Power BI 之 DAX语法规范详解1
文章预览:
- Power BI 之 DAX语法规范详解 1
-
- 前言
- 表构造函数{()}
- Lookupvalue函数
- Related函数:
- Relatedtable函数
- 筛选引擎Calculate
-
- 单条件筛选
- 多条件筛选
- 筛选表
- 高级筛选器Filter
-
- 什么时候用Filter函数
- Values人工造表
- DISTINCT
-
- VALUES与DISTINCT的差异
- ALL函数
-
- ALL函数应用于表(计算占比)
- ALLSELECTED函数
- ALL函数应用于列(分类占比)
- ALLEXCEPT函数
- ALLNOBLANKROW
- 聚合函数
- 迭代函数
-
- SUMX
- Earlier函数 [当前行]
- 条件判断函数
-
- 1.IFERROR
- 2.if条件判断
- 3.switch多项条件判断
-
- switch的特殊用法
Power BI 之 DAX语法规范详解 1
前言
数据分析表达式 (DAX) 是在 Analysis Services、Power BI 以及 Excel 中的 Power Pivot 使用的公式表达式语言。
可供参考学习的文档:
DAX是什么 - DAX圣经 - Power BI极客 (powerbigeek.com)
ALLEXCEPT 函数 (DAX) - DAX | Microsoft Docs
用到的Excel表:
链接:https://pan.baidu.com/s/1WdXej1qo3VXfKCPlvsKcrg
提取码:b60l
一些需要注意的:
1、关于数据建模,注意 一对一,一对多,多对多的关系
一端可以向多端进行筛选,多端可以向一端申请内容
2、写函数的时候尽量都写上表名 ‘表名’[列名]
3、建数据库的时候一般都是建一个多端的表,其他的都是一端的表,永远都是一端去连多端
表构造函数{()}
只包含一列的表:
表={“张三”,“李四”,“王五”}
表={(“张三”),(“李四”),(“王五”)}
返回包含一列或多列的表:
表={
(“张三”,“男”,“22”,“实习生”),
(“李四”,“男”,“25”,“工程师”),
(“王五”,“女”,“22”,“销售”)
}
如果没有指定数据类型或某列不同行的数据类型不同时,DAX会自动将该列转为自动识别的数据类型
设置表头:
员工表=
VAR a=
{
(“张三”,“男”,“22”,“实习生”),
(“李四”,“男”,“25”,“工程师”),
(“王五”,“女”,“22”,“销售”)
}
Return
SelectColumns(a,“姓名”,[Value1],“性别”,[Value2],“年龄”,[Value3],“职位”,[Value4])

Lookupvalue函数
语法:Lookupvalue(把哪张表的哪个列取出,那张表的参数,自己表的参数)
多端向一端拿取数据的时候,例如销售表是多端,想要商品表的进价
新建列:
进价 = LOOKUPVALUE(‘商品表’[进价],‘商品表’[商品编码],‘销售表’[商品编码])
Related函数:
(多端找一端)(数据表找基础表)
测试 = LOOKUPVALUE(‘商品表’[进价],‘商品表’[商品编码],‘销售表’[商品编码]) * ‘销售表’[销售数量]
销售成本 = [销售数量] *RELATED(‘商品表’[进价])
Relatedtable函数
(一端找多端)(基础表找数据表)
订单数量 = COUNTROWS(RELATEDTABLE(‘销售表’)
COUNTROWS 函数:统计表的行数
筛选引擎Calculate
我们把不带任何筛选条件、CALCULATE只有第一参数的度量称为元度量。
引擎Calculate分为两部分,第一部分为计算器,第二部分为筛选器
单条件筛选
A01产品销量1 = CALCULATE([总销量],‘商品表’[商品编码]=“A01”)
A01产品销量2 = CALCULATE([总销量],‘销售表’[商品编码]=“A01”)
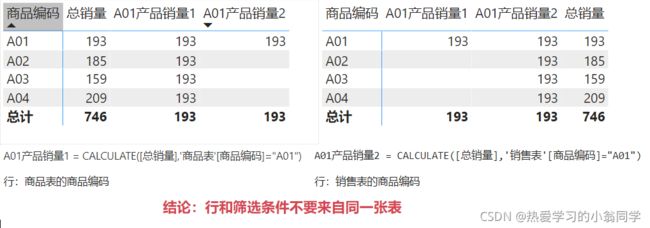
多条件筛选
两个列的多条件筛选
多条件 = CALCULATE([总销量],‘商品表’[商品名称]=“A01”,‘商品表’[进价]=1800)
一个列的多条件筛选
多条件1 = CALCULATE([总销量],‘商品表’[商品编码] in {“A01”,“A02”,“A03”})
多条件2 = CALCULATE([总销量],not ‘商品表’[商品编码] in {“A01”,“A02”,“A03”})

筛选表
Calculatetable(表,筛选条件)
可以多表运作筛选,最后返回一张表
筛选表 = CALCULATETABLE(‘销售表’,‘销售表’[店号]=1,‘商品表’[商品编码]=“A01”)
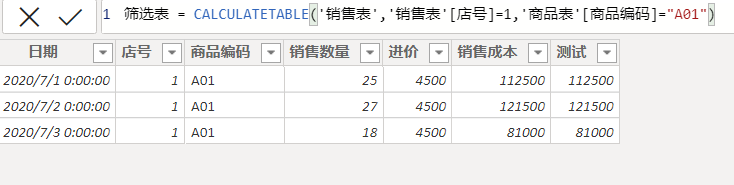
高级筛选器Filter
返回一个表,用于表示另一个表或表达式的子集,不能单独使用
Filter是一个表函数,Filter函数对筛选的表进行横向的**逐行扫描**,这样的函数叫迭代函数
举例:
Countrows(Filter(表,筛选条件))
先筛选,再计算行数Calculate(表达式(度量值),Filter(‘表名’,筛选条件))
计算1班男同学的总成绩
- 1班男生a = CALCULATE(‘度量值’[总成绩],‘花名册’[班级]=“1班”,‘花名册’[性别]=“男”)
- 1班男生b = CALCULATE(‘度量值’[总成绩],FILTER(‘花名册’,‘花名册’[班级]=“1班”&&‘花名册’[性别]=“男”))
简单的筛选时(筛选条件是列和固定值比较时),它们的效果是一样的
在Calculate函数中的直接筛选条件里,我们只能输入:
‘表’[列] = 固定值 或 ‘表’[列] <> 固定值‘表’[列]>=固定值 或 ‘表’[列] <= 固定值
‘表’[列] > 固定值 或 ‘表’[列] < 固定值
