数据库事务
MySQL常用的存储引擎有InnoDB(支持事务)和MyISAM(不支持事务)。
数据库事务是指构成单一逻辑工作单元的操作集合,即作为单个逻辑工作单元执行的一系列操作(对数据库的相关增删改查的操作)。
事务默认是自动开启的。可以手动开启和关闭事务。手动开启事务的方式有两种:begin;命令和start transaction;命令,手动关闭事务的方式也有两种:commit;命令和rollback;命令。事务结束就是在执行commit;或rollback;命令之后。对于自动开启的事务,会在sql语句执行完后,无论成功与否,都会自动关闭事务,也就是自动执行commit;或rollback;命令。事务结束的时候,事务所持有的锁就会被释放。在使用数据库客户端工具(如Navicat)与服务端建立连接,当手动开启事务,并执行sql语句之后,如果没有执行commit;或rollback;命令,而是直接关闭窗口或客户端工具,这时事务会回滚,相当于手动执行rollback;命令。
一、事务的特性-ACID
数据库事务的四大特性(ACID)及实现原理:
原子性(Atomicity):一个事务必须被视为不可分割的最小工作单位,一个事务中的所有操作要么全部成功提交,要么全部失败回滚,对于一个事务来说不可能只执行其中的部分操作,这就是事务的原子性。
一致性(Consistency):事务的执行结果必须使数据库从一个一致性状态到另一个一致性状态。
隔离性(Isolation):多个事务之间互不影响,其对数据库的操作应该和它们串行执行时一样。
持久性(Durability):事务一旦提交,其对数据库的更新就是持久的。任何事务或系统故障都不会导致数据丢失。
一致性是数据库事务的根本追求,原子性、持久性和隔离性都是为实现一致性服务的。
对数据一致性的破坏主要来自两个方面:事务故障(或系统故障)和事务的并发执行。数据库系统是通过日志恢复技术和并发控制技术来避免这两种情况发生的。日志恢复技术保证了事务的原子性(undo log)和持久性(redo log),使一致性状态不会因事务或系统故障被破坏。并发控制技术(锁和MVCC)保证了事务的隔离性,使数据库的一致性状态不会因为并发执行的操作被破坏。
1、原子性实现原理:undo log
undo log叫做回滚日志,用于记录数据被修改前的信息。undo log主要记录的是数据的逻辑变化,为了在发生错误时回滚之前的操作,需要将之前的操作都记录下来,然后在发生错误时才可以回滚。
每条数据变更(insert/update/delete)操作都伴随一条undo log的生成,并且回滚日志必须先于数据持久化到磁盘上。所谓的回滚就是根据回滚日志做逆向操作,比如delete的逆向操作为insert,insert的逆向操作为delete,update的逆向为update。回滚操作就是要还原到原来的状态,undo log记录了数据被更改前的信息以及新增、删除和修改数据的sql语句,根据undo log生成回滚语句,比如:
(1) 如果在回滚日志里有新增数据记录,则生成删除该条记录的sql语句。
(2) 如果在回滚日志里有删除数据记录,则生成新增该条记录的sql语句。
(3) 如果在回滚日志里有修改数据记录,则生成修改回原先数据的sql语句。
总之,undo log是用来回滚数据的,用于保障未提交事务的原子性。
2、持久性实现原理:redo log
例如有两张表:银行账户表bank(name=’lisi’,balance=1000)和理财账户表finance(name=’lisi’,amount=0),从bank表中转出400元到finance表中。
start transaction;
select balance from bank where name="lisi";
//在Buffer Pool中保存修改后的balance的值,紧接着在redo log buffer中生成重做日志 balance=600,undo log中也有相应记录保存,以便回滚
update bank set balance = balance - 400;
//在Buffer Pool中保存修改后的amount的值,紧接着在redo log buffer中生成重做日志 amount=400,undo log中也有相应记录保存,以便回滚
update finance set amount = amount + 400;
//提交事务就是将redo log buffer中的日志记录持久化到磁盘上,undo log中也有相应记录保存,以便回滚
commit;
redo log叫做重做日志,是用来实现事务的持久性。重做日志中记录数据被修改后的信息。该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到该日志中。
mysql为了提升性能不会把每次修改的数据都实时同步到磁盘,而是会先存到Buffer Pool(缓冲池)里头,把这个当作缓存来用。然后使用后台线程将缓冲池中的数据持久化到磁盘。
那么问题来了,如果还没来得及同步(将缓冲池中的数据持久化到磁盘上)的时候宕机或断电了,这样会导致丢失已提交事务的修改信息!所以引入了redo log来记录已成功提交事务的修改信息,并且会把redo log持久化到磁盘,系统重启之后再读取redo log恢复最新数据。
总之,redo log是用来恢复数据的,用于保障已提交事务的持久化特性。
既然redo log也需要存储,也涉及磁盘IO为啥还用它?
