NLP-Beginner任务五学习笔记:基于神经网络的语言模型
**用LSTM、GRU来训练字符级的语言模型,计算困惑度**
数据集:https://github.com/FudanNLP/nlp-beginner/blob/master/poetryFromTang.txt
任务一博客链接:https://blog.csdn.net/qq_51983316/article/details/129314052
任务二博客链接:https://blog.csdn.net/qq_51983316/article/details/129387225
任务三博客链接:https://blog.csdn.net/qq_51983316/article/details/129470730
任务四博客链接:https://blog.csdn.net/qq_51983316/article/details/129542010
目录
一、数据集
二、知识点学习
(一)语言模型
1、基本概念
2、评价指标—困惑度
3、评价指标—BLEU算法
4、评价指标—ROUGE算法
(二)文本生成
1、基于语言模型的文本生成
2、基于深度学习的文本生成
(三)GRU
三、实验
(一)代码实现
1、main.py
2、feature_extraction.py
(二)结果展示与分析
一、数据集
原始数据集:https://github.com/FudanNLP/nlp-beginner/blob/master/poetryFromTang.txt
原始数据展示:

共163首唐诗,但一些诗句中有乱码/英文字母的错误,需要进行简单的清洗,如下图:

二、知识点学习
(一)语言模型
1、基本概念
语言模型(Language Model,LM)是定义在单词序列上的概率模型。通过将一个句子或者一段文字视作单词序列,可以运用概率论,统计学,信息论,机器学习等方法对语言进行建模,从而实现对单词序列的概率进行计算。一般来说,概率更大的单词序列意味着其在语言交流中出现的可能性更大,也即其可能更加符合语言习惯和会话逻辑。
语言模型仅仅对句子出现的概率进行建模,并不尝试去理解句子的内容含义。语言模型可以根据句子的一部分预测下一个词,简言之,语言模型就是判断一句话是否在语法上通顺。
举例:P(今天很累)> P(累很今天)
假设句子S包含k个单词,记为 ![]() ,该句子的概率为:
,该句子的概率为:
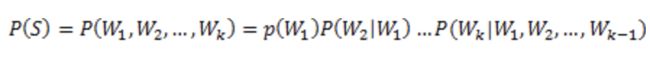
由公式可以看出,对于任意的词序列,语言模型能够计算出这个序列是一句话的概率。
从文本生成的角度而言,语言模型可以定义为:给定一个短语(一个词组或一句话),语言模型可以生成(预测)接下来的一个词。
语言模型的发展可以分为两个大的阶段,分别是以N-gram语言模型为代表的统计语言模型阶段,以及神经网络语言模型阶段。神经网络语言模型又可以分为早期的以【设计神经网络结构】为主的阶段和目前的通过巨量语料进行训练,再通过微调进行部署的【预训练语言模型阶段】。
在统计语言模型中,往往采用极大似然估计来计算每个词出现的条件概率,但对于任意长的语句,形如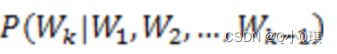 ,其条件很长且数据稀疏,根据极大似然估计直接计算不现实。
,其条件很长且数据稀疏,根据极大似然估计直接计算不现实。
为了解决此问题,引入马尔可夫假设(Markov assumption),即假设当前词出现的概率只依赖于前 个词,N-gram模型是基于此原理最经典的模型,其计算方式如下:
个词,N-gram模型是基于此原理最经典的模型,其计算方式如下:
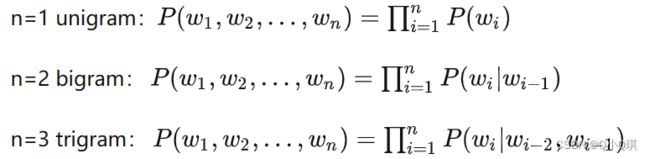
其中, 当 n>1 时,为了使句首词的条件概率有意义,需要给原序列加上一个或多个起始符
以N-gram为代表的统计语言模型的优缺点:
1、优点:
- 采用极大似然估计,参数易训练;
- 完全包含了前 n-1 个词的全部信息;
- 可解释性强,直观易理解。
2、缺点:
- 缺乏长期依赖,只能建模到前 n-1 个词;
- 随着 n 的增大,参数空间呈指数增长;
- 数据稀疏,难免会出现OOV(out of vocabulary words)的问题;
