re:Invent 2023 技术上新|知识库现在可以在 Amazon Bedrock 中提供完全托管的 RAG 体验...

亚马逊云科技在去年9月推出了 Amazon Bedrock 知识库预览版。如今,Amazon Bedrock 知识库也已经正式发布。借助知识库,您可以将 Amazon Bedrock 中的基础模型(FM)安全连接到您的公司数据,以实现检索式增强生成(RAG)。访问其他数据有助于模型生成更相关、更具体和更准确的响应,而无需不断重新训练 FM。从知识库检索的所有信息都带有来源归因,以提高透明度并最大限度地减少幻觉。如果您想知道它的工作原理,可以浏览之前的博文,其中包括 RAG 入门介绍:https://aws.amazon.com/cn/blogs/aws/preview-connect-foundation-models-to-your-company-data-sources-with-agents-for-amazon-bedrock/
知识库将为您提供完全托管的 RAG 体验,这也是在 Amazon Bedrock 中开始使用 RAG 最简单的方法。知识库现在可以管理初始向量存储设置,处理嵌入和查询,并提供生产 RAG 应用程序所需的来源归因和短期内存。如果需要,您还可以自定义 RAG 工作流程,以满足特定用例的要求或将 RAG 与其他生成式 AI 工具和应用程序集成。
完全托管的 RAG 体验
Amazon Bedrock 知识库可为您管理端到端的 RAG 工作流程。您可以指定数据的位置,选择嵌入模型以将数据转换为向量嵌入,然后让 Amazon Bedrock 在您的账户中创建一个向量存储,来存储向量数据。当您选择此选项(仅在控制台中可用)时,Amazon Bedrock 会在您账户中的 Amazon OpenSearch 无服务器中创建一个向量索引,所以无需自行管理任何内容。
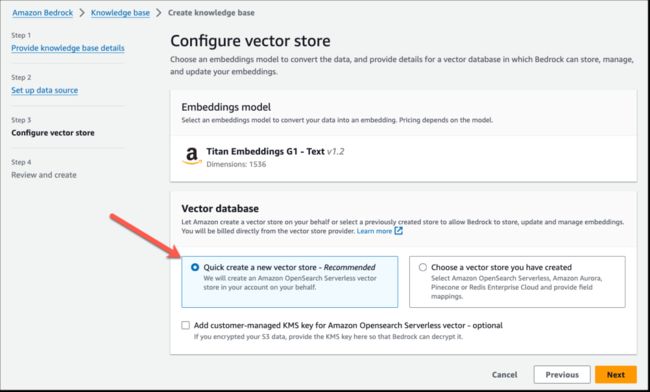
向量嵌入包括文档中文本数据的数字表示形式。每个嵌入都旨在捕获数据的语义或上下文含义。Amazon Bedrock 负责创建、存储、管理和更新向量存储中的嵌入,并确保您的数据始终与向量存储同步。
Amazon Bedrock 现在还支持 RAG 的两个新 API,用于处理嵌入和查询,并提供生产 RAG 应用程序所需的来源归因和短期内存。
借助新的 RetrieveAndGenerate API,您可以直接从知识库检索相关信息,并通过在 API 调用中指定 FM,让 Amazon Bedrock 根据结果生成响应。我向大家演示一下是如何操作的。
使用 RetrieveAndGenerate API
不妨尝试一下,请导航到 Amazon Bedrock 控制台,创建并选择一个知识库,然后选择测试知识库。在这个演示中,我创建了一个知识库,该知识库可以访问亚马逊云科技上生成式 AI 的 PDF 版本。我选择选择模型来指定 FM。
然后,我问:“什么是 Amazon Bedrock?”