(1)redo log 的存储是顺序存储,而缓存同步是随机操作。
(2)缓存同步是以数据页为单位的,每次传输的数据大小大于redo log。
3、隔离性实现原理:读写锁和MVCC
隔离性是要管理多个事务并发读写请求的访问顺序。 这种顺序包括串行和并行。
MySQL中事务的隔离性是通过读写锁和MVCC两种方式实现的,默认隔离级别是REPEATABLE READ。
读写锁:读锁(又被称为共享锁shared lock)和写锁(又被称为排他锁exclusive lock)。
读锁是可以共享的,或者说多个读请求可以共享一把锁读数据,不会造成阻塞。
写锁会排斥其他所有获取锁的请求,一直阻塞,直到写入完成释放锁。当一个事务获取写锁,其他事务既不能获取写锁,也不能获取读锁,即写写互斥,读写互斥。
采用读写锁实现REPEATABLE READ:
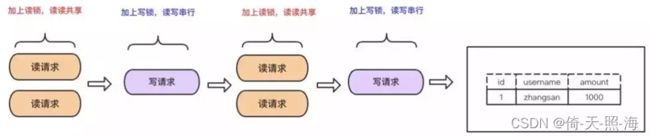
MVCC (MultiVersion Concurrency Control) 叫做多版本并发控制,是指生成一个数据请求时间点的一致性数据快照(snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取。
InnoDB的MVCC是通过在每行记录的后面保存两个隐藏的列来实现的。这两个列,一个保存了行的创建时间,一个保存了行的过期时间,当然存储的并不是实际的时间值,而是系统版本号。(以上片段摘自《高性能Mysql》这本书对MVCC的定义)
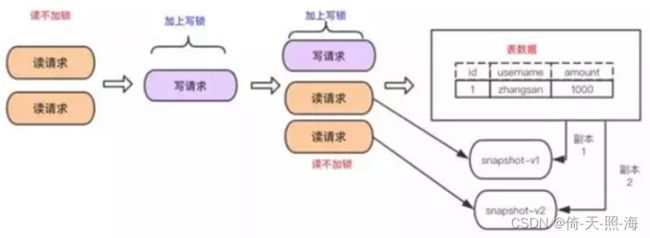
其主要实现思想是通过数据多版本来做到读写分离,从而实现读不加锁来做到读写并行。
MVCC在mysql中的实现依赖的是undo log与read view,undo log中记录某行数据的多个版本的数据,read view用来判断当前版本数据的可见性。
采用MVCC实现REPEATABLE READ:
4、一致性实现原理
通过原子性(undo log)、持久性(redo log)和隔离性(读写锁)共同实现一致性。
二、事务的隔离级别
常见的并发异常:
1、脏写是指事务回滚了其他事务对数据项的已提交修改,例如事务1对数据A的回滚,导致事务2对A的已提交修改也被回滚了。
2、丢失更新是指事务覆盖了其他事务对数据的已提交修改,导致这些修改好像丢失了一样。
3、脏读是指一个事务读取了另一个事务未提交的数据。例如,在事务1对A的处理过程中,事务2读取了A的值,但之后事务1回滚,导致事务2读取的A是未提交的脏数据。
4、不可重复读是指同一查询在同一事务中多次进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集,此时发生不可重复读。(A transaction rereads data it has previously read and finds that another committed transaction has modified or deleted the data. )。
5、幻读是指同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻读。(A transaction reexecutes a query returning a set of rows that satisfies a search condition and finds that another committed transaction has inserted additional rows that satisfy the condition. )。
脏读和不可重复读的区别在于:前者读取的是其他事务未提交的脏数据,后者读取的是其他事务已经提交的数据。
幻读和不可重复读的区别在于:表面上看,区别就在于不可重复读能看见其他事务提交的修改和删除,而幻读能看见其他事务提交的插入。不可重复读重点在于update和delete,而幻读的重点在于insert。
事务具有隔离性,理论上来说事务之间的执行不应该相互产生影响,其对数据库的影响应该和它们串行执行时一样。然而完全的隔离性会导致系统并发性能很低,降低对资源的利用率,因而实际上对隔离性的要求会有所放宽,这也会一定程度造成对数据库一致性要求降低。SQL标准为事务定义了不同的隔离级别。
事务的隔离级别,从低到高依次是:
读未提交(READ UNCOMMITTED),会产生脏读、不可重复读和幻读。
读已提交(READ COMMITTED),解决了脏读,但会产生不可重复读和幻读。
可重复读(REPEATABLE READ),解决了脏读和不可重复读,但会产生幻读。
串行化(SERIALIZABLE),解决了脏读、不可重复读和幻读。
事务的隔离级别越低,可能出现的并发异常越多,但是通常而言系统能提供的并发能力越强。因此,较低的隔离级别会破坏数据的一致性。MySQL默认的隔离级别是可重复读。
三、锁
MySQL官网中提到了在InnoDB中支持八种锁。
This section describes lock types used by InnoDB.
- Shared and Exclusive Locks
- Intention Locks
- Record Locks
- Gap Locks
- Next-Key Locks
- Insert Intention Locks
- AUTO-INC Locks
- Predicate Locks for Spatial Indexes
1、共享锁/排他锁(读锁/写锁)
在MySQL的官方文档中有以下描述:
InnoDB implements standard row-level locking where there are two types of locks, shared (S) locks and exclusive (X) locks。
A shared (S) lock permits the transaction that holds the lock to read a row.
An exclusive (X) lock permits the transaction that holds the lock to update or delete a row.