- 单纯的基于统计频次,泛化能力差。
最早的前馈神经网络语言模型——NNLM(Neural Network Language Model)在Bengio于2003年发表的《A Neural Probabilistic Language Model》中被提出,其模型原理如下:
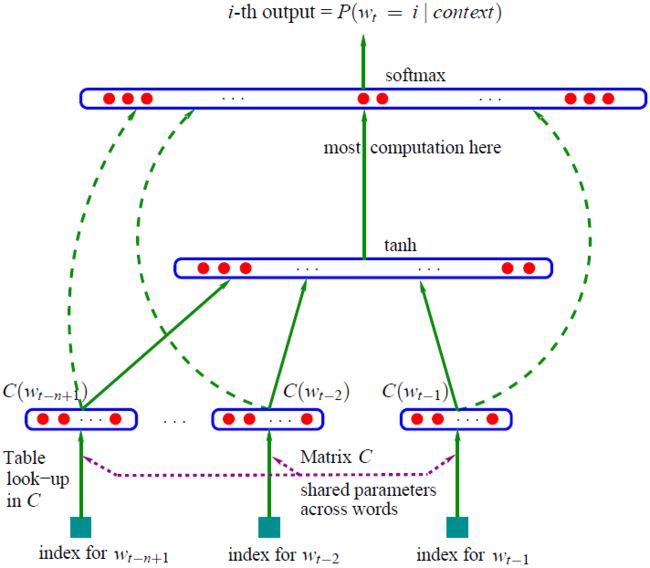
输入层:将大小为 ![]() 的参数矩阵
的参数矩阵 与one-hot向量表示的词汇表
与one-hot向量表示的词汇表 中的单词
中的单词  相乘,得到该词的稠密向量表示
相乘,得到该词的稠密向量表示 ![]() ,并将输入序列对应的所有向量拼接后得到神经网络的输入向量
,并将输入序列对应的所有向量拼接后得到神经网络的输入向量 ![]() 。
。
隐藏层:设置 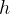 个隐藏单元,权重矩阵
个隐藏单元,权重矩阵 ![]() ,偏置向量
,偏置向量 ![]() ,tanh激活函数。
,tanh激活函数。
输出层:将隐藏层到输出层的运算结果(权重矩阵 ![]() ,偏置向量
,偏置向量 ![]() )和从输入层直接到输出层的运算结果(权重矩阵
)和从输入层直接到输出层的运算结果(权重矩阵 ![]() )相加,得到:
)相加,得到:
![]()
再将y通过softmax函数,便得到了以概率表示的![]()
其本质过程就是先给每个词在连续空间中赋予一个向量(词向量),再通过神经网络去学习这种分布式表征。利用神经网络去建模当前词出现的概率与其前 n-1 个词之间的约束关系。很显然这种方式相比 N-gram 具有更好的泛化能力,只要词表征足够好。从而很大程度地降低了数据稀疏带来的问题。但是这个结构的明显缺点是仅包含了有限的前文信息。
其对于统计语言模型的颠覆之处在于
1,将词以抽象符号的表示方法转变为了语义空间下的向量表示
2,以向量表示的单词序列作为神经网络的输入,求取![]()
循环神经网络语言模型在Tomas Mikolov于2010年发表的《Recurrent neural network based language model》中被提出,彻底解决了语言模型不能捕捉长距离信息的问题。循环神经网络的当前隐藏层反复捕捉当前输入的词向量和上一隐藏层(包含了前文中所有词向量的信息)
但循环神经网络存在参数经过多次传递后,易发生梯度消失或爆炸的问题,且其平等的对待所有的输入单词,但是在实际的语言中,不同的单词对于句子的重要性其实是不一样的。
后续提出的长短期记忆(Long short-term memory,LSTM)神经网络能够通过某种策略有选择地保留或者遗忘前文的信息,在没有改变循环神经网络基本结构的基础上,很好的解决了循环升级网络的问题,同时也保留了其可以捕捉全文信息的优点。
神经网络语言模型的优缺点:
1、优点
- 长距离依赖,具有更强的约束性;
- 避免了数据稀疏所带来的OOV问题;
- 好的词表征能够提高模型泛化能力。
2、缺点
- 模型训练时间长;
- 神经网络黑盒子,可解释性较差。
2、评价指标—困惑度
语言模型的常用评价指标是困惑度(perplexity),其基本思想为:给测试集的句子赋予较高概率值的语言模型较好;当一个语言模型训练完成后,测试集中的句子(正常的自然语言句子)出现概率越高越好。困惑度越小,句子概率越大,语言模型越好。
在信息论中,perplexity(困惑度)用来度量概率模型预测样本的好坏程度,也可以用来比较两个概率分布或概率模型。低困惑度的概率分布模型能更好地预测样本。
简言之,困惑度刻画的是语言模型预测一个语言样本的能力。
比如已经知道![]() 这句话会出现在语料库之中,那么通过语言模型计算得到的这句话的概率越高,说明语言模型对这个语料库拟合的越好。
这句话会出现在语料库之中,那么通过语言模型计算得到的这句话的概率越高,说明语言模型对这个语料库拟合的越好。
perplexity实际是计算每一个词得到的概率倒数的几何平均,因此可以理解为平均分支系数,即模型预测下一个词时的平均可选择数量。perplexity计算公式如下:
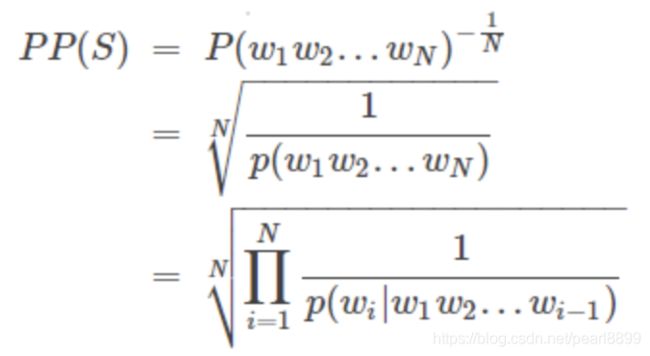