什么时候用Filter函数
[列] = [度量值]、[列] = 公式、[列] = [列]、
[度量值] = [度量值]、[度量值] = 公式、[度量值] = 固定值
注意:Filter第一参数的表,必须是唯一参数的表(一端的表)
例如 筛选总分>250,(总分是一个度量值),以下Filter2的写法是错误的
√:Filter1 = CALCULATE([总成绩],FILTER(‘花名册’,[总成绩]>250))
×:Filter2 = CALCULATE([总成绩],FILTER(‘成绩表’,[总成绩]>250))
度量值 [总成绩] = SUM(‘成绩表’[分数]) ,
那么,是否可以不使用度量值,将公式直接带入如Filter5?
答案是否定的
×:Filter5 =CALCULATE([总成绩],FILTER(‘花名册’,SUM(‘成绩表’[分数])>250))
Filter5 带入 SUM(‘成绩表’[分数]) ,只是带入了一个聚合函数,不具备筛选功能,可以改成如下形式:
√:Filter6 = CALCULATE([总成绩],FILTER(‘花名册’,CALCULATE(SUM(‘成绩表’[分数]))>250))
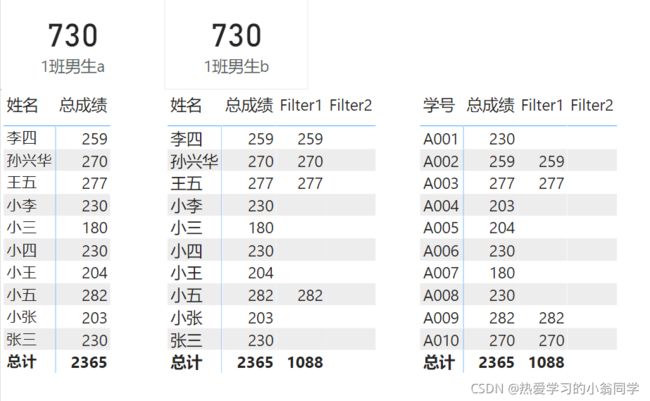
Values人工造表
如果没有一张唯一的表,那我们就可以使用Values人工造表
1、Values(表[列])
VALUES(‘成绩表’[学号])------------------可以拿到成绩表中学号的唯一值
Filter3 = CALCULATE([总成绩],FILTER(VALUES(‘成绩表’[学号]),[总成绩]>250))
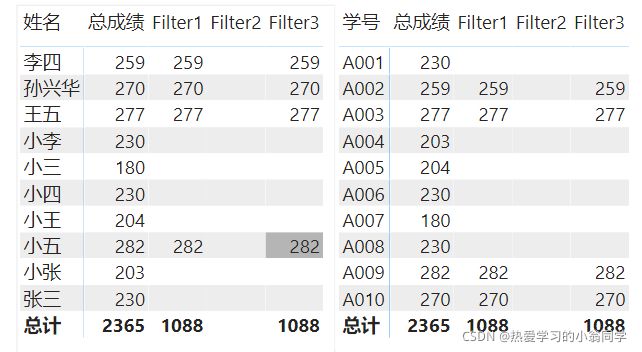
2、values(表)
复制一张表
DISTINCT
DISTINCT(表名[字段名]) 返回:去重后唯一值的列
DISTINCT(表) 返回:去除重复行的表
DISTINCT(返回表的表达式) 比如套用filter函数,先筛选再去重
VALUES与DISTINCT的差异
VALUES包括没有匹配的空白行(能返回空行),DISTINCT不返回没有匹配的空白行
DISTINCT函数允许列名或任何有效的表达式作为其参数,但VALUES函数仅接受列名或表名作为参数
ALL函数
ALL函数 ---------一般计算占比时会用到
作用:清除筛选(清除度量值的所有筛选) 返回:清楚筛选后的表格和列
筛选表
ALL函数应用于表(计算占比)
商品表中商品总数=CountRows(‘商品表’)
销售表中的商品数量= Calculate(CountRows(‘商品表’),‘销售表’)
这个时候可以用 [销售表中的商品数量] / [商品表中商品总数] ,求出销售过的商品类型占所有商品类型的占比,但是前提是矩阵里不能放行,否则就会具备筛选功能,如果我们不想要这个筛选功能,就可以用ALL函数来清楚筛选
不能筛选的总数 = CountRows(ALL(‘商品表’))