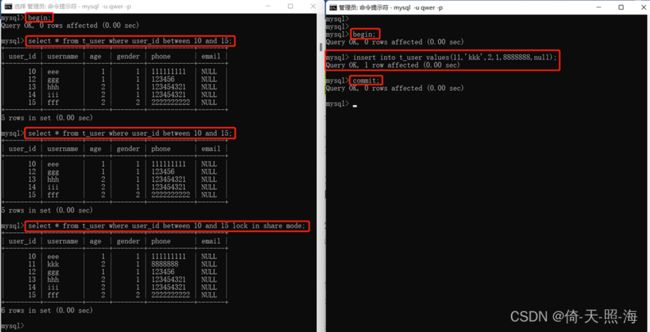
这段话明确说明了共享锁/排他锁都只是行锁,与间隙锁无关,这一点很重要,后面还会强调这一点。其中共享锁是一个事务并发读取某一行记录所需要持有的锁,比如select ... lock in share mode;排他锁是一个事务并发更新或删除某一行记录所需要持有的锁,比如select ... for update。
不过这里需要重点说明的是,尽管共享锁/排他锁是行锁,与间隙锁无关,但一个事务在请求共享锁/排他锁时,获取到的结果却可能是记录锁,也可能是间隙锁,也可能是临键锁,这取决于数据库的隔离级别以及查询的数据是否存在。
共享锁之间不互斥,简记为:读读可以并行。排他锁与任何锁互斥,简记为:写读,写写不可以并行。
2、意向共享锁/意向排他锁
在MySQL的官方文档中有以下描述:
Intention locks are table-level locks that indicate which type of lock (shared or exclusive) a transaction requires later for a row in a table。
The intention locking protocol is as follows:
Before a transaction can acquire a shared lock on a row in a table, it must first acquire an IS lock or stronger on the table.
Before a transaction can acquire an exclusive lock on a row in a table, it must first acquire an IX lock on the table.
这段话说明意向共享锁/意向排他锁属于表锁,且取得意向共享锁/意向排他锁是取得共享锁/排他锁的前置条件。
意向锁的主要目的是表明有事务正在锁定表中的行,或者打算锁定表中的行。意向锁是一个标志,用于告诉事务是否有其他事务正在锁定表中的记录。
共享锁/排他锁与意向共享锁/意向排他锁的兼容性关系:
| 事务2 事务1 |
X |
IX |
S |
IS |
| X |
互斥 |
互斥 |
互斥 |
互斥 |
| IX |
互斥 |
兼容 |
互斥 |
兼容 |
| S |
互斥 |
互斥 |
兼容 |
兼容 |
| IS |
互斥 |
兼容 |
兼容 |
兼容 |
这里需要重点关注的是IX锁和IX锁是相互兼容的。
3、记录锁
在MySQL的官方文档中有以下描述:
A record lock is a lock on an index record. Record locks always lock index records, even if a table is defined with no indexes. For such cases, InnoDB creates a hidden clustered index and uses this index for record locking.
这句话说明记录锁一定是作用在索引上的。
记录锁是锁定一条记录,作用在索引上。如果一张表没有索引(主键索引和唯一索引),InnoDB会默认为该表生成一个隐藏字段row_id作为主键,这时记录锁就会全表扫描row_id字段,为该字段加锁,其实就是加上表锁,也就是说行锁退化成表锁。
4、间隙锁
在MySQL的官方文档中有以下描述:
A gap lock is a lock on a gap between index records, or a lock on the gap before the first or after the last index record。
这句话表明间隙锁一定是开区间,比如(3,5)。在MySQL官网上还有一段非常关键的描述:
Gap locks in InnoDB are “purely inhibitive”, which means that their only purpose is to prevent other transactions from inserting to the gap. Gap locks can co-exist. A gap lock taken by one transaction does not prevent another transaction from taking a gap lock on the same gap. There is no difference between shared and exclusive gap locks. They do not conflict with each other, and they perform the same function.
这段话表明间隙锁在本质上是不区分共享间隙锁或互斥间隙锁的,而且间隙锁是不互斥的,即两个事务可以同时持有包含共同间隙的间隙锁。这里的共同间隙包括两种场景:其一是两个间隙锁的间隙区间完全一样;其二是一个间隙锁包含的间隙区间是另一个间隙锁包含间隙区间的子集。间隙锁本质上是用于阻止其他事务在该间隙内插入新记录,而自身事务是允许在该间隙内插入数据的。也就是说间隙锁的应用场景包括并发读取、并发更新、并发删除和并发插入。
在MySQL官网上关于间隙锁还有一段重要描述:
Gap locking can be disabled explicitly. This occurs if you change the transaction isolation level to READ COMMITTED. Under these circumstances, gap locking is disabled for searches and index scans and is used only for foreign-key constraint checking and duplicate-key checking.
这段话表明,在RU和RC两种隔离级别下,即使你使用select ... lock in share mode或select ... for update,也无法防止幻读(读后写的场景)。因为在RU隔离级别下没有锁,在RC隔离级别下只会有记录锁,而不会有间隙锁。InnoDB中,在RR隔离级别下使用间隙锁解决幻读。幻读是指某个事物多次执行相同的查询得到的范围结果不一样,这是因为其他事务在此期间插入了新的数据记录。间隙锁就是用于阻止其他事务在某个间隙内插入新记录。
5、临键锁
在MySQL的官方文档中有以下描述:
A next-key lock is a combination of a record lock on the index record and a gap lock on the gap before the index record.
这句话表明临键锁是记录锁+间隙锁,即临键锁是是一个左开右闭的区间,比如(3,5]。
在MySQL的官方文档中还有以下重要描述:
By default, InnoDB operates in REPEATABLE READ transaction isolation level. In this case, InnoDB uses next-key locks for searches and index scans, which prevents phantom rows.