其中,S代表sentence,N是句子长度,p(wi)是第i个词的概率。第一个词就是 p(w1|w0),而w0是START,表示句子的起始占位符。其主要是根据每个词来估计一句话出现的概率,并用句子长度作normalize,PP(S)值越小,p(wi)则越大,一句我们期望的sentence出现的概率就越高。
举例:训练好的bigram语言模型的困惑度为3,也就是说,在平均情况下,该模型预测下一个单词时,有3个单词等可能的可以作为下一个单词的合理选择。
Perplexity的影响因素:
- 训练数据集越大,Perplexity会下降得更低;
- 数据中的标点会对模型的困惑度产生很大影响,且标点的预测总是不稳定的;
- 预测语句中“的、了”等停用词也会对困惑度的取值有很大影响,但从语义上分析有没有这些停用词并不能完全代表句子生成的好坏。
因此,语言模型评估时可以用perplexity大致估计训练效果,但其并不是完全意义上的标准。
3、评价指标—BLEU算法
BLEU( BiLingual Evaluation Understudy) 算法是一种衡量模型生成序列和参考序列之间的 N 元词组( N-Gram) 重合度的算法, 最早用来评价机器翻译模型的质量, 目前也广泛应用在各种序列生成任务中。BLEU算法的值域范围是 [0, 1], 越大表明生成的质量越好。但是 BLEU 算法只计算精度, 而不关心召回率( 即参考序列里的N元组合是否在生成序列中出现)。
4、评价指标—ROUGE算法
ROUGE( Recall-Oriented Understudy for Gisting Evaluation)算法最早应用于文本摘要领域。和 BLEU算法类似, 但ROUGE算法计算的是召回率( Recall)。令 为从模型分布 中生成的一个候选序列, (1), ⋯ , () 为从真实数据分布中采样出的一组参考序列, 为从参考序列中提取N元组合的集合, ROUGEN算法的定义为:

其中 () 是N元组合 在生成序列 中出现的次数, (()) 是N元组合 在参考序列 () 中出现的次数。
(二)文本生成
参考此篇综述:https://www.jiqizhixin.com/articles/2017-05-22
自然语言生成系统:接受非语言形式的信息作为输入,生成可读的文字表述。
按照输入数据的区别,可以将文本生成任务大致分为文本到文本的生成、数据到文本的生成和图像到文本的生成三大类。文本到文本的生成又可根据不同的任务分为:文本摘要、 古诗生成、文本复述等。文本摘要又可以分为抽取式摘要和生成式摘要。
1、基于语言模型的文本生成
基于马尔可夫的语言模型在数据驱动的自然语言生成中有着重要的应用。它利用数据和文字间的对齐语料,主要采用两个步骤:内容规划和内容实现为数据生成对应的文本。Oh等人在搭建面向旅行领域的对话系统时,在内容规划部分使用bigram作特征根据近期的对话历史,选取待生成文本中需要出现的属性,内容实现部分使用n-gram语言模型生成对话。Ratnaparkhi等人经过实验对比发现在语言模型上加入依存语法关系有助于改善生成效果。
2、基于深度学习的文本生成
在文本到文本的生成方面,Zhang等人[8]使用RNN进行中文古诗生成,用户输入关键词后首先拓展为短语,并用来生成诗的第一行。接下来的每一行结合当时所有已生成的诗句进行生成。Wang[9]则将古诗生成分为规划模型和生成模型两部份。规划模型部分得到用户的输入,在使用TextRank进行关键词抽取和使用RNN语言模型和基于知识库的方法进行拓展后,获得一个主题词序列,作为写作大纲,每一个主题词在下一个部分生成一行诗。生成模型部分基于encoder-decoder模型,增加一个encoder为主题词获得一个向量表示。另一 个encoder编码已经生成的句子。使用attention-based的模型,decoder综合主题词和已经生成的句子,生成下一句的内容。通过这两个模型,在更好的控制每一行诗的主题的同时保持诗词的流畅性。
(三)GRU
GRU(Gated Recurrent Unit)也称门控循环单元,是传统 RNN 的变体,同 LSTM 一样能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象。同时它的结构和计算要比 LSTM 更简单。在 LSTM 中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值。而在 GRU 模型中只有两个门:更新门和重置门。具体结构如下图所示:
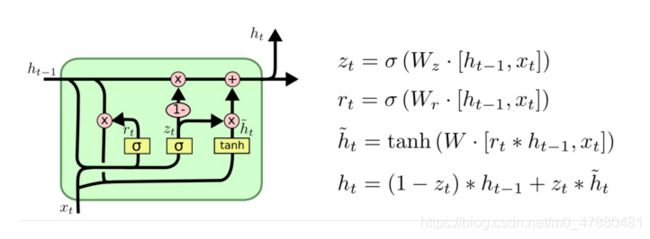
图中的 ![]() 和
和  分别表示重置门和更新门。
分别表示重置门和更新门。
- 重置门:控制前一状态有多少信息被写入到当前的候选集
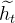 上,重置门越小,前一状态的信息被写入的越少。
上,重置门越小,前一状态的信息被写入的越少。 - 更新门:控制前一时刻的状态信息被带入到当前状态中的程度,更新门越大,前一时刻的状态信息带入越多。
pytorch中nn.GRU类初始化主要参数解释:
- input_size:输入张量x中特征维度的大小
- hidden_size: 隐层张量h中特征维度的大小
- num_layers:隐含层数量
- nonlinearity:激活函数的选择,默认是tanh
- bidirectional:是否选择使用双向,如果为True则使用;默认不使用
RNN & LSTM & GRU 对比:
- RNN特点:每个隐状态取决于当前的隐状态和当前的输入。
- LSTM 特点:通过门结构使模型能够自由选择信息的传递。进一步增加RNN的记忆能力,并减轻梯度爆炸和消失的问题。
- GRU 特点:对LSTM的循环函数进行简化,三个门变为两个门,解决LSTM的循环函数比较复杂的问题,在保证效果和LSTM相似的情况下,提高学习和推理效率。
GRU 优缺点:
- 优点:在捕捉长序列语义关联时,能有效抑制梯度消失或爆炸,效果优于传统RNN且计算复杂度比LSTM要小。
- 缺点:GRU仍然不能完全解决梯度消失问题,同时其作用RNN的变体,有着RNN结构本身的一大弊端,即不可并行计算,这在数据量和模型体量逐步增大的未来,是关键瓶颈。
此任务中model(LSTM/GRU)代码实现:
import torch.nn as nn
import torch
"""语言模型:LSTM/GRU"""
class Language(nn.Module):
def __init__(self, len_feature, len_words, len_hidden, num_to_word, word_to_num, strategy='LSTM', pad_id=0, start_id=1, end_id=2, drop_out=0.5):
super(Language, self).__init__()
self.pad_id = pad_id
self.start_id=start_id
self.end_id = end_id
# 一个将数字编码转换为单词的字典
self.num_to_word = num_to_word
# 一个将单词转换为数字编码的字典
self.word_to_num = word_to_num
self.len_feature = len_feature
self.len_words = len_words
self.len_hidden = len_hidden
self.dropout = nn.Dropout(drop_out)
_x = nn.init.xavier_normal_(torch.Tensor(len_words, len_feature))
self.embedding = nn.Embedding(num_embeddings=len_words, embedding_dim=len_feature, _weight=_x)
if strategy == 'LSTM':
self.gate = nn.LSTM(input_size=len_feature, hidden_size=len_hidden, batch_first=True)
elif strategy == 'GRU':
self.gate = nn.GRU(input_size=len_feature, hidden_size=len_hidden, batch_first=True)
else:
raise Exception("Unknown Strategy!")
