机器学习之逻辑回归-考试通过预测-预测芯片质量通过
分类问题(Classfication)
实例:垃圾邮件检测
任务
- 输入:电子邮件
- 输出:此为垃圾邮件/普通硬件
流程
- 标注样本邮件为垃圾/普通邮件(人)
- 获取批量的样本邮件及其标签,学习其特征(计算机)
- 针对新的邮件,自动判断其类别(计算机)
特征
用于帮助判断是否为垃圾邮件的属性
- 发件人包含字符:%&*#!..
- 正文包含:现金、领取、中奖等
- …
分类
分类:根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类
基本框架:

分类方法
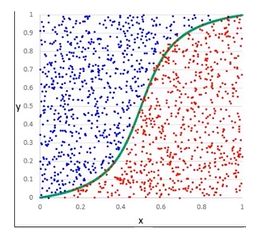
逻辑回归
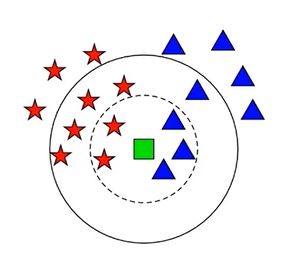
KNN近邻模型
决策树
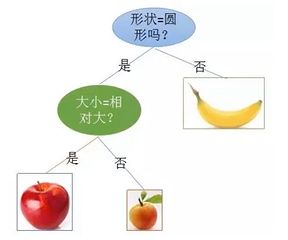
神经网络

分类任务与回归任务的明显区别
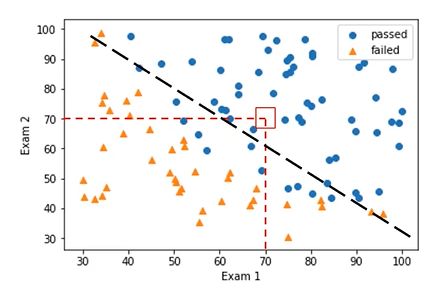
分类目标:判断类别
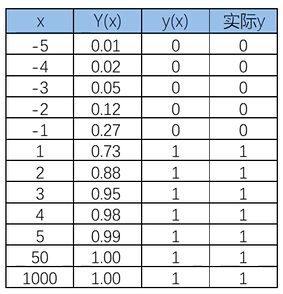
模型输出:非连续型标签
(passed/failed;0/1/2…)
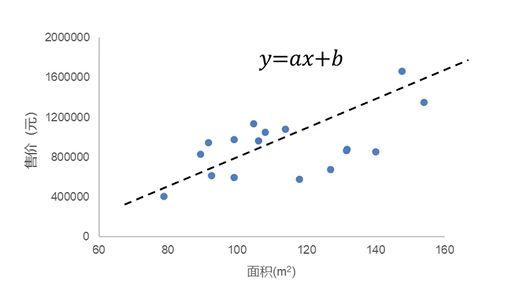
