实时语义分割模型ICNet(ECCV 2018)解析
paper:ICNet for Real-Time Semantic Segmentation on High-Resolution Images
project page:ICNet for Real-Time Semantic Segmentation on High-Resolution Images
official implementation:https://github.com/hszhao/ICNet
third-party implementation: https://github.com/open-mmlab/mmsegmentation/tree/main/configs/icnet
存在的问题
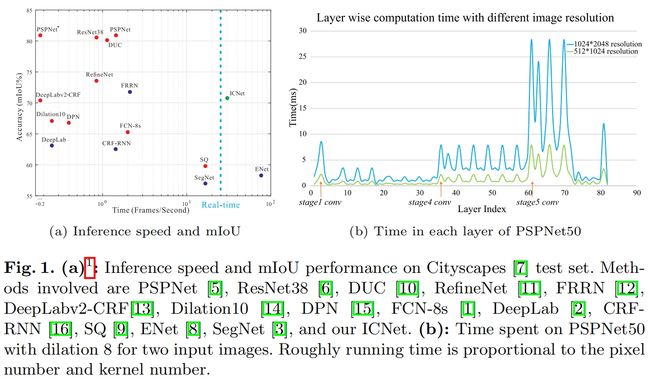
之前的语义分割模型大都达不到实时的要求,因此在实际应用中受到了限制。而少数达到或接近实时要求的模型精度又下降的厉害,如ENet、SegNet等,如图1(a)所示
本文的创新点
本文的目标是在设计一个实时语义分割模型同时精度又足够decent,与之前的结构不同,本文综合考虑了速度和准确性两个因素。首先对语义分割框架中time budget进行了深入的分析,并通过大量的实验表明现有的直觉可行的加速策略的不足。
本文提出了image cascade network (ICNet),一个兼顾精度与速度的语义分割模型。它利用低分辨率图像的处理效率和高分辨率图像的处理质量,想法是首先让低分辨率的图像经过完整的分割网络得到一个粗糙的预测图,然后提出了级联特征融合单元cascade feature fusion unit和级联标签指导策略cascade label guidance整合中、高分辨率的特征,然后逐步细化粗预测结果。
方法介绍
速度分析
在卷积中,输入特征图 \(V\in \mathbb{R}^{C\times H\times W}\) 经过变换函数 \(\Phi\) 的处理后得到输出 \(U\in \mathbb{R}^{C'\times H'\times W'}\),其中 \(c,h,w\) 分别表示通道、高、宽。变换 \(\Phi:V \to U\) 是通过 \(c'\) 个卷积核 \(K\in \mathbb{R}^{c\times k\times k}\) 实现的,因此卷积的总操作数 \(O(\Phi)=c'ck^{2}h'w'\),输出尺寸 \(h',w'\) 和输入高度相关,通过步长 \(s\) 控制,\(h'=h/s,w'=w/s\),则
![]()
可以看出计算复杂度和特征图的分辨率 \(h,w,s\)、卷积核的数量和网络宽度 \(c,c'\) 有关。图1(b)展示的是PSPNet50中两种不同分辨率图像的时间成本,蓝色曲线对应的是1024x2048的高分辨率输入,绿色曲线对应的是512x1024的低分辨率输入,计算的增加相较于分辨率呈平方关系。对于两条曲线,stage4和stage5的分辨率是相同的,但后者的计算量是前者的4倍,这是因为stage5中输入通道数和卷积核数量 \(c,c'\) 都翻倍了。
网络结构
根据上述分析,作者首先采用了一些直观加速策略进行实验,如降采样输入、压缩特征图通道、模型压缩,结果表明推理的精度和速度之间很难保持良好的平衡,虽然这些方法可以减少推理时间,但精度也显著下降。
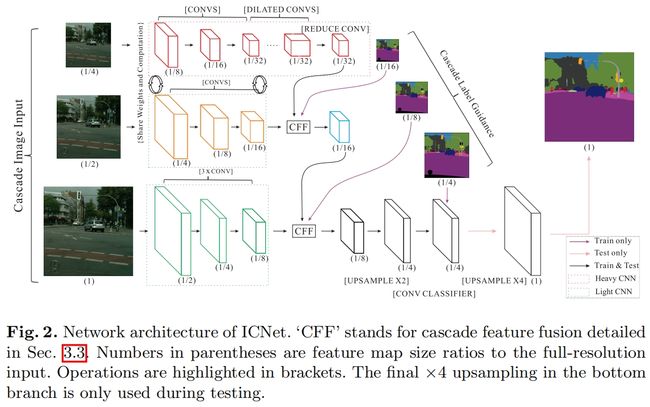
本文提出的ICNet不是简单的选择上述任何一种方法,而是采用级联图像输入(即低、中、高分辨率图像)、级联特征融合单元、并在级联标签指导下进行训练。具体结构如图2所示,完整分辨率的图像(如Cityscapes中1024x2048)降采样2倍、4倍,得到级联图像输入。
用像FCN这样的网络直接分割高分辨率的输入是很耗时的,为了克服这个问题,本文用低分辨的输入来提取语义特征如图2最上所示,一个1/4大小的输入进入到PSPNet中得到1/32大小的特征图。为了获得高质量的分割结果,中、高分辨率分支(图2中的中间和下部)用来恢复和细化第一个分支粗略的预测。虽然第一个分支中丢失了一些细节提取的边缘也比较模糊,但它已经获得了大部分的语义特征,因为我们可以安全的限制中、下两个分支的参数量。轻量的CNN用于下面两个分支,不同分支的输出通过cascade-feature-fusion unit进行融合,然后通过cascade label guidance进行训练。
Cascade Feature Fusion
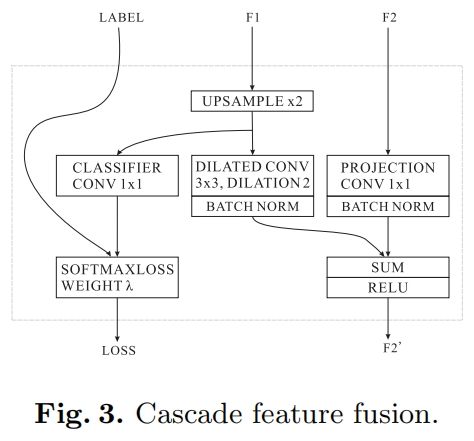
为了融合不同分支的输出,作者提出了一个级联特征融合单元如图3所示。输入包括两个特征图 \(F_{1}\) 和 \(F_{2}\) 分辨率分别为 \(C_{1}\times H_{1}\times W_{1}\) 和 \(C_{2}\times H_{2}\times W_{2}\),以及一个ground truth label分辨率为 \(1\times H_{2}\times W_{2}\)。其中 \(F_{2}\) 是 \(F_{1}\) 的两倍。
首先对 \(F_{1}\) 双线性差值上采样2倍得到与 \(F_{2}\) 一样大小的输出,然后接一个dilation=2的 \(C_{3}\times 3\times 3\) 的空洞卷积得到 \(C_{3}\times H_{2}\times W_{2}\) 的输出,对于 \(F_{2}\),一个 \(C_{3}\times 1\times 1\) 的卷积用来映射成和 \(F_{1}\) 的输出一样的通道,然后接两个BN,接着是element-wise add和ReLU,最终得到融合特征 \(F'_{2}\),大小为 \(C_{3}\times H_{2}\times W_{2}\)。为了增强 \(F_{1}\) 的学习能力,对 \(F_{1}\) 的上采样输出采用了一个辅助label guidance。