# 全连接层对象,该层将从LSTM/GRU中获得的隐藏状态转换为输出单词的概率。
self.fc = nn.Linear(len_hidden, len_words)
def forward(self, x):
x = self.embedding(x)
x = self.dropout(x)
self.gate.flatten_parameters()
# gate表示门控循环单元(GRU)或长短时记忆(LSTM)单元
x, _ = self.gate(x)
# fc线性变换,返回预测结果的概率分布logits
logits = self.fc(x)
return logits
""" 生成固定古诗 """
# max_len 每行诗句的最大长度;num_sentence 生成古诗的行数
def generate_random_poem(self, max_len, num_sentence, random=False):
if random:
initialize = torch.randn
else:
initialize = torch.zeros
# 初始化隐藏状态 hn 和细胞状态 cn
hn = initialize((1, 1, self.len_hidden)).cuda()
cn = initialize((1, 1, self.len_hidden)).cuda()
# 使用诗歌开始标记的 ID 初始化当前的输入 x,同时创建一个空列表 poem,用于保存生成的古诗
x = torch.LongTensor([self.start_id]).cuda()
poem = list()
# 循环生成古诗,直到达到指定的行数
while(len(poem)!=num_sentence):
word = x
sentence = list()
for j in range(max_len):
# 每次生成一个词。首先将当前的输入 word 转换为张量
word = torch.LongTensor([word]).cuda()
word = self.embedding(word).view(1, 1, -1)
output, (hn, cn) = self.gate(word, (hn, cn))
output = self.fc(output)
# 获取概率最大的词的 ID
word = output.topk(1)[1][0].item()
"""
如果生成的词是句子结束标记的ID,则将当前输入 x 设置为诗歌开始标记的ID,并跳出内层循环。
如果生成的词不是句子结束标记,则将其对应的词语添加到当前句子 sentence 中。
如果生成的词是句号 self.word_to_num['。'] 的 ID,则说明当前诗句已经结束,跳出内层循环。
"""
if word == self.end_id:
x = torch.LongTensor([self.start_id]).cuda()
break
sentence.append(self.num_to_word[word])
if self.word_to_num['。'] == word:
break
# 如果内层循环正常结束,则说明当前诗句已经达到了最大长度 max_len,此时将当前输入 x 设置为句号的 ID 。
else:
x = self.word_to_num['。']
# 如果当前诗句非空,则将其添加到生成的古诗列表 poem 中。
if sentence:
poem.append(sentence)
#print(self.word_to_num.items())
return poem
"""生成藏头诗句"""
def generate_hidden_head(self, heads, max_len=50, random=False): # head是藏头诗的每一行的开头的字;max_len表示每一行最多包含的字数
# 循环遍历输入的每一个开头的字
for head in heads:
if head not in self.word_to_num:
raise Exception("Word: "+head+" is not in the dictionary, please try another word")
poem = list()
if random:
initialize = torch.randn
else:
initialize = torch.zeros
# 生成每一行的藏头诗
for i in range(len(heads)):
# 获取开头字 heads[i] 对应的数字 word,并将其作为起始字符
word = self.word_to_num[heads[i]]
sentence = [heads[i]]
hn = initialize((1, 1, self.len_hidden)).cuda()
cn = initialize((1, 1, self.len_hidden)).cuda()
for j in range(max_len-1):
word = torch.LongTensor([word]).cuda()
word = self.embedding(word).view(1, 1, -1)
output, (hn, cn) = self.gate(word, (hn, cn))
# 下一个字的概率分布
output = self.fc(output)
# 根据上述分布采样得到下一个字的数字 word
word = output.topk(1)[1][0].item()
# 将当前字符添加到句子末尾,如果当前字符是句号,则停止生成这一行。
sentence.append(self.num_to_word[word])