回归目标:建立函数关系
模型输出:连续型数值
(比如0-200000的任意数值)
逻辑回归
分类任务
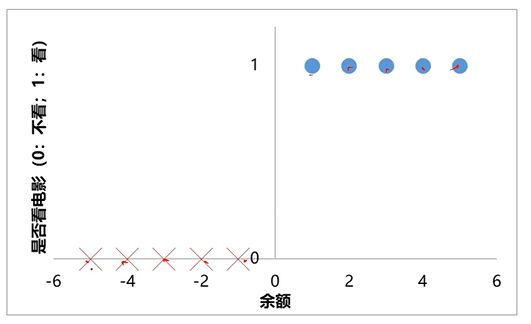
任务:根据余额,判断小明是否会去看电影
训练数据
余额1、2、3、4、5:
看电影(正样本)
余额为-1、-2、-3、-4、-5:
不看电影(负样本)
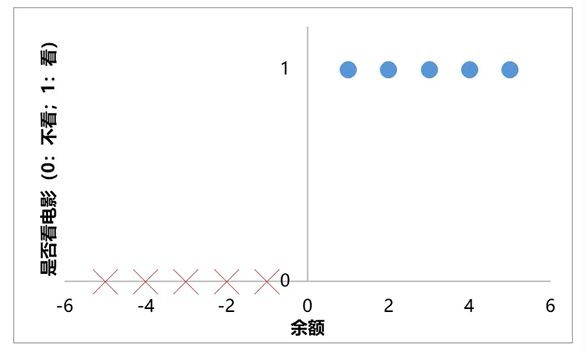


任务:寻找f(x)

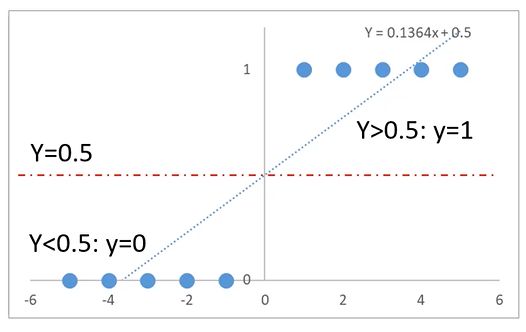
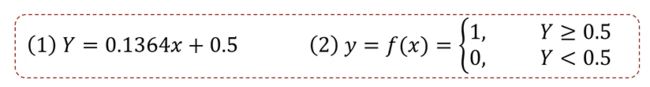
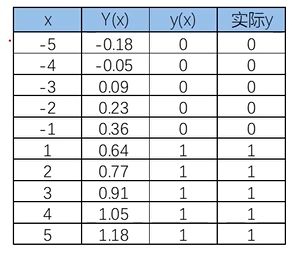
线性回归效果似乎很不错!
线性回归的局限性:样本量变大以后,准确率下降
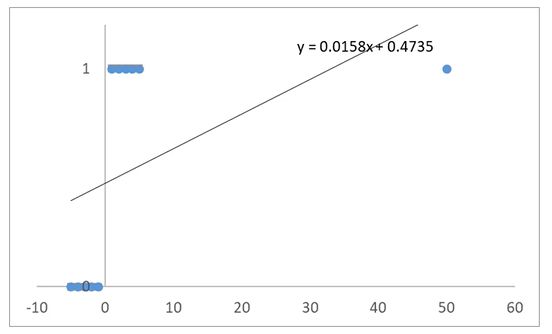
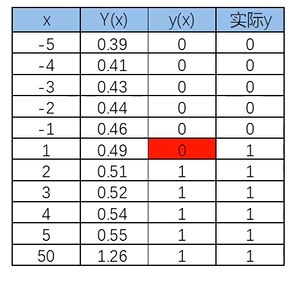
当x距离原点变远,预测开始不准确
逻辑回归
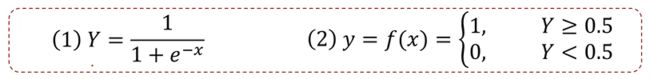
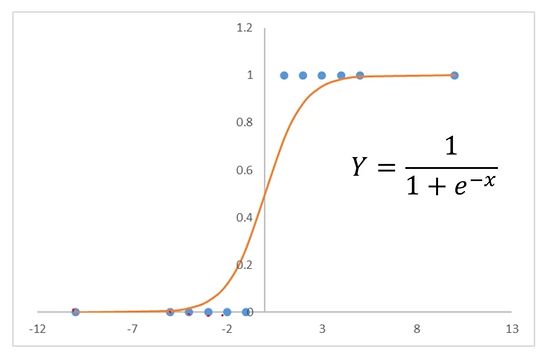
使用逻辑回归拟合数据,可以很好的完成分类任务!
逻辑回归:用于解决分类问题的一种模型。根据数据特征或属性,计算其归属于某一类别的概率P(X),根据概率数值判断其所属类别。主要应用场景:二分类问题。

逻辑回归判断小明是否去看电影(余额-10、100)
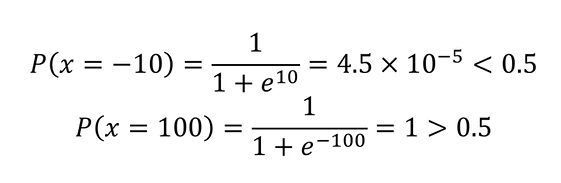
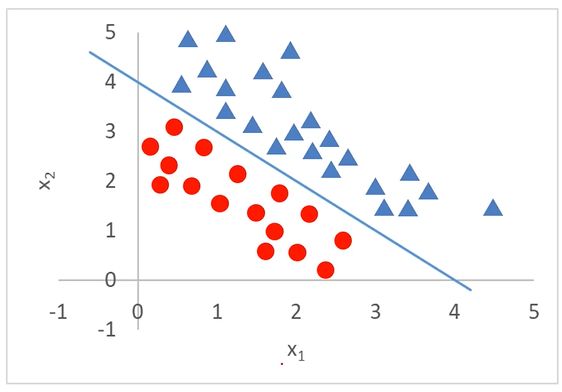
当分类任务变得更为复杂

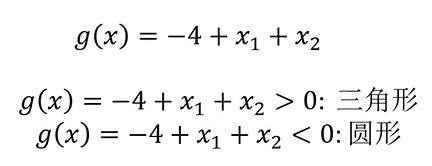
![]()
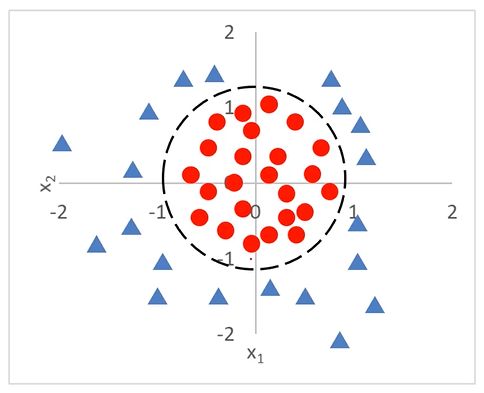
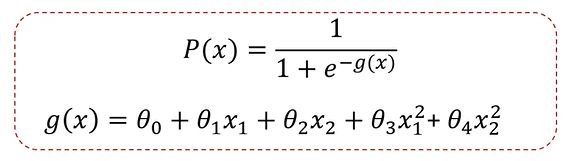
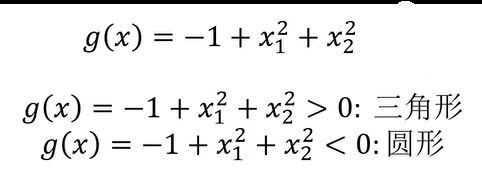

逻辑回归结合多项式边界函数可解决复杂的分类问题
逻辑回归求解
线性回归求解,最小化损伤函数(J):
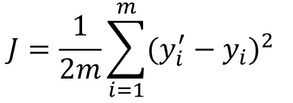
分类问题,标签与预测结果都是离散点,使用该损失函数无法寻找极小值点

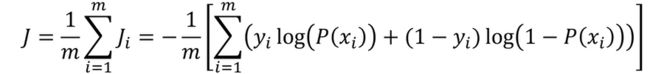
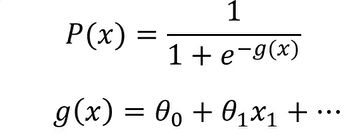
最小化所有样本的损失函数
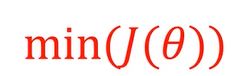
实战准备
图形展示
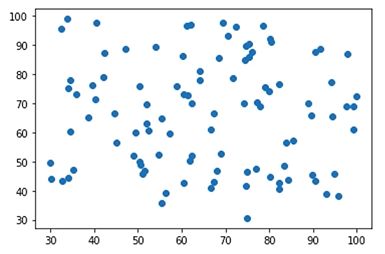
未区分类别散点图
plt.scatter(X1,X2)
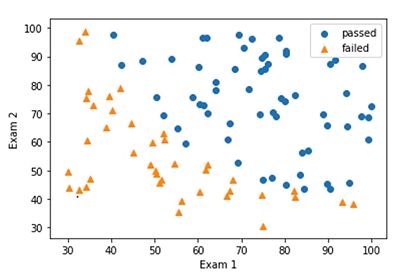
区分类别散点图
mask=y==1
passed=plt.scatter(X1[mask],X2[mask])
failed=plt.scatter(X1[~mask],X2[~mask],marker='^')
逻辑回归实现二分类
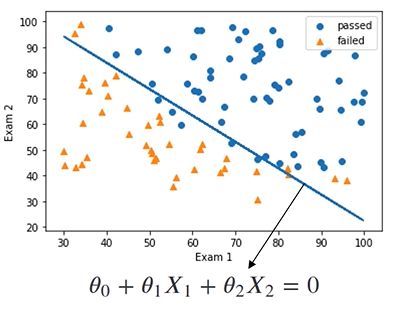
模型训练
from sklearn.linear_model import LogisticRegression
lr_model = LogisticRegression()
lr_model.fit(x,y)
边界函数系数
theta1,theta2 = LR.coef_[0][0],LR.coef_[0][1]
theta0 = LR.intercept_[0]
对新数据做预测
predictions = lr_model.predict(x_new)
生成新的属性数据
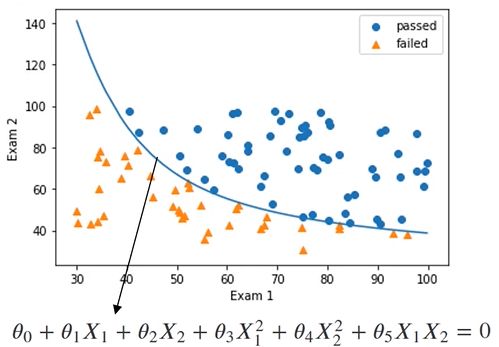
X1_2=X1*X1
X2_2=X2*X2
X1_X2=X1*X2
X_new_dic={'X1':X1,'X2':X2,'X1^2':X1_2,'X2^2':X2_2,'X1X2':X1_X2}
X_new=pd.DataFrame(X_new_dic)
评估模型表现
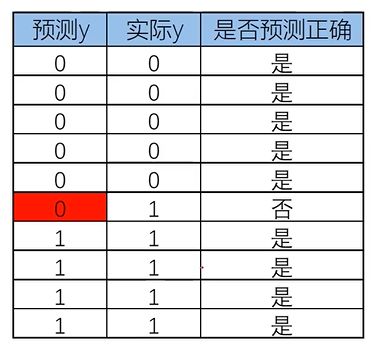
准确率(类别正确预测的比例):

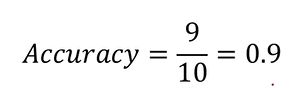
准确率越接近1越好
计算准确率:
from sklearn.metrics import accuracy_score
y_predict = LR.predict(X)
accuracy = accuracy_score(y,y_predict)
画图看决策边界效果,可视化模型表现:
plt.plot(X1,X2_boundary)
passed=plt.scatter(X1[mask],X2[mask])
failed=plt.scatter(X1[~mask],X2[~mask],marker='^')
考试通过预测
- 基于examdata.csv数据,建立逻辑回归,评估模型表现
- 预测Exam1=75,Exam2=60时,该同学能否通过Exam3
- 建立二阶边界函数,重复任务1、2
