JetsonNano部署改进yolov5算法(C++)
前段时间根据项目需求改进了一版yolov5的算法,但是发现网上对于如何在Jetson nano上用c++部署自己的改进的目标检测算法的资料很少。为了方便自己的学习,在此总结了自己的一套方法。由于篇幅有限,该文章中很多技术细节没有体现,读者可以参考其它文章对比看,可以提高学习的效率。
一.相关软件
1.yolov5源码
yolov5是2020年6月Ultralytics发布的,可以去下面地址直接下载。
地址:https://github.com/ultralytics/yolov5.git
2.Netron神经网络可视化软件
Netron是一个网络可视化软件,该软件可以直接显示训练好的神经网络模型,方便对网络模型进行观察。该软件可以直接在Google上打开使用,非常方便,并且该软件支持pt、torchscript、onnx等多种参数模型,有兴趣的伙伴可以慢慢去尝试。
地址:https://netron.app/
3.TensorRT
TensorRT是nvidia家的一款高性能深度学习推理SDK。此SDK包含深度学习推理优化器和运行环境,可为深度学习推理应用提供低延迟和高吞吐量。此项目是根据此开源软件包进行二次开发。在github上下载合适的版本,通过cmake工具直接安装在JetsonNano中。
地址:https://github.com/NVIDIA/TensorRT.git
4.tensorrtx
这个开源软件包是在github上开源的,这里面有很多已经写好的神经网络的例子,按要求编译后可以直接使用。大家如果想深入学习tensorrt,建议直接学习官方资料,直接coding。在此使用该开源软件包中的例子,加入自己改进的网络。
地址:https://github.com/wang-xinyu/tensorrtx.git
二.模型的准备
信大家现在都有一个属于自己的训练好的网络模型(.pt格式)。我们现在需要通过一个脚本将.pt格式的文件转换成.wts的文件。下面附上代码(这个代码在tensorrtx的每个工程中都有,可以直接复制到yolov5根目录中)。
import argparse
import os
import struct
import torch
from utils.torch_utils import select_device
def parse_args():
parser = argparse.ArgumentParser(description='Convert .pt file to .wts')
parser.add_argument('-w', '--weights', required=True,
help='Input weights (.pt) file path (required)')
parser.add_argument(
'-o', '--output', help='Output (.wts) file path (optional)')
parser.add_argument(
'-t', '--type', type=str, default='detect', choices=['detect', 'cls'],
help='determines the model is detection/classification')
args = parser.parse_args()
if not os.path.isfile(args.weights):
raise SystemExit('Invalid input file')
if not args.output:
args.output = os.path.splitext(args.weights)[0] + '.wts'
elif os.path.isdir(args.output):
args.output = os.path.join(
args.output,
os.path.splitext(os.path.basename(args.weights))[0] + '.wts')
return args.weights, args.output, args.type
pt_file, wts_file, m_type = parse_args()
# Initialize
device = select_device('cpu')
# Load model
model = torch.load(pt_file, map_location=device) # load to FP32
model = model['ema' if model.get('ema') else 'model'].float()
if m_type == "detect":
# update anchor_grid info
anchor_grid = model.model[-1].anchors * \
model.model[-1].stride[..., None, None]
# model.model[-1].anchor_grid = anchor_grid
delattr(model.model[-1], 'anchor_grid') # model.model[-1] is detect layer
# The parameters are saved in the OrderDict through the "register_buffer" method, and then saved to the weight.
model.model[-1].register_buffer("anchor_grid", anchor_grid)
model.to(device).eval()
with open(wts_file, 'w') as f:
f.write('{}\n'.format(len(model.state_dict().keys())))
for k, v in model.state_dict().items():
vr = v.reshape(-1).cpu().numpy()
f.write('{} {} '.format(k, len(vr)))
for vv in vr:
f.write(' ')
f.write(struct.pack('>f', float(vv)).hex())
f.write('\n')将上述脚本命名为gen_wts.py,在pycharm中终端下直接输入以下代码即可生成.wts文件。其中best.pt中best可替换成自己模型的名称。同样,best.wts中best为输出后的文件名称。
python gen_wts.py -w best.pt -o best.wts2.转化成.engine的文件
在这一步,我们需要具体编写自己的神经网络模型,如果是对yolov5算法改进,只需要编写相应的改进模型,程序框架可以使用tensorrtx中的程序,可以将这些程序封装成类,以便之后的使用。在编写自己的神经网络代码时,必须严格按照训练时的网络框架,否则会出现很多错误。在tensorrt中封装有很多网络层,可以直接百度官方的tensorrt的使用文档进行查询。如果在tensorrt中没有对应的网络层,可以通过其它网络层堆叠构建新的网络层,但是要保证参数量的一致,不然无法正常生成.engine文件。
然后将编写完成的网络,按照训练时的神经网络架构放到模型的指定位置,例如我自己创建的网络放在第9层当中,这里要非常详细的知道每层网络的输入、输出的大小(可以使用Netron工具查看)。
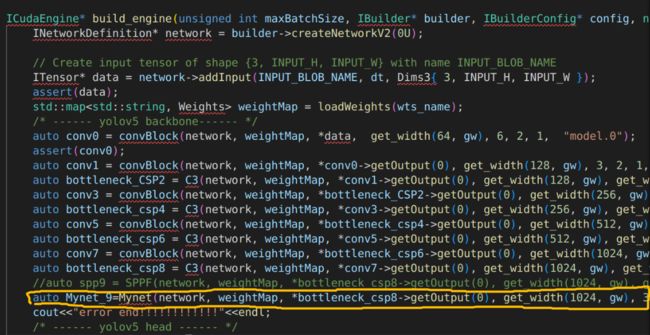
然后,将整个文件编译生成可执行文件。使用该文件生成.engine文件即可。例如,生成的可执行名为yolov5,可直接使用下面代码生成.engine文件。
./yolov5 -s best.wts best.engine s至此,可用于推理的文件已经生成,接下来就是使用此文件来进行识别。
三.模型推理
在进行模型推理时,我们需要依据tensorrt构建一整套的模型推理框架,我们需要从生成的.engine文件中分别构造三个主要的对象,其class分别为IRuntime、ICudaEngine、IExecutionContext,具体如何构建可参考Nvidia官网中有关tensorrt的文档,也可以直接参考tensorrtx中的源码。
最后一步,将构建好的文件进行编译,即可生成最终的效果图。如下图所示。

总体来说,效果还可以,推理速度大约是8ms或者9ms一帧,应该还是可以提高的。
对于如何详细构建网络以及最后的模型推理,这里没有细讲,等之后会陆续的写成博客,方便你我他。如果各位小伙伴有什么建议和疑问,欢迎随时私信。