斯坦福机器人Mobile ALOHA的背后技术:动作分块ACT、Diffusion Policy、VINN
前言
23年已过35 今24年则将36,到40岁之前还有4年半,这4年半我想冲一把大模型机器人(兼具商业价值、社会价值、科技价值),更大的如造车 我也干不了,但
- 通过过去一年的研究探索与应用开发,机器人是在可能范围之内我能做的最大的项目,很难,4年半下来也不一定能达到预期,但全力
- 希望通过Q1之内的技术准备、复现Moblie aloha、建机器人开发团队之后,Q2之内可以 拿到一笔融资全力开干(至于教育培训会永远一直做,毕竟能为项目推荐源源不断的人才)
根据上一篇文章《大模型机器人发展史:从VoxPoser、RT2到斯坦福Mobile ALOHA、Google机器人》可知,斯坦福Mobile ALOHA在其发布的论文中提到
In our experiments, we combine this co-training recipe with multiple base imitation learning approaches, including ACT [104], Diffusion Policy [18], and VINN [63]
相当于Mobile ALOHA涉及到了这三大关键技术:ACT、Diffusion Policy、VINN,故本文分三个部分一一阐述
第一部分 动作分块算法ACT
1.1 ALOHA + ACT解决现有机器人昂贵且难以做精确任务的问题
斯坦福Mobile ALOHA在被推出之前,其实在23年Q1便已有了ALOHA,所谓ALOHA,即是A Low-cost Open-source Hardware System for Bimanual Teleoperation,一个低成本的开源硬件系统,用于手动远程操作,怎么一步步来的呢?
在前两年,让机器人去完成一些抽象精细的操作任务,比如穿线扎带或开槽电池,是比较困难的
- 一方面,因为这些任务需要比较高的精准度、协调性以及闭环视觉反馈。通常情况下,执行这些任务需要使用高端机器人、精确传感器或者仔细校准设备,而且成本昂贵且难以设置。Stanford University、UC Berkeley、Meta等研究者为了让低成本和不太精确的硬件也能完成这些复杂操作,提出了一个低成本系统,可以通过定制远程操作接口收集实际演示,进行端到端的模仿学习(We present a low-cost system that performs end-to-end imitation learning directly from real demonstrations,collected with a custom teleoperation interface)
- 二方面,在高精度领域中进行模仿学习还存在挑战:策略中的错误可能会随着时间推移而累积,并且人类演示可能是非平稳的。为了解决这些挑战,该团队开发了一种动作分块算法,即Action Chunking with Transformers (ACT),它基于Transformer在动作序列上生成模型并允许机器人学习现实世界中6项困难任务(例如打开半透明调味品杯和插入电池),成功率达80-90%(这是其演示地址)
根据该团队发表的这篇论文《Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware》可知
- 他们训练了一个端到端的策略,该策略直接将来自商品网络相机的RGB图像映射到动作(we therefore train an end-to-end policy that directly maps RGB images from commodity web cameras to the actions.)。这种从像素到动作的转换方法特别适用于精细操作,因为精细操纵通常涉及具有复杂物理特质的对象,这样学习操纵策略比建模整个环境要简单得多
- 以调味品杯为例:模拟轻推杯子时的接触,以及撬开盖子时的变形,都会引起大量的物理变化。与其耗费大量的研究和具体任务的工程努力去设计一个足够精确的模型进行具体的规划,不如转化为执行上要简单的很多的策略制定,即确定轻推和打开杯子的策略或方法,因为策略可以对杯子和盖子的不同位置做出反应,而不是提前精确预测它将如何移动
Designing a model accurate enough for planning would require significant research and task specific engineering efforts. In contrast, the policy of nudging and opening the cup is much simpler, since a closed-loop policy can react to different positions of the cup and lid rather than precisely anticipating how it will move in advance
说白了,咱们不是去生成一个轻推和打开杯子的视频,不用去描绘过程,咱们只是要完成一个具体的目标(结果说话),而完成某个具体的目标有策略、有方法就行
1.1.1 模仿学习及其挑战:Action Chunking with Transformers(ACT)
系统有了,数据也好办(高质量的人类演示可以让系统学习人类的灵巧,因此,可让低成本但灵巧的遥操作系统ALOHA做数据收集),但训练一个端到端的策略(end-to-end policy)可没那么容易,因为即使是高质量的演示,在处理需要精度和视觉反馈的任务时,对模仿学习来说也是一个重大挑战
- 预测动作中的小误差会引起状态的大差异,加剧模仿学习的“复合误差”问题。为了解决这个问题,他们从动作分块(action chunking)中获得灵感,这是心理学中的一个概念,描述了如何将一系列动作组合在一起作为一个块,并作为一个单元执行
Small errors in the predicted action can incur large differences in the state, exacerbating the “compounding error” problem of imitation learning [47, 64, 29]. To tackle this, we take inspiration from action chunking, a concept in psychology that describes how sequences of actions are grouped together as a chunk, and executed as one unit [35]. - 在他们的案例中,策略预测了接下来k个时间步的目标关节位置,而不仅仅是一次一步。这通过k折减少了任务的有效视界,减轻了复合误差
In our case, the policy predicts the target joint positions for the next k timesteps, rather than just one step at a time. This reduces the effective horizon of the task by k-fold, mitigating compounding errors.