if self.word_to_num['。'] == word:
break
# 生成完一行之后,将其添加到 poem 列表中
poem.append(sentence)
return poem
三、实验
参数设置:
训练集:poetryFromTang.txt
模型:LSTM / GRU
词嵌入:Random Embeddingrandom_seed:2023
学习率:0.004
batch_size:1
embedding_size:50 # 每个词向量有几维
hidden_size:50
iter_times:250
运行环境:
python:3.7
pytorch:1.7.0(gpu)
cuda版本:10.1
(一)代码实现
1、main.py
# 导入包
from feature_extraction import get_batch, Random_Embedding
from torch import optim
import random
import numpy
import torch
from model import Language
import torch.nn.functional as F
import matplotlib.pyplot
# 设置随机种子,确保计算的可重复性
random.seed(2023)
numpy.random.seed(2023)
torch.cuda.manual_seed(2023)
torch.manual_seed(2023)
# 读取数据
with open('data/poetryFromTang.txt', 'rb') as f:
# 每行都以字节字符串的形式表示
temp = f.readlines()
# 特征提取
a = Random_Embedding(temp)
a.data_process()
train = get_batch(a.matrix, 1)
learning_rate = 0.004
iter_times = 150
# 计算损失和准确度
strategies = ['LSTM', 'GRU']
train_loss_records = list() # 记录每个模型的训练损失
train_acc_records = list() # 记录每个模型的准确率
total_acc_records = list() # 记录累计的准确率
models = list()
# 循环两次,i分别为0和1,主要为了用LSTM和GRU两种不同的模型进行训练
for i in range(2):
# 每个模型的训练过程中使用的随机数是相同的
random.seed(2023)
numpy.random.seed(2023)
torch.cuda.manual_seed(2023)
torch.manual_seed(2023)
# 词嵌入维度、词汇表大小、隐藏层维度、标签字典、词典和模型策略
model = Language(50, len(a.word_dict), 50, a.tag_dict, a.word_dict, strategy=strategies[i])
# 定义了一个Adam优化器,用于更新模型参数,学习率为learning_rate
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 定义了损失函数,使用交叉熵损失
loss_fun = F.cross_entropy
train_loss_record = list() # 记录每次迭代的损失
train_acc_record = list() # 记录每次迭代的准确率
total_acc = 0 # 累计准确率
model = model.cuda()
# 循环iter_times次,迭代模型
for iteration in range(iter_times):
# 定义了训练损失、累计准确率和一个计数器
total_loss = 0
model.train()
acc = 0
total_acc = 0
# 循环遍历训练数据集中的每个批次
for i, batch in enumerate(train):
x = batch.cuda()
# 将输入数据和标签分离:取 x 的所有行和除了最后一列以外的所有列;x 的所有行和从第二列开始的所有列
# 模型就可以根据前面的词来预测后面的词
x, y = x[:, :-1], x[:, 1:]
# 将预测结果张量的第1维和第2维进行转置
pred = model(x).transpose(1, 2)
# 将优化器的梯度归零,计算损失并更新总损失,然后反向传播更新梯度并更新模型参数
optimizer.zero_grad()
# 计算预测值 pred 和真实值 y 之间的交叉熵损失
loss = loss_fun(pred, y)
# 将当前 batch 的损失加到总损失中。其中 (x.shape[1]-1) 是 batch 的序列长度
total_loss += loss.item()/(x.shape[1]-1)
# 计算损失相对于模型参数的梯度
loss.backward()
# 更新模型参数
optimizer.step()
# 将预测值 pred 沿维度 1 取最大值,得到每个时间步的标签
pred_labels = pred.argmax(dim=1)
# 计算准确率
acc += pred_labels.eq(y).sum().item()
# 将当前 batch 的样本数量加到累计准确率 total_acc 中
total_acc += y.numel()
# 将本次迭代的平均损失加入到训练损失列表中
train_loss_record.append(total_loss/len(train))
