【题解】—— LeetCode一周小结1
1.经营摩天轮的最大利润
题目链接: 1599. 经营摩天轮的最大利润
你正在经营一座摩天轮,该摩天轮共有 4 个座舱 ,每个座舱 最多可以容纳 4 位游客 。你可以 逆时针 轮转座舱,但每次轮转都需要支付一定的运行成本 runningCost 。摩天轮每次轮转都恰好转动 1 / 4 周。
给你一个长度为 n 的数组 customers , customers[i] 是在第 i 次轮转(下标从 0 开始)之前到达的新游客的数量。这也意味着你必须在新游客到来前轮转 i 次。每位游客在登上离地面最近的座舱前都会支付登舱成本 boardingCost ,一旦该座舱再次抵达地面,他们就会离开座舱结束游玩。
你可以随时停下摩天轮,即便是 在服务所有游客之前 。如果你决定停止运营摩天轮,为了保证所有游客安全着陆,将免费进行所有后续轮转 。注意,如果有超过 4 位游客在等摩天轮,那么只有 4 位游客可以登上摩天轮,其余的需要等待 下一次轮转 。
返回最大化利润所需执行的 最小轮转次数 。 如果不存在利润为正的方案,则返回 -1 。
示例 1:
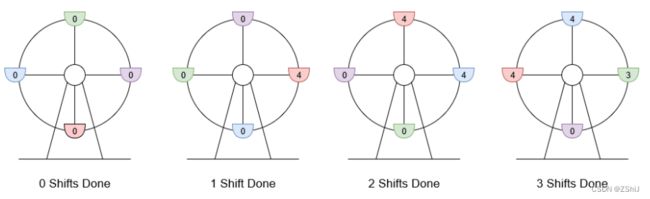
输入:customers = [8,3], boardingCost = 5, runningCost = 6
输出:3
解释:座舱上标注的数字是该座舱的当前游客数。
- 8 位游客抵达,4 位登舱,4 位等待下一舱,摩天轮轮转。当前利润为 4 * $5 - 1 * $6 = $14 。
- 3 位游客抵达,4 位在等待的游客登舱,其他 3 位等待,摩天轮轮转。当前利润为 8 * $5 - 2 * $6 = $28 。
- 最后 3 位游客登舱,摩天轮轮转。当前利润为 11 * $5 - 3 * $6 = $37 。 轮转 3 次得到最大利润,最大利润为 $37 。
示例 2:
输入:customers = [10,9,6], boardingCost = 6, runningCost = 4
输出:7
解释:
- 10 位游客抵达,4 位登舱,6 位等待下一舱,摩天轮轮转。当前利润为 4 * $6 - 1 * $4 = $20 。
- 9 位游客抵达,4 位登舱,11 位等待(2 位是先前就在等待的,9 位新加入等待的),摩天轮轮转。当前利润为 8 * $6 - 2 * $4 = $40 。
- 最后 6 位游客抵达,4 位登舱,13 位等待,摩天轮轮转。当前利润为 12 * $6 - 3 * $4 = $60 。
- 4 位登舱,9 位等待,摩天轮轮转。当前利润为 * $6 - 4 * $4 = $80 。
- 4 位登舱,5 位等待,摩天轮轮转。当前利润为 20 * $6 - 5 * $4 = $100 。
- 4 位登舱,1 位等待,摩天轮轮转。当前利润为 24 * $6 - 6 * $4 = $120 。
- 1 位登舱,摩天轮轮转。当前利润为 25 * $6 - 7 * $4 = $122 。 轮转 7 次得到最大利润,最大利润为$122 。
示例 3:
输入:customers = [3,4,0,5,1], boardingCost = 1, runningCost = 92
输出:-1
解释:
- 3 位游客抵达,3 位登舱,0 位等待,摩天轮轮转。当前利润为 3 * $1 - 1 * $92 = -$89 。
- 4 位游客抵达,4 位登舱,0 位等待,摩天轮轮转。当前利润为 7 * $1 - 2 * $92 = -$177 。
- 0 位游客抵达,0 位登舱,0 位等待,摩天轮轮转。当前利润为 7 * $1 - 3 * $92 = -$269 。
- 5 位游客抵达,4 位登舱,1 位等待,摩天轮轮转。当前利润为 11 * $1 - 4 * $92 = -$357 。
- 1 位游客抵达,2 位登舱,0 位等待,摩天轮轮转。当前利润为 13 * $1 - 5 * $92 = -$447 。 利润永不为正,所以返回 -1 。
提示:
n == customers.length
1 <= n <= 105
0 <= customers[i] <= 50
1 <= boardingCost, runningCost <= 100
题解
新年第一天想到头痛
看了半天题干里面 随时可以停下,免费进行后续 原来是指游客上摩天轮以后就不用管他们了…
方法1:模拟
我们可以直接模拟摩天轮的轮转过程,每次轮转时,累加等待的游客以及新到达的游客,然后最多 4 个人上船,更新等待的游客数和利润,记录最大利润与其对应的轮转次数。