预测动作序列也有助于解决时间相关的干扰因素,例如难以用马尔可夫单步策略建模的演示中的停顿
Predicting action sequences also helps tackle temporally correlated confounders [61], such as pauses in demonstrations that are hard to model with Markovian single-step policies. - 为了进一步提高策略的平滑性,本文提出了时间集成,更频繁地查询策略,并在重叠的动作块上进行平均。他们使用Transformers[65](一种为序列建模而设计的架构)实现动作分块策略,并将其训练为条件VAE (CVAE),以捕获人类数据中的可变性。他们将该方法命名为Action Chunking with Transformers(ACT),并发现它在一系列模拟和现实世界的精细操作任务上显著优于以前的模仿学习算法
To further improve the smoothness of the policy, we propose temporal ensembling, which queries the policy more frequently and averages across the overlapping action chunks. We implement action chunking policy with Transformers [65], an architecture designed for sequence modeling, and train it as a conditional VAE (CVAE) [55, 33] to capture the variability in human data. We name our method Action Chunking with Transformers (ACT), and find that it significantly outperforms previous imitation learning algorithms on a range of simulated and real-world fine manipulation tasks.
1.1.2 行为克隆(Behavioral cloning, BC)中为何要引入ACT
模仿学习可以让机器人直接向专家学习,而行为克隆(Behavioral cloning, BC)是最简单的模仿学习算法之一,将模仿作为从观察到行动的监督学习
- BC的一个主要缺点是复合误差,以前时间步长的误差累积并导致机器人偏离其训练分布,导致难以恢复状态[47,64]。这个问题在精细操作设置[29]中尤为突出。减轻复合错误的一种方法是允许额外的政策上的交互和专家修正,如DAgger[47]及其变体[30,40,24]
- 然而,对于遥操作界面[29],专家注释可能是耗时且不自然的。人们也可以在演示采集时注入噪声以获得具有纠正行为[36]的数据集,但对于精细操作而言,这种噪声注入会直接导致任务失败,降低遥操作系统的灵巧度。为了规避这些问题,之前的工作以离线的方式生成合成校正数据[16,29,70]。虽然它们仅限于可获得低维状态的设置,或特定类型的任务,如抓取。由于这些限制,需要从不同的角度来解决复合误差问题,好与高维视觉观察兼容
- 因此建议通过动作分块(action chunking)来减少任务的有效视界,即预测一个动作序列而不是单个动作,然后跨重叠的动作块进行集成,以产生既准确又平滑的轨迹
1.2 硬件套装:ALOHA + 远程操作系统
1.2.1 ALOHA:低成本的开源硬件系统,用于手动远程操作
我们已经知道市面上已有类似达芬奇外科手术机器人或ABB YuMi这样的机器人,但成本一般比较昂贵。他们团队则转向低成本硬件(很类似七月在一系列大模型应用上的探索,侧重小团队 低成本 大效果),例如每个成本约为5k美元的手臂,并寻求使它们能够执行高精度、闭环任务。他们的遥操作设置最类似于Kim等人的[32],也使用了人类遥控者和跟随者机器人之间的关节空间映射。与之前的这个系统不同,他们没有使用特殊的编码器、传感器或加工部件。他们只使用现成的机器人和少量3D打印部件来构建他们的系统,让非专业人士在不到2小时内组装好它
具体而言,其具备以下五个特点
- 低成本:整个系统应该在大多数机器人实验室的预算之内,可与单个工业手臂相媲美
- 通用性:它可以应用于广泛的与现实物体的精细操作任务
- 人性化:系统应该直观、可靠、易于使用
- 可修复:当设置不可避免地出现故障时,研究人员可以轻松修复设置
- 易于搭建:研究人员可以快速组装,材料来源容易
如下图所示:
- 左侧为前、顶部和两个手腕摄像机的视角,以及ALOHA双手工作空间的示意图
- 中间是“手柄和剪刀”机制和定制夹具的详细视图
- 根据上面的原则1、4和5,建立了一个双手平行颚夹持器设置与两个ViperX 6-DoF机器人手臂,上图右侧列出了ViperX 6dof机器人的技术规格
出于价格和维护方面的考虑,不使用灵巧手。使用的ViperX臂具有750克和1.5米跨度的工作有效载荷,精度为5-8毫米
且该机器人模块化,维修简单:在电机出现故障的情况下,低成本的Dynamixel电机可以轻松更换。这种机器人可以以5600美元左右的价格购买到现货。然而,OEM的手指不够通用,无法处理精细的操作任务。因此,设计了自己的3D打印“透明”手指,并将其贴合在夹持胶带(gripping tape)上
1.2.2 远程操作系统
然后,需要设计一个远程操作系统,然没有将VR控制器或摄像头捕获的手部姿势映射到机器人的末端执行器姿势,即任务空间映射(Instead of mapping the hand pose captured by a VR controller or camera to the end-effector pose of the robot, i.e. task-space mapping),而是使用来自同一家公司制造的小型机器人WidowX的直接关节空间映射,成本为3300美元
用户通过反向驱动较小的WidowX(“领导者”)来远程操作,其关节与较大的ViperX(“追随者”)同步。在开发设置时,注意到使用关节空间映射(joint-space mapping)比使用任务空间有一些好处
- 精细操作通常需要在机器人的singularities附近操作,在他们的例子中,机器人有6个自由度,没有冗余。现成的逆运动学(inverse kinematics,IK)在这种情况下经常失效。另一方面,关节空间映射保证了关节限制内的高带宽控制,同时也需要更少的计算和减少延迟
- leader机器人的重量可以防止用户移动过快,同时也可以抑制小的振动。注意到使用关节空间映射比手持VR控制器在精确任务上表现更好。为了进一步提高遥操作体验,设计了一个3d打印的“手柄和剪刀(handle and scissor)”机构,可以改装到领导者机器人上
它减少了操作人员反向驱动电机所需的力,并允许连续控制夹持器,instead of binary opening or closing - We also design a rubber band load balancing mechanism that partially counteracts the gravity on the leader side。它减少了操作人员所需的努力,并使更长的遥操作时间(如>30分钟)成为可能(项目网站中包含了有关设置的更多细节)
其余设置包括一个尺寸为20×20mm的铝挤压机器人笼,由交叉钢缆加固(The rest of the setup includes a robot cage with 20×20mm aluminum extrusions, reinforced by crossing steel cables)。
总共有四个Logitech C922x网络摄像头,每个流输出480×640 RGB图像
- 其中两个网络摄像头安装在跟随机器人手腕上,以提供夹具的近距离视角(allowing for a close-up view of the grippers)
- 剩下的两个相机分别安装在前方和顶部位置。遥控操作和数据记录均以50Hz频率进行
1.3 Action Chunking with Transformers(ACT)的整体流程
为了在新任务上训练ACT,首先使用ALOHA收集人类演示
- 该团队记录了领导机器人的关节位置(record the joint positions ofthe leader robots,即来自人类操作员的输入),并将其作为动作
之所以使用领导者的关节位置而不是跟随者的关节位置,是因为通过低级PID控制器施加力量时,这些力量是由“它们之间的差异”隐式定义决定的