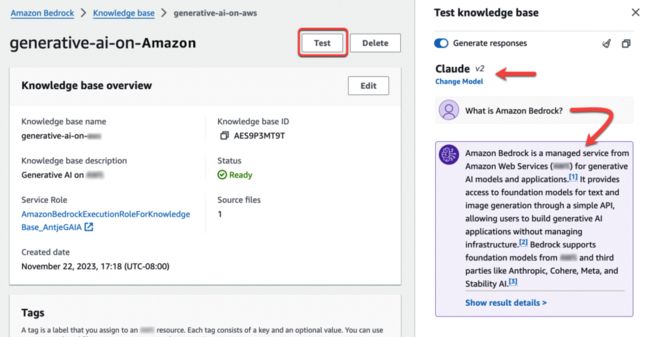
在后台,Amazon Bedrock 将查询转换为嵌入,查询知识库,然后使用搜索结果作为上下文信息来增强 FM 提示,并返回 FM 生成的对我所提问题的响应。对于多轮对话,知识库管理对话的短期内存,以提供更多上下文结果。
在此进行一个快速演示,展示如何在适用于 Python 的 Amazon SDK(Boto3)中使用 API。
Python
def retrieveAndGenerate(input, kbId):
return bedrock_agent_runtime.retrieve_and_generate(
input={
'text': input
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kbId,
'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-instant-v1'
}
}
)
response = retrieveAndGenerate("What is Amazon Bedrock?", "AES9P3MT9T")["output"]["text"]
PythonRetrieveAndGenerate API 的输出包括生成的响应、来源归因和检索到的文本块。在我的演示中,API 响应如下(为简洁起见,我对部分输出进行了编辑):
{ ...
'output': {'text': 'Amazon Bedrock is a managed service from AWS that ...'},
'citations':
[{'generatedResponsePart':
{'textResponsePart':
{'text': 'Amazon Bedrock is ...', 'span': {'start': 0, 'end': 241}}
},
'retrievedReferences':
[{'content':
{'text': 'All AWS-managed service API activity...'},
'location': {'type': 'S3', 's3Location': {'uri': 's3://data-generative-ai-on-aws/gaia.pdf'}}},
{'content':
{'text': 'Changing a portion of the image using ...'},
'location': {'type': 'S3', 's3Location': {'uri': 's3://data-generative-ai-on-aws/gaia.pdf'}}}, ...]
...}]
}生成的响应如下:
Amazon Bedrock 是一项托管服务,通过简单的 API 为生成式 AI 提供无服务器体验。它允许访问来自 Amazon 和第三方的基础模型,以执行文本生成、映像生成和构建对话代理等任务。通过 Amazon Bedrock 处理的数据仍是私有的,并且是加密的。
自定义 RAG 工作流程
如果想进一步处理检索到的文本块、查看检索的相关性得分或开发自己的文本生成编排,您可以使用新的 Retrieve API。此 API 将用户查询转换为嵌入,搜索知识库并返回相关结果,从而让您拥有更多控制权,在语义搜索结果的基础上构建自定义工作流程。
使用 Retrieve API
在 Amazon Bedrock 控制台中,我切换开关以禁用生成响应。

然后,我再问一遍:“什么是 Amazon Bedrock?” 这一次,输出显示了检索结果,其中包含指向文本块来源的源文档链接。
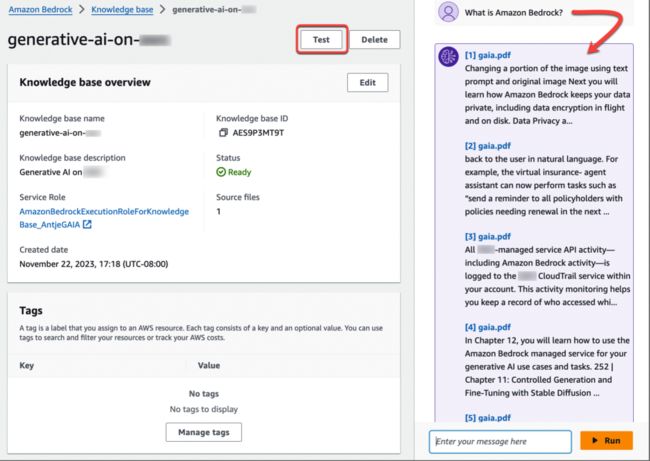
以下是在 boto3 中使用 Retrieve API 的方法。
import boto3
bedrock_agent_runtime = boto3.client(
service_name = "bedrock-agent-runtime"
)
def retrieve(query, kbId, numberOfResults=5):
return bedrock_agent_runtime.retrieve(
retrievalQuery= {
'text': query
},