class Solution {
public int minOperationsMaxProfit(int[] customers, int boardingCost, int runningCost) {
int ans = -1; // 初始化答案为-1,表示没有找到最大利润的方案
int max = 0, t = 0; // 初始化最大利润为0,当前总利润为0
int wait = 0, i = 0; // 初始化等待人数为0,轮转次数为0
// 当等待人数大于0或者还有客户需要服务时,继续循环
while (wait > 0 || i < customers.length) {
// 如果还有游客,将等待人数加入等待游客的人数
wait += i < customers.length ? customers[i] : 0;
int up = Math.min(4, wait); // 计算可以上车的人数,最多为4人
wait -= up; // 更新等待人数
i++; // 轮转次数
t += up * boardingCost - runningCost; // 更新当前总利润
if (t > max) { // 如果当前总利润大于最大利润
max = t; // 更新最大利润
ans = i; // 更新答案为当前的轮转次数
}
}
return ans; // 返回答案
}
}
方法2:贪心
维护变量 time 代表转动的次数,那么成本就是 cost = time * runningCost;
维护变量 customer 代表当前有多少等在上摩天轮的游客数量;
枚举 customers[i] 那么当前 下标i 可以看做第几轮转动前的状态,那么更新 customer += customers[i] 得到当前等待的游客数量,由于存在大量游客(大于等于4)的可能,那么我们就可以直接得出,当前的等待游客如果 “尽量凑4人” 需要转多少轮,也就是更新 time += customer // 4 ,假设预计完成的轮次 time 大于当前 下标i 那么很明显,我们可以等后面游客过来补充 “填数”,如此形成循环。这个循环停止,代表当前游客不能再凑齐 4 人了,而且必须启动转一下,那么直接计算转一下把 “剩余游客” 接上。最后外循环判断还有没有下一轮游客过来即可;
整个过程记录其最大利润并记录这个例如出现时的 time 即为答案;
ps:计算如果直接用除法、乘法和余法会非常慢,可以直接位运算加速
class Solution {
public int minOperationsMaxProfit(int[] customers, int boardingCost, int runningCost) {
// 如果每次摩天轮的载客量乘以4小于等于运行成本,则无法盈利,返回-1
if (boardingCost * 4 <= runningCost) return -1;
int customer = 0, time = 0, income = 0, bestRes = 0, bestTime = -1;
for (int i = 0; i < customers.length; ) {
// 计算当前轮次前是否有新的游客加入,如果之前存在游客,尽量凑 4 人
for (; i < customers.length && i <= time; i++) {
customer += customers[i]; // 累加游客人数
income += (customer >> 2 << 2) * boardingCost; // 计算收入
time += customer >> 2; // 更新轮转次数
customer &= 3; // 更新剩余游客人数
}
// 上轮循环跳出证明当前出现无游客凑够 4 人的情况,所以先核算之前满载 4 人的最优情况下利润是否创新高
if (bestRes < income - runningCost * time) {
bestRes = income - runningCost * time; // 更新最佳利润
bestTime = time; // 更新轮转次数
}
// 到这里证明游客少于 4 人,且必须转动,那么就直接计算并判断
income += boardingCost * customer; // 计算收入
customer = 0; // 更新剩余游客人数
time++; // 更新轮转次数