It is important to use the leader joint positions instead of the follower’s, because the amount of force appliedis implicitly defined by the difference between them, through the low-level PID controller
观察结果由跟随机器人当前关节位置和4个摄像机图像馈入组成(The observations are composed ofthe current joint positions of follower robots and the image feedfrom 4 cameras) - 接下来,训练ACT根据当前观察结果预测未来动作序列(we train ACT to predict the sequence offuture actions given the current observations)
这里一个动作对应于下一个时间步中两只手的目标关节位置(An action here corresponds to the target joint positions for both arms in the next time step)
直观地说,ACT试图模仿人类操作员在当前观察结果下,在接下来的时间步中会做什么(ACT tries to imitate what a human operator would do in the following time steps given current observations) - 然后,Dynamixelmotors内部的低级、高频PID控制器跟踪这些目标关节位置。在测试时,加载实现了最低验证损失策略,并在环境中推出。出现的主要挑战是复合错误,其中包括来自之前动作的错误导致了超出训练分布范围的状态
These target joint positions are then tracked bythe low-level, high-frequency PID controller inside Dynamixelmotors. At test time, we load the policy that achieves the lowest validation loss and roll it out in the environment. Themain challenge that arises is compounding errors, where errorsfrom previous actions lead to states that are outside of training distribution.
1.3.1 动作如何具体分块:将同一时间步内的预测动作进行聚合
为了以一种与像素到动作策略兼容的方式来解决模仿学习中的复合错误,寻求减少高频收集的长轨迹的有效视域(To combat the compounding errors of imitation learning in away that is compatible with pixel-to-action policies,we seek to reduce the effective horizon of long trajectories collected at high frequency)
对此,受到了动作分块的启发,这是一个神经科学概念,其中个体动作被分组在一起并作为一个单元执行,从而更有效地存储和执行[We are inspired by action chunking,a neuro science concept where individual actions are grouped together and executed as one unit, making them more efficientto store and execute]
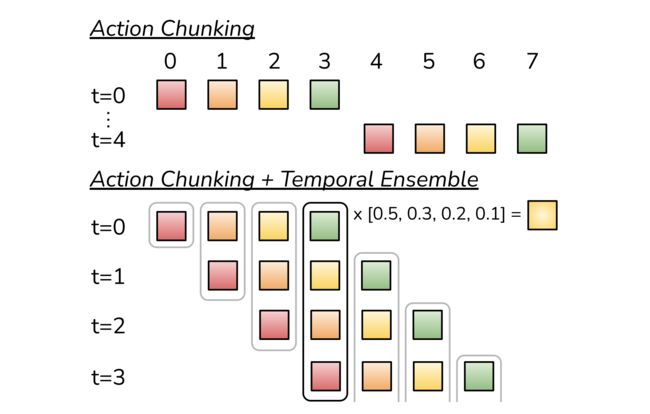
- 直观地说,一组动作可以对应于抓住糖果包装纸角或将电池插入槽中。如上图所示,将块大小固定为k:每k步agent接收一个观察,并生成下一个k个动作依次执行这些动作。这意味着任务的有效视界减少了k倍
wefix the chunk size to be k: every k steps, the agent receivesan observation, generates the next k actions, and executes theactions in sequence.This implies a k-fold reduction in the effective horizon of the task.
具体来说,该策略模拟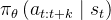 而不是
而不是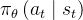 。换言之,单步策略将对抗与时间相关的干扰因素,例如人类演示的过程中间出现暂停 ,因为行为不仅取决于状态还取决于时间步长。通过采用动作分块方法可以缓解这种混淆
。换言之,单步策略将对抗与时间相关的干扰因素,例如人类演示的过程中间出现暂停 ,因为行为不仅取决于状态还取决于时间步长。通过采用动作分块方法可以缓解这种混淆
Concretely, the policymodels πθ(at:t+k|st) instead of πθ(at|st). Specifically, a single-step policy would struggle with temporally correlated confounders, such as pauses in the middle of ademonstration [61], since the behavior not only depends onthe state, but also the time step. Action chunking can mitigate - 这样做可以使不同的动作块相互重叠,在给定的时间步长上产生多个预测动作(This makes different action chunks overlap with each other,and at a given time step there will be more than one predict edaction),并提出了一个时间集成方法来组合这些预测结果
其时间集成通过加权平均对这些预测进行处理,采用指数加权方案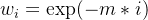 ,其中
,其中 表示最早动作的权重(Our temporal ensemble performs a weighted average over these predictions with anexponential weighting scheme wi = exp(−m ∗i), where w0is the weight for the oldest action. )
表示最早动作的权重(Our temporal ensemble performs a weighted average over these predictions with anexponential weighting scheme wi = exp(−m ∗i), where w0is the weight for the oldest action. )
新观察到达时速度由参数 决定,较小的意味着更快地纳入新观察(The speed for incorporatingnew observation is governed by m, where a smaller m meansfaster incorporation)
决定,较小的意味着更快地纳入新观察(The speed for incorporatingnew observation is governed by m, where a smaller m meansfaster incorporation)
需要注意的是,与典型平滑方法不同(当前动作与相邻时间步中的动作被聚合在一起,那样会引入偏差),他们将同一时间步内的预测动作进行聚合
We note that unlike typical smoothing,where the current action is aggregated with actions in adjacent time steps, which leads to bias, we aggregate actions predicted forthe same timestep.