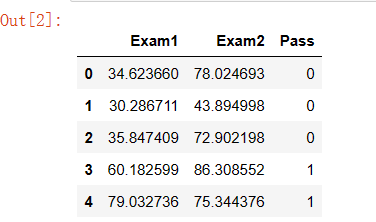
导入包读取数据
import pandas as pd
import numpy as np
data = pd.read_csv('examdata.csv')
data.head()
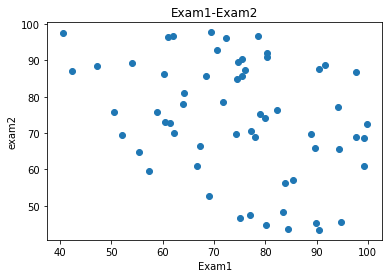
可视化展示数据
from matplotlib import pyplot as plt
fig1 = plt.figure()
plt.scatter(data.loc[:,'Exam1'],data.loc[:,'Exam2'])
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('exam2')
plt.show()

只展示考试通过的考生成绩
mask=data.loc[:,'Pass']==1
fig2 = plt.figure()
plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask])
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('exam2')
plt.show()
通过与未通过的分类展示
fig2 = plt.figure()
passed=plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask])
failed=plt.scatter(data.loc[:,'Exam1'][~mask],data.loc[:,'Exam2'][~mask])
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('exam2')
plt.legend((passed,failed),('passed','failed'))
plt.show()
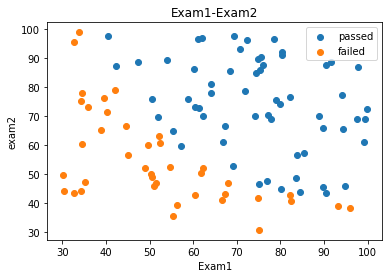
数据预处理
x=data.drop(['Pass'],axis=1)
y=data.loc[:,'Pass']
x1=data.loc[:,'Exam1']
x2=data.loc[:,'Exam2']
建立模型并训练
from sklearn.linear_model import LogisticRegression
LR=LogisticRegression()
LR.fit(x,y)
查看预测结果
# 查看预测结果
y_predict = LR.predict(x)
print(y_predict)
评估模型
#评估模型
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
预测Exam1=75,Exam2=60时,该同学能否通过Exam3
#exam1=70,exam2=65
y_test=LR.predict([[70,65]])
print('passed' if y_test==1 else 'failed')
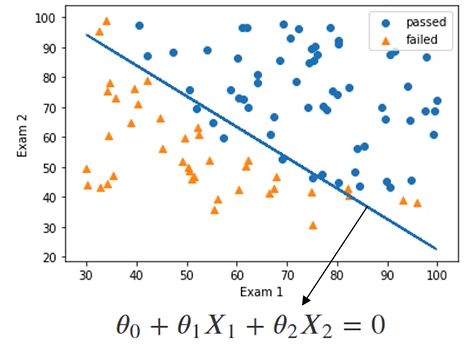
展示边界函数
theta0=LR.intercept_
theta1,theta2=LR.coef_[0][0],LR.coef_[0][1]
print(theta0,theta1,theta2)
x2_new=-(theta0+theta1*x1)/theta2
fig3 = plt.figure()
passed=plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask])
failed=plt.scatter(data.loc[:,'Exam1'][~mask],data.loc[:,'Exam2'][~mask])
plt.plot(x1,x2_new)
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('exam2')