knowledgeBaseId=kbId,
retrievalConfiguration= {
'vectorSearchConfiguration': {
'numberOfResults': numberOfResults
}
}
)
response = retrieve("What is Amazon Bedrock?", "AES9P3MT9T")["retrievalResults"] Retrieve API 的输出包括检索到的文本块、源数据的位置类型和 URI 以及检索的得分。得分有助于确定与查询匹配度更高的文本块。
在我的演示中,API 响应如下(为简洁起见,我对部分输出进行了编辑):
[{'content': {'text': 'Changing a portion of the image using ...'},
'location': {'type': 'S3',
's3Location': {'uri': 's3://data-generative-ai-on-aws/gaia.pdf'}},
'score': 0.7329834},
{'content': {'text': 'back to the user in natural language.For ...'},
'location': {'type': 'S3',
's3Location': {'uri': 's3://data-generative-ai-on-aws/gaia.pdf'}},
'score': 0.7331088},
...]要进一步自定义 RAG 工作流程,您可以定义自定义分块策略并选择自定义向量存储。
自定义分块策略 – 为了实现对数据的有效检索,常见的做法是先将文档拆分成可管理的块。这提高了模型更有效地理解和处理信息的能力,从而改善了相关检索并生成一致的响应。Amazon Bedrock 知识库可管理文档的分块。
当您为知识库配置数据来源时,就可以定义分块策略。默认分块将数据拆分为多达 200 个令牌的块,并针对问答任务进行了优化。如果您不确定数据的最佳块大小,请使用默认分块。
您还可以选择指定自定义块大小,并与固定大小分块重叠。如果您知道数据的最佳块大小和重叠情况(基于文件属性、准确性测试等),请使用固定大小分块。在 0-20% 的推荐范围内,分块之间的重叠有助于提高准确性。重叠程度越高,相关性得分越低。
如果选择为每个文档创建一个嵌入,知识库会将每个文件作为一个块保存。如果您不希望 Amazon Bedrock 对数据进行分块,例如,如果您想使用特定于您的用例的算法对数据进行离线分块,请使用此选项。常见用例包括代码文档。
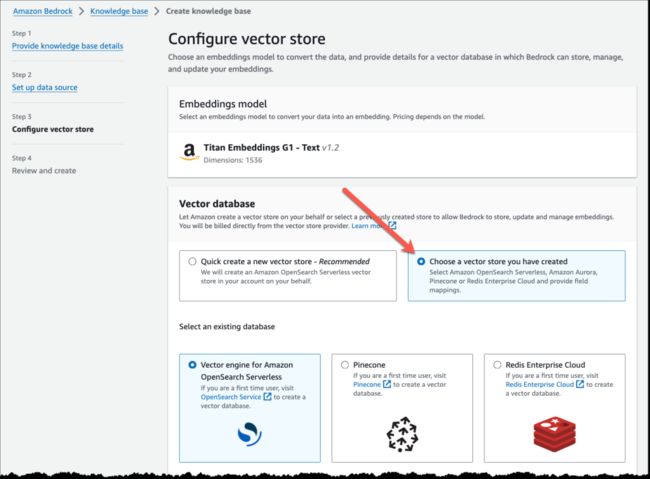
自定义向量存储 – 您也可以选择自定义向量存储。可用的向量数据库选项包括 Amazon OpenSearch 无服务器的向量引擎、Pinecone 和 Redis Enterprise Cloud。要使用自定义向量存储,您必须从支持的选项列表中创建新的空向量数据库,并提供向量数据库索引名称以及索引字段和元数据字段映射。该向量数据库需要专供 Amazon Bedrock 使用。
将 RAG 与其他生成式 AI 工具和应用程序集成
如果您想构建一个人工智能助手,该助手可以执行多步骤任务和访问公司数据来源,以生成更相关和上下文感知响应,则可以将知识库与 Amazon Bedrock 代理集成。您还可以使用适用于 LangChain 的知识库检索插件,将 RAG 工作流程集成到生成式 AI 应用程序中。
可用性
Amazon Bedrock 知识库现已在如下区域推出:美国东部(弗吉尼亚州北部)和美国西部(俄勒冈州)。
了解详情
Amazon Bedrock 知识库
https://aws.amazon.com/bedrock/knowledge-bases/
知识库用户指南
https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base.html
控制台中的 Amazon Bedrock
https://console.aws.amazon.com/bedrock/home
了解所有 re:Invent 2023 热门发布产品,
请扫描下方二维码:

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!