该过程没有额外训练成本,只需增加推理计算所需时间。实践证明,动作分块和时间集成对ACT模型都至关重要,它们能够产生准确且平滑流畅的运动效果
This procedure also incurs no additional training cost, only extra inference-time computation. In practice,we find both action chunking and temporal ensembling to beimportant for the success of ACT, which produces precise andsmooth motion
1.3.2 Modeling human data与ACT的执行
上文1.2节我们解决了硬件系统的问题,1.3节我们解决了算法优化的问题,接下来,该细化数据的问题了。
实话说,让机器人从嘈杂的人类演示中学习并不容易,在相同的观察下,人类可以使用不同的轨迹来解决任务。在精度不那么重要的区域,人类也会更随机。因此,对于政策来说,关注高精度重要的区域是很重要的。该团队通过训练他们的动作分块策略作为一个生成模型来解决这个问题
最终将策略训练为条件变分自编码器(CVAE,用类似BERT的编码器实现),以生成以当前观察为条件的动作序列。CVAE有两个组件:一个CVAE编码器和一个CVAE解码器。CVAE编码器只用于训练CVAE解码器(策略),在测试时被丢弃
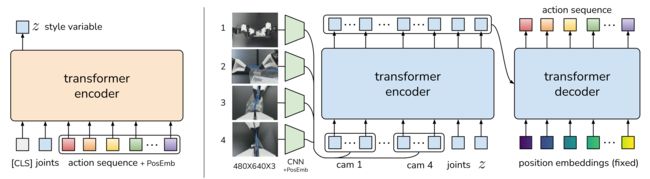
具体而言,如下图所示
- 编码器的输入是来自演示数据集的当前关节位置,和长度为k的目标动作序列,前面加上一个类似于BERT的习得的“[CLS]”token,从而这形成了一个k+2长度的输入
The inputs to the encoder are the current joint positions and the target action sequence of length k from thedemonstration dataset, prepended by a learned “[CLS]” tokensimilar to BERT. - 通过编码器之后,使用“[CLS]”对应的特征来预测“风格变量”z的均值和方差
- 之后,CVAE解码器(即策略),通过z和当前观测(图像+关节位置)的条件来预测动作序列(即接下来的k个动作)。在测试时,我们将z设置为先验分布的均值,即0以确定解码
For faster training in practice, we leave outthe image observations and only condition on the proprioceptiveobservation and the action sequence. The CVAE decoder, i.e.the policy, conditions on both z and the current observations(images + joint positions) to predict the action sequence. Attest time, we set z to be the mean of the prior distribution i.e.zero to deterministically decode.
整个模型被训练成maximize演示动作块的对数似然,即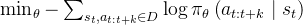
The whole model is trained to maximize P the log-likelihood of demonstration action chunks, i.e.minθ−st,at:t+k ∈D log πθ(at:t+k |st)
标准VAE目标有两项:重建损失和将编码器正则化为高斯先验的项。直观地说,更高的β将导致z中传递的信息更少
with the standard VAEobjective which has two terms: a reconstruction loss and a termthat regularizes the encoder to a Gaussian prior. Following [23],we weight the second term with a hyperparameter β.
当然,我们使用ResNet图像编码器、transformer encoder,和transformer decoder来实现CVAE解码器,直观地说
transformer编码器综合了来自不同相机视角、关节位置和风格变量的信息(different camera viewpoints, the joint positions, and the style variable)
transformer解码器生成连贯的动作序列(generates a coherent action sequence)
1.4 ACT执行的详细架构图与详细步骤
以下是论文中关于上述训练过程的更多细节
1.4.1 采样数据
如下图所示

- 输入:包括4张RGB图像,每张图像的分辨率为480 ×640,以及两个机器人手臂的关节位置(总共7+7=14 DoF)
Intuitively, the transformer encoder synthesizes information from different camera viewpoints, the joint positions, and the style variable, and the transformer decoder generates a coherentaction sequence. The observation includes 4 RGB images, eachat 480 ×640 resolution, and joint positions for two robot arms(7+7=14 DoF in total). - 输出:动作空间是两个机器人的绝对关节位置,一个14维向量。因此,通过动作分块,策略在给定当前观测的情况下输出一个k ×14张量(每个动作都被定义为一个14维的向量,所以k个动作自然便是一个k ×14张量)
The action space is the absolute jointpositions for two robots, a 14-dimensional vector. Thus withaction chunking, the policy outputs a k ×14 tensor giventhe current observation.