train_acc = acc / total_acc # 计算每次迭代的准确率
train_acc_record.append(train_acc)
total_acc_records.append(total_acc) # 记录累计准确率
print("---------- Iteration", iteration + 1, "----------")
print("Train loss:", total_loss/len(train))
print("Train accuracy:", train_acc)
train_loss_records.append(train_loss_record)
train_acc_records.append(train_acc_record) # 记录每个模型的训练准确率
models.append(model)
# 通过调用模型的方法生成不同类型的诗歌
"""拼接诗句"""
def cat_poem(l):
poem = list()
for item in l:
poem.append(''.join(item))
return poem
""" 生成固定诗句 """
model = models[0]
# 生成一个每句9个字,共有6句的固定格式诗句
poem = cat_poem(model.generate_random_poem(9, 6, random=False))
for sent in poem:
print(sent)
""" 生成随机诗句 """
torch.manual_seed(2023)
# 生成一个每句15个字,共有4句的固定格式诗句
poem = cat_poem(model.generate_random_poem(15, 4, random=True))
for sent in poem:
print(sent)
""" 生成固定藏头诗 """
# 生成一个由 4 句,每句长度不超过 20 个字符的固定格式藏头诗
poem = cat_poem(model.generate_hidden_head("春夏秋冬", max_len=20, random=False))
for sent in poem:
print(sent)
""" 生成随机藏头诗 """
torch.manual_seed(0)
poem = cat_poem(model.generate_hidden_head("春夏秋冬", max_len=20, random=True))
for sent in poem:
print(sent)
# 绘制训练损失图
x = list(range(1, iter_times + 1))
matplotlib.pyplot.plot(x, train_loss_records[0], 'r--', label='LSTM')
matplotlib.pyplot.plot(x, train_loss_records[1], 'b--', label='GRU')
matplotlib.pyplot.legend()
matplotlib.pyplot.title("Average Train Loss")
matplotlib.pyplot.xlabel("Iterations")
matplotlib.pyplot.ylabel("Loss")
matplotlib.pyplot.savefig('loss.jpg')
matplotlib.pyplot.show()
# 绘制准确度图
matplotlib.pyplot.plot(x, train_acc_records[0], 'r--', label='LSTM')
matplotlib.pyplot.plot(x, train_acc_records[1], 'b--', label='GRU')
matplotlib.pyplot.legend()
matplotlib.pyplot.title("Average Train Accuracy")
matplotlib.pyplot.xlabel("Iterations")
matplotlib.pyplot.ylabel("Accuracy")
matplotlib.pyplot.savefig('accuracy.jpg')
matplotlib.pyplot.show()2、feature_extraction.py
from torch.utils.data import Dataset, DataLoader
import torch
from torch.nn.utils.rnn import pad_sequence
""" 词嵌入模型 """
class Random_Embedding():
def __init__(self, data):
self.data = data
# 将每个汉字映射到一个唯一的整数 ID
self.word_dict = {'': 0, '': 1, '': 2}
# 将每个 ID 映射回对应的汉字
self.tag_dict = {0: '', 1: '', 2: ''}
self.matrix = list()
# 诗歌分割
def form_poem(self):
# 将每个元素转换为utf-8的编码
data_utf8 = list(map(lambda x, y: str(x, encoding=y), self.data, ['utf-8'] * len(self.data)))
poems = list()
# 将每首诗歌定义为一个字符串,包含一个诗歌的所有行
new_poem = ""
for item in data_utf8:
# 如果当前元素是一个换行符,则表示我们已经到了当前诗歌的结尾
if item == '\n':