if (bestRes < income - runningCost * time) {
bestRes = income - runningCost * time; // 更新最佳利润
bestTime = time; // 更新轮转次数
}
}
return bestTime; // 返回轮转次数
}
}
2.统计重复个数
题目链接:466. 统计重复个数
定义 str = [s, n] 表示 str 由 n 个字符串 s 连接构成。
- 例如,
str == ["abc", 3] =="abcabcabc"。
如果可以从 s2 中删除某些字符使其变为 s1,则称字符串 s1 可以从字符串 s2 获得。
- 例如,根据定义,
s1 = "abc"可以从s2 = "abdbec"获得,仅需要删除加粗且用斜体标识的字符。
现在给你两个字符串 s1 和 s2 和两个整数 n1 和 n2 。由此构造得到两个字符串,其中 str1 = [s1, n1]、str2 = [s2, n2] 。
请你找出一个最大整数 m ,以满足 str = [str2, m] 可以从 str1 获得。
示例 1:
输入:s1 = “acb”, n1 = 4, s2 = “ab”, n2 = 2
输出:2
示例 2:
输入:s1 = “acb”, n1 = 1, s2 = “acb”, n2 = 1
输出:1
提示:
1 <= s1.length, s2.length <= 100
s1 和 s2 由小写英文字母组成
1 <= n1, n2 <= 106
题解
方法(来自官方题解):找出循环节(个人觉得太麻烦)
思路
由于题目中的 n1 和 n2 都很大,因此我们无法真正把 S1 = [s1, n1] 和 S2 = [s2, n2] 都显式地表示出来。由于这两个字符串都是不断循环的,因此我们可以考虑找出 S2 在 S1 中出现的循环节,如果我们找到了循环节,那么我们就可以很快算出 S2 在 S1 中出现了多少次了。
有些读者可能对循环节这个概念会有些陌生,这个概念我们可以类比无限循环小数,如果从小数部分的某一位起向右进行到某一位止的一节数字「循环」出现,首尾衔接,称这种小数为「无限循环小数」,这一节数字称为「无限循环小数」。比如对于 3.56789789789… 这个无限循环小数,它的小数部分就是以 789 为一个「循环节」在无限循环,且开头可能会有部分不循环的部分,这个数字中即为 56。
那么回到这题,我们可以将不断循环的 s2 组成的字符串类比作上面小数部分,去找是否存在一个子串,即「循环节」,满足不断在 S2 中循环,且这个循环节能对应固定数量的 s1 。如下图所示,在第一次出现后,S2 的子串 bdadc 构成一个循环节:之后 bdadc 的每次出现都需要有相应的两段 s1。

当我们找出循环节后,我们即可知道一个循环节内包含 s1 的数量,以及在循环节出现前的 s1 的数量,这样就可以在 O(1)的时间内,通过简单的运算求出 s2 在 S1 中出现的次数了。当然,由于 S1 中 s1 的数量 n1 是有限的,因此可能会存在循环节最后一个部分没有完全匹配,如上图最后会单独剩一个 s1 出来无法完全匹配完循环节,这部分我们需要单独拿出来遍历处理统计。
有些读者可能会怀疑循环节是否一定存在,这里我们给出的答案是肯定的,根据鸽笼原理,我们最多只要找过 |s2| + 1 个 s1,就一定会出现循环节。
class Solution {
public int getMaxRepetitions(String s1, int n1, String s2, int n2) {
if (n1 == 0) {
return 0;
}
int s1cnt = 0, index = 0, s2cnt = 0;
// recall 是我们用来找循环节的变量,它是一个哈希映射
// 我们如何找循环节?假设我们遍历了 s1cnt 个 s1,此时匹配到了第 s2cnt 个 s2 中的第 index 个字符
// 如果我们之前遍历了 s1cnt' 个 s1 时,匹配到的是第 s2cnt' 个 s2 中同样的第 index 个字符,那么就有循环节了
// 我们用 (s1cnt', s2cnt', index) 和 (s1cnt, s2cnt, index) 表示两次包含相同 index 的匹配结果
// 那么哈希映射中的键就是 index,值就是 (s1cnt', s2cnt') 这个二元组
// 循环节就是;