1.4.2 推断z
然后,我们使用下图右侧黄色所示的CVAE编码器推断风格变量z
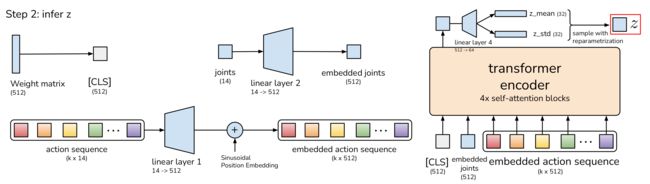
编码器的输入是
- [CLS]token,它由随机初始化的学习权值组成
- 嵌入关节位置embedded joints
通过一个线性层linear layer2,把joints投影到嵌入维度的关节位置(14维到512维):embedded joints - 嵌入动作序列embedded action sequence
通过另一个线性层linear layer1,把k × 14的action sequence投影到嵌入维度的动作序列(k × 14维到k × 512维)
以上三个输入最终形成(k + 2)×embedding_dimension的序列,即(k + 2) × 512,并用transformer编码器进行处理
最后,只取第一个输出,它对应于[CLS]标记,并使用另一个线性网络来预测 分布的均值和方差,将其参数化为对角高斯分布。使用重新参数化获得的样本,这是一种允许在采样过程中反向传播的标准方法,以便编码器和解码器可以联合优化[33]
分布的均值和方差,将其参数化为对角高斯分布。使用重新参数化获得的样本,这是一种允许在采样过程中反向传播的标准方法,以便编码器和解码器可以联合优化[33]
1.4.3 预测动作序列
接下来,我们尝试从CVAE解码器中获得预测的动作,即策略(预测动作序列)
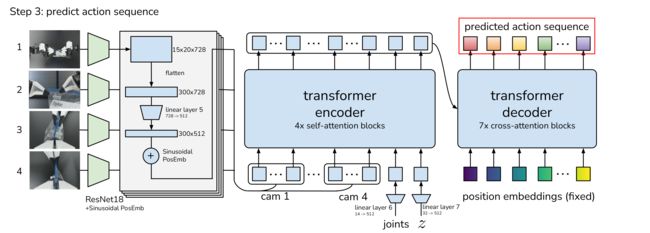
- 首先,对于每一个图像观察,其皆被ResNet18处理以获得一个特征图(将480张×640 ×3 RGB图像转换为15张×20 ×728特征图)
然后flatten化以获得一个特征序列(300×728)
这些特征用线性层linear layer5投影到嵌入维度(300×512)
为了保留空间信息,再添加一个2D正弦位置嵌入(即Sinusoidal PosEmb)
其次,对所有4张图像重复此操作,得到的特征序列维度为1200 ×512
Repeating this for all 4 images gives a feature sequence of 1200 × 512 in dimension.
接着,将来自每个摄像机的特征序列连接起来,用作transformer encoder的输入之一,对于另外两个输入:当前的关节位置joints和“风格变量”z,它们分别通过线性层linear layer6、linear layer7从各自的原始维度(14、15)都统一投影到512
最终,the input to the transformer encoder is 1202×512(相信你很快反应出来了,连接此三:4张图像的特征维度1200 ×512、关节位置joins的特征维度1×512,风格变量z的特征维度1×512) - transformer解码器的输入有两个方面
一方面,transformer解码器的“query”是第一层固定的正弦位置嵌入,即如上图右下角所示的position embeddings(fixed),其维度为k ×512
二方面,transformer解码器的交叉注意力(cross-attention)层中的“keys”和“values”来自上述transformer编码器的输出
即如论文中所述,The transformer decoder conditions on the encoder output through cross-attention, where the input sequence is a fixed position embedding, with dimensions k × 512, and the keys and values are coming from the encoder.
从而,transformer解码器在给定编码器输出的情况下预测动作序列
以下是更多细节
transformer解码器的输出维度是k ×512,然后用MLP向下投影到k ×14,对应于接下来k个步骤的预测目标关节位置
This gives the transformer decoder an output dimension of k × 512, which is then down-projected with an MLP into k × 14, corresponding to the predicted target joint positions for the next k steps.
最终,我们使用L1损失进行重建,而不是更常见的L2损失:我们注意到,L1损失导致对动作序列进行更精确的建模(We use L1 loss for reconstruction instead of the more common L2 loss: we noted that L1 loss leads to more precise modeling of the action sequence. )
我们还注意到,当使用delta关节位置作为动作而不是目标关节位置时,性能会下降(We also noted degraded performance when using delta joint positions as actions instead of target joint positions)
以下是算法1和算法2中ACT的训练和推理。该模型有大约80M个参数,为每个任务从头开始训练。训练在单个11G RTX 2080 Ti GPU上需要大约5个小时,在同一台机器上的推理时间约为0.01秒


1.5 ACT与其他模仿学习方法的比较
我们将ACT与之前的4种模仿学习方法进行比较
- BC-ConvMLP是最简单但最广泛使用的基线[69, 26],它采用卷积网络处理当前图像观测,并将其输出特征与关节位置连接,以预测动作
BC-ConvMLP is the simplest yet most widely used baseline [69, 26], which processes the current image observations with a convolutional network, whose output features are concatenated with the joint positions to predict the action. - BeT [49]也利用Transformer作为架构,但有两个关键区别:
(1)没有对动作进行分块处理,该模型预测给定“观测历史之下”的一个动作
no action chunking: the model predicts one action given the history of observations
(2)图像观测由单独训练的冻结视觉编码器预处理,即感知和控制网络没有联合优化
the image observations are pre-processed by a separately trained frozen visual encoder. That is, the perception and control networks are not jointly optimized. - RT-1 [7]是另一种基于Transformer的架构,从“过去观测中固定长度的历史中”预测一个动作。
RT-1 [7] is another Transformerbased architecture that predicts one action from a fixed-length history of past observations.