个人觉得这段话描述得不够好,很容易引起误解。这里更正如下:InnoDB的默认事务隔离级别是RR,在这种级别下,如果使用select ... lock in share mode或者select ... for update语句,那么InnoDB会使用临键锁,因而可以防止幻读。如果只是使用普通的select语句,即使隔离级别是RR,那么InnoDB将是快照读,使用的是MVCC,不会使用任何锁,因而还是无法防止幻读。
如下图所示,在事务1中使用加锁的select读取一个区间,在事务2中向同一个区间内插入一条数据,由于锁等待超时,事务2回滚,插入失败。事务1再次查询,两次查询结果相同。
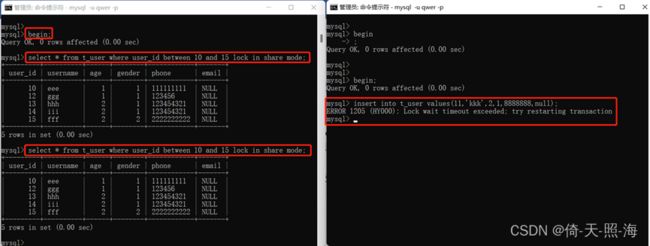
6、插入意向锁
在MySQL的官方文档中有以下重要描述:
An insert intention lock is a type of gap lock set by INSERT operations prior to row insertion. This lock signals the intent to insert in such a way that multiple transactions inserting into the same index gap need not wait for each other if they are not inserting at the same position within the gap. Suppose that there are index records with values of 4 and 7. Separate transactions that attempt to insert values of 5 and 6, respectively, each lock the gap between 4 and 7 with insert intention locks prior to obtaining the exclusive lock on the inserted row, but do not block each other because the rows are nonconflicting.
这段话表明尽管插入意向锁是一种特殊的间隙锁,但不同于间隙锁的是,该锁只用于并发插入操作。如果说间隙锁锁住的是一个区间,那么插入意向锁锁住的就是一个点。因而从这个角度来说,插入意向锁确实是一种特殊的间隙锁。与间隙锁的另一个非常重要的差别是:尽管插入意向锁也属于间隙锁,但两个事务却不能在同一时间内一个拥有间隙锁,另一个拥有该间隙区间内的插入意向锁(当然,插入意向锁如果不在间隙锁区间内则是可以的)。这里我们再回顾一下共享锁和排他锁:共享锁用于读取操作,而排他锁是用于更新或删除操作。也就是说插入意向锁、共享锁和排他锁涵盖了常用的增删改查四个动作。
7、自增锁
最后,我们再来介绍下自增锁。在MySQL的官方文档中有以下描述:
An AUTO-INC lock is a special table-level lock taken by transactions inserting into tables with AUTO_INCREMENT columns.The innodb_autoinc_lock_mode configuration option controls the algorithm used for auto-increment locking. It allows you to choose how to trade off between predictable sequences of auto-increment values and maximum concurrency for insert operations.
这段话表明自增锁是一种特殊的表级锁,主要用于事务中插入自增字段,也就是我们最常用的自增主键id。通过innodb_autoinc_lock_mode参数可以设置自增主键的生成策略。
8、空间索引的谓词锁(Predicate Locks for Spatial Indexes)
Innodb 支持对包含空间列的列进行 SPATIAL 索引。
为了处理与 SPATIAL 索引有关的操作的锁定,邻键锁定不能很好地支持 REPEATABLE READ 或 SERIALIZABLE 事务隔离级别。 多维数据中没有绝对排序概念,因此不清楚哪个是邻键。
为了支持具有 SPATIAL 索引的表的隔离级别,InnoDB使用谓词锁。空间索引包含最小外接矩形值,因此 InnoDB 通过在用于查询的 MBR 值上设置谓词锁来强制对索引进行一致性读。 其他事务不能插入或修改与查询条件匹配的行。
9、产生死锁的示例分析
上面介绍了MySQL中用到的八种锁,理解了前六种锁之后,下面分析两个场景。
有如下一张表:
CREATE TABLE test (
id int(20) NOT NULL,
name varchar(20) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
表中有如下数据:
mysql> SELECT * FROM test;
+----+------+
| id | name |
+----+------+
| 1 | 1 |
| 5 | 5 |
| 10 | 10 |
| 15 | 15 |
| 20 | 20 |
| 25 | 25 |
+----+------+
6 rows in set (0.00 sec)
当数据库的隔离级别为Repeatable Read或Serializable时,我们来看这样的两个并发事务。
先来分析场景一:

在场景一中,因为IX锁是表锁且IX锁之间是兼容的,因而事务一和事务二都能同时获取到IX锁和间隙锁。另外,需要说明的是,因为我们的隔离级别是RR,且在请求X锁的时候,查询的对应记录都不存在,因而返回的都是间隙锁。如果记录存在的话,得到的是记录锁,这样两个事务之间就彼此没有影响,都可以成功插入。接着事务一请求插入意向锁,这时发现事务二已经获取了一个区间间隙锁,而且事务一请求的插入点在事务二的间隙锁区间内,因而只能等待事务二释放间隙锁。这个时候事务二也请求插入意向锁,该插入点同样位于事务一已经获取的间隙锁的区间内,因而也不能获取成功,不过这个时候,MySQL已经检查到了死锁,于是事务二被回滚,事务一提交成功。
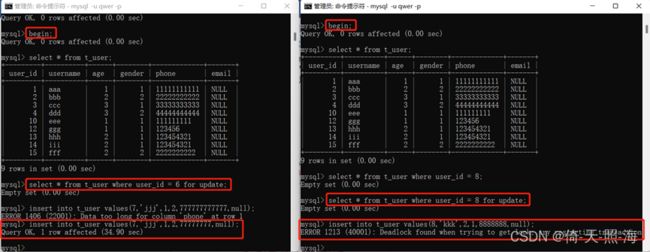
如上图所示,事务一向表中插入一条数据时被阻塞了,花了34.9秒才插入成功,这是因为事务二向表中插入数据时,MySQL检查到死锁,事务二立即被回滚,事务一才插入成功。不过此时事务一还未提交,在事务二中还查不到事务一插入的数据,等到事务一提交之后,在事务二中就可以查到事务一插入的数据了。
分析并理解了场景一,那场景二理解起来就会简单多了:
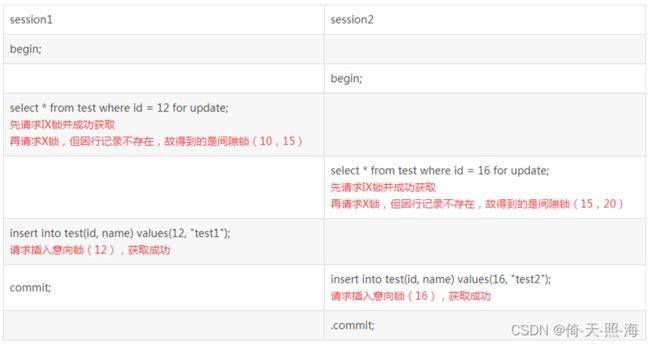
场景二中,两个间隙锁没有交集,而各自获取的插入意向锁也不是同一个点,因而都能执行成功。
总结:InnoDB中四种隔离级别是如何通过锁来实现的?
| READ UNCOMMITTED (RU) |
READ COMMITTED (RC) |
REPEATABLE READ (RR)(默认隔离级别) |
SERIALIZABLE |
|
| 普通的select |
不加锁 无MVCC |
MVCC |
MVCC |
被隐式的转成加锁的select |
| 加锁的select |
Record Lock |
Record Lock Gap Lock Next-key Lock |
排他锁 |
|
| insert |
||||
| update |
||||
| delete |
加锁的select包括:select ... lock in share mode(共享锁)和select ... for update(排他锁)。
InnoDB中的RR隔离级别使用间隙锁(Gap Lock)可以解决幻读。

如图所示,如果当前事务执行的是当前读(即加锁的select),由于当前事务对所查数据已经加锁,其他事务根本就无法对加锁数据执行增删改操作,等待一会就会提示错误:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction。
四、MVCC
1、什么是MVCC?
MVCC (MultiVersion Concurrency Control) 叫做多版本并发控制,其实现原理是生成一个数据请求时间点的一致性数据快照(snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取。
如此一来不同的事务在并发过程中,SELECT操作可以不加锁而是通过MVCC机制读取指定的版本历史记录(快照读),并通过一些手段保证读取的记录值符合事务所处的隔离级别,从而解决并发场景下的读写冲突。
快照读:SQL读取的数据是快照版本,也就是历史版本,普通的SELECT就是快照读,数据的读取将由cache(原本数据) + undo(事务修改过的数据) 两部分组成。
当前读:SQL读取的数据是最新版本。通过锁机制来保证读取的数据无法通过其他事务进行修改。UPDATE、DELETE、INSERT、SELECT … LOCK IN SHARE MODE、SELECT … FOR UPDATE都是当前读。
下面举一个多版本读的例子,例如两个事务 A 和 B 按照如下顺序进行更新和读取操作。
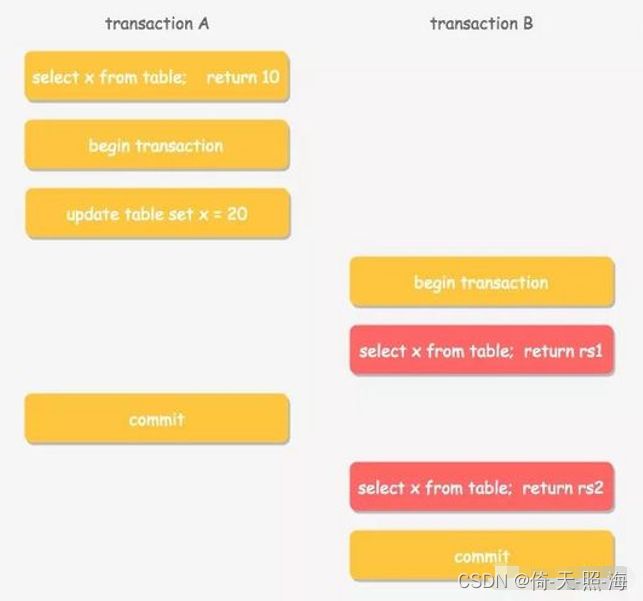
在事务 A 提交前后,事务 B 读取到的 x 的值是什么呢?答案是:事务 B 在不同的隔离级别下,读取到的值不一样。
1.如果事务 B 的隔离级别是读未提交(RU),那么两次读取均读取到 x 的最新值,即 20 。
2.如果事务 B 的隔离级别是读已提交(RC),那么第一次读取到旧值 10 ,第二次因为事务 A 已经提交,则读取到新值20。
3.如果事务 B 的隔离级别是可重复读(RR)或者串行(S),则两次均读到旧值 10 ,不论事务 A 是否已经提交。
可见在不同的隔离级别下,数据库通过 MVCC 和隔离级别,让事务之间并行操作遵循了某种规则,来保证单个事务内前后数据的一致性。
2、为什么需要MVCC?