Cascade Label Guidance
为了加强每个分支的学习过程,本文采用了级联标签指导策略。它利用不同尺度的ground truth来监督不同分辨率输入分支的学习。给定 \(\mathcal{T}\) 个分支(比如\(\mathcal{T}=3\))和 \(\mathcal{N}\) 个类别,在分支 \(t\) 中,预测特征图 \(\mathcal{F}^{t}\) 的大小为 \(\mathcal{Y}_{t}\times \mathcal{X}_{t}\)。位置 \((n,y,x)\) 处的像素值为 \(\mathcal{F}^{t}_{n,y,x}\),\((y,x)\) 位置处对应的ground truth label为 \(\hat n\)。训练中,我们在每个分支使用加权softmax cross entropy loss,分支对应的权重为 \(\lambda_{t}\),则完整的损失函数 \(\mathcal{L}\) 如下
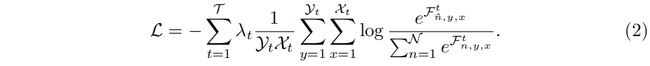
在推理时,low, medium guidance会被丢弃,只保留高分辨率的分支。
代码解析
这里以MMSegmentation中的实现为例,讲解一下代码实现,输入为(16, 3, 480, 480)。
下面是backbone的配置文件,在ResNet50的基础上做了一些修改。首先是dilation,原始的ResNet中四个stage的dilation都为1即不采用空洞卷积,这里后两个stage采用dilation=2,4的空洞卷积。然后是stride,原始的ResNet中strides=(1, 2, 2, 2),而这里只在第二个stage中进行下采样。
backbone=dict(
type='ICNet',
backbone_cfg=dict(
type='ResNetV1c',
in_channels=3,
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=norm_cfg,
norm_eval=False,
style='pytorch',
contract_dilation=True),
in_channels=3,
layer_channels=(512, 2048),
light_branch_middle_channels=32,
psp_out_channels=512,
out_channels=(64, 256, 256),
norm_cfg=norm_cfg,
align_corners=False,
)接着看一下backbone的forward函数,如下。注意,这里和论文中的图2差异很大,图2中是对原始图片下采样后得到不同分辨率的输入,然后进入backbone,其中small, medium分支共享权重。但在这里的实现中只有一个分支,只不过对中间特征图进行下采样,然后取中间不同阶段的特征图作为backbone的输出,这样改后就像是deep supervision,只不过对不同阶段的特征图通过CFF进行了融合。
官方实现也和论文中不一致,Not exactly similar as the description in your paper · Issue #7 · hszhao/ICNet · GitHub
在其它实现中也有指出,ICNet Problem · Issue #107 · Tramac/awesome-semantic-segmentation-pytorch · GitHub,ICNet Problem · Issue #1 · lxtGH/Fast_Seg · GitHub。
def forward(self, x): # (16,3,480,480)
output = []
# sub 1
output.append(self.conv_sub1(x)) # (16,64,60,60)
# sub 2
x = resize(
x,
scale_factor=0.5,
mode='bilinear',
align_corners=self.align_corners) # (16,3,240,240)
x = self.backbone.stem(x) # (16,64,120,120)
x = self.backbone.maxpool(x) # (16,64,61,61)
x = self.backbone.layer1(x) # (16,256,61,61)
x = self.backbone.layer2(x) # (16,512,31,31)
output.append(self.conv_sub2(x)) # (16,256,31,31)
# sub 4
x = resize(
x,
scale_factor=0.5,
mode='bilinear',
align_corners=self.align_corners) # (16,512,15,15)
x = self.backbone.layer3(x) # (16,1024,15,15)
x = self.backbone.layer4(x) # (16,2048,15,15)
psp_outs = self.psp_modules(x) + [x]
# [(16,512,15,15),(16,512,15,15),(16,512,15,15),(16,512,15,15),(16,2048,15,15)]
psp_outs = torch.cat(psp_outs, dim=1) # (16,4096,15,15)
x = self.psp_bottleneck(psp_outs) # (16,512,15,15)
output.append(self.conv_sub4(x)) # (16,256,15,15)