BeT和RT-1都离散化了动作空间:输出为离散箱分类分布,在BeT情况下还添加了连续偏移量。而我们的方法ACT直接预测连续动作,这是出于精确操作所需精度驱使
Both BeT and RT-1 discretize the action space: the output is a categorical distribution over discrete bins, but with an added continuous offset from the bincenter in the case of BeT. Our method, ACT, instead directly predicts continuous actions, motivated by the precision required in fine manipulation. - 最后,VINN [42]是一种非参数方法,在测试时假设可以访问演示数据。给定新的观察数据时,它检索具有最相似视觉特征的k个样本,并返回一个加权操作
Lastly, VINN [42] is a non-parametric method that assumes access to the demonstrations at test time. Given a new observation, it retrieves the k observations with
the most similar visual features, and returns an action using weighted k-nearest-neighbors.
且其采用了一个经过预训练的ResNet作为视觉特征提取器,并在无监督学习的演示数据上进行微调。我们通过精心调整超参数,使用立方体转移方法对这四种先前方法进行了优化
The visual feature extractor is a pretrained ResNet finetuned on demonstration data with unsupervised learning. We carefully tune the hyperparameters of these four prior methods using cube transfer.
第二部分 Diffusion Policy
如我组建的复现团队里的邓老师所说,斯坦福mobile aloha团队也用了 diffusion,不过是作为对比实验的打击对象来用的
下面,我们便根据Columbia University、Toyota Research Institute、MIT的研究者联合发布的《Diffusion Policy:Visuomotor Policy Learning via Action Diffusion》这篇论文详细解读下Diffusion Policy
2.1 什么是Diffusion Policy
如下图所示
- a)具有不同类型动作表示的显式策略(Explicit policy with different types of action representations)
- b)隐式策略学习以动作和观察为条件的能量函数,并对最小化能量景观的动作进行优化(Implicit policy learns an energy functionconditioned on both action and observation and optimizes for actions that minimize the energy landscape)
- c)扩散策略通过学习的梯度场将噪声细化为动作。这种表述提供了稳定的训练,允许学习到的策略准确地建模为多模态动作分布,并容纳高维动作序列
Diffusion policy refines noise into actions via a learned gradient field. This formulation provides stable training, allows the learned policy to accurately model multimodalaction distributions, and accommodates high-dimensional action sequences
进一步,所谓扩散策略,是指将机器人的视觉运动策略表示为条件去噪扩散过程来生成机器人行为的新方法
- 扩散策略学习动作-分布评分函数的梯度
即该策略不是直接输出一个动作,而是以视觉观察为条件,对K次去噪迭代推断“动作-得分梯度”(instead of directly outputting an action, the policy infers the action-score gradient, conditioned on visual observations, for K denoising iterations) - 并在推理过程中通过一系列随机朗之万动力学步骤对该梯度场进行迭代优化。扩散公式在用于机器人策略时产生了强大的优势,包括优雅地处理多模态动作分布,适合高维动作空间,并表现出令人印象深刻的训练稳定性
- 为了充分释放扩散模型在物理机器人上进行视觉运动策略学习的潜力,作者团队提出了一套关键的技术贡献,包括将后退视界控制、视觉调节和时间序列扩散transformer结合起来
2.2 Diffusion for Visuomotor Policy Learning
如下图所示
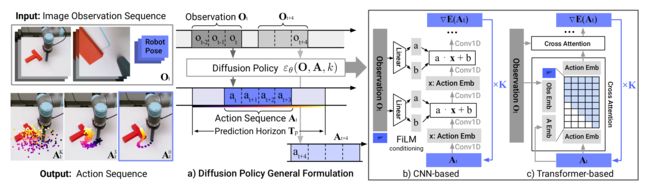
- a)一般情况下,该策略在时间步长
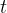 时将最新的
时将最新的 步观测数据
步观测数据 作为输入,并输出
作为输入,并输出 步动作
步动作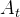
General formulation. At time step t, the policy takes the latest To steps of observation data Ot as input and outputs Ta steps of actions At - b)在基于CNN的扩散策略中,对观测特征应用FiLM(Feature-wise Linear Modulation)[35]来调节每个卷积层通道。从高斯噪声中提取的
 减去噪声估计网络
减去噪声估计网络 的输出,并重复
的输出,并重复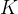 次,得到去噪动作序列
次,得到去噪动作序列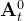 「(这个过程是扩散模型去噪的本质,如不了解DDPM,请详看此文:《AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/Swin transformer》」
「(这个过程是扩散模型去噪的本质,如不了解DDPM,请详看此文:《AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/Swin transformer》」
In the CNN-based Diffusion Policy, FiLM (Feature-wise Linear Modulation) [35] conditioning of the observation feature Ot is applied to every convolution layer, channel-wise. Starting from AtK drawn from Gaussian noise, the outputof noise-prediction network εθ is subtracted, repeating K times to get At0, the denoised action sequence. - c)在基于Transformer的[52]扩散策略中,观测
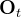 的嵌入被传递到每个Transformer解码器块的多头交叉注意力层。每个动作嵌入使用所示注意力掩码进行约束,仅关注自身和之前的动作嵌入(因果注意)
的嵌入被传递到每个Transformer解码器块的多头交叉注意力层。每个动作嵌入使用所示注意力掩码进行约束,仅关注自身和之前的动作嵌入(因果注意)
In the Transformer-based [52]Diffusion Policy, the embedding of observation Ot is passed into a multi-head cross-attention layer of each transformer decoder block. Eachaction embedding is constrained to only attend to itself and previous action embeddings (causal attention) using the attention mask illustrated.
虽然DDPM通常用于图像生成,但该团队使用DDPM来学习机器人的视觉运动策略。这需要针对DPPM的公式进行两大修改
- 之前输出的是图像,现在需要输出:为机器人的动作(changing the output x to represent robot actions)
- 去噪时所依据的去噪条件为观测Ot (making the denoising processes conditioned on input observation Ot)
具体来说,在时间步,该策略以最新步的观测数据Ot作为输入,预测![]() 步的动作。其中,机器人执行步的动作时无需重新规划。在此定义中,表示观测视界,
步的动作。其中,机器人执行步的动作时无需重新规划。在此定义中,表示观测视界,![]() 表示动作预测视界,而则代表了动作执行视界。这样做既促进了时间动作的一致性,又保持了响应速度
表示动作预测视界,而则代表了动作执行视界。这样做既促进了时间动作的一致性,又保持了响应速度
我们使用DDPM来近似条件分布p(At|Ot),而不是Janner等人[20]用于规划的联合分布p(At,Ot)。这种表述方式允许模型以观察为条件来预测动作,而无需以推断未来状态的成本(This formulation allows the model to predict actionsconditioned on observations without the cost of inferringfuture states),加快扩散过程并提高生成动作的准确性
- 众所周知,从从高斯噪声中采样的
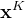 开始,DDPM执行次去噪迭代,以产生一系列降低噪声水平的中间动作,
开始,DDPM执行次去噪迭代,以产生一系列降低噪声水平的中间动作,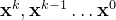 ,直到形成所需的无噪声输出
,直到形成所需的无噪声输出 (说白了,就是去噪)
(说白了,就是去噪)
该过程遵循下述所示的公式1
其中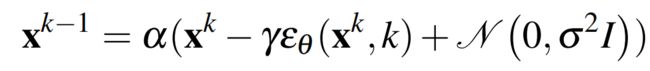 为通过学习优化参数的噪声估计网络,
为通过学习优化参数的噪声估计网络,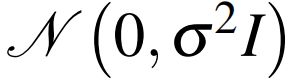 为每次迭代时加入的高斯噪声
为每次迭代时加入的高斯噪声
且上面的公式1也可以理解为一个单一的噪声梯度下降步长,定义为如下公式2
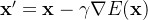
其中噪声估计网络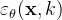 有效地预测了梯度场
有效地预测了梯度场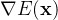 ,
, 为学习速率
为学习速率
此外,公式1中的 、和
、和 作为与迭代步长
作为与迭代步长 相关的函数选择被称为噪声调度,可以理解为梯度下降过程中学习速率的调整策略。经证明,将设定略小于1能够改善稳定性
相关的函数选择被称为噪声调度,可以理解为梯度下降过程中学习速率的调整策略。经证明,将设定略小于1能够改善稳定性
再之后,训练过程首先从数据集中随机抽取未修改的样本。对于每个样本,我们随机选择一个去噪迭代,然后为迭代采样一个具有适当方差的随机噪声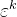
然后要求噪声估计网络从添加噪声的数据样本中预测噪声,如下公式3
最小化公式3所示的损失函数也同时最小化了数据分布p(x0)和从DDPM q(x0)中提取的样本分布之间KL-散度的变分下界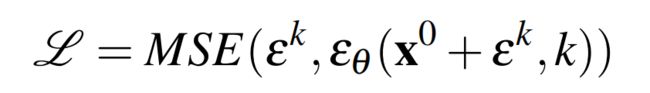
- 为了获取条件分布
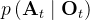 ,将公式1修改为如下公式4
,将公式1修改为如下公式4
将训练损失由公式3修改为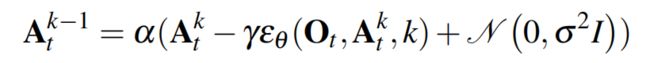

2.2.1 视觉编码器的选型:CNN PK transformer
基于CNN的扩散策略中,采用Janner等人[21]的一维时态CNN,并做了一些修改,如下图所示
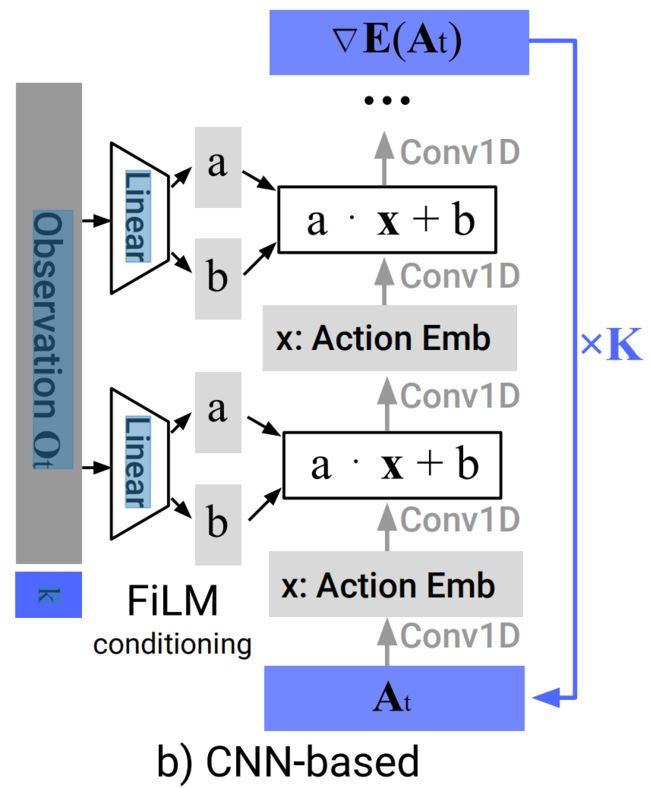
- 首先,我们仅通过特征线性调制(FiLM),和对观测特征的动作生成过程进行调节,并进行去噪迭代,以建模条件分布
- 其次,我们仅预测动作轨迹,而非连接观测动作轨迹(we only predict the action trajectory instead of the concatenated observation action trajectory)
- 第三,利用receding prediction horizon,删除了基于修复的目标状态条件反射。然而,目标条件反射仍然是可能的,与观测所用的FiLM条件反射方法相同
we removed inpainting-based goal state conditioning due to incompatibility with our framework utilizing a receding prediction horizon.However, goal conditioning is still possible with the same FiLM conditioning method used for observations
在实践中发现,基于CNN的骨干网络在大多数任务上表现良好且无需过多超参数调优。然而,当期望的动作序列随着时间快速而急剧变化时(如velocity命令动作空间),它的表现很差,可能是由于时间卷积的归纳偏差[temporal convolutions to prefer lowfrequency signals],以偏好低频信号所致。为减少CNN模型中过度平滑效应[49],我们提出了一种基于Transformer架构、借鉴minGPT[42]思想的DDPM来进行动作预测