// - 前 s1cnt' 个 s1 包含了 s2cnt' 个 s2
// - 以后的每 (s1cnt - s1cnt') 个 s1 包含了 (s2cnt - s2cnt') 个 s2
// 那么还会剩下 (n1 - s1cnt') % (s1cnt - s1cnt') 个 s1, 我们对这些与 s2 进行暴力匹配
// 注意 s2 要从第 index 个字符开始匹配
Map<Integer, int[]> recall = new HashMap<Integer, int[]>();
int[] preLoop = new int[2];
int[] inLoop = new int[2];
while (true) {
// 我们多遍历一个 s1,看看能不能找到循环节
++s1cnt;
for (int i = 0; i < s1.length(); ++i) {
char ch = s1.charAt(i);
if (ch == s2.charAt(index)) {
index += 1;
if (index == s2.length()) {
++s2cnt;
index = 0;
}
}
}
// 还没有找到循环节,所有的 s1 就用完了
if (s1cnt == n1) {
return s2cnt / n2;
}
// 出现了之前的 index,表示找到了循环节
if (recall.containsKey(index)) {
int[] value = recall.get(index);
int s1cntPrime = value[0];
int s2cntPrime = value[1];
// 前 s1cnt' 个 s1 包含了 s2cnt' 个 s2
preLoop = new int[]{s1cntPrime, s2cntPrime};
// 以后的每 (s1cnt - s1cnt') 个 s1 包含了 (s2cnt - s2cnt') 个 s2
inLoop = new int[]{s1cnt - s1cntPrime, s2cnt - s2cntPrime};
break;
} else {
recall.put(index, new int[]{s1cnt, s2cnt});
}
}
// ans 存储的是 S1 包含的 s2 的数量,考虑的之前的 preLoop 和 inLoop
int ans = preLoop[1] + (n1 - preLoop[0]) / inLoop[0] * inLoop[1];
// S1 的末尾还剩下一些 s1,我们暴力进行匹配
int rest = (n1 - preLoop[0]) % inLoop[0];
for (int i = 0; i < rest; ++i) {
for (int j = 0; j < s1.length(); ++j) {
char ch = s1.charAt(j);
if (ch == s2.charAt(index)) {
++index;
if (index == s2.length()) {
++ans;
index = 0;
}
}
}
}
// S1 包含 ans 个 s2,那么就包含 ans / n2 个 S2
return ans / n2;
}
}
方法:递归
我们预处理出以字符串 s2 的每个位置 i 开始匹配一个完整的 s1 后,下一个位置 jjj 以及经过了多少个 s2,即 d[i]=(cnt,j),其中 cnt 表示匹配了多少个 s2,而 j 表示字符串 s2 的下一个位置。
接下来,我们初始化 j=0,然后循环 n1 次,每一次将 d[j][0] 加到答案中,然后更新 j=d[j][1]。
最后得到的答案就是 n1 个 s1所能匹配的 s2 的个数,除以 n2 即可得到答案。
class Solution {
public int getMaxRepetitions(String s1, int n1, String s2, int n2) {
int len1 = s1.length();
int len2 = s2.length();
int[][] DP = new int[len2][0]; // 0 记录s2匹配的个数 1 记录下一个s2匹配的位置
for (int i = 0; i < len2; i++) {
int j = i; // 记录下一个s2匹配的位置
int cnt = 0; // 记录s2匹配的个数: 一个s1中可能含有多个s2串
for (int k = 0; k < len1; k++) { // 遍历s1字符串进行匹配
if (s1.charAt(k) == s2.charAt(j)) { // 匹配相同的字符串
j++; // 指向下一个位置
if (j == len2) { // s2匹配完一段
j = 0; // 重置索引
cnt++; // 匹配个数加1
}
}
}
// 循环结束,j的位置始终对标在s1中的位置
DP[i] = new int[]{cnt, j}; // 匹配完一次 则将结果添加到数组中
}
int ans = 0; // 定义结果变量
for (int j = 0; n1 > 0; n1--) { // 遍历n1,记录每个循环中s2下标出现的数量
ans += DP[j][0]; // 累加匹配数
j = DP[j][1]; // 获取下一个位置
}
return ans / n2; // 将n2个s2作为一个整体数量,砍掉n2个就是结果
}
}
3.从链表中移除节点
题目链接:2487. 从链表中移除节点
给你一个链表的头节点 head 。
移除每个右侧有一个更大数值的节点。
返回修改后链表的头节点 head 。
示例 1:

输入:head = [5,2,13,3,8]
输出:[13,8]
解释:需要移除的节点是 5 ,2 和 3 。
- 节点 13 在节点 5 右侧。
- 节点 13 在节点 2 右侧。
- 节点 8 在节点 3 右侧。
示例 2:
输入:head = [1,1,1,1]
输出:[1,1,1,1]
解释:每个节点的值都是 1 ,所以没有需要移除的节点。
提示:
给定列表中的节点数目在范围 [1, 105] 内
1 <= Node.val <= 105
题解
方法:递归
由题意可知,节点对它右侧的所有节点都没有影响,因此我们可以对它的右侧节点递归地进行移除操作:
-
该节点为空,那么递归函数返回空指针。
-
该节点不为空,那么先对它的右侧节点进行移除操作,得到一个新的子链表,如果子链表的表头节点值大于该节点的值,那么移除该节点,否则将该节点作为子链表的表头节点,最后返回该子链表。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeNodes(ListNode head) {
if (head == null) {
return null;
}
head.next = removeNodes(head.next);
if (head.next != null && head.val < head.next.val) {
return head.next;
} else {
return head;
}
}
}
4.被列覆盖的最多行数
题目链接:2397. 被列覆盖的最多行数
给你一个下标从 0 开始、大小为 m x n 的二进制矩阵 matrix ;另给你一个整数 numSelect,表示你必须从 matrix 中选择的 不同 列的数量。
如果一行中所有的 1 都被你选中的列所覆盖,则认为这一行被 覆盖 了。
形式上,假设 s = {c1, c2, ...., cnumSelect} 是你选择的列的集合。对于矩阵中的某一行 row ,如果满足下述条件,则认为这一行被集合 s 覆盖:
- 对于满足
matrix[row][col] == 1的每个单元格matrix[row][col](0 <= col <= n - 1),col均存在于s中,或者 row中 不存在 值为1的单元格。
你需要从矩阵中选出numSelect个列,使集合覆盖的行数最大化。
返回一个整数,表示可以由 numSelect 列构成的集合 覆盖 的 最大行数 。
示例 1:
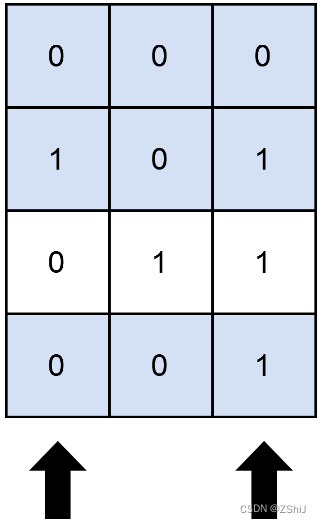
输入:matrix = [[0,0,0],[1,0,1],[0,1,1],[0,0,1]], numSelect = 2
输出:3
解释:
图示中显示了一种覆盖 3 行的可行办法。 选择 s = {0, 2} 。
- 第 0 行被覆盖,因为其中没有出现 1 。
- 第 1 行被覆盖,因为值为 1 的两列(即 0 和 2)均存在于 s 中。
- 第 2 行未被覆盖,因为 matrix[2][1] == 1 但是 1 未存在于 s 中。
- 第 3 行被覆盖,因为 matrix[2][2] == 1 且 2 存在于 s 中。 因此,可以覆盖 3 行。 另外 s = {1, 2} 也可以覆盖 3 行,但可以证明无法覆盖更多行。
示例 2:
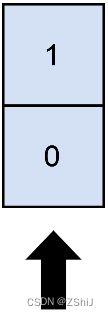
输入:matrix = [[1],[0]], numSelect = 1
输出:2
解释:
选择唯一的一列,两行都被覆盖了,因为整个矩阵都被覆盖了。 所以我们返回 2 。
提示:
m == matrix.length
n == matrix[i].length
1 <= m, n <= 12
matrix[i][j]要么是 0 要么是 1
1 <= numSelect <= n
题解
方法:二进制枚举
我们先将矩阵中的每一行转换成一个二进制数,记录在数组 rows中,其中 rows[i]表示第 i 行对应的二进制数,而 rows[i] 这个二进制数的第 j 位表示矩阵第 i 行第 j 列的值。
接下来,我们枚举所有的 2n2 种列选择方案,其中 n 为矩阵的列数。对于每一种列选择方案,我们判断是否选中了 numSelect列,如果不是,则跳过。否则,我们统计矩阵中有多少行中的所有 1 都被选中的列覆盖,即统计有多少行的二进制数 rows[i]与列选择方案 mask 按位与的结果等于 rows[i],并更新最大的行数。
class Solution {
public int maximumRows(int[][] matrix, int numSelect) {
// 获取矩阵的行数m和列数n
int m = matrix.length, n = matrix[0].length;
// 定义一个长度为m的一维数组rows,用于存储每一行的二进制表示
int[] rows = new int[m];
// 遍历矩阵的每一行
for (int i = 0; i < m; ++i) {
// 遍历矩阵的每一列
for (int j = 0; j < n; ++j) {
// 如果当前位置的元素值为1,则将该位置对应的二进制位设置为1
if (matrix[i][j] == 1) {
rows[i] |= 1 << j;
}
}
}
// 初始化答案ans为0
int ans = 0;
// 遍历所有可能的二进制掩码(从1到2^n-1)
for (int mask = 1; mask < 1 << n; ++mask) {
// 如果当前掩码中1的个数不等于numSelect,则跳过当前循环
if (Integer.bitCount(mask) != numSelect) {
continue;
}
// 初始化计数器t为0
int t = 0;
// 遍历每一行的二进制表示
for (int x : rows) {
// 如果当前行的二进制表示与当前掩码进行按位与运算后的结果等于当前行的二进制表示,则计数器t加1
if ((x & mask) == x) {
++t;
}
}
// 更新答案ans为ans和t中的较大值
ans = Math.max(ans, t);
}
// 返回答案ans
return ans;
}
}
5.队列中可以看到的人数
题目链接:1944. 队列中可以看到的人数
有 n 个人排成一个队列,从左到右 编号为 0 到 n - 1 。给你以一个整数数组 heights ,每个整数 互不相同,heights[i] 表示第 i 个人的高度。
一个人能 看到 他右边另一个人的条件是这两人之间的所有人都比他们两人 矮 。更正式的,第 i 个人能看到第 j 个人的条件是 i < j 且 min(heights[i], heights[j]) > max(heights[i+1], heights[i+2], …, heights[j-1]) 。
请你返回一个长度为 n 的数组 answer ,其中 answer[i] 是第 i 个人在他右侧队列中能 看到 的 人数 。
示例 1:
输入:heights = [10,6,8,5,11,9]
输出:[3,1,2,1,1,0]
解释:
第 0 个人能看到编号为 1 ,2 和
4 的人。
第 1 个人能看到编号为 2 的人。
第 2 个人能看到编号为 3 和 4 的人。
第 3 个人能看到编号为 4 的人。
第 4个人能看到编号为 5 的人。
第 5 个人谁也看不到因为他右边没人。
示例 2:
输入:heights = [5,1,2,3,10]
输出:[4,1,1,1,0]
提示:
n == heights.length
1 <= n <= 105
1 <= heights[i] <= 105
heights 中所有数 互不相同 。
提示 1
如何在二次复杂度中解决这个问题?