InnoDB相比MyISAM 有两大特点,一是支持事务,二是支持行级锁。事务的引入带来了一些新的挑战。相对于串行处理来说,并发事务处理能大大增加数据库资源的利用率,提高数据库系统的事务吞吐量,从而可以支持更多的用户。但并发事务处理也会带来一些问题,主要包括以下几种情况:
1.更新丢失( Lost Update ):当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题 —— 最后的更新覆盖了其他事务所做的更新。如何避免这个问题呢,最好在一个事务对数据进行更改但还未提交时,其他事务不能访问修改同一个数据。
2.脏读( Dirty Reads ):一个事务正在对一条记录做修改,在这个事务提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些尚未提交的脏数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做 “脏读” 。
3.不可重复读( Non-Repeatable Reads ):一个事务在读取某些数据已经发生了改变、或某些记录已经被删除了!这种现象叫做“不可重复读”。
4.幻读( Phantom Reads ):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为 “幻读” 。
以上是并发事务过程中会存在的问题,解决更新丢失可以交给应用,但是后三者需要数据库提供事务间的隔离机制来解决。 实现隔离机制的方法主要有两种 :读写锁和一致性快照读,即 MVCC。
但本质上,隔离级别是一种在并发性能和并发产生的副作用间的妥协,通常数据库均倾向于采用 Weak Isolation 。
3、InnoDB MVCC实现原理
InnoDB中MVCC的实现方式为:每一行记录都有两个隐藏列:DB_TRX_ID 、DB_ROLL_PTR(如果没有主键和非空唯一列,则还会多一个隐藏的主键列DB_ROW_ID)。

DB_TRX_ID:创建或最近更新这条记录的事务ID ,大小为 6 个字节。可以理解成创建版本。
DB_ROLL_PTR:回滚指针,指向数据的上一个版本,表示指向该行回滚段(rollback segment)的指针,大小为 7 个字节, InnoDB 便是通过这个指针找到之前版本的数据。该行记录上所有旧版本,在 undo log中通过链表的形式组织。
DB_ROW_ID:行标识(隐藏单调自增ID),大小为6字节,如果表没有主键和非空唯一列, InnoDB 会自动生成一个隐藏主键,因此会出现这个列。另外,每条记录的头信息( record header )里都有一个专门的 bit ( deleted_flag )来表示当前记录是否已经被删除。
3.1、如何组织版本链?
上文提到,在多个事务并发操作某行数据的情况下,不同事务对该行数据的UPDATE 会产生多个版本,然后通过回滚指针组织成一条Undo Log链,这节我们通过一个简单的例子来看一下Undo Log链是如何组织的,DB_TRX_ID 和 DB_ROLL_PTR 两个参数在其中又起到什么样的作用。
还是以上文 MVCC 的例子,事务 A 对值 x 进行更新之后,该行即产生一个新版本和旧版本。假设之前插入该行的事务 ID 为 100 ,事务 A 的 ID 为 200,该行的隐藏主键为 1 。

事务 A 的操作过程为:
1.对 DB_ROW_ID = 1 的这行记录加排他锁;
2.把该行原本的值拷贝到undo log中,DB_TRX_ID和DB_ROLL_PTR都不修改;
3.将x的值从10修改成20,这时产生一个新版本,更新DB_TRX_ID为修改记录的事务ID ,将DB_ROLL_PTR指向刚刚拷贝到undo log链中的旧版本记录,这样就能通过DB_ROLL_PTR找到这条记录的历史版本。如果对同一行记录执行连续的UPDATE ,undo log会组成一个链表,遍历这个链表可以看到这条记录的变迁。
4.记录redo log,包括undo log中的修改。
那么INSERT和DELETE会怎么做呢?其实相比UPDATE这二者很简单,INSERT会产生一条新纪录,它的DB_TRX_ID为当前插入记录的事务ID; DELETE某条记录时可看成是一种特殊的UPDATE ,其实是软删,真正执行删除操作会在commit时,DB_TRX_ID则记录下删除该记录的事务ID 。
3.2、如何实现一致性读-ReadView
在RU隔离级别下,可以读取其他事务未提交的脏数据,无法使用MVCC,因为MVCC中的DB_TRX_ID和DB_ROLL_PTR只有在事务提交后才会产生,直接读取版本的最新记录就OK。对于SERIALIZABLE隔离级别,则是通过加锁互斥来访问数据,因此不需要MVCC 的帮助。因此MVCC运行在RC和RR这两个隔离级别下,当InnoDB隔离级别设置为二者其一时,在SELECT数据时就会用到版本链。
核心问题是版本链中哪些版本对当前事务可见?InnoDB为了解决这个问题,设计了ReadView (可读视图)的概念。
事务进行第一次快照读操作时根据当前系统中所有活跃事务生成ReadView,ReadView中包括三个字段,trx_list、up_limit_id和low_limit_id,trx_list表示生成ReadView时当前系统的活跃事务id列表,up_limit_id表示活跃列表中最小的事务id值,low_limit_id表示系统尚未分配的下一个事务id值(系统为事务分配的事务id值是递增的)。