如下图所示
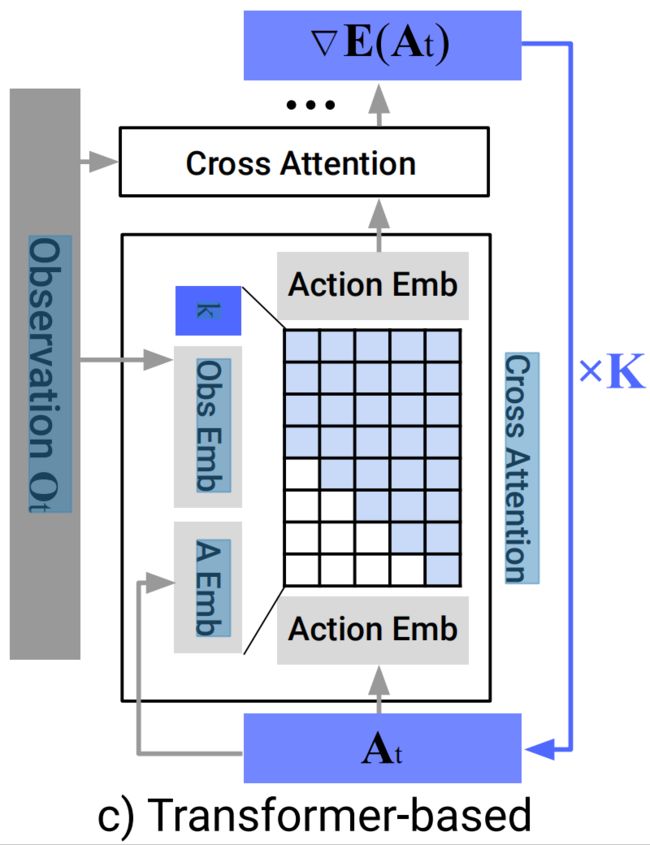
- 行动和噪声
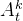 作为transformer解码器块的输入tokens传入,扩散迭代的正弦嵌入作为第一个token(Actions with noise At k are passed in as input tokens for the transformer decoder blocks, with the sinusoidal embedding for diffusion iteration k prepended as the first token)
作为transformer解码器块的输入tokens传入,扩散迭代的正弦嵌入作为第一个token(Actions with noise At k are passed in as input tokens for the transformer decoder blocks, with the sinusoidal embedding for diffusion iteration k prepended as the first token)
观测通过共享的MLP转换为观测嵌入序列,然后作为输入特征传递到transformer解码器堆栈中(The observation Ot is transformed into observation embedding sequence by a shared MLP, which is then passed into the transformer decoder stack as input features)
“梯度”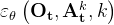 由解码器堆栈的每个对应输出token进行预测(The "gradient" εθ (Ot ,At k , k) is predicted by each corresponding output token of the decoder stack)
由解码器堆栈的每个对应输出token进行预测(The "gradient" εθ (Ot ,At k , k) is predicted by each corresponding output token of the decoder stack) - 在我们的基于状态的实验中,大多数性能最佳的策略都是通过Transformer骨干实现的,特别是当任务复杂度和动作变化率较高时。然而,我们发现Transformer对超参数更敏感
Transformer训练的困难[25]并不是Diffusion Policy所独有的,未来可以通过改进Transformer训练技术或增加数据规模来解决(However, we found the transformer to be more sensitive to hyperparameters. The difficulty of transformer training [25] is not unique to Diffusion Policy and could potentially be resolved in the future with improved transformer training techniques or increased data scale)
故,一般来说,我们建议从基于CNN的扩散策略实施开始,作为新任务的第一次尝试。如果由于任务复杂性或高速率动作变化导致性能低下,那么可以使用时间序列扩散Transformer公式来潜在地提高性能,但代价是额外的调优(In general, we recommend starting with the CNN-based diffusion policy implementation as the first attempt at a new task. If performance is low due to task complexity or high-rate action changes, then the Time-series Diffusion Transformer formulation can be used to potentially improve performance at the cost of additional tuning)
看到上面这里后,我第一反应是想到了此文《视频生成的原理解析:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0、W.A.L.T》第六部分中提到的W.A.L.T:将Transformer用于扩散模型
“23年12月中旬,来自斯坦福大学、谷歌、佐治亚理工学院的研究者提出了 Window Attention Latent Transformer,即窗口注意力隐 Transformer,简称 W.A.L.T
该方法成功地将 Transformer 架构整合到了隐视频扩散模型中,斯坦福大学的李飞飞教授也是该论文的作者之一”
当然,既然提到了视频生成,也顺便说一嘴,如我组建的mobile aloha复现小组里邓老师所说的:“机器人比生成视频,简单太多了,例如视频由一连串图像帧构成,每一帧图像,经常是 256 * 256 * 3 个数值,而机器人只有 14 个数值”
2.2.2 视觉编码器
// 待更
参考文献与推荐阅读
- https://tonyzhaozh.github.io/aloha/