return output # [(16,64,60,60),(16,256,31,31),(16,256,15,15)]还有一点需要注意,这里对stem后的maxpool进行了修改,导致(120, 120)的输入经过最大池化后得到的输出为(61, 61)而不是(60, 60)
# Note: Default `ceil_mode` is false in nn.MaxPool2d, set
# `ceil_mode=True` to keep information in the corner of feature map.
self.backbone.maxpool = nn.MaxPool2d(
kernel_size=3, stride=2, padding=1, ceil_mode=True)级联特征融合在neck部分实现,如下
def forward(self, inputs):
assert len(inputs) == 3, 'Length of input feature \
maps must be 3!'
x_sub1, x_sub2, x_sub4 = inputs # [(16,64,60,60), (16,256,31,31), (16,256,15,15)]
x_cff_24, x_24 = self.cff_24(x_sub4, x_sub2) # (16,128,31,31),(16,128,31,31)
x_cff_12, x_12 = self.cff_12(x_cff_24, x_sub1) # (16,128,60,60),(16,128,60,60)
# Note: `x_cff_12` is used for decode_head,
# `x_24` and `x_12` are used for auxiliary head.
return x_24, x_12, x_cff_12其中融合操作cff的实现如下,具体就是上采样对齐尺度后,分别通过一层卷积再对齐通道,然后相加进行融合。
class CascadeFeatureFusion(BaseModule):
"""Cascade Feature Fusion Unit in ICNet.
Args:
low_channels (int): The number of input channels for
low resolution feature map.
high_channels (int): The number of input channels for
high resolution feature map.
out_channels (int): The number of output channels.
conv_cfg (dict): Dictionary to construct and config conv layer.
Default: None.
norm_cfg (dict): Dictionary to construct and config norm layer.
Default: dict(type='BN').
act_cfg (dict): Dictionary to construct and config act layer.
Default: dict(type='ReLU').
align_corners (bool): align_corners argument of F.interpolate.
Default: False.
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
Returns:
x (Tensor): The output tensor of shape (N, out_channels, H, W).
x_low (Tensor): The output tensor of shape (N, out_channels, H, W)
for Cascade Label Guidance in auxiliary heads.
"""
def __init__(self,
low_channels,
high_channels,
out_channels,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
align_corners=False,
init_cfg=None):
super().__init__(init_cfg=init_cfg)
self.align_corners = align_corners
self.conv_low = ConvModule(
low_channels,
out_channels,
3,
padding=2,
dilation=2,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.conv_high = ConvModule(
high_channels,
out_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
def forward(self, x_low, x_high):
x_low = resize(
x_low,
size=x_high.size()[2:],
mode='bilinear',
align_corners=self.align_corners)
# Note: Different from original paper, `x_low` is underwent
# `self.conv_low` rather than another 1x1 conv classifier
# before being used for auxiliary head.
x_low = self.conv_low(x_low)
x_high = self.conv_high(x_high)
x = x_low + x_high
x = F.relu(x, inplace=True)
return x, x_low