plt.legend((passed,failed),('passed','failed'))
plt.show()
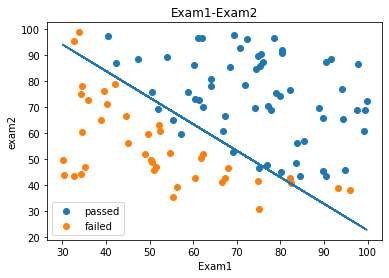
建立二阶边界
# 二阶边界函数
x1_2=x1*x1
x2_2=x2*x2
x1_x2=x1*x2
x_new={'x1':x1,'x2':x2,'x1_2':x1_2,'x2_2':x2_2,'x1_x2':x1_x2}
x_new=pd.DataFrame(x_new)
print(x_new)
# 创建新模型并训练
LR2=LogisticRegression()
LR2.fit(x_new,y)
# 评估模型
y2_predict=LR2.predict(x_new)
accuracy2=accuracy_score(y,y2_predict)
print(accuracy2)
x1_new=x1.sort_values()
theta0=LR2.intercept_
theta1,theta2,theta3,theta4,theta5=LR2.coef_[0][0],LR2.coef_[0][1],LR2.coef_[0][2],LR2.coef_[0][3],LR2.coef_[0][4]
a=theta4
b=theta5*x1_new+theta2
c=theta0+theta1*x1_new+theta3*x1_new*x1_new
x2_new_boundary=(-b+np.sqrt(b*b-4*a*c))/(2*a)
fig5 = plt.figure()
passed=plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask])
failed=plt.scatter(data.loc[:,'Exam1'][~mask],data.loc[:,'Exam2'][~mask])
plt.plot(x1_new,x2_new_boundary)
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('exam2')
plt.legend((passed,failed),('passed','failed'))
plt.show()
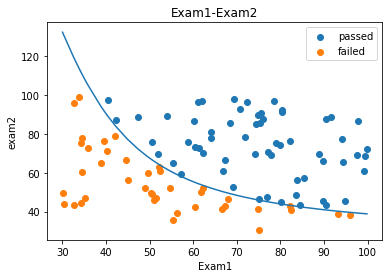
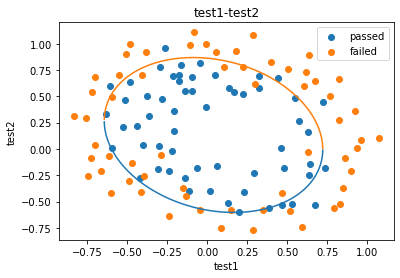
预测芯片质量通过
- 基于chip_test.csv数据,建立逻辑回归模型(二阶边界),评估模型表现
- 以函数的方式求解边界曲线
- 描绘出完整的决策边界曲线
加载数据
import pandas as pd
import numpy as np
data=pd.read_csv('chip_test.csv')
data.head()
可视化
mask=data.loc[:,'pass']==1
from matplotlib import pyplot as plt
fig1=plt.figure()
passed=plt.scatter(data.loc[:,'test1'][mask],data.loc[:,'test2'][mask])
failed=plt.scatter(data.loc[:,'test1'][~mask],data.loc[:,'test2'][~mask])
plt.title('test1-test2')
plt.xlabel('test1')
plt.ylabel('test2')
plt.legend((passed,failed),('passed','failed'))
plt.show()
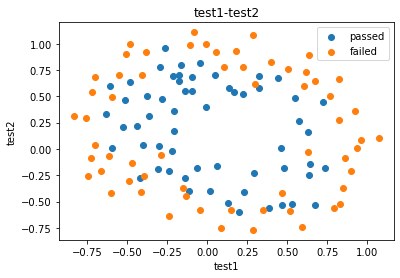
生成新数据
x=data.drop(['pass'],axis=1)
y=data.loc[:,'pass']
x1=data.loc[:,'test1']
x2=data.loc[:,'test2']
x1_2=x1*x1
