Android/Linux Kernel 内存管理-入门笔记
Android/Linux Kernel上下層的記憶體管理機制,由於牽涉到基礎,核心與使用者空間的Framework,這系列的文章會分為幾個單元,依據筆者自己的時間安排,逐一分享出來,並希望對各位有所助益.
相對於整理Kernel 排程,FileSystem,與相關核心模組的知識,重新再去彙整Kernel記憶體機制的Topics,會發現表現上看似簡單的Malloc/Free,背後的諸多細節都有他不簡單的道理. 同時,所需供應的記憶體對象,還包括User-Space/Kernel-Space的應用需求,但考量到安全,記憶體的節省與效率,背後就會衍生出諸多設計去改善這些路徑,要能清楚的掌握,還須用功紮根才是. 雖然撰寫過程中盡可能確保資訊的完整與正確性,若仍有所不足還請見諒.
本文會以Linux Kernel 3.5.4為參考Source Code,目前Kernel已經演進到3.6.1 (http://www.kernel.org/pub/linux/kernel/v3.0/linux-3.6.1.tar.bz2),Kernel Memory也有一些改善,後續的討論也會轉到3.6核心上,若各位手中的Kernel邏輯與筆者所參照有落差,請以自己手中所使用的Linux Kernel版本Source Code為主.
在軟體的世界,處理器需要記憶體上儲存的指令集與資料來運算開發者所設計好的邏輯,從一個Task的產生,就會涉及 Data/Code Segment Memory Mapping,Stack與Heap的Memory Allocation. 在non-MMU的世界,包括作業系統與應用程式都直接面對實體記憶體,在這階段的記憶體管理,由於保護機制的缺乏,一旦發生Corruption,要有效收斂的難度也相對較高. 但在有MMU的作業系統上,User與Kernel 世界的記憶體可以被切開,而User-Space Cross-Process之間的空間也彼此獨立,若有一個Process有設計上的缺陷,通常都可以控制在該Process運算空間內觸發問題,而針對該流程進行收斂. 若各位也走過non-MMU Real-Time OS到目前功能完備的Linux Kernel這段路,因此也會有所體會的.
參考Linux Kernel文件 “Documentation/memory.txt”,有如下對記憶體的簡述
“There are some motherboards that will not cache above a certain quantity of memory. If you have one of these motherboards, your system will be SLOWER, not faster as you add more memory. Consider exchanging your motherboard.”
筆者用自己的理解來複述,也就是 “不論所使用的處理器多麼的強大,若不能給予Linux Kernel足夠的記憶體資源去調度使用,那系統效率也不會好,請考慮升級你的硬體” .
每一個產品開發流程,都會被要求要做記憶體的Cost-Down,因此就有相關記憶體節省或壓榨的技術產生,Linux Kernel 要運作的有效率,包括Buddy System,Per-CPU Page List, Buffer/Cache,到User-Space Mermoy Mapping,File-Mapping..等,若因為記憶體受限,上述機制就會無法被最有效的利用,當然也因此會導致效能上的損耗,有關Memory/Performance 間C/P值的權衡,還是有賴不同產品的設計需求.
簡單卻又不簡單的機制
筆者舉最常見的動態函式庫Mapping最為例子,Linux Kernel為了節省實體記憶體的配置數量,雖然應用程式認知上已經載入該.SO動態函式庫,且該函式庫也已經MMAP到記憶體中,但實際上只有這塊Memory Mapping的範圍被設定好,並沒有真的佔據實體的記憶體空間,等到使用者參考該區域資料產生Data-Abort(觸發Kernel函式do_DataAbort in arch/arm/mm/fault.c)或是去執行該區域的程式碼產生Prefetch-Abort(觸發Kernel函式do_PrefetchAbort in arch/arm/mm/fault.c ),Kernel才會真的把資料讀出載入到對應的Memory Page上.
在機制上,雖然應用程式載入一個動態函式庫,但執行期間並不會需要完整的動態函式庫.SO檔案,會依據動態需求,使用不同動態函式庫.SO檔案的各部分內容.因此,透過這樣的機制可省去要把整個.SO與檔案讀取到記憶體的成本,讓應用程式的載入效率提高,節省記憶體成本,以便容納更多應用程式同時運作的需求.
整體運作概念可參考如下圖所示,應用程式載入動態函式庫後,若執行或參考到尚未被更新到記憶體中的內容,就會觸發Data-Abort/Prefetch-Abort,再透過Kernel機制從外部Storage把對應的資料讀取到記憶體中,並恢復原本觸發這機制的應用程式執行.對應用程式本身,並不會察覺到剛才所使用到的Memory 內容是因為觸發了這段流程才能得以進行,對Kernel而言也藉此機制,可更有彈性去調配記憶體給User-Space的應用程式使用.
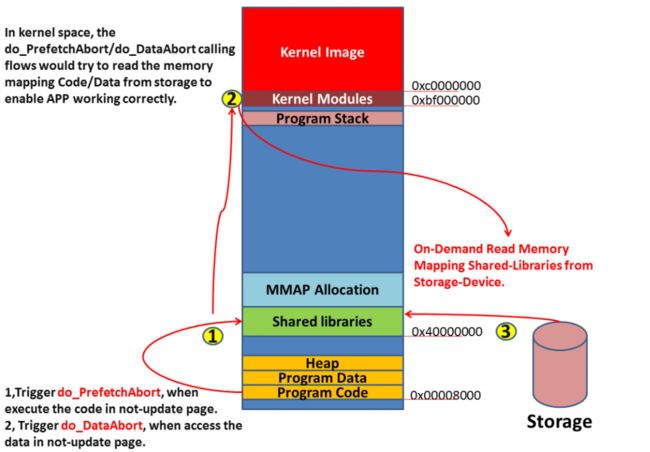
也就是說,一個簡單的應用程式與動態函式庫的執行流程,其實背後卻有如上述流程不簡單的機制輔助著,接下來我們從Memory Node/Zone的概念,來入門Linux Kernel Memory.
Memory Node, Zone
有關Linux Kernel Memory Node與Zone彼此關係可參考如下圖所示,在支援NUMA(Non-Uniform Memory Access)的環境下, Kernel Memory可管理一個以上的Memory Node,而每個Memory Node都是一個獨立的Memory節點,具備像是DMA Zone,Low Memory Zone與High Memory Zone,當目前Process所運作的Memory Node所對應的Memory Zone記憶體不足時,可以根據當下Memory Node System Control設定,選擇是要到其它Memory Node的同類型Memory Zone配置記憶體,還是要在自己Local Memory Node上的其它Memory Zone配置記憶體. 當然,如果是後者選擇在同一個Memory Node上配置記憶體,對Local處理器與記憶體存取效率來說會是比較高的.]

有關Linux Memory Node的定義可以參考 nodemask_t node_states 的宣告 (in include/linux/nodemask.h),其中包括了根據當下支援Memory Node最大值MAX_NUMNODES產生的BitMap,與在這BitMap上所對應的Node狀態,包括
1,N_POSSIBLE,用以表示這個Memory Node是否可以被Online
2,N_ONLINE,用以表示這個Memory Node是否已經Onlne
3,N_NORMAL_MEMORY,用以表示這個Memory Node是否具有Normal Memory Zone
4,N_HIGH_MEMORY,用以表示這個Memory Node是否具有High Memory (若當下Kernel組態不支援High Memory,則此值會等於N_NORMAL_MEMORY)
5,N_CPU,用以表示這個Memory Node是否具備CPU (用以決定是否以Local Processor進行 Zone Reclaim)
根據所在系統差異, 像是在原本x86環境會提供ISA DMA的DMA Zone (for 24bits, 16MB Memory Range),但在x86-64的64bits環境下,除了原本的DMA Zone外,還會提供DMA32 Zone以供DMA 32bits 4GB記憶體範圍的使用.
| Node 0, zone DMA Node 0, zone DMA32 Node 0, zone Normal |
相對於x86的I/O Space差異,在ARM處理器上則無DMA Zone.配置
| Node 0, zone Normal Node 0, zone HighMem |
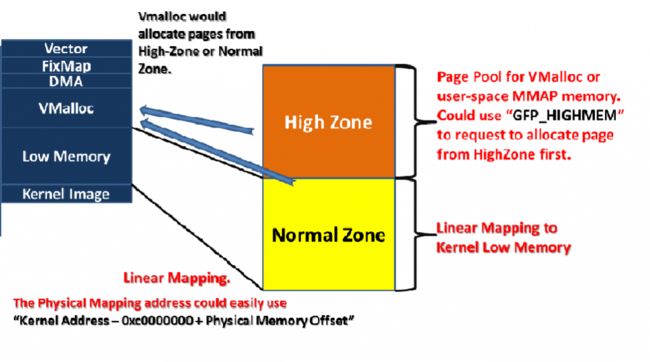
另一個差異會是,由於32bits處理器所分配的4GB空間通常會是1GB Kernel Space+ 3GB User Space或 2GB Kernel Space + 2GB User Space,若使用者所安裝的記憶體超過1GB,在1GB Kernel Space組態,由於這塊記憶體範圍還包括Kernel Image,vmalloc range,vector,fixmap, iotable mapping, 以致於Kernel會無法Linear Mapping去存取完整的實體記憶體空間,為了讓記憶體的使用有彈性,Linux Kernel 在32bits環境支援了High Memory Zone (目前筆者已知64bits並無需High-Memory),用以去管理在Linux Kernel Linear Mapping Normal Zone上所看不到的記憶體範圍.
所有Kernel核心物件都還是會從Normal Zone (Low Memory Zone)去進行配置,但像是vmalloc 或 User-Space的記憶體配置,就會盡可能從High Memory Zone配置,以達到記憶體使用最佳化. 接下來,就從Buddy System開始講起.
Buddy System
Buddy System主要Source Code是在 “mm/page_alloc.c”,有興趣的開發者可以自行參閱. 在總體Physical Memory扣掉Hardware Reserved與Kernel Image本身使用的記憶體空間後,依據Memory Zone的分配,每個Zone範圍內的實體記憶體也就是Kernel Buddy System所管理的範圍.
如下圖所示, Buddy System會以4kbytes為Page單位細分所管理的記憶體空間,並會根據Memory Zone分配,每個Zone都會有其所對應的Buddy System機制. 而Kernel Image所佔用的記憶體空間會被分配到屬於Normal Zone (也就是 Low Memory)所在區域.

Kernel記憶體管理最殘酷的部份就是在Kernel啟動後一段時間,Physical Memory Fragmentation會讓大塊實體連續的記憶體越來越不容易存在. 如下圖所示,Buddy System會以4kbytes為基礎並以Order 0到Order 10 (也就是有2^0=1 到 2^10=1024個連續Page)為管理的單位進行Free Space的管理工作,並確保在執行過程中,儘可能的讓Page 有被Merge的機會,以便能大塊連續Page有機會產生.
對32-bits系統來說,啟動後的Buddy System記憶體分配範例如下
| [root@localhost /]# cat /proc/buddyinfo Node 0, zone DMA 3 4 5 4 3 3 3 1 2 1 0 Node 0, zone Normal 1805 662 318 70 23 17 8 4 3 3 3 Node 0, zone HighMem 68 97 11 14 1 0 0 0 0 0 0 [root@localhost /]# |
對64-bits系統來說,啟動後的Buddy System記憶體分配範例如下
| [root@ localhost /]# cat /proc/buddyinfo Node 0, zone DMA 2 0 1 2 1 1 0 0 1 1 3 Node 0, zone DMA32 2193 2235 1970 1255 463 109 27 2 0 0 0 Node 0, zone Normal 880 1786 1133 592 255 69 20 8 0 0 0 [root@ localhost /]# |
另外,值得提醒的一點就是,Page Order跟Memory Alignment兩者是有正相關的,也就是說一個Page Order 0的Page起點記憶體位址就一定是跟4096bytes Memory Alignment對齊,如果是一個Page Order 4的Page (=16個4kbytes Pages),也就是連續64kbytes的實體記憶體空間,起點記憶體位址就一定是跟64kbytes Memory Alignment對齊,如果今天有一個Parder Order 4的Page起點記憶體位址並沒有對齊64kbytes Memory Alignment,也就表示這個傳遞進來的Page可能有錯誤發生.
Linux Kernel的文件對Buddy System設計有如下描述, “Buddy System的設計為提供direct-mapped table並以2^Order進行Memory Block Page配置,其中最小為4096bytes Page的記憶體配置. 每一個Level都會提供2^Order的Pages連續記憶體空間.每當配置或釋放一個Page空間時,都會跟其它的Buddies有所關係,例如要配置一個小Block,就有可能會把一個比較大的Block分拆成小區塊,以供這次配置所需,其它依據大小再拆解成對應2^Order 的Pages小區塊.若要釋放一個Block,並且它旁邊的Buddy空間也處於Free的狀態,此時兩者就可以整合成一個比較大的區塊,並把這區塊往上升級一個2^Order Page Block”.
如下圖所示,當要釋放一個Memory Page時,Buddy System會嘗試確認該Page左右兩邊是否為Free,若是就進行Merge,並往上一層Order邁進,以這例子來說,正好釋放一個Order 0的Page,同時左邊Order 0 Page也處於Free狀態,兩者Merge 後,旁邊Order 1的Page也正好處於Free狀態,因此可再進一步Merge成Order 2的Page,若正好Order 2的Page右邊的Page也處於Free狀態,就可以再次往上一個Order Merge,以便創造出足夠大塊的2^Order Free Page.
再舉另一個Allocate記憶體的例子,如果要配置一個Order 0的Page,但此時恰好系統中只剩下Order 3的Page,系統會把這Order 3的Page進行如下的Split動作,分出一個Order 0 Page供使用者配置使用,並把這Order 3剩下的Page,依序再分配給Order 2,1,0的Free List空間,以供其它Page Allocation需求.
有關Buddy System的概念,大致簡述如上,後續將針對Buddy System初始化與程式碼,作一個簡要的說明,希望對於Trace Source Code的開發者而言可以有所助益.
Buddy System 初始化
Buddy System的初始化,會分為兩個階段,
第一階段,會執行如下流程,把指定Memory Node的Memory Zone Buddy System初始化,但在這階段每一個對應2^Order的Free Area Link-List都為空,且nr_free為0,還尚未有Free Page可供配置使用.
第二階段,才會把Boot Memory Free出來,並放到對應Buddy System Page Order Link-List中,此時系統才能真的提供Page Allocation的服務.
有關第一階段的程式流程如下簡述
1, 從start_kernel 透過setup_arch,進入函式arm_bootmem_free(in arch/arm/mm/init.c)
2, 呼叫 free_area_init_node (in mm/page_alloc.c) 以便針對Memory Node 0進行初始化.
3, 呼叫 free_area_init_core (in mm/page_alloc.c) 初始化Memory Node上的每一個Memory Zone,
4, 呼叫 init_currently_empty_zone (in mm/page_alloc.c),並帶入Zone Start PFN與Size,以便初始化這個Memory Zone的Buddy System
5, 呼叫 zone_init_free_lists (in mm/page_alloc.c),透過for_each_migratetype_order初始化Order 0-10 的Zone Free Area與每個Zone Free Area下的Free List Type(包括 MIGRATE_UNMOVABLE,MIGRATE_RECLAIMABLE,MIGRATE_MOVABLE,MIGRATE_ISOLATE..etc)並設定Order 0-10 的 Zone Free Area 初始nr_free為0,至此Buddy System已初始化完畢,但還尚未有Free Page可供Page Allocation使用.
整體概念如下圖所示,屬於Memory Node 0上的Memory Zone Boddy System的 Free Area Order 0-10 所串連的Page Link-List與相關Migration Type都在這階段初始化完畢.
如下圖所示,在start_kernel 透過setup_arch,呼叫arm_bootmem_free到init_currely_empty_zone-> zone_init_free_lists初始化Zone後, 會回到start_kernel函式繼續往下執行,之後進入函式mem_init,並往後執行free_all_bootmem,會把開機過程中所使用的Boot Memory進行釋放,回到Buddy System中.
在走完mem_init之後,Buddy System內對應的Page Order Link-List與nr_free就能反應當下Page Order實際Free Page狀況,並進行Allocate Page.
提到Buddy System概念與初始化後,再來會舉實際配置與釋放的例子,作簡要說明
Buddy System Memory Allocation and Free
如下,筆者以基於Slub的Kernel Memory 配置流程加以說明,其中有關kmem_cache_alloc_trace,trace_kmalloc的Trace機制,在本文中將不涉及.
筆者以函式__get_free_pages (in mm/page_alloc.c)為例,這是一個在Kernel Space用以配置Normal Memory的機制,並回傳已Mapping到虛擬記憶體空間的Address. 函式__get_free_pages在Kernel中使用廣泛,像是 ARM Page Table 的第一層 16kbytes,就會透過 pgd_alloc->__pgd_alloc 執行 __get_free_pages(GFP_KERNEL, 2),透過 Buddy System 挖取一個Page Order 2,也就是4*4kbytes = 16kbytes的第一層Page Table.
如下所述為__get_free_pages (in mm/page_alloc.c)的運作流程
1,若判斷 gfp_mask & __GFP_HIGHMEM 為真,則觸發 VM_BUG_ON
(__get_free_pages 只用來配置 Linear Mapping的記憶體區塊,並透過page_address返回取得Page對應的Kernel Memory Virtual Address)
2,呼叫alloc_pages執行函式alloc_pages_node (in include/linux/gfp.h),透過Buddy System挖取對應Order大小的Pages
2-1,若 Memory Node ID<0,則呼叫 numa_node_id取得目前的Memory Node ID
2-2,呼叫__alloc_pages (in include/linux/gfp.h)
2-2-1,呼叫__alloc_pages_nodemask (in mm/page_alloc.c)
2-2-1-1,確認透過node_zonelist(Memory_Node_ID, gfp_mask)所取得的Zone List->_zonerefs->zone是否包括有效的Memory Zone符合在對應Memory Node上的Memory GFP Mask,若在所使用的Memory Node上無法找到符合Memory GFP Mask有效的Memory Zone則會返回NULL表示Allocate Page操作失敗.
2-2-1-2, 呼叫first_zones_zonelist, 取得第一個Zone,或在許可的Memory Node上 zonelist中 highest_zoneidx的下一個Zone.
2-2-1-2-1, 呼叫next_zones_zonelist,取得下一個Zone,或在zonelist中 highest_zoneidx的下一個Zone.
2-2-1-3, 若無法透過first_zones_zonelist取得有效的Memory Zone (可能在同一個Memory Node或不同的Memory Node上的有效Memory Zone),則執行goto out,若此時其它Race Condition下的Thread也更新狀態,讓原本Failed準備要goto out的Page Allocation機制有機會成功,就會執行goto retry_cpuset,嘗試讓Page Allocation成功.
2-2-1-4, 呼叫get_page_from_freelist並帶入上一步選中的preferred_zone,
2-2-1-4-1,透過for_each_zone_zonelist_nodemask,基於cpuset_zone_allowed選擇一個有足夠Free Pages的Memory Zone
2-2-1-4-2,若Memory Zone內的File Dirty PageCache,NFS Unstable Pages,或Writeback Pages總數超過zone_dirty_limit,表示該Memory Zone已經滿了.
2-2-1-4-3,若alloc_flags & ALLOC_NO_WATERMARKS不成立,則進入 2-2-1-4-3-1
2-2-1-4-3-1,若Zone內的Free空間滿足Watermark水位的要求,則直接進入try_this_zone,呼叫函式buffered_rmqueue從對應的Memory Zone上取得Page.
2-2-1-4-3-2,反之就會進入zone_reclaim流程,直到確定Zone內的Free空間滿足Watermark水位的要求
2-2-1-4-4,若alloc_flags & ALLOC_NO_WATERMARKS成立, 則直接進入try_this_zone,呼叫函式buffered_rmqueue從對應的Memory Zone上取得Page.
2-2-1-4-4-1,呼叫buffered_rmqueue,在函式buffered_rmqueue中,如果要配置的記憶體是Order=0,會先嘗試從Per-CPU Page List快取中取得Page,並會關閉中斷,避免像是Drain All Pages的流程觸發IPI中斷回收Per-CPU Page List快取,導致兩者行為交互上的錯誤.若此時,Per-CPU Page List為空,則透過rmqueue_bulk往Buddy System挖Page,反之就從 Per-CPU Page List快取取得Page.若Order>0,就直接從Buddy System挖.
2-2-1-5, 呼叫__alloc_pages_slowpath, 由於嘗試直接配置記憶體失敗,進入到__alloc_pages_slowpath慢速的路徑後,會嘗試喚醒kswapd Kernel Thread進行記憶體回收,在進行相關Reclaim流程時,會再嘗試透過get_page_from_freelist進行配置,若允許ALLOC_NO_WATERMARKS的配置方式,則在此會透過__alloc_pages_high_priority再嘗試一次.如果Process Flag中TIF_MEMDIE成立,表示該Process正在被結束中,若是則直接結束Slow Path記憶體配置.若上述流程都還是配置不到記憶體,則會根據條件依序進行 __alloc_pages_direct_compact,__alloc_pages_direct_reclaim 與最後一關搭配OOM(Out-Of-Memory) Killer 的__alloc_pages_may_oom,強制系統透過砍Process釋出足夠的記憶體空間.最後會根據條件,判斷是否要再 goto rebalance,重複上述流程. (繼續努力讓系統可以擠出記憶體)
3,呼叫page_address,執行lowmem_page_address 傳回 Linear Mapping Address.
在以函式__get_free_pages簡述Page Allocation的例子後,筆者以 __free_one_page(in mm/page_alloc.c)說明Page釋放回到Buddy System的流程.
1,透過PageCompound判斷是否為連續Page的一部分,若是,則呼叫destroy_compound_page,確認是否能夠被Free (若返回bad值>0就直接結束Free Page流程)
2,取得Page Frame Number,確認該Page是否在Buddy System同一Order中的第一個Page,如果不是就會觸發VM_BUG_ON,
| 舉例來說,要觸發一個Order=4的Page,而傳入Page的PFN=4096,系統支援的最大MAX_ORDER=11,因此 page_idx = page_to_pfn(page) & ((1 << MAX_ORDER) – 1) = 4096 & ((1 << 11)-1) = 4096 & 0x7FF = 0×00 再把page_idx跟當下傳入Page Order作如下計算 (page_idx & ((1 << order) – 1) 如果結果為0,表示傳入的Page Frame Number是在 Order 4 = 16 的倍數,以就是合法的PFN. 如果不為0,就表示傳入的PFN是在Order 4 這16個Page連續記憶體的中間 (也就是說不是Order 4的第一個Page.) .那就表示這個Page是無效Page,就會觸發 VM_BUG_ON |
3,呼叫bad_range,確認Page是在Memory Zone內的有效範圍
4,進行釋放Page流程,並確認當前釋放的Page,是否可以跟前後的Buddy Page整合為一個更大的Page (需符合 Buddy System對Order的要求),若能就整合,反之就結束合併Buddy Page的流程
5,呼叫 set_page_order 設定Page Order ((page)->private=Order and __SetPageBuddy)
6,透過page_is_buddy查核目前Page的Buddy Page的下個Page是否為Free,Buddy 並有更高一階有的 Order, 若是就透過list_add_tail把目前的Page放在zone->free_area[order].free_list[migratetype]的後面,以便當中間使用中的Page被釋放時,兩個Free Buddy可以合併成一個更大的Buddy,再跟原本就已經Free的高一階Buddy整合, 成一個更大的Buddy.
7,若6不成立,就透過list_add把這個Page放到 zone->free_area[order].free_list[migratetype]的前面,根據目前free_list的操作,放在越前面的Page會被越快用到. (除非有第6點企圖要整合成一個更更高一階Order的目的,不然就還是會固定放在Link-List的頭端)
上述有關Free Page確認下一個Buddy Page是否為Free,並把目前要 Free的Page放到對應Link-List尾端,等待中間還在被使用的Order =1 (=2 Pages)被釋放後,就機會更快讓系統得到連續的Order=3 Page概念,筆者圖示如下
Per-CPU PageList機制
User/Kernel Space應用程式的運作中,Order 0 Page是所有需求中數量最多,Allocation/Free最頻繁的Order,主要原因在於包括User-Space Malloc/Free 或Kernel Space的vmalloc,都會是以 Order 0 Page透過虛擬記憶體的操作提供連續的虛擬記憶體空間. 也因為如此,如果每次都要頻繁的去Buddy System進行Order 0 Page的Merge/Split,無形中也成為一個Bottleneck,若能有效的降低Order 0 Page大量操作下的成本,對系統效能將有顯著的改善.
Kernel目前支援Per-CPU PageList的機制,用以在直接去Buddy System找 Order 0 Page前,可以有一個快取機制,能直接供應Order 0 Page操作,作為改善的機制. Per-CPU PageList對應的結構為 "struct per_cpu_pages *" ,如下所示
| struct per_cpu_pages { int count; => 表示目前在Per-CPU PageList中的Order 0 Page個數. int high; =>作為Per-CPU PageList的high watermark,當在List中儲存的Page個數超過這值時,就會呼叫函式free_pcppages_bulk,並參考batch數值,將Order 0 Page還回給系統. int batch; =>可用以指定每次還Order 0 Page給系統時,透過free_pcppages_bulk所要釋放的Page個數. 或當發現Per-CPU PageList中為空時,也會透過rmqueue_bulk搭配這個batch數值,用以配置基本數量的Order 0 Page給Per-CPU PageList,以達到快取的目的. 由此可知batch值的定義,對於Buddy System 快取的改善是有很重要的角色. struct list_head lists[MIGRATE_PCPTYPES]; =>用以儲存Per-CPU PageList對應不同Page Migration Type的Link List Array.目前支援三種 Type,Migration Movable/Unmovable與Reclaimable }; |
在多核心的環境下,drain_all_pages (in mm/page_alloc.c)是很常被呼叫到的Kernel Memory Management機制,例如在__alloc_pages_direct_reclaim或alloc_contig_range,這些配置記憶體的操作上,若有遇到記憶體不足時,就會透過drain_all_pages,呼叫on_each_cpu_mask,透過SMP IPI觸發中斷讓每個處理器執行drain_local_pages,並呼叫函式drain_pages(in mm/page_alloc.c),透過free_pcppages_bulk 釋放目前在 Per-CPU PageList 快取的Pages,讓這些Pages可以回到 Buddy System中, 重新被配置使用,
free_hot_cold_page (in mm/page_alloc.c)主要用以釋放Order 0 的Page,並加入到 Per-CPU PageList中,Per-CPU PageList所管理的pcp->lists (in include/linux/mmzone.h),MIGRATE_PCPTYPES 用以表示目前Per-CPU PageList所支援的Page Type總數. (以Linux Kernel 3.5.4而言此值為3),Per-CPU PageList 主要支援以下的Migration Type,
MIGRATE_UNMOVABLE:Page屬性為 Unmovable
MIGRATE_RECLAIMABLE:Page屬性為 Reclaimable
MIGRATE_MOVABLE:Page屬性為 Movable
此外,若 Page屬性為Isolation (=MIGRATE_ISOLATE),就會透過free_one_page直接釋放掉,而不會進到Per-CPU PageList快取中.
1,如果是Cold Page,會呼叫list_add_tail放到Per-CPU PageList "pcp->lists[migratetype]" 的最後面
2,如果是Hot Page,會呼叫list_add 放到Per-CPU PageList "pcp->lists[migratetype]" 的最前面
3,最後並把 Per-CPU PageList Count 加一 "pcp->count++"
4,如果pcp->count大於 Per-CPU PageList的高水位 "pcp->high" (也就是Per CPU PageList中的Page個數太多了), 就會透過free_pcppages_bulk釋放pcp->batch筆數,並修正pcp->count的統計.
在介紹完基本Buddy System的概念與流程後,另一個筆者覺得也很值得介紹的議題就是Kernel Image的Memory Layout,對Kernel Image在記憶體中的Layout與範圍清楚,對於核心問題的解決上,總是可以多了更多的背景輔助知識,用以處理產品化的問題.
Kernel Image的Memory Layout
既然要介紹Kernel Image Layout,筆者希望能以各位也可以取得的環境來做驗證,選擇的Source Code為HTC OneX Linux Kernel 3.0.8 (可自http://htcdev.com 下載),並以 arm-eabi-gcc (GCC 4.4.3) 進行編譯.
這版Kernel Source Code的CONFIG_PAGE_OFFSET設定為0xC0000000,因此Linux Kernel會從0xc0008000開始載入到記憶體 (前面的0xc0004000-0xc0007fff 為啟動過程配置為1MB Section的Page Table).
編譯後的Kernel Image, Section to Segment mapping 會如下所示,
| Segment Sections… 00 .init .data..percpu 01 .text 02 .rodata __bug_table __ksymtab __ksymtab_gpl __kcrctab __kcrctab_gpl __ksymtab_strings __init_rodata __param __modver .ARM.unwind_idx .ARM.unwind_tab 03 .data .notes .bss |
可參考這版Kernel Source Code Linker Script的配置 (in arch/arm/kernel/vmlinux.lds ),在上述Segments之間會加入“. = ALIGN(1<<20);”標示,讓這些Segments在編譯為Kernel Image後,彼此的記憶體間隔會是1MB Memory Alignment.
如下圖所示,是筆者以上述OneX Kernel Image載入到記憶體後的Layout,最前面兩個Section分別為 .init (屬於BSS Data Section),與 .data..percpu (屬於Data Section,用以記錄在 Multi-Processor下的Per CPU Data變數).
再來就是程式碼區塊,由於Kernel 支援像是Tracer或Jump Label這類會修改Linux Kernel Code Segment的機制,也因此不像是一般ELF應用程式會把Code Segment設定為Read-Only,在Linux Kernel中的Code Segment本身會是可以寫入的. 好處當然是有關的Tracer或改善效能的機制可以更有彈性被加入,但缺點就是如果有一個核心模組存在程式碼撰寫上的缺陷,就有機會導致Kernel Code Segment的Corruption,導致不預期的錯誤發生. 在.text section之後為 .rodata (屬於RO Data Section),與 Kernel Symbol/Unwind等有關的Section (屬於RO Data Section). 再來就是可讀可寫的 .data section (屬於Data Section)與 .bss section (屬於BSS Data Section).
但由於.init section 與 .data..percpu section兩者總和並佔不滿1MB的記憶體範圍,在接續到.text section中間會有空間浪費的問題,若不希望造成記憶體的閒置,可以把 Alignment縮小,以筆者的驗證來說,可以改為4kbytes Alignment,例如 “. = ALIGN(1<<12);”,編譯後的Section to Segment mapping 會如下所示,
| Segment Sections… 00 .init .data..percpu .text .rodata __bug_table __ksymtab __ksymtab_gpl __kcrctab __kcrctab_gpl __ksymtab_strings __init_rodata __param __modver .ARM.unwind_idx .ARM.unwind_tab .data .notes .bss |
從.init section 到 .bss section結尾所佔用記憶體的空間,會從原本的0xc0008000 到 0xc0edcddc,變成改為 4kbytes alignment後的0xc0008000 到 0xc0cd4ddc, 若以 .bss section 結尾位置來比較的話,大概相差了 2MB.
在開發階段,如果希望便於除錯或是硬體有支援Memory Protection除錯能力,把Segment範圍對齊硬體Memory Protection的Alignment位址,反而有利於偵測硬體或處理器Memory Corruption的錯誤發生,只要最後產品化階段,把記憶體的Alignment調整回來即可,至於如何權衡還需以當下需求為主.
從Kernel.org 所下載的Linux Kernel, ARM環境原本配置就是 4kbytes Page Alignment, 若無特別除錯需求的考量,是不需要額外修改的.本節是以HTC OneX 使用的Linux Kernel 3.0.8為例.
既然談了Memory Node,Zone,Buddy System與Kernel Image Memory Layout,另一個筆者覺得基礎的主題就是VMalloc 與 High Memory Zone的配置,將在下個段落中加以說明.
VMalloc 大小與VMalloc Guard Zone的關係
假設,使用者的 Kernel command line 設定 vmalloc=546M,此時
vmalloc : 0xdd000000 – 0xff000000 ( 544 MB)
lowmem : 0xc0000000 – 0xdce00000 ( 462 MB)
可以知道vmalloc 起點 0xdd000000距離lowmem終點 0xdce00000 有2MB的Guard Zone.
若是設定 vmalloc=549M,此時
vmalloc : 0xdd000000 – 0xff000000 ( 544 MB)
lowmem : 0xc0000000 – 0xdcb00000 ( 459 MB)
Guard Zone長度變為5MB,VMalloc位址起點還是不變為0xdd000000,但lowmem結尾卻往後退到0xdcb00000.
再更進一步, 設定vmalloc=552M,此時
vmalloc : 0xdd000000 – 0xff000000 ( 544 MB)
lowmem : 0xc0000000 – 0xdc800000 ( 456 MB)
Guard Zone長度變為8MB,VMalloc位址起點還是不變為0xdd000000,但lowmem結尾卻往後退到0xdc800000.
最後,我們設定vmalloc=553M,此時
vmalloc : 0xdc800000 – 0xff000000 ( 552 MB)
lowmem : 0xc0000000 – 0xdc700000 ( 455 MB)
Guard Zone長度變為1MB,VMalloc空間由544MB變成552MB,位址起點變為0xdc800000,而lowmem結尾往後退到0xdc700000.
綜合上述的驗證流程,我們可以看到當設定一個VMalloc大小時,系統會以該VMalloc往下找第一個8MB Alignment的位址最為VMalloc虛擬記憶體空間的起點 (以就是說一定確保VMalloc空間Start起點是8MB Alignment的記憶體位址).
也因此,根據啟動時傳給Kernel Command Line VMalloc值的大小,位於VMalloc與Low Memory中間的Guard Zone可以有1MB-8MB的變化,這只會影響到虛擬空間的改變,當 Guard Zone變大導致Low Memory空間變小,就會讓HighZone空間對等變大,也就是說使用者總體可使用的實體記憶體變沒有減少,只是轉由直接Linear Mapping的Low Memory,變成透過High Zone取得.
談系統High Memory Zone的配置
提到Linux Kernel記憶體管理, Memory Zone觀念是最為基礎的項目,在32bits系統User-Space與Kernel Space必須要能共用這塊4GB的虛擬記憶體空間.通常Kernel-Space跟User-Space的比例可以為1GB vs 3GB或2GB vs 2GB,而一般Android環境下的Linux Kernel若無意外設定通常會是1GB vs 3GB,如下圖所示
如前述包括Kernel Image,vmalloc range,vector,fixmap, iotable mapping,都會導致這1GB Kernel Space記憶體空間的使用加速,結果就是並非所有實體記憶體都有機會被對應到這1GB的記憶體空間來,無法對應到這1GB實體空間的記憶體,就會透過另一個Memory Zone進行配置,也是稱的High-Memory Zone.
一般Linux Kernel根據Kernel Space虛擬記憶體範圍與VMalloc配置的大小,決定系統是否需要存在High-Memory Zone,
但在Kernel 3.4後, VMalloc空間計算有了改變,必須要加入I/O Table Mapping Memory Size合併計算,有關VMalloc空間與I/O Table Mapping合併的歷史,可以參考 3.4.0 的這版Patch, “ARM: move iotable mappings within the vmalloc region” (http://git.kernel.org/?p=linux/kernel/git/stable/linux-stable.git;a=commitdiff;h=0536bdf33faff4d940ac094c77998cfac368cfff),作者Nicolas Pitre撰寫的描述如下
| In order to remove the build time variation between different SOCs with regards to VMALLOC_END, the iotable mappings are now allocated inside the vmalloc region. This allows for VMALLOC_END to be identical across all machines. The value for VMALLOC_END is now set to 0xff000000 which is right where the consistent DMA area starts. To accommodate all static mappings on machines with possible highmem usage,the default vmalloc area size is changed to 240 MB so that VMALLOC_START is no higher than 0xf0000000 by default. |
以ARM Linux來說通常,0xff000000 以上16MB空間為 fixmap與vector, 再來就是 VMalloc, Guard Zone與LowMem.要預估一個系統中是否存在High-Memmory Zone以及該High-Memory Zone的大小,最好的方式就是估出Low Memory Zone大小(含Kernel Image 佔用的Code/Data Size),在跟實際記憶體計算即可.
舉例來說,Linux 裝置上有1024MB的記憶體,扣除Hardware Reserved 64MB後,還剩下960MB實體記憶體. 同時,在這裝置的虛擬記憶體空間1GB Kernel Spae包括VMalloc 配置為300MB與224MB I/O Table Mapping (其中包括4MB Guard Zone),因此Low Memory Zone的空間會有 1024 – 16 (0xff000000以上空間) – 296-4-224=484MB.
再來把實體記憶體1024MB大小減去Hardware Reserved 64MB與減去Low Memory Zone 484MB,就可以得到High-Memory Zone的大小應為1024-64-484=476MB.
所以最後的系統會存在
0,總共1024MB實體記憶體
1, 64MB Hardware Reserved Memory
2, 296MB VMAlloc
3, 4MB VMAlloc Guard Zone
4, 224MB I/O Table Mapping
5,484MB Low-Memory Zone (Normal Zone)
6,476MB High-Memory Zone
在談了相關Kernel Memory設計邏輯後,最後補充說明/proc下的Memory Information與Control機制,供開發者參考.
Proc FileSystem Memory Information
Linux Kernel Memory Management除了前述有關的設計邏輯外,對剛入門的開發者而言,最需要解決的是眾多的名詞與邏輯,其他包括在 /proc目錄下提供的Kernel Memory資訊,或是再 /proc/sys/vm目錄下提供的Kernel Memory控制機制. 筆者在此針對自己認為比較重要與需要理解的部份作一個說明,由於名詞與含義眾多,若非原本就已經很熟悉的開發者,就只要大概知道這些名詞就好,等到真的有需求時,再來翻閱本文或其它各位覺得便利的技術資料即可.
/proc/Buddyinfoè
Kernel的Buddy System會以Page Order為單位去Group所管理與使用的外部實體記憶體,Kernel會以Order 0,1,2,3,4,5,6,7,8,9,10,也就是從 Order 0 一個Page 4096kbytes大小,到Order 10提供約4MB大小的Memory配置,根據每種不同大小的連續記憶體的使用狀況,可把被釋放的記憶體組合為更上一階的Memory Page Oder,或是把連續的記憶體根據需求拆解為所需的Page Order不同大小的記憶體區塊,而這些當下Buddy System對記憶體管理的使用情況,就是BuddyInfo所可以提供的即時記憶體使用資訊,當所要配置的記憶體Page Order正好落在目前Buddy System所無法供應的連續記憶體區塊時,就可能會導致記憶體配置失敗. (會透過 Low Memory Killer 或 OOM (當一個Page配置都失敗時)來強制透過應用程式的刪除執行,配置出足夠大小的連續實體記憶體空間.
如下表所示,解決Kernel 使用外部Physical Memory的Fragmentation一直都是在記憶體管理上非常重要的課題.而BuddyInfo就是可以提供開發者了解目前Linux Kernel Memory Page使用狀況的Proc Filesystem Node,透過BuddyInfo的資訊,我們可以知道當下Kernel Memory Fragmentation的程度,以及知道哪一檔次Order的Memory,在現在記憶體配置時,是會導致失敗的.
| Node | Zone | Order | ||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 0 | DMA | 0 | 8 | 10 | 8 | 8 | 6 | 0 | 0 | 0 | 0 | 0 |
| 0 | Normal | 488 | 144 | 73 | 14 | 7 | v | 2 | 0 | 0 | 0 | 0 |
| 0 | HighMem | 16 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
每一列都表示當下指定Node與Zone中對應Page Order的數量,例如在表中有8個2^1*PAGE_SIZE大小的Zone DMA,或14個2^3*PAGE_SIZE大小的Zone Normal空間.
而另一個關係到Fragmentation可供參考的Proc Node 為 pagetypeinfo,詳細說明可參考如下段所示
/proc/pagetypeinfo è
除了可以看到Buddy System對應不同Page Order的數量外,還可以根據以Migration Type分類的方式,並以連續記憶體範圍來分類Page Blocks,例如假設在這個Zone中有10個Page,其中連續區塊為 3,3 4個Pages區塊,在Pagetypeinfo中,” Free pages count per migrate type at order” 會根據Migration Type以Page個數為單位來作計算總共有10個Pages,但在 “Number of blocks type”統計中,則會依據總共是三個連續區塊的組合,而計算該Migration Type總共有3個Blocks.
基於Migration Type,有關 "Movable" 與 ” Reclaimable” blocks也會是屬於Allocatable, 除非Memory Page被設定為mlock,也就是說會脫離LRU Active/Inactive Anonymous/File-Mapping Memory Pages以外的範圍.
| Page block order: 10 Pages per block: 1024
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 0, zone DMA, type Unmovable 0 0 0 1 1 1 1 1 1 1 0 Node 0, zone DMA, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone DMA, type Movable 1 1 2 1 2 1 1 0 1 0 2 Node 0, zone DMA, type Reserve 0 0 0 0 0 0 0 0 0 1 0 Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone Normal, type Unmovable 502 1 0 0 0 0 0 0 0 0 0 Node 0, zone Normal, type Reclaimable 14 0 0 1 0 0 0 0 0 0 0 Node 0, zone Normal, type Movable 1 18 8 2 0 0 0 0 0 0 0 Node 0, zone Normal, type Reserve 67 26 9 14 7 1 2 0 0 0 0 Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone HighMem, type Unmovable 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone HighMem, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone HighMem, type Movable 7 0 0 0 0 0 0 0 0 0 0 Node 0, zone HighMem, type Reserve 0 0 1 1 1 0 0 0 0 0 0 Node 0, zone HighMem, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Reclaimable Movable Reserve Isolate Node 0, zone DMA 2 0 5 1 0 Node 0, zone Normal 23 2 85 1 0 Node 0, zone HighMem 3 0 7 1 0 |
/proc/meminfo è
主要用以提供Memory Distribution/Utilization的使用狀況,有關meminfo顯示的程式碼部分,可參考線上的Source Code Reference (http://hala01.com/src/linux/linux-3.5.4/HTML/S/6483.html#L22),
| 名稱 | 說明 |
| MemTotal: 482104 kB | 顯示目前Linux Kernel 所可以管理的所有記憶體總數,計算方式為總體實體記憶體,扣除硬體Reserved的部份,與Kernel Image本身所佔用的記憶體,就是屬於Linux Kernel Memory Management所可以管理的實體記憶體總數. 也就是在這所顯示的數值. |
| MemFree: 4460 kB | 會顯示目前位在 HighMemory與LowMemory中Free的Memory總數. |
| Buffers: 9208 kB | 屬於Buffers的記憶體會直接對應到Block Device區塊.用以作為Raw Disk Block的記憶體暫時儲存區域,會隨著記憶體與磁碟而增長. (例如在筆者的Server上這個值就超過1GB.). |
| Cached: 101256 kB | 作為檔案系統檔案讀取時的記憶體快取(Page Cache),用以加上基於VFS檔案系統讀取時的效率. |
| SwapCached: 112 kB | 由於Swap-Out (把Page從高效率的Memory寫到外部Storage裝置中) 與 Swap-In(Back) (把Page從外部Storage讀取回到高效率的Memory上),只要涉及到外部儲存裝置的存取動作,都會導致系統效能的降低 因此SwapCached這塊記憶體的功能主要用於讓程式會使用到的Memory內容在Swap-Out/In過程中,可以暫存在此作為SWAP Device的快取記憶體,避免頻繁的存取外部Storage,節省在I/O等待的時間. |
| Active: 305388 kB | 一般User-Space配置記憶體會透過Anonymous或File-Mapping的方式,例如malloc會透過mmap配置屬於MAP_ANONYMOUS的記憶體,或進行從Storage上把檔案Memory Mapping到使用者記憶體空間的操作. 兩者差別在於Anonymous是作為一般程式碼運作過程中所配置使用的記憶體內容,而File-Mapping這塊記憶體比較像是讓一個實體存在的檔案被貼到記憶體中存取或是執行 (.so),而對於User-Space而言,除了特別的Device Node會經由Kernel Module透過vmalloc/kmalloc配置記憶體外,由Linux Kernel開放給User-Space使用的記憶體就只有透過Anonymous或File-Mapping這兩個途徑. 而在這所指的Active,就是屬於Anonymous或File-Mapping透過LRU(Least Recently Used)屬於Active (也就是被定義為活躍還有持續在存取的記憶體內容.). |
| Inactive: 56336 kB | 如前述, Inactive為透過LRU(Least Recently Used)機制定義為非Active的Page,並可在後續記憶體配置有需要時,觸發Page-Reclaim回收給當下需要記憶體的程式使用. (只有放在LRU中的記憶體才會面臨是否要被Page-Reclaim的行為,或是屬於Unevictable或是藉由vmalloc/kmalloc所配置出來的記憶體,就不會被Page-Reclaim機制所回收) |
| Active(anon): 252496 kB | 屬於LRU(Least Recently Used) Anonymous Active(=LRU_ACTIVE_ANON) 的記憶體總量. |
| Inactive(anon): 272 kB | 屬於LRU(Least Recently Used) Anonymous Inactive(=LRU_INACTIVE_ANON) 的記憶體總量. |
| Active(file): 52892 kB | 屬於LRU(Least Recently Used) File-Mapping Active(=LRU_ACTIVE_FILE) 的記憶體總量. |
| Inactive(file): 56064 kB | 屬於LRU(Least Recently Used) File-Mapping Inactive(=LRU_INACTIVE_FILE) 的記憶體總量. |
| Unevictable: 5628 kB | 屬於LRU(Least Recently Used) Unevictable(=LRU_UNEVICTABLE) 的記憶體總量. |
| Mlocked: 16228 kB | 用以統計有被執行mlock的Page數目. (若Page存在LRU中,就會被改放到Unevictable List中). |
| HighTotal: 45056 kB | 用以表示目前屬於High Memory的記憶體總量,通常Kernel Space虛擬記憶體的起點會是0xc0000000-0xfffffff 這段約1GB的範圍,當實體記憶體空間超過Kernel所能定址的虛擬記憶體範圍時,這時Kernel 會需要提供一個機制,把能直接定址的記憶體範圍區分為Low Memory,而無法直接定址的記憶體範圍定義為High Memory,當要取得vmalloc 或 User-Space這類無需實體Linear Mapping的記憶體時,就會優先透過High-Memory Zone來取得,並透過這樣的機制,讓Kernel 也可以去善用這塊非實體Linear Mapping的記憶體空間. HighTotal的大小,則需視所在Kernel虛擬記憶體空間(from 0×80000000 or 0xc0000000)與當下的實體記憶體配置大小而定. |
| HighFree: 140 kB | 承上,除了vmalloc與User-Space記憶體外,像是檔案系統PageCache也會透過High-Memory進行配置. 而HighFree則用以表示當下屬於High-Memory區塊還有多少尚未被使用的空間. |
| LowTotal: 437048 kB | 相對於High-Memory, Low Memory就是指可以被Kernel Linear Mapping的實體連續記憶體空間,像是kmalloc/kmem_cache這類需要實體連續記憶體配置的操作,就會透過Low Memory取得. 而當High-Memory Zone能提供的記憶體不足時,也會選擇透過Low Memory進行記憶體配置. |
| LowFree: 4320 kB | 承上,Low Memory除了可在High Memory空間不足時,用以配置空間外,Low Memory也可供所有Kernel/User 記憶體需求配置來源,包括Kernel Memory Management所採用的Slab/Slob/Slub,及其上的kmalloc/kmem_cache所提供的核心模塊記憶體配置,都可倚賴Low-Memory區塊進行配置. 而LowFree所表示的就是這塊Low-Memory區域所剩餘的空間,當Low-Memory記憶體不足時,對Linux Kernel來說也會是記憶體吃緊最差的狀況. |
| SwapTotal: 0 kB | 用以表示目前系統Swap空間的總量. SwapTotal: total amount of swap space available |
| SwapFree: 0 kB | 用以表示目前目前Swap空間的剩餘數量. |
| Dirty: 2220 kB | 用以表示目前有多少Page屬性為Dirty,預備寫回外部儲存裝置中. |
| Writeback: 0 kB | 用以表示正準備回寫到外部儲存裝置的記憶體大小. |
| AnonPages: 256884 kB | 沒有實體檔案屬於Anonymous Page被映射到User-Space的記憶體大小. (=NR_ANON_PAGES) |
| Mapped: 90548 kB | 基於實體檔案被映射到User-Space Page的記憶體大小. (=NR_FILE_MAPPED),像是動態函式庫 .so/.dex 之類的檔案. |
| Shmem: 316 kB | =NR_SHMEM |
| Slab: 23176 kB | Slab是Linux Kernel記憶體管理機制最基礎也是許多核心模塊所基於的記憶體分配機制,通常用於配置重要的核心資料結構或是配置實體連續的記憶體使用.通常使用Slab的方式為透過kmalloc或透過kmem_cache. Slab記憶體空間的總和= SUnreclaim+SReclaimable |
| SReclaimable: 11952 kB | 用以表示可收回的Slab記憶體空間大小,例如供Cache使用的記憶體配置. |
| SUnreclaim: 11224 kB | 用以表示不可收回的Slab記憶體空間大小. |
| KernelStack: 5544 kB | =global_page_state(NR_KERNEL_STACK) * THREAD_SIZE / 1024 |
| PageTables: 9836 kB | 用以表示作為Page Table使用的記憶體空間大小. (=NR_PAGETABLE) |
| NFS_Unstable: 0 kB | 用以表示目前尚未送回到伺服器上穩定儲存裝置的NFS Pages記憶體空間大小. (=NR_UNSTABLE_NFS) |
| Bounce: 0 kB | Bounce: Memory used for block device "bounce buffers"(=NR_BOUNCE) |
| WritebackTmp: 0 kB | WritebackTmp: Memory used by FUSE for temporary writeback buffers(=NR_WRITEBACK_TEMP) |
| CommitLimit: 241052 kB | 當vm.overcommit_memory值設定為2, CommitLimit才會被致能.用以指當前系統還可以分配給應用程式使用的虛擬記憶體空間. CommitLimit的計算會基於vm.overcommit_ratio比例的配置,計算的公式如下所示 CommitLimit = (‘vm.overcommit_ratio’ * Physical RAM) + Swap 例如系統總共有1GB記憶體搭配4GB的SWAP,而vm.overcommit_ratio配置為40 ,則CommitLimit就會等於1GB*40%+4GB=4.4GB. (更進一步的資訊可以參考 vm/overcommit-accounting (Source Code路徑 http://hala01.com/src/linux/linux-3.5.4/HTML/S/25217.html)) |
| Committed_AS: 7632288 kB | 指目前在系統中已經分配給應用程式使用的虛擬記憶體總量,包括已經分配但尚未被使用到的虛擬記憶體空間. 若一個應用程式malloc了1GB記憶體,但只實際上Touch 400MB則對應到這個Committed_AS參數則只會顯示400MB,若一個應用程式配置了1GB 記憶體並設定為Committed,則會顯示完整的記憶體空間. 承上,當vm.overcommit_memory值設定為2,就會依據CommitLimit公式對虛擬記憶體的配置進行限制. |
| VmallocTotal: 573440 kB | 用以表明整體vmalloc記憶體配置區間的大小. |
| VmallocUsed: 157512 kB | 用以表示vmalloc區間被使用的空間大小. |
| VmallocChunk: 143364 kB | 用以表示vmalloc區塊(虛擬記憶體)最大可取得(Free)的連續記憶體空間. |
/proc/vmallocinfo è
提供vmalloc/vmap的配置資訊,每一行都代表一個虛擬記憶體範圍的配置,包括
1,虛擬記憶體配置的範圍
2,配置的記憶體大小 (bytes)
3,Caller的名稱/資訊
4,所包含的Page個數
5,Physical Memory的位址 (phys=7fee8000)
6,Callee的資訊 (像是 vmalloc,ioremap,vmap, vpages (buffer for pages pointers was vmalloced huge area)…etc)
取決於當下實際Kernel 虛擬記憶體的配置狀況.
實際Dump結果可參考如下內容
| 0xbf000000-0xbf042000 270336 module_alloc_update_bounds+0×14/0×64 pages=65 vmalloc 0xbf050000-0xbf058000 32768 module_alloc_update_bounds+0×14/0×64 pages=7 vmalloc 0xbf05b000-0xbf07e000 143360 module_alloc_update_bounds+0×14/0×64 pages=34 vmalloc 0xbf086000-0xbf0aa000 147456 module_alloc_update_bounds+0×14/0×64 pages=35 vmalloc 0xbf0b5000-0xbf0bb000 24576 module_alloc_update_bounds+0×14/0×64 pages=5 vmalloc 0xbf0be000-0xbf0de000 131072 module_alloc_update_bounds+0×14/0×64 pages=31 vmalloc 0xbf0e6000-0xbf0f3000 53248 module_alloc_update_bounds+0×14/0×64 pages=12 vmalloc 0xbf0f7000-0xbf114000 118784 module_alloc_update_bounds+0×14/0×64 pages=28 vmalloc 0xbf119000-0xbf11c000 12288 module_alloc_update_bounds+0×14/0×64 pages=2 vmalloc 0xbf11e000-0xbf120000 8192 module_alloc_update_bounds+0×14/0×64 pages=1 vmalloc 0xbf122000-0xbf129000 28672 module_alloc_update_bounds+0×14/0×64 pages=6 vmalloc 0xbf12c000-0xbf18c000 393216 module_alloc_update_bounds+0×14/0×64 pages=95 vmalloc 0xbf199000-0xbf1a0000 28672 module_alloc_update_bounds+0×14/0×64 pages=6 vmalloc 0xbf1a2000-0xbf1ad000 45056 module_alloc_update_bounds+0×14/0×64 pages=10 vmalloc 0xbf1af000-0xbf1bb000 49152 module_alloc_update_bounds+0×14/0×64 pages=11 vmalloc 0xbf1bd000-0xbf1e3000 155648 module_alloc_update_bounds+0×14/0×64 pages=37 vmalloc 0xbf1ee000-0xbf1f2000 16384 module_alloc_update_bounds+0×14/0×64 pages=3 vmalloc 0xbf1f4000-0xbf1f6000 8192 module_alloc_update_bounds+0×14/0×64 pages=1 vmalloc 0xbf1f8000-0xbf259000 397312 module_alloc_update_bounds+0×14/0×64 pages=96 vmalloc 0xdc004000-0xdc010000 49152 zisofs_init+0×14/0×34 pages=11 vmalloc 0xdc010000-0xdc211000 2101248 storage_logger_init+0x34c/0×564 pages=512 vmalloc 0xdc212000-0xdc214000 8192 slp_mod_init+0×34/0xb0 ioremap 0xdc214000-0xdc216000 8192 slp_mod_init+0×54/0xb0 ioremap 0xdc218000-0xdc293000 503808 mmc_blk_alloc_req+0×330/0x39c pages=122 vmalloc 0xdc293000-0xdc2a7000 81920 mt_lbprof_malloc_buf+0x2c/0×78 pages=19 vmalloc 0xdc2a7000-0xdc6b9000 4268032 mt_lbprof_malloc_buf+0x2c/0×78 pages=1041 vmalloc vpages 0xdc6b9000-0xdc6bc000 12288 mt_lbprof_malloc_buf+0x2c/0×78 pages=2 vmalloc 0xdc714000-0xdc716000 8192 NewVMallocLinuxMemArea+0x8c/0x14c [nodek] vmalloc vpages 0xdc716000-0xdc71a000 16384 NewVMallocLinuxMemArea+0x8c/0x14c [nodek] vmalloc vpages ………………. |
/proc/slabinfo è
用以顯示Kernel Slab Memory Pool資訊,Linux Kernely採用Slab/Slob/Slub作為核心記憶體的管理機制,而slabinfo可用以顯示Kernel Memory Cache物件使用的狀態,如下為筆者以Slub為例,並在系統啟動後透過/proc/slabinfo所顯示的Kernel Memory Cache使用狀態.
包括像是檔案系統,TCPIP通訊層,kmalloc所要配置使用的記憶體區塊 (kmalloc-8192,kmalloc-4096,kmalloc-2048,kmalloc-1024,kmalloc-512,kmalloc-256,kmalloc-192,kmalloc-128,kmalloc-96 kmalloc-64,kmalloc-32),都會記錄在slabinfo中,可藉此了解核心記憶體配置當下的狀況.
| slabinfo – version: 2.1 # name ext4_groupinfo_4k 34 34 120 34 1 : tunables 0 0 0 : slabdata 1 1 0 RAWv6 19 38 832 19 4 : tunables 0 0 0 : slabdata 2 2 0 UDPLITEv6 0 0 832 19 4 : tunables 0 0 0 : slabdata 0 0 0 UDPv6 19 38 832 19 4 : tunables 0 0 0 : slabdata 2 2 0 tw_sock_TCPv6 0 0 160 25 1 : tunables 0 0 0 : slabdata 0 0 0 TCPv6 0 0 1504 21 8 : tunables 0 0 0 : slabdata 0 0 0 nf_conntrack_c0b175a0 0 0 240 17 1 : tunables 0 0 0 : slabdata 0 0 0 kcopyd_job 0 0 2952 11 8 : tunables 0 0 0 : slabdata 0 0 0 dm_uevent 0 0 2464 13 8 : tunables 0 0 0 : slabdata 0 0 0 dm_rq_clone_bio_info 0 0 8 512 1 : tunables 0 0 0 : slabdata 0 0 0 dm_rq_target_io 0 0 248 16 1 : tunables 0 0 0 : slabdata 0 0 0 cfq_io_cq 1346 1387 56 73 1 : tunables 0 0 0 : slabdata 19 19 0 fuse_request 0 0 400 20 2 : tunables 0 0 0 : slabdata 0 0 0 fuse_inode 0 0 544 15 2 : tunables 0 0 0 : slabdata 0 0 0 isofs_inode_cache 17 17 456 17 2 : tunables 0 0 0 : slabdata 1 1 0 fat_inode_cache 5850 5850 536 15 2 : tunables 0 0 0 : slabdata 390 390 0 fat_cache 184 340 24 170 1 : tunables 0 0 0 : slabdata 2 2 0 jbd2_transaction_s 26 50 160 25 1 : tunables 0 0 0 : slabdata 2 2 0 jbd2_revoke_record_s 128 128 32 128 1 : tunables 0 0 0 : slabdata 1 1 0 journal_handle 170 340 24 170 1 : tunables 0 0 0 : slabdata 2 2 0 revoke_record 256 256 16 256 1 : tunables 0 0 0 : slabdata 1 1 0 ext4_inode_cache 1763 1764 760 21 4 : tunables 0 0 0 : slabdata 84 84 0 ext4_free_data 102 204 40 102 1 : tunables 0 0 0 : slabdata 2 2 0 ext4_allocation_context 36 72 112 36 1 : tunables 0 0 0 : slabdata 2 2 0 ext4_prealloc_space 53 92 88 46 1 : tunables 0 0 0 : slabdata 2 2 0 ext4_io_end 182 196 576 14 2 : tunables 0 0 0 : slabdata 14 14 0 ext4_io_page 5120 6144 8 512 1 : tunables 0 0 0 : slabdata 12 12 0 ext3_inode_cache 0 0 616 13 2 : tunables 0 0 0 : slabdata 0 0 0 ……… |
Proc FileSystem Memory Control Information
除了前述屬於資訊類的Memory Proc File System操作外, Kernel Memory還幫開發者預備好可供控制的各類參數,了解這些參數的入門障礙,絕對會比從眾多Kernel Memory Soure Code去整理邏輯來的好上手,這也是對Kernel Memory管理有興趣的開發者很適合的入門基礎.
如下為在筆者Linux Kernel 環境下,透過System Control Tool “sysctl” 所顯示出當下所有System Control Information 的數值
| sysctl -a|more kernel.sched_child_runs_first = 0 kernel.sched_min_granularity_ns = 3000000 kernel.sched_latency_ns = 15000000 kernel.sched_wakeup_granularity_ns = 3000000 kernel.sched_shares_ratelimit = 750000 kernel.sched_tunable_scaling = 1 kernel.sched_shares_thresh = 4 kernel.sched_features = 15834235 kernel.sched_migration_cost = 500000 kernel.sched_nr_migrate = 32 kernel.sched_time_avg = 1000 kernel.timer_migration = 1 kernel.sched_rt_period_us = 1000000 kernel.sched_rt_runtime_us = 950000 kernel.sched_compat_yield = 0 kernel.panic = 0 kernel.exec-shield = 1 kernel.core_uses_pid = 1 kernel.core_pattern = core ……………………. |
而在Android 4.1.1 r1下,則可以透過 “system/core/rootdir/init.rc” (http://hala01.com/src/android/android-4.1.1_r1/HTML/S/4180.html)檢視如下內容
| write /proc/sys/kernel/panic_on_oops 1 write /proc/sys/kernel/hung_task_timeout_secs 0 write /proc/cpu/alignment 4 write /proc/sys/kernel/sched_latency_ns 10000000 write /proc/sys/kernel/sched_wakeup_granularity_ns 2000000 write /proc/sys/kernel/sched_compat_yield 1 write /proc/sys/kernel/sched_child_runs_first 0 write /proc/sys/kernel/randomize_va_space 2 write /proc/sys/kernel/kptr_restrict 2 write /proc/sys/kernel/dmesg_restrict 1 write /proc/sys/vm/mmap_min_addr 32768 write /proc/sys/kernel/sched_rt_runtime_us 950000 write /proc/sys/kernel/sched_rt_period_us 1000000 write /proc/sys/vm/overcommit_memory 1 write /proc/sys/vm/min_free_order_shift 4 write /proc/sys/vm/dirty_expire_centisecs 200 write /proc/sys/vm/dirty_background_ratio 5 …… |
在沒有移植sysctl的環境,就可以參考Android init.rc中的作法,可以透過自行Script echo值的方式對System Control數值進行調教動作.
有關Memory System Control Information的資訊還可以透過 /proc/sys/vm目錄下的File Node來取得,如下筆者根據 /proc/sys/vm 目錄下不同的File Node進行說明與範例.
/proc/sys/vm/block_dumpè
在筆者的裝置上預設為0 (也就是步開啟 Block I/O Debugging),若設定為非0值就表示開啟Block I/O Debugging機制.
/proc/sys/vm/compact_memory è
當Linux Kernel編譯時設定CONFIG_COMPACTION,就可以開啟Kernel Memory支援Compact Memory 機制的能力,若設定此File Node值為 ”1” 時,所有的Memory Zone都會致能Compaction能力,讓原本隨著Kernel執行時間越長,會越來越破碎的Free Memory 區塊可以有機會被整合在一起成為連續的Block,讓Linux Kernel有機會配置較大塊的實體連續記憶體.
/proc/sys/vm/dirty_background_bytes and
/proc/sys/vm/dirty_background_ratio è
可以參考Linux Kernel 3.5.4中 mm/page-writeback.c的代碼,
dirty_background_ratio值預設為 10,也就是當Drity Page達到總系統記憶體10%時,就會觸發 Kernel Background WriteBack Thread “pdflush” 進行回寫流程.
dirty_background_bytes用以表示當Dirty Page Memory達到多少Bytes時,會觸發pdflush daemon背景執行Write-Back的行為. 同樣的, dirty_background_ratio則用以表示當Dirty Page Memory比率達到總系統管理Memory比率多少時,會觸發pdflush daemon背景執行Write-Back.
兩者只有一個會啟作用,當dirty_background_ratio致能時,就會導致另一個數值dirty_background_bytes變為0,以筆者的CentOS主機而言, dirty_background_bytes為0,而dirty_background_ratio為10,也就是說當Dirty Page Memory佔系統可管理的Memory比率達到10%時,就會觸發pdflush daemon進行Write-Back回寫的操作.而在Android 4.1.1_r1下, dirty_background_ratio被設定為5,也就是說,只要有5%的Dirty Page,在Android手機上就會觸發pdflush 回寫的機制.
/proc/sys/vm/dirty_bytes and
/proc/sys/vm/dirty_ratio è
可參考Linux Kernel 3.5.4中 mm/page-writeback.c的代碼,
vm_dirty_ratio值預設為 20,也就是當Drity Page達到總系統記憶體20%時,
就會觸發Kernel Page Write-Back的程序.
dirty_bytes用以表示當Dirty Page Memory達到多少Bytes時,會觸發Page強制Write-Back的行為. 同樣的, dirty _ratio則用以表示當Dirty Page Memory比率達到總系統管理Memory比率多少時,會觸發Page強制Write-Back.
當第一次看到 dirty_background_ratio 與 dirty_ratio時,當下各位可能會想明明都是針對Dirty Page的WriteBack行為,為何會有兩種水位與兩種行為同時存在系統中呢? 其實參考mm/page-writeback.c的代碼時,就可以發現dirty_ratio是屬於強制性的回寫,也就是說當一個Memory Zone內的Dirty Page達到這個比例時就會觸發Kernel Memory Management把Dirty Page強制回寫的流程,但dirty_background_ratio是屬於較軟性的行為,因為這是透過pdflush kernel thread進行的流程,可以在背景執行對這些Dirty Page回寫,並不會因此影響到當下正在執行中的Process. 所以看Linux Kernel中預設的水位是Dirty Page達到10%的比例時就會先透過pdflush kernel thread進行回寫,當Dirty Page達到20%比例時,就等於是一個很嚴重的狀況,此時就會在balance dirty page流程中觸發強制的Write Back,讓系統可以回復到原本預設合理的狀態.
/proc/sys/vm/dirty_expire_centisecs è
用以表明一個Dirty Page多久算是 “Expire”, 例如在筆者的CentOS上此值為3000 (也就是30秒算是Expire),而在我的Android手機上此值為100(也就是1秒算是Expire),當系統存在的Dirty Page ”時間週期”超過這個”Expire”數值時,就會在下次pdflush kernel thread被喚醒時,被回寫到儲存裝置中.
若此值設定太低,也就間接導致回寫儲存裝置會較為頻繁,需依產品當下的需求而定.
/proc/sys/vm/dirty_writeback_centisecs è
用以設定pdflush kernel thread多久執行一次,單位為1/100秒,例如在筆者的CentOS上此值為500 (也就是每5秒一次),而在我的Android手機上此值為300(也就是每3秒一次),通常如果所在環境記憶體比較充裕,且對執行檔案寫入的應用需求較低,而此值適合增加,但若記憶體的總量低或對檔案寫入的需求與頻繁度高,而降低這個值,會讓pdflush比較頻繁也均勻化Dirty Page Write-Back的行為.(可以更頻繁的分散到不同的時間間隔中)
/proc/sys/vm/drop_caches è
透過drop_caches可用以支援檔案系統相關的Cache 清除機制,例如像是
1,如果要釋放File的PageCache: 就可以透過 echo 1 到這檔案中
2,如果要釋放檔案系統的Dentries與Inodes: 就可以透過 echo 2到這檔案中
3,如果要同時釋放File PageCache與檔案系統的Dentries與Inodes: 就可以透過 echo 3到這檔案中
有關釋放Cache Memory的操作並不包含尚未回寫到儲存裝置的Dirty Page,要能一併有效反應並釋放出更多的記憶體空間,可先透過指令 “sync” 強制讓Cache Memory回寫到儲存裝置中.
/proc/sys/vm/extfrag_threshold è
extfrag_threshold值預設為500,這值的設定會影響到Kernel Compaction Memory的行為,而這值會發揮作用的前提也是Linux Kernel Memory Compaction機制有被致能.
當” fragmentation index is <= extfrag_threshold”成立,則Compact Memory流程將不會被執行,也就是說如果extfrag_threshold為0,則表示上述條件式不會成立,也就表示Kernel會很積極的進行Memory Compaction,也就是說當此值為0,但卻又配置不到連續的記憶體時,就表示Kernel Memory 當下真的是處於記憶體不足的狀況.反之,如果此值為1000,則Linux Kernel Memory Compaction會處於非常不積極的狀態,此時如果配置記憶體失敗,就有很大可能是因為Linux Kernel Memory當下Fragment 狀況所引起的.
/proc/sys/vm/hugepages_treat_as_movable è
hugepages_treat_as_movable值預設為0,當被設定為非0值時就表示允許從ZONE_MOVABLE Memory 區塊進行大塊(Huge Page)的記憶體配置.
Movable Zone主要用於配置可以被Reclaim或Move的Kernel Page,像是大區塊的記憶體配置(Hugh Pages)預設就不會從這區塊記憶體進行配置,但若是設定hugepages_treat_as_movable為非0值,就表示系統許可大區塊的記憶體配置可以從Movable Zone中進行配置(Depend on nr_hugepages). 但若應用程式使用大量的mlock (Memory Lock)配置所取得的Memory Page,就會導致Movable Zone不容易發揮對應的效益.
在初始化時會把所傳入的kernekcore記憶體數字根據系統有多少Memory Node平均分配給不同的Memory Node. 最後並會透過巨集roundup,計算MOVABLE ZONE 包含Pages的數值,並確保不會小於MAX_ORDER_NR_PAGES 的Page個數,而MAX_ORDER_NR_PAGES通常為 Order 10,也就是不小於1024個Pages.
除了kernelcore參數外,並支援kernelcore_max_addr用以限定因kernelcore設置後所配置的kernelcore最大的記憶體位置(在這範圍內的記憶體位址都是Non-Movable),在kernelcore_max_addr位址以上的記憶體Page都會是屬於 Movable/Migratable.
在沒有指定kernelcore參數的核心中,則不會有 ZONE_MOVABLE記憶體區段產生.當Kernel傳入的Parameters有包括kernelcore,則會透過函式cmdline_parse_kernelcore去解析核心啟動時所傳入的kernelcore帶的數值,這數字用以表示Linux Kernel支援non-movable allocation的記憶體總量,並會Applied這參數到系統中有致能”High Memory Zone”的 Memory Node上.而對每一個Memory Node而言,在這數值範圍以外的記憶體就會是屬於Movable Pages.(多數的手持裝置或購買的桌上型電腦都是只有一個Memory Node.).
/proc/sys/vm/hugetlb_shm_group è
包含許可產生支援hugetlb page的System V Shared Memory區段的Group ID.
/proc/sys/vm/laptop_mode è
有關laptop_mode的說明最佳文件就是Linux Kernel Source Code中的 "Documentation/laptops/laptop-mode.txt" 檔案,主要用以針對筆記型電腦的配置所支援的設定參數,所屬的系統參數設定檔可以參考"/etc/sysconfig/laptop-mode",像是最後剩餘的電量還能使用多久,就要強制關係Laptop Mode,Process Dirty Page,或有關儲存系統的配置參數…etc.