如何判断当前事务能否查询到DB_TRX_ID事务修改并提交的数据记录?通过可见性算法判断,可见性算法如下所示。
可见性算法:
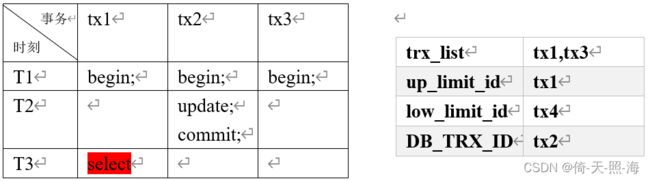
1、首先比较DB_TRX_ID 2、判断DB_TRX_ID>=low_limit_id,如果大于等于,则表示DB_TRX_ID事务提交的记录在ReadView生成后才出现的,那么对于当前事务肯定不可见,如果小于,则进入下一个判断;(此处说法不严谨,看第4点补充说明部分) 3、判断DB_TRX_ID是否在活跃事务中,如果在,则表示在ReadView生成时这个事务还是活跃状态,还没有commit,等到DB_TRX_ID事务修改数据并commit之后,ReadView中是不包括修改后的数据的,所以当前事务是看不到DB_TRX_ID事务修改的数据的。如果不在,则说明DB_TRX_ID事务在ReadView生成之前就已经commit了,那么当前事务就能看到DB_TRX_ID事务修改的结果。 4、补充说明:如果DB_TRX_ID>=low_limit_id,且事务DB_TRX_ID已提交,说明是在事务DB_TRX_ID提交之后当前事务才执行快照读生成的ReadView,则当前事务可以读取到事务DB_TRX_ID修改后提交的数据记录。如果事务DB_TRX_ID未提交,说明当前事务在执行快照读生成ReadView时还没有事务DB_TRX_ID,则当前事务肯定不能读取到事务DB_TRX_ID提交的数据记录。 一句话总结:若要判断当前事务tx1是否可以读取其他事务tx2更新并提交的数据,主要是判断当前事务tx1在第一次执行快照读时,更新数据的事务tx2是否仍是活跃事务,如果不是活跃事务,说明当前事务tx1执行快照读时,事务tx2已经提交,则当前事务可以读取到事务tx2更新并提交的数据。如果是活跃事务,说明当前事务执行快照读时,事务tx2还未提交,则当前事务不能读取到事务tx2更新并提交的数据。 举例说明: (1)只有当事务进行快照读操作时才会根据当前系统中所有活跃事务生成ReadView,快照读就是普通的select查询,读取历史数据。所以事务tx1在T3时刻产生快照读时会生成ReadView。ReadView中包括三个字段,trx_list、up_limit_id和low_limit_id,trx_list表示生成ReadView时当前系统的活跃事务id列表,此处包括tx1和tx3,即[tx1,tx3],up_limit_id表示活跃列表中最小的事务id值,此处是tx1,low_limit_id表示系统尚未分配的下一个事务id值,由于此处trx_list中最大事务id是tx3,所以下一个未分配事务id是tx4。DB_TRX_ID表示新增或最后修改这个记录的事务id,此处事务tx2在时刻T2处修改了数据并提交,所以DB_TRX_ID是tx2。根据上面ReadView的可见性算法,可以判断事务tx1在T3时刻能够查询到事务tx2在时刻T2所做的修改。 (2)假设上例中没有事务tx3,其他情况与上例保持一致,那么事务tx1在T3时刻进行快照读时生成的ReadView中活跃事务id列表就是[tx1],此时事务tx2>tx1,根据上面ReadView的可见性算法,事务tx1应该不能读取事务tx2在T2时刻修改并提交的数据,但实际却能读取到。这就与ReadView的可见性算法存在矛盾了,所以ReadView的可见性还需要补充一点,那就是从第一个快照读生成ReadView开始,任何已经提交过的事务的修改均可见。 (3)由于trx_list是活跃事务id列表,此处tx1是最小事务id,上一个已经提交的事务id肯定比tx1小,故此处假设是tx0,所以此处DB_TRX_ID取值为tx0。在RR隔离级别中,当前事务只有在第一次进行快照读时才会生成ReadView,之后进行快照读不会生成新的ReadView,只会使用之前生成的ReadView,所以事务tx1在T4时刻进行快照读时依然使用T2时刻生成的ReadView。所以在T4时刻,ReadView中trx_list依然是tx1,tx2,tx3,up_limit_id依然是tx1,low_limit_id依然是tx4。但是DB_TRX_ID并不是ReadView中的字段,在T4时刻DB_TRX_ID的值变成了tx2。根据ReadView的可见性算法可知,事务tx1在T4时刻不能查询到事务tx2在T3时刻提交的修改记录。 幻读问题产生的本质原因是多次查询数据时同时使用了快照读和当前读,如果事务中只使用快照读,是不会产生幻读问题的。 例如:事务tx1第一次使用快照读(select * from t where name=’aaa’)查询数据之后,事务tx2新增一条记录(insert into t values(2,’aaa’);),并commit之后,根据ReadView的可见性可知,事务tx1再次使用快照读查询数据是不会查到事务tx2新增的记录的。但是如果事务tx1使用当前读(insert、update、delete、select … lock in share mode、select … for update都是当前读),如select * from t where name=’aaa’ for update,则事务tx1是可以看到事务tx2新增的记录的。 