提示 2
对于从索引i开始的每个子数组,继续寻找新的最大值,直到找到一个大于arr[i]的值。
提示 3
因为极限很高,你需要一个线性解。
提示 4
在从末尾到开始迭代数组时,使用堆栈来保持数组值的排序。
提示 5
继续从堆栈中弹出元素,直到找到一个大于arr[i]的值,这些是我可以看到的人。
题解
方法:单调栈
由题可知,对于第 i 个人来说,他能看到的人一定是按从左到右高度严格单调递增的。
因此,我们可以倒序遍历数组 heights,用一个从栈顶到栈底单调递增的栈 stk 记录已经遍历过的人的高度。
对于第 i 个人,如果栈不为空并且栈顶元素小于 heights[i],累加当前第 i 个人能看到的人数,然后将栈顶元素出栈,直到栈为空或者栈顶元素大于等于 heights[i]。如果此时栈不为空,说明栈顶元素大于等于 heights[i],那么第 i 个人能看到的人数还要再加 1。
接下来,我们将 heights[i]入栈,继续遍历下一个人。
遍历结束后,返回答案数组 ans。
class Solution {
public int[] canSeePersonsCount(int[] heights) {
int n = heights.length;
int[] ans = new int[n];
Deque<Integer> stk = new ArrayDeque<>(); // 双端队列stk,用于存储高度信息
for (int i = n - 1; i >= 0; --i) { // 倒序遍历数组
while (!stk.isEmpty() && stk.peek() < heights[i]) { // 如果栈不为空且栈顶元素小于当前元素
stk.pop(); // 弹出栈顶元素
++ans[i];
}
if (!stk.isEmpty()) {
++ans[i];
}
stk.push(heights[i]); // 将当前元素压入栈中
}
return ans;
}
}
6.在链表中插入最大公约数
题目链接: 2807. 在链表中插入最大公约数
给你一个链表的头 head ,每个结点包含一个整数值。
在相邻结点之间,请你插入一个新的结点,结点值为这两个相邻结点值的 最大公约数 。
请你返回插入之后的链表。
两个数的 最大公约数 是可以被两个数字整除的最大正整数。
示例 1:
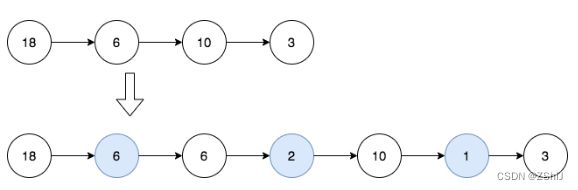
输入:head = [18,6,10,3]
输出:[18,6,6,2,10,1,3]
解释:第一幅图是一开始的链表,第二幅图是插入新结点后的图(蓝色结点为新插入结点)。
- 18 和 6 的最大公约数为 6 ,插入第一和第二个结点之间。
- 6 和 10 的最大公约数为 2 ,插入第二和第三个结点之间。
- 10 和 3 的最大公约数为 1 ,插入第三和第四个结点之间。
所有相邻结点之间都插入完毕,返回链表。
示例 2:
输入:head = [7]
输出:[7]
解释:第一幅图是一开始的链表,第二幅图是插入新结点后的图(蓝色结点为新插入结点)。
没有相邻结点,所以返回初始链表。
提示:
链表中结点数目在 [1, 5000] 之间。
1 <= Node.val <= 1000
题解
方法:遍历
遍历链表,在当前节点node 后面插入gcd节点,同时gcd节点指向下一个node 节点。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
// 插入最大公约数节点的方法
public ListNode insertGreatestCommonDivisors(ListNode head) {
ListNode node = head; // 初始化当前节点为头节点
while (node.next != null) { // 遍历链表,直到最后一个节点
node.next = new ListNode(gcd(node.val, node.next.val), node.next); // 将当前节点的下一个节点替换为最大公约数节点
node = node.next.next; // 移动到新插入的最大公约数节点的下一个节点
}
return head; // 返回修改后的链表头节点
}
// 计算两个整数的最大公约数的方法
public int gcd(int a, int b) {
while (b != 0) { // 当b不为0时,继续循环
int tmp = a % b; // 计算a除以b的余数
a = b; // 将b的值赋给a
b = tmp; // 将余数赋给b
}
return a; // 返回最大公约数
}
}
7.赎金信
题目链接:383. 赎金信
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
如果可以,返回 true ;否则返回 false 。
magazine 中的每个字符只能在 ransomNote 中使用一次。
示例 1:
输入:ransomNote = “a”, magazine = “b”
输出:false
示例 2:
输入:ransomNote = “aa”, magazine = “ab”
输出:false
示例 3:
输入:ransomNote = “aa”, magazine = “aab”
输出:true
提示:
1 <= ransomNote.length, magazine.length <= 105
ransomNote 和 magazine 由小写英文字母组成
题解
class Solution {
public boolean canConstruct(String ransomNote, String magazine) {
int[] memo = new int[26];
// 遍历magazine字符串中的每个字符,将其转换为小写字母后在memo数组中对应的位置加1
for (char ch : magazine.toCharArray()) memo[ch - 'a']++;
// 遍历ransomNote字符串中的每个字符,将其转换为小写字母后在memo数组中对应的位置减1
for (char ch : ransomNote.toCharArray()) if (--memo[ch - 'a'] < 0) return false;
// 如果减1后的值小于0,说明ransomNote中的某个字符在magazine中不存在,返回false
// 如果ransomNote中的所有字符都在magazine中存在,返回true
return true;
}
}