/proc/sys/vm/legacy_va_layout è
預設值為0,若設定為非0值,會把目前32-bits MMAP Layout設定為原本2.4 Kernel的Process MMAP Layout. (筆者目前無2.4環境,尚無法比對跟Kernel 3.x的差異…..Orz).
/proc/sys/vm/lowmem_reserve_ratio è
在筆者的Android裝置上,若為DMA or DMA32 Zone此值預設值為 256,其它則是預設為 32 (例如,Normal Zone),對Linux Kernel而言,通常User-Space記憶體的取得會先從High Memory Zone取,若無才會往Low Memory Zone取,主要原因在於Kernel重要的資料結構 (based on kmalloc/kmem_cache),都會從有限的Low Memory空間挖取,若User-Space記憶體配置也先從Low Memory 空間挖取記憶體設定mlock, 就會導致Low Memory 空間越來越難以回收
基於上述說明,可以知道lowmem_reserve_ratio 比較適用於平台上有大塊High-Memory Zone的配置,若使用者裝置尚僅有Low Memory Zone,或是High Memory Zone也很有限 (例如只有幾十MB),其實設定這個參數的意義也不會太大.
有關計算的方式可以參考Linux Kernel 3.5.4函式 setup_per_zone_lowmem_reserve (in Source Code mm/page_alloc.c, 線上Source Code inhttp://hala01.com/src/linux/linux-3.5.4/HTML/S/8040.html#L4996), 基於lowmem_reserve_ratio與Present Page所計算的Zone Protetion邏輯如下
| (i = j): (should not be protected. = 0; (i < j): zone[i]->protection[j] = (total sums of present_pages from zone[i+1] to zone[j] on the node) / lowmem_reserve_ratio[i]; (i > j): (not necessary, but looks 0) |
由於lowmem_reserve_ratio會以Array的方式呈現目前系統中每個Zone的參數,以筆者手中的裝置來說,在Buddy System包括如下內容的環境
| Node 0, zone Normal 488 144 73 14 7 1 2 0 0 0 0 Node 0, zone HighMem 16 2 1 1 1 0 0 0 0 0 0 |
lowmem_reserve_ratio Array內容為 “32 32”,且
| Zone Normal, present=112268 and protection: (0, 349, 349) Zone HighMem, present=11176 and protection: (0, 0, 0) |
基於計算邏輯,
Zone Normal的protection: (0, 349, 349)是以
A, (i = j), protection=0
B, (i < j), protection=11176/32 = 349.
C,(i < j) , protection=11176/32 = 349.
計算所得.
在64bits Linux Kernel 上的Buddy System包括如下內容的環境 (請注意這是64bits的裝置,雖然記憶體有16GB,但卻不會有High-Memory Zone)
| Node 0, zone DMA 2 0 1 2 1 1 0 0 1 1 3 Node 0, zone DMA32 9150 8854 8318 7520 6130 4201 2203 723 146 11 2 Node 0, zone Normal 8660 6230 5741 19059 14697 6314 2367 496 48 4 0 |
lowmem_reserve_ratio Array內容為 “256 256 32” ,且
| Zone DMA, present=3809 and protection: (0, 2914, 16042, 16042) Zone DMA32, present=746212 and protection: protection: (0, 0, 13128, 13128) Zone Normal, present=3360775 and protection: (0, 0, 0, 0) |
基於計算邏輯,
Zone DMA的protection: (0, 2914, 16042, 16042)是以
A, (i = j), protection=0
B, (i < j), protection=746212 /256 = 2914.
C,(i < j) , protection=(746212 +3360775 )/ 256 = 16042.
D,(i < j) , protection=(746212 +3360775 )/ 256 = 16042.
Zone DMA32的protection: (0, 0, 0, 13128, 13128)是以
A, (i > j), protection=0
B, (i = j), protection=0.
C,(i < j) , protection=(3360775 )/ 256 = 13128.
D,(i < j) , protection=(3360775 )/ 256 = 13128.
計算所得.
基於lowmem_reserve_ratio所計算的Protection數值可用以決定是否一個Memory Zone適合用於記憶體配置或是應該要進行Memory Reclaimed流程了.
當要進行記憶體配置時就會先到當下對應Zone ID (此區也會是Protection數值為0的區塊)進行配置,若當下對應的Zone ID已經沒有足夠的Free Page可供使用,此時就可以往下一個Zone ID去找Free Page嘗試配置出足夠的記憶體空間,
以DMA32的例子來說,所以DMA32 Zone的Free Page並不足夠因應這次所需的記憶體配置需求,Kernel就會取得下一個Normal Zone (ID=2) 的Free Page數值,並且確認該Memory Zone的“Free Page數量大於 watermark[WMARK_HIGH] + 13128 (=DMA32 Zone->Protection[2])”,若是則可將DMA32所需記憶體透過Normal Zone進行記憶體配置.
也就是說,若希望確保Normal Zone盡可能不要被其它需求給配置走,就該把 lowmem_reserve_ratio設定為1 (=100%),若是設定的數值越高,則DMA32 Zone->Protection的數值計算後越低,則越有機會讓Normal Zone提供記憶體給DMA32 Zone.
/proc/sys/vm/max_map_count è
MMAP是Linux環境上記憶體配置(dlmalloc mmap)與應用程式執行所需Shared Library 與 DEX檔案Mapping最頻繁使用的介面.而max_map_count能用以限定單一應用程式執行環境最大的MMAP數量,預設值會等於DEFAULT_MAX_MAP_COUNT,而在筆者驗證的Android手機上此值預設為65530.
基於目前Android上的dlmalloc/mspace記憶體管理機制,包含檔案執行MMAP的需求,除非有Resource Leakage的問題發生,預設值的配置已能符合目前應用程式的需求.
/proc/sys/vm/memory_failure_early_kill è
Linux Kernel Memory Failure保護機制 (Source Code in mm/memory-failure.c),原本用意是在支援有記憶體ECC保護機制下,透過硬體回報特定的Memory Page有問題時,透過Page Poison Bit提供一個 "Soft Offline"機制,避免讓有問題的Page導致程式執行錯誤發生.在執行時期也可以透過SetPageHWPoison設定一個Page為Hardware Poison,或可透過PageHWPoison巨集確認是否所處理的Page已經被設定為Hardware Poison.
memory_failure_early_kill預設為0,可用以設定當Memory Page被Hardware報錯誤時,要如何處理當下Process運作的行為. 通常,如果所損壞的Page可以在儲存裝置上找到的話,Kernel 是有機會可以補救的,但若該損壞的內容是Run-Time執行
過程中產生的,除非結束Process執行,不然會非常難以補救.
如下所示,列出memory_failure_early_kill設定數值與對應的處理行為
0: 在偵測到Page損壞後,會把該Page 從所有使用到他的程式記憶體空間中Unmap掉,並只有在後續仍嘗試去使用該Page的程式會被結束執行.
1: 在偵測到Page損壞後,會結束包含該無法修復Page的所有程式執行. (只限於User-Space的應用程式,若是Kernel Space的Memory Page則無法補救.)
結束User-Space程式的方式為透過SIGBUS (Signal No. 7 with Signal Code=5, BUS_MCEERR_AO in include/asm-generic/siginfo.h). 若程式處理流程有需要攔截這動作,則可另外處理.
而Hardware Poison機制只限定於有支援Memory ECC的硬體上,若所使用的平台並沒有這樣的能力,則無這樣的支援.
/proc/sys/vm/memory_failure_recovery è
memory_failure_recovery預設為1,如同memory_failure_early_kill,這是一個基於Hardware Poison的機制,可用以設定Memory Failure Recovery的行為,當設定為1表示會嘗試進行修復,反之設定為0則表示一定遇到Memory Failure就會觸發Kernel Panic 並顯示 “Memory failure from trap …. on page ….” Kernel 字串.
/proc/sys/vm/min_free_kbytes è
在筆者測試的Android環境中, min_free_kbytes值預設為2680,此值主義用來強制Linux Kernel所要保留的最低Free Memory總數. 而這個值也會被用來計算為當下Kernel Memory Management中的 Min WaterMark水位 (=watermark[WMARK_MIN]).
若此值設定的太高,會更容易在進入Reclaim Pages時,導致觸發OOM (Out-Of-Memory) 流程,反之若設定的過低,例如只有幾百kbytes,就有機會導致Kernel Memory 的Allocation與Reclaim流程,在系統陷入極低Free Memory狀態下,陷入Deadlock的狀況. (在配置記憶體時,又會進入Reclaim Page,與進入OOM,隨後又執行記憶體配置,如此不斷反覆觸發,導致系統Deadlock無法有效運作.)
/proc/sys/vm/min_slab_ratio è
min_slab_ratio預設為5,並只在支援 NUMA(Non-Uniform Memory Access Architecture)的Linux Kernel才支援這個選項, 並會被用以計算Memory Zone的min_slab_pages數字,若目前Memory Zone內可被Reclaim的Slab Page總數大於min_slab_pages,就會觸發Shrink Slab流程,直到釋放足夠的記憶體為止.
/proc/sys/vm/min_unmapped_ratio è
min_unmapped_ratio預設為1,並只在支援 NUMA(Non-Uniform Memory Access Architecture)的Linux Kernel才支援這個選項, 並會被用以計算Memory Zone的 min_unmapped_pages數字,若Unmapped Pages超過這數值,會導致zone_reclaim_mode設定為1,
/proc/sys/vm/mmap_min_addr è
mmap_min_addr 的設定是在Linux Kernel 2.6.23之後導入的機制, 用以指定User-Space可以MMAP的最低記憶體位址,在Jelly Bean之後這個數值被設定為32768.
主要目的為避免非特權等級的使用者行程在非許可的低記憶體位址空間中產生記憶體映射,而發生Linux潛在的安全問題發生(像是跳到鄰近0×00000000附近的記憶體位址執行程式碼或讀取資料).
/proc/sys/vm/nr_hugepages è
用以設定hugepage pool的最低許可值.(相關文件可參考 Documentation/vm/hugetlbpage.txt).
/proc/sys/vm/nr_overcommit_hugepages è
用以設定hugepage pool的最大值,一個系統的上限為 “nr_hugepages + nr_overcommit_hugepages”
/proc/sys/vm/nr_pdflush_threads è
這是一個唯讀的設定,用以顯示目前系統有多少pdflush kernel thread被啟動用以把Dirty Page回寫到儲存裝置中.一個系統的pdflush kernel thread上限可以透過nr_pdflush_threads_max進行設定.
/proc/sys/vm/nr_trim_pages è
nr_trim_pages只在關閉 MMU 時才有作用 (CONFIG_MMU=n),當數值為0表示Disable,若設定為1表示在NO-MMU環境下MMAP超過2^1的記憶體配置都會被裁剪,參考函式do_mmap_private (in Source Code mm/nommu.c),若設定為>=1,則會依據所設定的值,以power-of-2進行Page Size Aignment. (例如設定為3既是超過2^3=8個Pages就會被裁剪.).
/proc/sys/vm/numa_zonelist_order è
numa_zonelist_order預設為” default”,並只在支援 NUMA(Non-Uniform Memory Access Architecture)的Linux Kernel才支援這個選項.
在進行記憶體配置時,跨不同Memory Zone之間的記憶體配置會根據Zone List順序來加以決定,例如要配置GFP_KERNEL屬性的記憶體時,找尋Memory Zone的順序會是 ZONE_NORMAL -> ZONE_DMA,也就是說當Normal Zone記憶體不足時,就會嘗試透過DMA Memory Zone來尋找是否有可供使用的記憶體區塊大小.