如下图所示,事务1如果一直是快照读,就不会出现幻读,在事务2插入数据前后,事务1读取的结果是一样的。如果事务1先用快照读,再用当前读,就会出现幻读,读取到事务2新插入的一条数据记录。 3.2.1、RR下ReadView的生成 在RR隔离级别下,每个事务touch first read时(本质上就是执行第一个 SELECT语句时,后续所有的SELECT都是复用这个ReadView,其它update、delete、insert语句与这个一致性读snapshot的建立没有关系),会将当前系统中所有活跃事务(是指还未结束的事务,即还未提交或回滚的事务)拷贝到一个列表生成ReadView,ReadView中保存的是所有活跃事务id,形成一个列表。 下图中事务A第一条SELECT语句在事务B更新数据前,因此生成的ReadView在事务A过程中不发生变化,即使事务B在事务A之前提交,但是事务A第二条查询语句依旧无法读到事务B的修改。 两阶段提交涉及到两个日志文件:redo log和binlog。 redo log和binlog这两种日志有以下三点不同: 1、 redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。binlog用于主从同步、恢复数据(误删除)和扩容等。 2、 redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。 3、redo log文件大小是固定的,当文件被写满之后,会回到文件开头循环写,覆盖原来的日志,在覆盖之前会把redo log中的数据保存到数据文件中;binlog 是可以追加写入的,“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。 redo log用到了MySQL中经常说的WAL技术,WAL的全称是Write- Ahead Logging,它的关键点就是先写日志,再写磁盘。当有一条记录需要更新时,InnoDB引擎就会先更新内存,同时把记录写到redo log里,这个时候更新就完成了。等到合适的时候,存储引擎再将数据更新到磁盘文件。因为如果每一次的更新操作都需要将数据写进磁盘,就需要先在磁盘中找到对应的那条记录,然后再更新,整个过程IO成本、查找成本都很高。将更新记录写到redo log文件中是顺序读写,直接在redo log中追加即可,而将数据写到数据文件中是随机读写,需要先找到数据在文件中的位置,然后再修改数据,IO的速度必然很慢。 两阶段提交: 假如执行下面这条更新语句,看一下两阶段提交的具体流程。 update t_test set age = age +1 where id = 1 1、执行器先调用存储引擎接口查找id=1的这一行数据记录,如果这一行的数据页在内存中,就直接返回给执行器,否则就需要从磁盘读取后再返回。 2、执行器拿到存储引擎提供的数据,给age字段加1,比如原来是9,现在就是10,得到新的一行数据,再调用存储引擎接口写入这行数据。 3、存储引擎将新的数据行更新到内存中,同时将这个更新操作记录到redo log,并将redo log中该行记录的状态设置为prepare状态,然后告知执行器执行完成了,随时可以提交事务。 4、执行器生成这个操作的binlog,并把binlog写入磁盘。 5、执行器调用存储引擎接口,提交事务,存储引擎把redo log中刚刚更新记录的状态改成commit状态,更新完成。 最后三步比较绕,将redo log的写入拆成了两个步骤prepare和commit,这就是两阶段提交。 为什么要使用两阶段提交?如果不使用两阶段提交,会存在什么问题呢? 因为有redo log和binlog两个日志文件,要保证两个日志文件的一致性。如果不使用两阶段提交,会存在redo log和binlog日志不一致的问题。 1、假设先写入redo log,后写入binlog, 在写入redo log之后出现了系统故障。重启数据库服务之后,innodb存储引擎根据redo log恢复数据,这时数据库中的数据是正常的。如果存在从库,从库需要根据主库的binlog日志同步数据,这时从库与主库的数据就会不一致。 2、假设先写入binlog,后写入redo log,在写入binlog之后出现了系统故障。重启数据库服务之后,innodb存储引擎根据redo log恢复数据,这时数据库中的数据还是更新之前的数据。如果存在从库,从库需要根据主库的binlog日志同步数据,这时从库中是更新之后的数据,依然会存在主从数据库中数据不一致的问题。 在做故障恢复(crash recovery)时,有以下三种情况: 1、binlog有记录,redolog状态commit:正常完成的事务,不需要恢复; 2、binlog有记录,redolog状态prepare:在binlog写完之后且提交事务之前出现的故障,恢复操作:提交事务。(因为之前没有提交) 3、binlog无记录,redolog状态prepare:在binlog写完之前出现的故障,恢复操作:回滚事务(因为故障发生时并没有成功写入数据库)。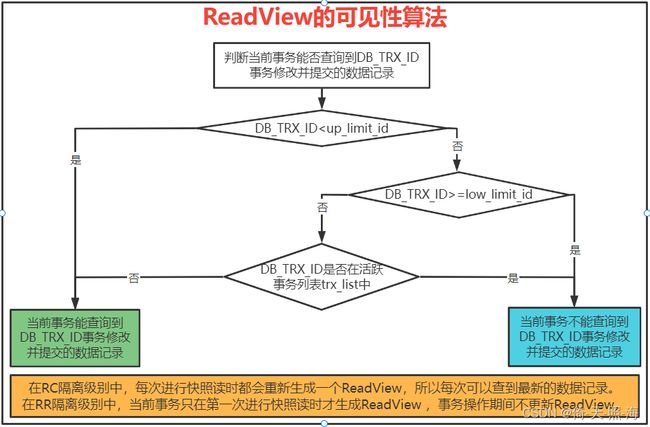

五、mysql两阶段提交