if new_poem:
poems.append(new_poem)
new_poem = ""
else:
# 如果当前元素不是换行符,则表示我们需要将其添加到当前诗歌中
if item[-2] == ' ':
position = -2
else:
position = -1
new_poem = ''.join([new_poem, item[:position]])
self.data = poems
print(self.data)
def get_words(self):
for poem in self.data:
for word in poem:
if word not in self.word_dict:
self.tag_dict[len(self.word_dict)]=word
self.word_dict[word] = len(self.word_dict)
def get_id(self):
for poem in self.data:
# 将每一首诗转换为一个由词的ID号组成的列表
self.matrix.append([self.word_dict[word] for word in poem])
def data_process(self):
self.form_poem()
# 按照长度进行升序排序
self.data.sort(key=lambda x: len(x))
self.get_words()
self.get_id()
""" 加载和预处理输入数据 """
class ClsDataset(Dataset):
def __init__(self, poem):
self.poem = poem
def __getitem__(self, item):
return self.poem[item]
def __len__(self):
return len(self.poem)
""" 自定义batch数据的输出形式 """
# 函数 collate_fn是 PyTorch 中 DataLoader 类的一个参数,用于在迭代数据时组合数据样本
# 将一个 batch 中的数据样本按照句子长度进行填充,以便构造成一个张量
def collate_fn(batch_data):
poems = batch_data
# 在每首诗歌的开头添加一个特殊的标记begin
poems = [torch.LongTensor([1, *poem]) for poem in poems]
padded_poems = pad_sequence(poems, batch_first=True, padding_value=0)
# 在每首诗歌的末尾添加一个特殊的标记end
padded_poems = [torch.cat([poem, torch.LongTensor([2])]) for poem in padded_poems]
padded_poems = list(map(list, padded_poems))
return torch.LongTensor(padded_poems)
# 使用自定义数据集,通过 dataloader 可以实现对整个数据集的批量迭代
def get_batch(x, batch_size):
dataset = ClsDataset(x)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=False, drop_last=True, collate_fn=collate_fn)
return dataloader
(二)结果展示与分析

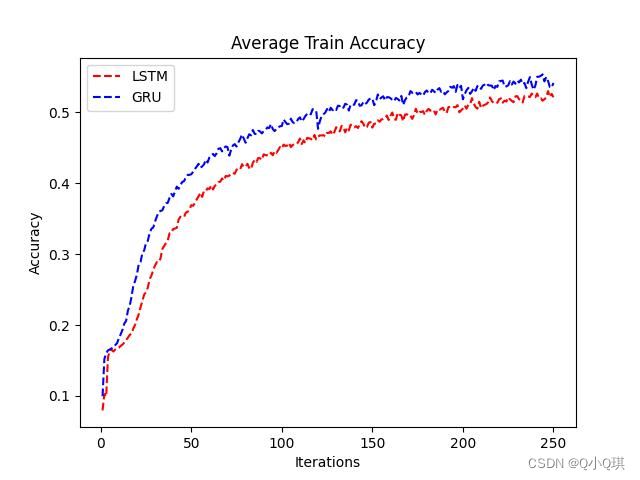
通过对比损失和准确度的可视化结果,可以看出GRU的效果相较LSTM更好些
GRU和LSTM的loss和accuracy分别如左图和右图所示:

生成随机诗句:

生成藏头诗:


总结:
由于是初学者,学习过程中参考了很多大佬的资料和代码,均附上参考链接:
1、https://blog.csdn.net/qq_42365109/article/details/121921018
2、邱锡鹏——《神经网络与深度学习》 第6、15章
3、BERT相关——(1)语言模型 | 冬于的博客 (ifwind.github.io)
4、语言模型发展综述 - sasasatori - 博客园 (cnblogs.com)
5、https://blog.csdn.net/qq_38556984/article/details/107125193
6、一起入门语言模型(Language Models) - 知乎 (zhihu.com)
7、语言模型 - 知乎 (zhihu.com)
8、https://blog.csdn.net/pearl8899/article/details/112854900
9、深入理解语言模型 Language Model - 知乎 (zhihu.com)
10、NLP——困惑度-Perplexity | Jiahong的个人博客 (joezjh.github.io)
11、文本生成概述 | 机器之心 (jiqizhixin.com)12、循环神经网络---GRU模型 - luyizhou - 博客园 (cnblogs.com)
13、https://blog.csdn.net/m0_47880481/article/details/106181451
14、https://zhuanlan.zhihu.com/p/32481747
15、https://blog.csdn.net/weixin_42691585/article/details/107114958
以上就是NLP-Beginner的任务五,欢迎各位前辈批评指正!