假設在一個平台上支援兩個Memory Node,而這兩個Memory Node各自都擁有Normal Zone與DMA Zone,則找尋記憶體的順序可以為
方案1, Normal Zone in Node(0) -> DMA Zone in Node(0)->Normal Zone in Node(1)
或
方案2, Normal Zone in Node(0) >Normal Zone in Node(1)
-> DMA Zone in Node(0)-
與效能而言,當Node 0的Normal Zone被使用完畢,取同一個Node 0上的DMA Zone的記憶體對效能上會是比較好的,但缺點卻在於會讓在Node 0上原本相對Size就比較小的DMA Zone被Normal Zone的需求給加速耗盡. 但如果選擇方案2,會因為要跨越Node 0->Node 1而導致效能的影響,當然好處是可以透過兩個Memory Node的Normal Zone配置避免因為記憶體不足的問題把要給硬體傳輸使用的DMA Zone也給加速耗盡. (通常,Normal Zone都會比DMA Zone大上不少).
而方案1在此可稱呼為 “Node-Order”,方案2可稱呼為 “Zone-Order”,兩者思維差異在前者是先把自己Node上的記憶體耗盡後才往其它Memory Node去找,後者則是依據不同Memory Node上的Zone屬性來最佳化記憶體的使用.
在系統啟動後可以透過 “echo Z > /sys/vm/numa_zonelist_order”啟動 Zone-Order ,透過“echo N > /sys/vm/numa_zonelist_order” 啟動 Node-Order,若是執行 “echo D > /sys/vm/numa_zonelist_order” 啟動 Default-Order則預設會是以Node-Order來執行.
/proc/sys/vm/oom_dump_tasks è
oom_dump_tasks設定為0,則關閉這機制,若設定為1表示機制開啟.
可在Out-Of-Memory 發生時Dump Task包括User/Kernel-Space Process/Thread的資訊,也就是說當Kernel在記憶體不足時,觸發OOM (Out-Of-Memory)去結束程式執行時,可以把包括 PID,UID,TGID,VM Size,RSS,CPU, OOM_ADJ Score與 Process Name 等資訊Dump出來,讓系統問題的解決時,可以有足夠的資訊進行分析問題會遇到記憶體不足的問題. (可能是Memory Leakage 亦或者是該應用程式特殊的設計行為).
/proc/sys/vm/oom_kill_allocating_task è
oom_kill_allocating_task預設為0,可用以關閉或開啟OOM (Out-Off-Memory)在記憶體不足時,進行Process結束執行的能力.
若此值為0,OOM Process Killer會在記憶體不足時Scan Task-List並針對所選出的Process進行結束執行的動作.(通常會選擇佔據記憶體最大的那個Task,以便在刪除時可以儘快釋出足夠的記憶體空間).
若設定為非0值,則不會去Scan Task-List只會結束觸發OOM狀況的Process.
此外,若panic_on_oom也有致能,Kernel Panic優先級會高於oom_kill_allocating_task所做的設定.
/proc/sys/vm/overcommit_memory è
overcommit_memory預設值為 0 (=OVERCOMMIT_GUESS),是用於控制User-Space 記憶體的配置是否可以Overcommit,影響的行為在於裝置上的Memory總數不足時,是否可以讓應用程式進行超過記憶體總量的配置,等到真的去Touch到過量的記憶體時,才做異常行為的處理. (可參考文件 Documentation/vm/overcommit-accounting, inhttp://hala01.com/src/linux/linux-3.5.4/HTML/S/25217.html)
若此值為0 (=OVERCOMMIT_GUESS),表示當User-Space一用程式要配置新的記憶體時,Kernel會去計算目前剩下的Free Memory是否足夠,才提供服務,若所在的環境有開啟Swap的話,就可以透過Swap-Device裝置,讓User-Space Page-Reclaimable 的記憶體有機會被Swap-Out到外部裝置上,從而讓整體可供使用的記憶體空間更大. (筆者使用的Linux Server就是設定為 0 + Swap-Device.)
若此值為1 (=OVERCOMMIT_ALWAYS),Kernel會假設記憶體永遠足夠,並許可User-Space 記憶體Overcommit,直到實際使用異常發生才做錯誤處理或預防. 筆者使用的Android裝置就使設定此值為1,但由於Android有支援Low-Memory Killer 機制,雖然設定此值為1,且絕大多數Android裝置都不會開啟Swap-Device,但並不會真的發生記憶體耗盡的問題. 除非有Kernel Space or ADJ權值很大的Process發生Memory Leakage,不然在進入到記憶體最差的狀況前,Low-Memory Killer機制就會運作刪除ADJ權值較低的Process,藉此釋放出更多的記憶體空間.
若此值為2 (=OVERCOMMIT_NEVER),則還須參考overcommit_ratio的設定值,表示 “Don’t overcommit”, 總體可使用的記憶體空間會等於 Swap裝置的大小 + Physical Memory Size * overcommit_ratio (預設為50%) ,Kernel會避免任何Overcommit記憶體的行為發生,也就是說若程式能配置到記憶體,就可以保證一定有對應的空間 (不論是來自Swap or Physical Memory)可以提供給程式使用,若會發生錯誤就是在記憶體配置時失敗,而不會說配置之後,才在Run-Time實際使用時,觸發Page Fault,但又無法找到可用的Memory Page,而導致在執行過程中的錯誤發生.
這配置對於設計Embedded System而言很有幫助,可藉此決定Memory釋出機制,並影響到最終產品的運作行為.
而當下Memory Commit的資訊可以透過/proc/meminfo中的CommitLimit與Committed_AS得知. (overcommit limit and amount committed).
例如下面為筆者的Android手機,設定為OVERCOMMIT_ALWAYS,可以看到實際Commit的記憶體上限跟
CommitLimit: 241052 kB
Committed_AS: 7632288 kB
例如下面為筆者的Linux Server,設定為OVERCOMMIT_GUESS,可以看到實際Commit的記憶體上限跟
CommitLimit: 24573564 kB
Committed_AS: 1468016 kB
有關記憶體屬性與Overcommit計算的原則如下
| 來源分類 | 記憶體屬性 | 說明 |
| File backed map (也就是有實體存在的檔案Memory Mapping) |
Shared或Read-Only | 不納入成本的計算 |
| PRIVATE WRITABLE | 依實際Mapping的範圍與Instance個數計算成本 | |
| Anonymous Memory 或來自 /dev/zero 的Memory Mapping | PRIVATE READ- Only | 不納入成本的計算 |
| PRIVATE WRITABLE | 依實際Mapping的範圍與Instance個數計算成本 | |
| SHARED | 以Mapping的範圍計算成本,但並不因Mapping的Instance變多而增加成本計算 |
其它影響計算成本的操作還有
| 1, Memory Mapping Page因為Copy-On-Write而產生出新的複製Page |
| 2, 透過mprotect設定Page屬性為 Commit |
| 3, 透過mremap改變Memory Mapping大小 |
| 4, 透過BRK (改變Data Segment大小)所配置的記憶體 |
| 5, 執行 munmap釋放記憶體 |
| 6, shmfs memory drawn from the same pool (SHMfs accounting) |
/proc/sys/vm/overcommit_ratio è
overcommit_ratio設定只在overcommit_memory設定為2(=OVERCOMMIT_NEVER)時才有作用,用以計算SWAP + Physical Memory * overcommit_ratio 得到系統總體可供Commit的記憶體總量.
/proc/sys/vm/page-cluster è
用以控制要把Memory Pages回寫到SWAP上的Pages數量與影響SWAP I/O操作. 會以power-of-2的方式表示,也就是說如果設定為0表示一次以一個Page為單位進行SWAP 處理,若設定為 1表示一次2個Page. page-cluster預設為3,也就是會一次以2^3=8個Pages處理Pages SWAP操作.
在系統效能調教時,就可根據自身產品對 I/O的配置,進行細部調整.
/proc/sys/vm/panic_on_oom è
可用以致能在OOM (Out-Of-Memory)發生時,觸發Kernel Panic. panic_on_oom預設值為0,Linux Kernel在OOM發生時,會透過oom_killer嘗試結束Process並釋放出足夠的記憶體讓系統可以持續運作下去.
如果設定為1,原則上當OOM發生時就會導致Kernel Panic,但若當下系統還有其它的Memory Node擁有Free Memory,只是這個Process受限於Memory Policy/CPUSets而導致無法透過其它Memory Node取得可供使用的記憶體空間,表示OOM的狀況並非系統當下已經沒有記憶體,而是受限於程式本身與系統配置的問題,此時就會透過oom_killer刪除程式釋放出足夠的記憶體,而不會讓系統進入Kernel Panic狀態,以免影響到其它Process的正常執行. (此時系統其它Process還是可以透過有Free Memory的Memory Node取得記憶體空間).
如果設定為2,一旦OOM發生,就會觸發Kernel Panic讓整體系統停下來,通常這樣激烈的手段,應該是用在開發過程中,希望透過觸發Kernel Panic + KDump進行除錯的需求.
/proc/sys/vm/percpu_pagelist_fractionè
初始值為0,表示Linux Kernel 預設不會用這個值作為設定Memory Zone Per CPU Page List High Water Mark的參數.
用以決定在每個Memory Zone中的per_cpu_pages->High_WaterMark 所佔的比例.最小值為8,用以表示不允許有超過1/8的Memory Zone所屬Page被配置給任意的Per CPU Page List.若設定為100,就表示Memory Zone內最多只能有1/100的Page是配置給Per CPU Page List.
/proc/sys/vm/stat_interval è
用以設定Virtual Memory統計資料 (VM Statistics)更新的週期,預設值為1.(也就是1秒.)
/proc/sys/vm/swappiness è
預設值為60,用以決定Kernel 會有多努力要把記憶體中的資料Swap Out到外部儲存裝置中,數值越高會越積極的去執行Swap Out.
/proc/sys/vm/vfs_cache_pressure è
用以決定Kernel Reclaim 檔案系統目錄/inode object Cache的積極性, vfs_cache_pressure預設為100,表示Kernel會試圖在考量到PageCache/SwapCache平衡的前提,去對dentries/inodes Cache Memory進行Page Reclaim的操作. 如果降低這個數值,會讓Kernel盡可能的保留dentries/inodes Cache Memory,缺點也就是會讓記憶體耗用的速度更快,反之如果這個數值大於100,就會讓Kernel 更積極的對dentries/inodes Cache Memory進行Reclaim的回收操作.
/proc/sys/vm/zone_reclaim_mode è
zone_reclaim_mode可提供當Memory Zone記憶體耗盡時,對Memory Reclaim積極性的增減操作. 若此值設定為0,表示不會以Zone Reclaim的動作發生,所有的記憶體配置會進一步嘗試從同一個Node中的其它Zone,或是從其它Node取得Free Memory. (需視當下numa_zonelist_order的設定為何).
有關zone_reclaim_mode的各Bit 意義說明如下
Bit 0 : 為1表示Memory Zone Reclaim Enable
Bit 1: 為1表示Zone reclaim writes dirty pages out
Bit 2: 為1表示Zone reclaim swaps pages
若所提供的服務是檔案伺服器,則並不建議打開Zone Reclaim機制,以便儘可能在記憶體中保留File System有關的Cache Memory,提昇系統的效能. 當觸發的Zone Reclaim是涉及到其它Memory Nde上的Dirty Page Write Out,則可能會對當下執行這動作的處理器Processes有效能上的影響.
結語
本文主要闡述筆者認為基礎,並補上Linux Kernel Memory在 /proc 下所提供的記憶體資訊與控制機制,若對於這些資訊與控制參數有興趣,在閱讀後各位也可以使用自己所擁有的Android/Linux執行環境加以驗證 (嗯嗯,,不過記得要先Root.),唯有親手操作過,體驗過,本文所提到的內容才有機會真正內化為未來可供使用的開發利器.
最後,核心記憶體管理機制是一個看似簡單,卻又複雜的議題,Linux Kernel Memory然在持續演進中,希望本文能對各位Hacking Kernel Source Code的路上有所助益. Thanks!.