x2_2=x2*x2
x1_x2=x1*x2
x_new={'x1':x1,'x2':x2,'x1_2':x1_2,'x2_2':x2_2,'x1_x2':x1_x2}
x_new=pd.DataFrame(x_new)
训练模型
from sklearn.linear_model import LogisticRegression
LR2=LogisticRegression()
LR2.fit(x_new,y)
模型评估
from sklearn.metrics import accuracy_score
y2_predict = LR2.predict(x_new)
accuracy2 = accuracy_score(y,y2_predict)
print(accuracy2)
可视化
x1_new=x1.sort_values()
theta0=LR2.intercept_
theta1,theta2,theta3,theta4,theta5=LR2.coef_[0][0],LR2.coef_[0][1],LR2.coef_[0][2],LR2.coef_[0][3],LR2.coef_[0][4]
a=theta4
b=theta5*x1_new+theta2
c=theta0+theta1*x1_new+theta3*x1_new*x1_new
x2_new_boundary=(-b+np.sqrt(b*b-4*a*c))/(2*a)
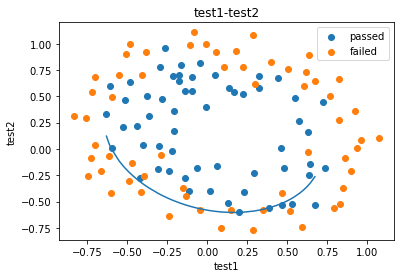
fig2=plt.figure()
passed=plt.scatter(data.loc[:,'test1'][mask],data.loc[:,'test2'][mask])
failed=plt.scatter(data.loc[:,'test1'][~mask],data.loc[:,'test2'][~mask])
plt.plot(x1_new,x2_new_boundary)
plt.title('test1-test2')
plt.xlabel('test1')
plt.ylabel('test2')
plt.legend((passed,failed),('passed','failed'))
plt.show()
以函数的方式求解边界曲线
def f(x):
a=theta4
b=theta5*x+theta2
c=theta0+theta1*x+theta3*x*x
x2_new_boundary1=(-b+np.sqrt(b*b-4*a*c))/(2*a)
x2_new_boundary2=(-b-np.sqrt(b*b-4*a*c))/(2*a)
return x2_new_boundary1,x2_new_boundary2
可视化
x1_range=[-0.9+x/10000 for x in range(0,19000)]
x1_range=np.array(x1_range)
x2_new_boundary1=[]
x2_new_boundary2=[]
for x in x1_range:
x2_new_boundary1.append(f(x)[0])
x2_new_boundary2.append(f(x)[1])
fig4=plt.figure()
passed=plt.scatter(data.loc[:,'test1'][mask],data.loc[:,'test2'][mask])
failed=plt.scatter(data.loc[:,'test1'][~mask],data.loc[:,'test2'][~mask])
plt.plot(x1_range,x2_new_boundary1)
plt.plot(x1_range,x2_new_boundary2)
plt.title('test1-test2')
plt.xlabel('test1')
plt.ylabel('test2')
plt.legend((passed,failed),('passed','failed'))
plt.show()