Bug小能手系列(python)_14: pd.concat得到的矩阵错误
pd.concat得到的不是自己想要的矩阵
- 0 引言
- 1 错误原因
- 2 解决思路
- 3 具体代码
- 4 总结
0 引言
今天在运行pd.concat (pd指的是pandas库),需要将两个DataFrame数据(数据分别为5*4的矩阵)进行列合并时,突然发现得到的矩阵是10*8的,而不是我想要的5*8的!!!虽然是个小问题,但是感觉网上给出的内容一直没把这个问题介绍清楚,这里就专门写一篇文章帮助大家理解这个问题,希望大家可以清晰地理解这个问题。运行得到的矩阵数据的图片如下:

运行代码的如下:
data = pd.concat([data_0, data_1], axis=1)
# 或者是下面这样 得到的结果是一样的
# 下面这样结果更不好 会消掉你的索引
data = pd.concat([data_0, data_1], axis=1, ignore_index=True)
可以看到矩阵中有很多nan的数值,初步分析是存在空缺值,排查后发现没有!!
然后,怀疑是两个数据冲突导致的,但是数据为什么会冲突呢? 根本没有什么区别呀?
最后,经过仔细分析后发现是:行号冲突!!!
1 错误原因
其实错误原因很简单:前面5行数据的行号和后面5行的行号不一样,所以使用concat连接的时候不会列直接连接,所以导致最终是个10*8的矩阵。
2 解决思路
按照上面的原因,只要将行号重置一下,那样的话不就可以正常连接了嘛?!
没错,解决思路就是将行号重置!!!
这里简要介绍一下所用的函数:reset_index
- level: 控制
哪些层次的索引需要被重置,默认为 None,表示所有层次的索引都会被重置。 - drop: 如果为 True,将
重置的索引从列中删除,默认为 False。 - inplace: 如果为 True,将在
原地修改对象,并返回 None。如果为 False,将返回一个新的带有重置索引的对象,默认为 False。 - col_level: 如果索引是多层次的,
指定将哪个层次的索引重置为列,默认为 0。 - col_fill: 如果指定了 col_level,可以
用来指定新列的名称。
注意:这里没有明确说到底哪个是重置行号的,但是有个原地修改对象,这个可以直接将行号重置!!!
原来的data_1:

使用了代码:
# 这里注意drop=True 这个也是要加的 不然你的行号会变成一个单独的列
# 有兴趣的可以测试一下
data_1.reset_index(drop=True, inplace=True)
重置后的data_1:

3 具体代码
下面是使用zeros矩阵生成的数据,跟真实数据本质是一样的。示例代码如下(大家可以测试一下上面说的问题 以及解决方案):
data_df = np.DataFrame(np.zeros([100,4]))
for i in range(len(data_df)//10):
data_0 = data_df.iloc[i*5:(i+1)*5,:]
data_1 = data_df.iloc[start_ind+i*5:start_ind+(i+1)*5, :]
# 很少有人重置这里 这是因为第一遍的时候 data_0的索引就是0-4 所以不用重置
# 但是第二遍的时候索引就不是了 所以在我们的代码里这个部分需要重置
data_0.reset_index(drop=True,inplace=True)
data_1.reset_index(drop=True, inplace=True)
data = pd.concat([data_0, data_1],axis=1)
第1轮的data_0:
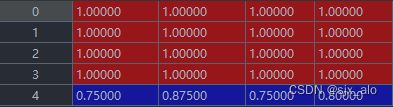
第2轮的data_0:

4 总结
总的而言,感觉出现concat得到矩阵错误主要是因为行号的问题。如果大家有什么问题的话可以评论留言,这边会根据最新的内容进行更新!!!
如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦。