,都应该属于外部依赖的范畴
Utils放哪里,是不是基础设施的一部分?
不建议:如果认为工具是基础设施的一部分,则Domain层甚至API层将感知Infrastructure层,破坏了依赖单向性。
建议基础工具抽到单独的二方包;业务工具放到对应的Module。
回顾下整篇文章,咱们对于应用架构的混乱问题进行了总结与归纳,并给出了一些重点需要理解的内容,希望能对大家的日常开发有一些帮助。

附录
后端开发实践系列——领域驱动设计(DDD)编码实践 - Thoughtworks洞见(地址:https://insights.thoughtworks.cn/backend-development-ddd/)
实现领域驱动设计(地址:https://book.douban.com/subject/25844633//)
Cola-阿里巴巴开源应用架构(地址:https://github.com/alibaba/COLA)

团队介绍
我们是淘天集团物流技术团队,服务淘天物流部及零售行业的产技团队,一直深耕在物流及供应链的数字化协同与运营领域:为零售业务提供灵活多样的经营模式管理方案及可以快速适配市场变化的经营策略数宇化管理工具;为商家提供高效低成本的物流及供应链解决方案,加快资金效率,提升协同效率;为消费者提供即时便捷的购物体验。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法