占比 = [销售表中的商品数量] / [不能筛选的总数]
计算销售表中每个商品的占比
总销量 = SUM(‘销售表’[销售数量])
禁止筛选的总销量 = CALCULATE ([总销量],all(‘销售表’))
每个商品的占比 = [总销量] / [禁止筛选的总销量]

当ALL参数为表是,忽略所有的筛选条件,无论是该图表内还是外部切片器
ALLSELECTED函数
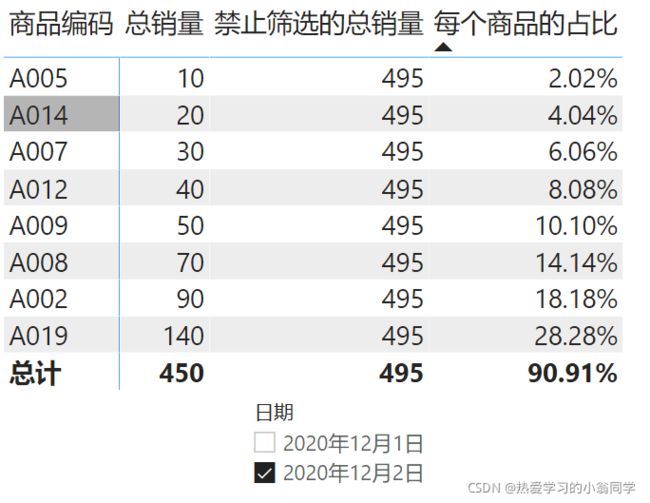
- 观察上图,占比100%变成90% ,这个时候出现了问题
外部加了筛选器,占比可能会受影响 ,这个时候将ALL函数替换成ALLSELECTED
ALLSELECTED函数不受内部筛选,受外部筛选
ALL函数应用于列(分类占比)
新建列
大类 = LOOKUPVALUE(‘商品表’[大类],‘商品表’[商品编码],‘销售表’[商品编码])
规格 = LOOKUPVALUE(‘商品表’[规格],‘商品表’[商品编码],‘销售表’[商品编码])
度量值
取消列筛选 = CALCULATE([总销量],all(‘销售表’[规格]))
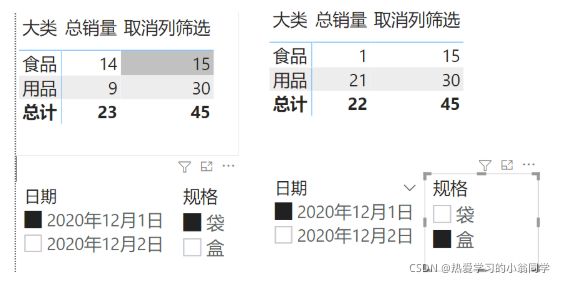
↑ 观察上图,规格的筛选并没有起作用
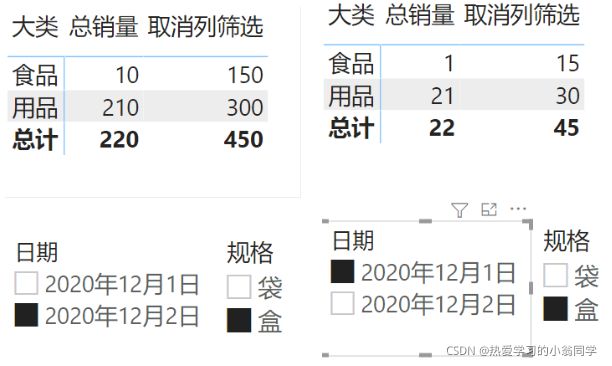
↑ 观察上图,对于日期的筛选起了作用
总结:当ALL函数的参数为列时,忽略该列筛选,其他图表字段或外部筛选对其产生作用
注意:ALL函数在引用列的时候,必须与矩阵的行和列在同一张表
假设,ALL函数引用的是销售表,矩阵行和列来自商品表,就会出错
占比 = [总销量] / [取消列筛选]
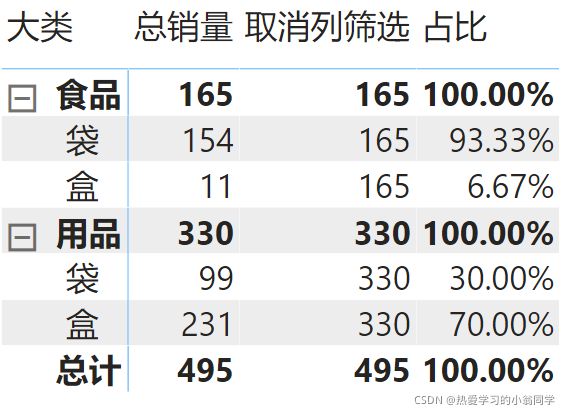
ALLEXCEPT函数
删除了所有筛选器(除了指定列的筛选器)
语法: Allexcept(表名[列名]) 等同于 All(表名[列名1],表名[列名2],表名[列名3],……)
可以是多个列,用逗号隔开
ALLNOBLANKROW
作用:返回表中除空白行以外的所有行(一般用于核对差异)
例如,签到表,名单是一个表,签字是一个表,核对哪些人没有到
聚合函数
SUM、AVERAGE(数值和/数值个数)、AVERAGEA(数值和/列的项数)、DISTINCTCOUNT、
COUNTA(计算列中单元格不为空的数目)、COUNTBLANK(计算列中单元格为空白数量)、PRODUCT(计算列中单元格乘积)
迭代函数
聚合函数+X
SUMX
将每一行按算数表达式计算后,再将计算结果求和
列 = sumx(‘表’, [列1] - [列] ) 对每一行逐行扫描,汇总求和
列 = CALCULATE( SUMX(‘表’, [列1] - [列2]) ) 加一个筛选,相当于展示每行的 列1 - 列2
AverageX、MaxX、MinX、CountX、CountaX、ProductX……它们都是行上下文函数
Earlier函数 [当前行]
例1:
用sumx只是为了逐行扫描,不具备实际作用
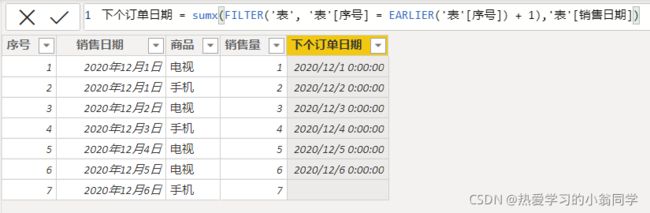
下个订单日期 = sumx( FILTER( ‘表’, ‘表’[序号] = EARLIER(‘表’[序号]) + 1),‘表’[销售日期])
sumx第二个参数不是表达式,不产生计算,所以结果就是销售日期
例2:累计求和
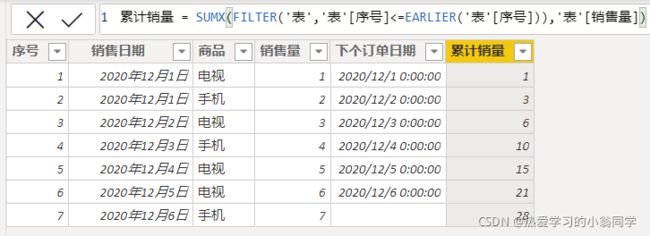
累计销量 = SUMX(FILTER(‘表’,‘表’[序号]<=EARLIER(‘表’[序号])),‘表’[销售量])
1、FILTER返回 序号小于等于当前序号的所有行的 表 2、对这个表进行逐行扫描,扫描 ‘表’[销售量] 求和
例3:分组累计求和
商品累计求和 = SUMX(FILTER(‘表’,‘表’[序号]<=EARLIER(‘表’[序号])&& ‘表’[商品]=EARLIER(‘表’[商品]) ),‘表’[销售量])
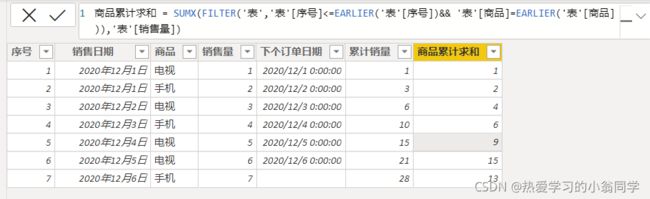
表没有序号比较也可以用销售日期比较 同理
例4:累计购买次数
第几次购买=COUNTROWS(FILTER(‘表1’,‘表1’[姓名]=EARLIER(‘表1’[姓名])&& ‘表1’[序号]<=EARLIER(‘表1’[序号])))

条件判断函数
1.IFERROR
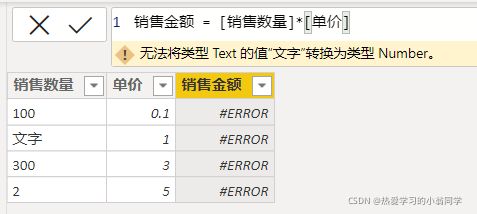
IFERROR遇到错误时使用指定数值替换
销售金额 = [销售数量]*[单价]
表达式计算遇到错误,返回空( blank() 换成数值也是可以的 ):
销售金额 = IFERROR([销售数量]*[单价],BLANK())
2.if条件判断
例1:称呼 = IF([性别]=“男”,“先生”,“女士”)
第三个参数可以省略不写,省略时返回为空
例2:
时间间隔 = IF([取款日期]=BLANK(),BLANK(),[取款日期]-[存款日期])
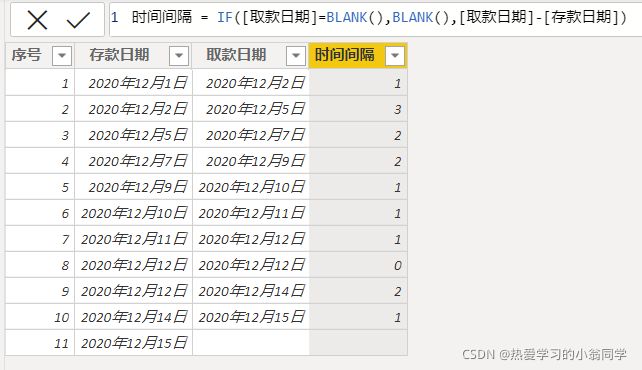
3.switch多项条件判断
switch(表达式,值1,结果1,……,[else])
最后一个参数可以省略不写,省略时返回为空
月份 = SWITCH(‘例3’[月],1,“一月”,2,“二月”,3,“三月”,
4,“四月”,5,“五月”,6,“六月”,7,“七月”,8,“八月”,
9,“九月”,10,“十月”,11,“十一月”,12,“十二月”,“无法识别”)
switch的特殊用法
使用TRUE做第一参数,返回条件判断List中第一个为TRUE的结果
年龄段 = SWITCH(TRUE(),‘例4’[年龄]<30,“30岁以下”,
‘例4’[年龄]<40,“30-40岁”,‘例4’[年龄]<50,“40-50岁”,
“50岁以上”)
若是多个条件,使用 && 连接即可
欢迎关注我的博客,与我一起学习数据分析,我将持续分享我的学习过程,我是 热爱学习的小翁同学~